一种端到端的风格一致的文字图像生成方法
1.本发明涉及一种文字图像生成方法,具体涉及一种在复杂背景环境下能够保持文字风格的端到端图像生成方法,主要面向图片翻译场景,把目标文字按照源风格进行图像绘制,保留背景纹理以及原始文本的风格(字体、颜色、形状等),实现翻译后文字的高保真替换。
背景技术:
2.风格一致的文字图像生成旨在实现文字高保真替换,有许多实际应用,如图像翻译、文本检测和识别任务、电影海报文字编辑等。对于图像翻译任务,可以改善翻译结果,提升用户体验;对于文本检测和文本识别任务,可以快速针对特定场景扩充数据;对于设计师来说,可以快速针对不同国家设计统一文字风格的海报。
3.对于自然场景中的真实图片,其中的文字语言不同、形状大多不规则、大小不等、字体多变、颜色不一,背景纹理也十分复杂,单纯的替换文字很简单,核心挑战在于新图像要保持原始文字风格和背景纹理。开发快速自动替换场景中文本的算法,从而无需花费数小时的手动图像编辑时间。
4.风格一致的文字图像生成需要gan、文本风格迁移、文字擦除等技术的支撑。
5.生成对抗网络(gan)已经在噪声生成图像、图像到图像的转换、风格迁移、姿势迁移、快速换脸等多个领域取得了很大的进步和关注。gan由一个生成网络和一个判别网络组成。两个模型通过对抗过程同时训练。生成网络学习创造逼真的样本,判别网络则学习如何辨别真实样本与生成的“假样本”。训练过程中,生成网络能力增强,生成的“假样本”趋近于真实,判别网络能力也逐渐变强,尽力拆穿伪造的样本。当判别网络无法区别真实样本与生成“假样本”时,说明生成网络产生的样本符合真实数据的分布。
6.文本风格迁移旨在从源图像捕捉完整的文本风格并将其迁移到目标文本中。现有一些方法侧重于字符级风格迁移。人们已经可以将标准字体图像变为书法图像,可以使用少量的风格化英文字符产生全部26个风格字母,甚至可以通过仅观察几个字符样本就可以在不同语言之间传递字体风格。
7.文字擦除主要针对图像中的文本区域进行修补,填充合理的背景纹理,并且要保证非文本区域的真实性。由于自然场景中的图像背景较为复杂、光照不均匀、文本形状畸变严重、文本区域未知等问题,因而具有很大的挑战性。
8.一种新的基于文本的增强现实系统,包括一个替换文本内容的实时图像增强算法(koo h i,kim b s,baikyk,et al.fast and simple text replacement algorithm for text
‑
based augmented reality[c]//2016visual communications and image processing(vcip).ieee,2016:1
‑
4)。该方法存在以下问题:
[0009]
(1)无法处理背景较为复杂的场景,在重建背景过程中容易产生伪影。
[0010]
(2)难以模拟文本复杂的形变,如透视形变、弯曲文本等情况,在反向校正后可能难以保证与全局图像的语义连贯。
[0011]
(3)无法完整捕捉原始文本的风格,如字体、形状、阴影等效果。
技术实现要素:
[0012]
针对现有技术存在的上述问题,本发明提供了一种端到端的风格一致的文字图像生成方法。
[0013]
本发明的目的是通过以下技术方案实现的:
[0014]
一种端到端的风格一致的文字图像生成方法,包括如下步骤:
[0015]
步骤一、对源风格图像中的文字进行擦除,补充背景纹理,得到无文字的背景图像,具体步骤如下:
[0016]
(1)将源风格文本图像通过3个下采样卷积层和4个残差块进行编码;
[0017]
(2)使用解码器通过3个上采样卷积层生成原始大小的输出图像;
[0018]
步骤二、将目标文本渲染为图像并嵌入背景重建模块输出的无文字的背景图像中,在相同背景下将源图像的文本风格迁移到目标文本中,具体步骤如下:
[0019]
(1)将背景图像与目标文本图像沿深度轴连接,经过3个下采样卷积层和4个残差块进行编码;
[0020]
(2)对源风格文本图像进行编码;
[0021]
(3)将(1)和(2)中两个编码特征图送入自注意力网络sa;
[0022]
