一种阻塞流水车间调度问题的改进麻雀搜索优化方法
1.本发明涉及车间调度技术领域,尤其是一种阻塞流水车间调度问题的改进麻雀搜索优化方法。
背景技术:
2.流水车间调度问题广泛存在于汽车、电子、航天材料等加工制造企业中,一个良好的生产计划和调度策略对于工厂降低生产成本、缩短生产周期、提高生产效益具有重要意义。阻塞流水车间是流水产线的机器之间缓存区容量为0,即若某一工件在当前机器完成加工后,后一机器仍处于工作状态,则该工件只能在当前机器上保持停留,直到后一机器处于可用状态为止,这使得下一工件的加工被阻塞;两台机器以上带阻塞的流水车间调度问题已被证明是一个np-hard问题;阻塞流水车间调度目标是找到能够产生最小总加工时间的工件生产序列,提高企业生产效率。
3.阻塞流水车间调度问题可认为是一种组合优化的决策过程;伴随着现代工业生产问题复杂程度的日益增加,传统的优化方法已经很难在规定的时间内得到有效解;近年来兴起的元启发式算法可以在一定程度上替代传统方法获得更高的质量,其调度方案的优劣取决于优化算法的先进程度;国内外学者将各种改进的元启发式算法应用在阻塞流水车间调度问题中;例如,m.abdel-basset等人将鲸鱼优化算法neh混合作为启发式方法来增强开发能力;同样,l.wang等将人工蜂群与可变邻域搜索启发式方法相结合,以提高局部开发能力。
4.麻雀搜索算法(ssa)是2020年提出的一种新型基于群体的智能优化算法,该算法是一种优化能力更强、效率更高的元启发式算法,主要受麻雀种群觅食和反捕食行为启发,麻雀搜索算法已被证明在优化性能上优于灰狼算法、鲸鱼算法、蝙蝠算法、蝗虫优化算法等,目前算法已应用在图像处理、燃料电池和路径规划等领域,并取得了较好的研究成果。将ssa应用于阻塞流水车间调度问题目前存在迭代后期种群多样性减少、算法容易陷入局部最优的问题。
技术实现要素:
5.本发明需要解决的技术问题是提供一种阻塞流水车间调度问题的改进麻雀搜索优化方法,针对阻塞流水车间问题的特点,解决以最小化完工时间为目标的阻塞流水车间调度问题。
6.为解决上述技术问题,本发明所采用的技术方案是:
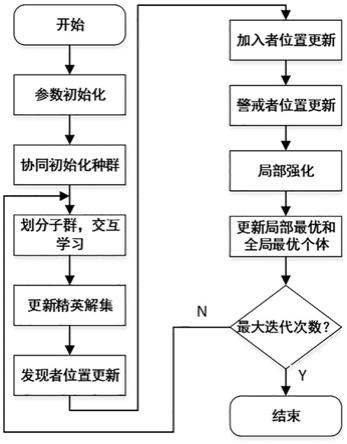
7.一种阻塞流水车间调度问题的改进麻雀搜索优化方法,应用新的种群初始化方案、改进的种群搜索策略、设计的局部强化机制优化阻塞流水车间调度问题,以得到的更好的阻塞流水车间调度方案,提高生产效率;具体过程包括以下步骤:
8.步骤1:参数初始化,麻雀种群初始化;
9.步骤2:平均划分多个子群,并进行交互学习;
10.步骤3:根据适应度值选择并更新精英解集;
11.步骤4:根据改进的发现者位置更新策略更新麻雀种群中发现者个体的位置;
12.步骤5:据改进的加入者位置更新策略更新麻雀种群中发现者个体的位置,即整个麻雀种群中的最优个体和每个子群中的最优个体共同指导加入者位置的更新;
13.步骤6:根据警戒者位置更新策略更新警戒者个体的位置;
14.步骤7:对精英解集中的个体进行局部强化,对精英解集中的个体依次执行三种不同的近邻启发式操作;
15.步骤8:更新局部最优和全局最优个体位置信息;
16.步骤9:是否满足停止条件,满足则转至步骤10;否则,迭代次数加一并转至步骤2;
17.步骤10:输出全局最优麻雀个体位置和适应度值并退出。
18.本发明技术方案的进一步改进在于:步骤1中,具体包括:
19.s1.1已知有一组n个工件来自集合j={1,2,
…
,n}要在m台机器上进行加工m={1,2,
…
,m};每个工件i∈j都有m个操作{o(i,1),o(i,2),
…
,o(i,m)},且每个工件在m个机器上的加工顺序是一样的;每两台机器之间不存在缓存区,如果机器k+1正忙于加工前一个工件,工件i必须在机器k上被阻止,导致该机器也无法加工后续工件;调度目标是找到能够产生最小总加工时间的工件生产序列;
