基于爬虫的数据采集系统的制作方法
1.本发明涉及计算机信息技术领域。更具体地说,本发明涉及一种基于爬虫的数据采集系统。
背景技术:
2.随着科技的逐步发展,人们已经迈入了“大数据时代”以及“人工智能时代”,然而大数据和人工智能的开发需要非常多的数据支持,数据的来源有很多的渠道。首先是企业所产生的用户数据:百度指数、阿里指数、tbi腾讯浏览指数、新浪微博指数;其次是数据平台购买数据:数据堂、国云数据市场、贵阳大数据交易所;或是政府/机构公开数据:中华人民共和国国家统计局数据、世界银行公开数据、联合国数据、纳斯达克;亦或是数据管理咨询公司:麦肯锡、埃森哲、艾瑞咨询;当然还有爬虫网络数据:如果需要的数据市场没有,或者不愿意购买,则需要使用网络爬虫采集。但是,目前的网络爬虫存在管理不便,用户体验较差的缺陷。因此,亟需设计一种能够一定程度克服上述缺陷的技术方案。
技术实现要素:
3.本发明的一个目的是提供一种基于爬虫的数据采集系统,其使用方便,用户体验好。
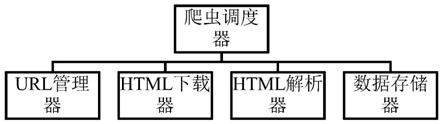
4.为了实现本发明的这些目的和其它优点,本发明提供了基于爬虫的数据采集系统,包括:url管理器,用于获取url链接;html下载器,用于根据所述url链接下载html 网页;html解析器,用于解析所述html网页的源代码,获得网页数据;数据存储器,用于存储所述网页数据。
5.进一步地,还包括:爬虫调度器,用于调度所述url管理器、所述html下载器、所述html解析器和所述数据存储器。
6.优选的是,还包括:客户端,用于接收爬虫任务,并将所述爬虫任务发送至所述爬虫调度器,所述爬虫任务包括所述url链接、爬取参数和期限信息;多个服务器,每个所述服务器内均设置所述url管理器、所述html下载器、所述html解析器和所述数据存储器;其中,所述爬虫调度器还用于将所述爬虫任务分配至多个所述服务器中的一个,并将所述爬虫任务中的所述url链接加入对应的所述url管理器。
7.优选的是,多个所述服务器分别与多个处理队列对应,每个所述处理队列包括依次排队的多个所述爬虫任务;所述爬虫调度器用于将所述爬虫任务加入多个所述处理队列中的一个。
8.优选的是,所述爬虫任务中还包括紧急标志,所述爬虫调度器根据所述紧急标志确定所述爬虫任务在处理队列中的位置;若所述紧急标志为第一紧急标志,则将所述爬虫任务加入至所述处理队列的首位,若所述紧急标志为第二紧急标志,则将所述爬虫任务加入至所述处理队列的末位;若所述处理队列的首位已存在包括所述第一紧急标志的所述爬虫任务,则所述爬虫调度器将其中所述期限信息更近的所述爬虫任务设置为首位。
9.优选的是,所述爬虫调度器间隔设定时间根据所述爬虫任务估算所述处理队列中各所述爬虫任务的所述爬取时长,进而估算各所述爬虫任务的截止时间,并根据所述爬取时长和所述截止时间将位于所述处理队列的末位的所述爬虫任务在各所述处理队列之间切换,以使得各所述处理队列的所述爬虫任务均匹配对应的所述期限信息。
10.优选的是,所述爬虫调度器还记录各所述爬虫任务的实际爬取时长,若与估算的所述爬取时长的差值大于设定阈值,则标记对应的所述url链接;当被标记的所述url链接出现在爬虫任务中时,则结合被记录的实际爬取时长估算所述爬取任务的所述爬取时长。
11.本发明至少包括以下有益效果:
12.本发明设置url管理器获取url链接,设置html下载器根据url链接下载html 网页,设置html解析器解析html网页的源代码,获得网页数据,设置数据存储器存储网页数据。本发明通过将各功能分别用各模块实现,提升了使用便利性和用户体验。
13.本发明的其它优点、目标和特征将部分通过下面的说明体现,部分还将通过对本发明的研究和实践而为本领域的技术人员所理解。
附图说明
14.图1为本发明的架构图。
具体实施方式
15.下面结合附图对本发明做进一步的详细说明,以令本领域技术人员参照说明书文字能够据以实施。
16.应当理解,本文所使用的诸如“具有”、“包含”以及“包括”术语并不排除一个或多个其它元件或其组合的存在或添加。
17.如图1所示,本技术的实施例提供了基于爬虫的数据采集系统,可以选择开发效率比较高的python语言进行开发,由于python的第三方开源库的大而全,因此在高效的开发过程中还能够确保爬虫的稳定性和精确性。具体而言,包括:url管理器,用于获取url 链接,即为获取新url链接提供接口;html下载器,用于根据所述url链接下载html 网页;html解析器,用于解析所述html网页的源代码,获得网页数据,同时也将新的url链接发送给url管理器以及将网页数据发送至存储器;数据存储器,用于存储所述网页数据至本地。本实施例通过将各功能分别用各模块实现,提升了使用便利性和用户体验。