(4)将自注意力网络sa输出的特征图输入3个上采样反卷积解码器网络,获得风格文本图像。
[0023]
一种实现上述文字图像生成方法的文字图像生成系统,包括背景重建模块和风格文本嵌入模块,其中:
[0024]
所述背景重建模块用于对源风格图像中的文字进行擦除,补充背景纹理,得到无文字的背景图像;
[0025]
所述风格文本嵌入模块用于将目标文本渲染为图像并嵌入背景重建模块输出的无文字的背景图像中,在相同背景下将源图像的文本风格迁移到目标文本中;
[0026]
所述背景重建模块采用gan架构,生成网络采用编码器
‑
解码器模式,在编码器
‑
解码器架构中引入skip
‑
connection,判别网络采用patchgan;
[0027]
所述风格文本嵌入模块采用gan架构,生成网络采用编码器
‑
解码器模式,判别网络采用patchgan,并且为了能够更好的迁移文本风格,在生成网络中引入自注意力网络。
[0028]
相比于现有技术,本发明具有如下优点:
[0029]
1、本发明中,背景重建模块主要目标是对图像中的文本进行擦除,补充背景纹理,得到无文字的背景图像。这一部分采用gan架构,生成网络采用编码器
‑
解码器模式,判别网络采用patchgan可以有效捕捉局部纹理的差别,通过生成网络与判别网络之间的博弈,能够得到更逼真的文本擦除后的图像,解决现有技术中背景重建可能产生的伪影、不真实等问题。
[0030]
2、本发明中,风格文本嵌入模块主要针对前景文本,将目标文本渲染为图像并嵌入重建好的背景中,在相同背景下将源图像的文本风格迁移到目标文本中。首先将内容图像与背景重建结果进行连接,使用下采样卷积层和残差块对其进行编码,同样也对源风格图像进行编码,然后将这两个特征图沿深度轴连接并馈送到自注意力网络,该网络会自动
学习特征图之间的对应关系,最后将输出的特征图输入上采样反卷积解码器网络获得风格化文本图像,可以解决现有技术中无法捕捉原始文本风格的问题。
[0031]
3、本发明实现的是中英之间的图像文本风格保真替换,但改变训练数据即可支持其他语言之间的风格保真替换。
[0032]
4、本发明采用端到端的方法,将文本风格迁移、文字擦除等工作整合为一个网络,减少中间步骤可能带来的效果和性能的损失。
[0033]
5、本发明通过使用gan算法,能够生成更加真实、风格更一致、语义更连贯的结果。
附图说明
[0034]
图1为端到端架构的生成网络结构图;
[0035]
图2为背景重建模块;
[0036]
图3为风格文本嵌入模块;
[0037]
图4为英文替换为中文的示例1;
[0038]
图5为英文替换为中文的示例2;
[0039]
图6为中文替换为英文的示例;
[0040]
图7为一组训练数据,英文替换为中文;
[0041]
图8为一组训练数据,英文替换为英文;
[0042]
图9为数据合成流程图;
[0043]
图10为一个残差块;
[0044]
图11为自注意力模型的计算过程。
具体实施方式
[0045]
下面结合附图对本发明的技术方案作进一步的说明,但并不局限于此,凡是对本发明技术方案进行修改或者等同替换,而不脱离本发明技术方案的精神和范围,均应涵盖在本发明的保护范围中。
[0046]
本发明提供了一种端到端的风格一致的文字图像生成系统,如图1所示,所述系统包括背景重建模块和风格文本嵌入模块,其中:背景重建模块将源风格图像中文字擦除并填充上合理的纹理,风格文本嵌入模块在背景图像上插入新的风格化目标文本。每个模块的详细结构如下:
[0047]
如图2所示,所述背景重建模块的主要目标是图像中的文本擦除,重建背景纹理,得到无文字的背景图像。
[0048]
生成对抗网络能够获得更真实、分辨率更高的图像,在这一部分采用gan架构。生成网络采用编码器
‑
解码器模式。首先将风格文本图像通过3个下采样卷积层和4个残差块进行编码,然后使用解码器通过3个上采样卷积层生成原始大小的输出图像,在每一层卷积之后都使用leakyrelu激活函数,并将tanh激活函数用于最后一层。
[0049]
u
‑
net能够合成视觉效果更加逼真的图像,故在编码器
‑
解码器架构中引入skip
‑