20.s1.2采用整数编码方式对生产序列进行编码处理,麻雀种群中的个体xi=(x
i,1
,x
i,2
,kx
i,n
)的每一维x
i,j
都是0到1之间的实数,将麻雀个体的n个实数按照最小排列准则记录对应顺序并将此顺序序列记为工件生产序列πi;
21.s1.3参数初始化,所述参数包括种群大小sizepop、最大迭代次数maxgen、发现者所占比例p_percent、上界ub、下界lb、动态权重最大值w
max
和最小值w
min
;其中令sizepop=100,maxgen=500,_percent=0.2b=1,lb=0,w
max
=0.9,w
min
=0.6;
22.s1.4采用改进tent混沌映射和设计的基于分解的启发式算法协同使用产生初始化种群,使得初始种群具有预设质量和多样性。
23.本发明技术方案的进一步改进在于:s1.4中,协同初始化方案具体为:
24.s1.4.1改进tent混沌序列
25.作为分段线性的一种一维映射,tent混沌映射具有形式简单、功率谱密度均匀的特点;且tent映射相较于logistic映射遍历性更好,并被证明能够为优化算法产生混沌序列,改进tent混沌映射表达式为:
[0026][0027]
经过贝努力移位变换可表示为:
[0028][0029]
式中,rand(0,1)是[0,1]范围内的随机数,使用改进tent混沌映射产生初始种群时随机生成,根据上式迭代产生整个种群的初始解;np为混沌序列粒子数,xi为第i个麻雀个体;
[0030]
s1.4.2反向学习
[0031]
反向学习思想是对原始解执行反向操作,具体表达式为:
[0032]
x
′i=lb+ub-xi[0033]
式中,lb为麻雀个体搜索空间的下界,ub为麻雀个体搜索空间的上界;
[0034]
应用反向学习思想对已经生成的np个初始解x
np
={x1,x2,...,x
np
}进行反向学习得到np个反向解x'
np
={x
′1,x
′2,...,x
′
np
};将x
np
和x'
np
混合成一个具有2np个初始解的群体,然后根据适应度值排序选出适应度值较小的np个初始解;
[0035]
s1.4.3基于分解的启发式算法
[0036]
1.4.3.1随机初始化np个麻雀个体的初始解;
[0037]
1.4.3.2破坏和重建阶段:在破坏阶段,对每个个体随机选择q个元素移除,q=0.01
×
sizepop
×
n;在重建阶段,移除的作业将按顺序重新插入麻雀个体的随机位置;如果新解适应度值更好,则替换旧的解;否则,保留旧解;
[0038]
1.4.3.3局部细化:对所有麻雀个体执行交换操作;即随机选择麻雀个体的两个元素进行交换,若交换后的适应度值更好则替换当前解,并一直执行下去,直到交换后适应度值不比当前解更好为止;
[0039]
s1.4.4协同使用
[0040]
由于两种方法会生成不同的初始解决方案,所以他们是协同使用的,即np=sizepop/2;一半个体由改进tent混沌映射产生,一半个体由基于分解的启发式算法生成。
[0041]
本发明技术方案的进一步改进在于:步骤2中,具体包括:将种群sizepop平均分为n个子群,子群之间进行交互学习,执行多群动态学习策略;
[0042]
所述多群动态学习策略指的是在每一次迭代中,对大小为sizepop的麻雀种群的n个子群分别进行适应度排序,每个子群中都存在一个最差的个体和一个最优的个体;对每一个子群中最差的个体执行操作:随机在n-1个麻雀子群中选择一个邻域子群,将邻域子群中最优个体的位置信息替换当前最差个体的位置信息,组成新的麻雀种群位置矩阵。
[0043]