18.在另一种技术方案中,还包括:爬虫调度器,用于管理、调度所述url管理器、所述html下载器、所述html解析器和所述数据存储器,爬虫调度器可以是一服务器。
19.在另一种技术方案中,还包括:客户端,用于接收爬虫任务,并将所述爬虫任务发送至所述爬虫调度器,所述爬虫任务包括所述url链接、爬取参数和期限信息;多个服务器,每个所述服务器内均设置所述url管理器、所述html下载器、所述html解析器和所述数据存储器;其中,所述爬虫调度器还用于将所述爬虫任务分配至多个所述服务器中的一个,并将所述爬虫任务中的所述url链接加入对应的所述url管理器。客户端用于用户提交爬虫任务,并发送至爬虫调度器,爬取参数为爬取数据量、数据类型等,紧急标志为爬虫任务的紧急程度,期限信息则为爬虫任务的规定完成时间,多个服务器并行,分别设置有一网络爬虫,分别根据爬虫任务进行数据爬取、采集,提升了数据爬取效率,每个爬虫任务得到的网
页数据分别存储在各服务器内。
20.在另一种技术方案中,多个所述服务器分别与多个处理队列对应,每个所述处理队列包括依次排队的多个所述爬虫任务;所述爬虫调度器用于将所述爬虫任务加入多个所述处理队列中的一个,这里的爬虫任务加入可根据每个处理队列的爬虫任务的数量确定,使得各处理队列的爬虫任务数量相当。
21.在另一种技术方案中,所述爬虫任务中还包括紧急标志,所述爬虫调度器根据所述紧急标志确定所述爬虫任务在处理队列中的位置;若所述紧急标志为第一紧急标志,则将所述爬虫任务加入至所述处理队列的首位,若所述紧急标志为第二紧急标志,则将所述爬虫任务加入至所述处理队列的末位;若所述处理队列的首位已存在包括所述第一紧急标志的所述爬虫任务,则所述爬虫调度器将其中所述期限信息更近的所述爬虫任务设置为首位。在这些实施例中,将爬虫任务分配至处理队列需要根据爬虫请求中的紧急标志确定,若为第一紧急标志,则表明较为紧急,将其加入处理队列首位,优先进行处理,若为第二紧急标志,则表明不紧急,将其加入处理队列末位,按先到先得的原则进行处理。当具有第一紧急标志的爬虫任务的数量多于服务器的数量,则比较新的爬虫任务与处理队列的首位爬虫任务的期限信息,将期限信息较紧急的爬虫任务放在首位,另一个放在第二位。
22.在另一种技术方案中,所述爬虫调度器间隔设定时间根据所述爬虫任务估算所述处理队列中各所述爬虫任务的所述爬取时长,进而估算各所述爬虫任务的截止时间,并根据所述爬取时长和所述截止时间将位于所述处理队列的末位的所述爬虫任务在各所述处理队列之间切换,以使得各所述处理队列的所述爬虫任务均匹配对应的所述期限信息。
23.在这些实施例中,为了避免新的爬虫任务的加入导致排队的爬虫任务的处理被延迟,爬虫调度器间隔设定时间估算截止时间和爬取时长,截止时间为爬虫任务的处理结束时间点,可根据各爬虫任务的爬取时长确定,爬取时长为爬虫任务的处理时间长度,当发现爬虫任务可能无法在期限内完成时,则对位于处理队列末位的爬虫任务的位置进行变换、调整,使得各爬虫任务均能在规定的时间期限内完成。
24.本实施例还可以包括以下细节,以更好地实现技术效果。当各爬虫任务的实际爬取时长达到估算的爬取时长的1/2时,检测该爬虫任务对应的爬取数据量,爬虫调度器根据爬取数据量对爬取时长进行重新估算,可以经过过往统计结果进行估算,若符合初始估算的爬取时长,则不予处理,若不符合,则根据将重新估算得到的爬取时长,以及对应处理队列中各爬虫任务的爬取时长和截止时间,重新调整位于处理队列末位的爬虫任务,使得各爬虫任务均能在规定的时间期限内完成。
25.在另一种技术方案中,所述爬虫调度器还记录各所述爬虫任务的实际爬取时长,若与估算的所述爬取时长的差值大于设定阈值,则标记对应的所述url链接;当被标记的所述url链接出现在爬虫任务中时,则结合被记录的实际爬取时长估算所述爬取任务的所述爬取时长。在这些实施例中,对于被标记的url链接,下次出现在爬虫任务中时,则结合被记录的实际爬取时长估算爬取时长,比如按比例进行估算。
26.这里说明的设备数量和处理规模是用来简化本发明的说明的。对本发明基于爬虫的数据采集系统的应用、修改和变化对本领域的技术人员来说是显而易见的。
27.尽管本发明的实施方案已公开如上,但其并不仅仅限于说明书和实施方式中所列运用,它完全可以被适用于各种适合本发明的领域,对于熟悉本领域的人员而言,可容易地
实现另外的修改,因此在不背离权利要求及等同范围所限定的一般概念下,本发明并不限于特定的细节和这里示出与描述的图例。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1