connection作为本模块的生成网络。如图2虚线所示,在下采样过程中,将编码特征图保留下来,与上采样过程中尺寸相同的特征图沿通道轴连接起来,可以在上采样过程中恢复丢失的背景信息,这样有助于保留更加丰富的纹理。
[0050]
一些经验表明,l1损失能够保证低频结构的正确性,通过使用l1+gan损失能够生成更好的结果。背景补全网络的生成网络损失函数可写为:
[0051]
l
bg
=
‑
e(logd
b
(o
b
,i
s
))+λ
b
||o
b
‑
t
b
||1;
[0052]
其中,o
b
为生成网络的预测结果,t
b
为真实背景图像,i
s
为源风格图像,用g
b
和d
b
分别表示背景重建的生成器和鉴别器,λ
b
是设置为10的平衡因子。
[0053]
背景重建模块的判别网络d采用patchgan,其可以有效的捕捉局部纹理的差别,能够更好分辨生成网络的输出样本和真实值,判别器损失函数如下:
[0054]
l
bd
=
‑
e(logd
b
(t
b
,i
s
)+log(1
‑
d
b
(o
b
,i
s
)))。
[0055]
如图3所示,所述风格文本嵌入模块主要针对前景文本,将目标文本渲染为图像并嵌入重建好的背景中,在相同背景下将源图像的文本风格迁移到目标文本中。
[0056]
为了在重建的背景上插入新的风格目标文本,首先将目标文本使用标准字体与黑色渲染为图像,将之插入背景图像,然后再从源风格图像中迁移文本风格到目标文本。这一部分同样遵循编解码器结构,首先将背景图像与目标文本图像沿深度轴连接,然后经过3个下采样卷积层和4个残差块进行编码,与此同时对源风格图像进行编码,之后将这两个特征图送入自注意力网络sa,该网络能够有效捕捉全局联系,最后将输出的特征图输入3个上采样反卷积解码器网络获得风格文本图像。
[0057]
与背景重建模块中相同,使用gan和l1损失函数,o
f
为生成网络输出的预测结果,t
f
为真实值,i
t
为目标文本图像,用g
f
和d
f
表示风格文本嵌入模块生成器和鉴别器,λ
f
为设置为10的平衡因子,生成器损失l
fg
为:
[0058]
l
fg
=
‑
e(logd
f
(o
f
,i
t
))+λ
f
||t
f
‑
o
f
||1;
[0059]
该模块的鉴别器损失l
fd
如下:
[0060]
l
fd
=
‑
e(logd
f
(t
f
,i
t
)+log(1
‑
d
f
(o
f
,i
t
)))。
[0061]
整个网络以端到端的方式训练,其生成网络总损失l
g
为:
[0062]
l
g
=l
bg
+l
fg
;
[0063]
整个网络的判别网络损失l
d
为:
[0064]
l
d
=l
bd
+l
fd
。
[0065]
遵循gan的训练算法,先训练鉴别器,降低l
d
,再训练生成器,降低l
g
,不断迭代直到收敛,得到生成器g。
[0066]
实施例:
[0067]
为使本发明的目的、技术解决方案、优点更加清晰,下面将结合自然场景图像对本发明做详细说明。
[0068]
系统开发平台为linux操作系统centos7.2,gpu为一块nvidia geforce gtx titan x gpu,识别程序用python3.7编写,使用pytorch1.6框架。
[0069]
由于现实中并不存在文本替换后的成组数据,也没有相关的数据集,训练数据采用合成数据。
[0070]
1、训练数据合成
[0071]
收集字体文件、语料库、无文字图片等数据来生成训练数据。
[0072]
收集中英文词库。从网络中搜集到了一个英文词库(词数16万以上)、一个中文词库thuocl(词数15万以上,为了避免字体文件无法渲染某个中文字符,从词库中删除3500常
用字以外的字符)。
[0073]
收集风格字体文件。google有一个开源的字体文件仓库,可以渲染英文字符,能够有3947个文件用于合成数据。对于中文字符,书写爬虫从chinesefontdesign.com网站下载字体文件,共计1600多个,遴选出531个文件,确保中英文字体风格一致(选择一些中文和英文字符,让每个字体文件都渲染这些字符为图像,观察它们是否风格一致。部分字体文件中文字体有很强的风格,但英文字符却只是普通的黑体,应该予以删除)。