本发明技术方案的进一步改进在于:步骤3中,选取各个子群中的最优个体组成精英解集,如麻雀种群大小为sizepop=100,分为十个子群,精英解es={pop1_best,pop2_best,...,pop10_best}。
[0044]
本发明技术方案的进一步改进在于:步骤4中,所述改进的发现者位置更新策略具体表现方式为:
[0045][0046][0047]
式中,表示第t次迭代中麻雀个体i在第j维的位置信息,w为动态权重因子,rands(1)表示生成一个(-1,1)的随机数,q是一个服从正态分布的随机数,l表示元素都为1的大小为1
×
n的矩阵,w
max
是动态权重因子的最大值,w
min
为动态权重因子最小值;
[0048]
改变了当预警值r2小于安全阈值st时的发现者的位置更新公式,并引入了动态权重因子,其随着迭代次数的增加线性的减小,使其在迭代初期具有较大的值,能够更好地进
行全局探索,在迭代后期自适应地减小,从而更好地迚行局部搜索,同时提高收敛速度;
[0049]
本发明技术方案的进一步改进在于:步骤5中,所述改进的加入者位置更新策略具体表现方式为:
[0050]
本过程设置了概率阈值ps,每个加入者个体在每次迭代中都有两种并行的更新方式;随机生成一个随机数rand∈(0,1),若rand《ps,则加入者根据如下公式更新位置:
[0051][0052]
否则,加入者则根据如下公式更新位置:
[0053][0054][0055]
式中,a是一个元素随机赋1或-1的矩阵,矩阵大小为1
×
n,表示第t次迭代时精英解集中随机选择的一个精英个体;x
p
是目前发现者所占据的最优位置,表示当前迭代次数下的全局最差个体,δ表示控制步长,θ表示调整参数,取0.05。
[0056]
本发明技术方案的进一步改进在于:步骤6中,所述警戒者位置更新策略具体包括:
[0057]
假设意识到危险的麻雀占总数量的10%:20%,每次迭代过程中随机在种群中选择10%:20%的个体作为侦察者执行侦查预警行为,则侦察者的位置更新公式如下:
[0058][0059]
式中,为当前全局最优位置;β为步长控制参数,服从(0,1)正态分布;k为[-1,1]范围内的随机数;ε为一个避免出现零除误差的最小常数;fi为表示当前麻雀个体的适应度值;fg为表示当前全局最佳适应度值;fw为表示当前全局最差适应度值;
[0060]
当fi》fg,表示当前麻雀个体处在种群边缘的位置,容易被捕食者所攻击,需要向种群中心靠拢;当fi=fg时,表示处于种群中心的个体意识到危险,需要离开最佳位置向其他麻雀靠拢以减少被捕食的风险。
[0061]
本发明技术方案的进一步改进在于:步骤7中,所述对精英解集中的个体进行局部强化具体过程为:
[0062]
对精英解集中的每个精英个体来说,首先使用插入反向块邻近启发式;其次将概率参数ls应用交换或插入邻近启发式操作;最后设计了一种新的交叉操作;具体来说,三种不同的近邻启发式技术设计如下:
[0063]
(1)插入反向块邻近启发式
[0064]
对于精英个体x_es选取两个不同的随机位置,并反转它们之间的所有作业对,以
产生修改后的新精英个体x_es';每次该启发式检查修改后的新精英个体序列是否优于原始精英个体,如果更好即f(x_es')《f(x_es),则替换原精英个体的解;
[0065]
(2)交换或插入邻近启发式
[0066]
执行插入反向块邻近试探法后,调用交换或插入邻近试探法,我们使用最小二乘参数(使用概率参数ls)来确定选择插入或交换相邻启发式规则的概率,其工作原理如下:
[0067][0068]
式中,insert表示执行插入操作,swap表示执行交换操作,u[0,1]表示从均匀分布中生成一个随机数;
[0069]
在交换邻近试探中,使用最佳改进选择策略,由此精英个体每个位置信息与其他位置信息逐一交换,并且保留导致最佳状态的交换过程;另一方面,插入邻近试探法作为一个移位过程,由此每个被选定的位置被循环移位,并且导致最佳改进的插入位置被选择;