[0074]
收集无文字背景图像。synthtext项目中使用了8000张不包括文字的背景图像,describable textures dataset(dtd)是一个纹理图像数据集,包括5640张图像。
[0075]
如图7、图8所示,一组数据包括4张,依次为i
s
,i
t
,t
b
,t
f
,其中:i
s
为将风格文本a渲染到背景图像上生成的图像,i
t
为将标准文本b渲染到灰色背景上生成的图像,t
b
为背景图像,t
f
为将风格文本b渲染到背景图像上生成的图像。
[0076]
合成过程如图9所示,首先选取字体、文本、背景等参数,然后使用freetype估计文本所占范围、按字符渲染文本为图像surf1与surf2。接下来对surf1与surf2做透视变换,包括旋转、缩放、剪切变换、透视等复杂变换。之后,根据surf1与surf2的最大宽度与最大高度选择足够尺寸的背景图像,裁切产生t
b
,并要将surf1与surf2都调整到与t
b
相同的尺寸。接着使用数据增强库augmentor对前景文字图像执行随机的弹性变形,对背景图像亮度、颜色和对比度变换。
[0077]
为了确定字体颜色,synthtext从iiit5k word dataset中裁剪下来的文字图像中学习得到一个颜色模型,该文件可从github获得。它使用k
‑
means将每个裁剪的单词图像中的像素划分为两组,得到颜色对,其中一种颜色近似于前景(文本)颜色而另一种颜色近似于背景。渲染新文本时,选择背景颜色与目标图像区域最佳匹配的颜色对(使用颜色空间中的l2范数),并使用相应的前景颜色渲染文本。
[0078]
将surf1、surf2渲染到背景图像t
b
时,对2%的文本中每个字符加边框,主要通过opencv中的膨胀函数dilate实现。对2%的文本加阴影,主要使用高斯滤波器gaussianblur对文本进行高斯模糊,然后移动位置。并且为了让背景与前景文本融合更加真实,采用泊松图像编辑技术。
[0079]
为了将替换文本text2渲染为图像,选择微软雅黑为标准字体,并将背景像素值设为127,即上文提到的灰色背景。
[0080]
2、端到端的网络训练参数设置
[0081]
训练数据每组4张图片。批处理大小设置为16,各批次图像高度可统一为64像素,一个批次的图像应该处理为统一大小,高度均为64,宽度使用这一批次的平均值并处理为8的倍数。图片像素值需要规范化为[
‑
1,1]之间(像素值
÷
127.5
‑
1)。由于使用的是pytorch框架,数据输入格式为b
×
c
×
h
×
w。
[0082]
为了提升数据读取速率,消除数据读取瓶颈,设置dataloader中的pin_memory为true,设置num_works为16,但这样会与opencv的多线程发生死锁,在第一个epoch的最后一个batch读完后卡住,无法继续读取数据,可以通过cv2.setnumthreads(0)以及cv2.ocl.setuseopencl(false)关闭opencv的多线程,并在第一个epoch的最后一个batch读完后让程序休眠若干秒。
[0083]
由于生成对抗网络训练不稳定,采用wgan优化。训练过程中,优化器使用rmsprop
算法,学习率配置为10
‑4,判别网络最后一层不使用sigmoid函数,生成网络与判别网络的损失函数不取对数,每次判别网络参数更新后将其参数截断使其绝对值不超过0.01。
[0084]
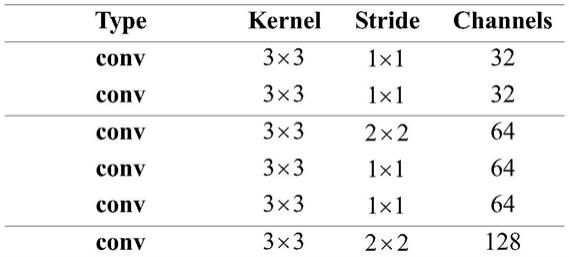
下表1编码器,表2解码器,图10残差块为网络中的基础结构,图11为自注意力网络,应用在风格文本嵌入模块,表3为patchgan判别网络结构,在背景重建和风格文本嵌入两个模块中使用。
[0085]
表1编码器架构图
[0086][0087][0088]
表2解码器架构图
[0089][0090]
表3patchgan架构图
[0091]
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1