[0070]
(3)精英解集近邻插入
[0071]
这是局部强化的最后一个邻近启发式算法,其工作原理如下:随机确定一个数n1(n1《d),然后在选出的精英个体1和精英个体2中随机固定n1个位置信息,最后将精英个体1中不为这n1个数的其他维度的数依次按顺序插入到精英个体2中;这样形成一个新解,若新解的适应度值好于精英个体2,则替换它。
[0072]
本发明技术方案的进一步改进在于:步骤8中,更新局部最优和全局最优个体位置信息具体为:根据适应度值更新第t次迭代后的每个个体的位置和全局最优解;若第t次迭代后个体xi的适应度值小于第t-1次迭代后的适应度值,则更新xi的位置,否则保持上一代的麻雀个体位置。
[0073]
由于采用了上述技术方案,本发明取得的技术进步是:
[0074]
1、本发明在种群初始化阶段采用改进tent混沌映射和设计的基于分解的启发式算法(h/d)协同初始化种群,与现有的随机初始化种群策略相比,能够获得具有一定质量和多样性的初始种群,有利于加快算法收敛速度。
[0075]
2、本发明在麻雀的搜索更新种群位置过程中,引入了精英解集和多群动态学习策略,可以提高全局搜索的充分性,平衡麻雀算法局部挖掘和全局探索的能力。
[0076]
3、本发明改进了麻雀发现者和加入者个体的位置更新公式,尤其使用全局最优个体和精英解集共同指导加入者的位置更新,能够避免迭代过程中种群多样性降低,使算法具有跳出局部最优解的能力。
[0077]
4、本发明为精英解集设计了3个基于关键解的近邻启发式技术,包括插入反向块、交换或插入、精英解集近邻插入,通过局部增强操作能够提高算法开发能力,克服算法容易陷入局部最优的问题,从而能够得到更好的调度方案。
附图说明
[0078]
图1是本发明的算法流程图;
[0079]
图2是本发明中多群动态学习策略示意图;
[0080]
图3是本发明中插入反向块邻近启发式操作示意图;
[0081]
图4是本发明中交换邻近试探示意图;
[0082]
图5是本发明中插入邻近试探示意图;
[0083]
图6是本发明中精英解集近邻插入邻近试探示意图。
具体实施方式
[0084]
下面结合附图和实施例对本发明做进一步详细说明:
[0085]
如图1所示,一种阻塞流水车间调度问题的改进麻雀搜索优化方法,针对阻塞流水车间问题的特点,解决以最小化完工时间为目标的阻塞流水车间调度问题,该方法把协同初始化种群、多子群动态学习策略、精英解集、局部强化策略融合进麻雀搜索算法中,优化阻塞流水车间调度问题。
[0086]
本发明采用整数-实数混合编码方式对麻雀个体和工件生产序列进行编码;使用一种新的协同初始化策略初始化麻雀个体位置;将麻雀种群分割成多个子群进行相互学习;通过改进的麻雀个体搜索策略求得较好的工件生产序解集即麻雀个体精英解集;对求得的精英解集进行局部增强,求得最优麻雀个体即最优工件加工序列。具体的:
[0087]
1、阻塞流水车间调度问题
[0088]
1.1问题描述
[0089]
具有阻塞的作业调度可以被描述为有一组n个工件来自集合j={1,2,
…
,n}要在m台机器上进行加工m={1,2,
…
,m};每个工件i∈j都有m个操作o(i,1),o(i,2),
…
,o(i,m),且每个工件在m个机器上的加工顺序是一样的。操作o(i,k)表示工件i在机器k上以p(i,k)处理时间执行加工操作。p(i,k)也包括工件在机器间的运输时间。
[0090]
设定每个机器和工件在零时刻都是可用的,一个工件最多只能被一台机器加工,每台机器最多可以处理一个工件,因为每两台机器之间不存在缓存区,所以在操作o(i,k)中,工件i在机器k上完成处理之前不能移动到机器k+1进行处理;如果机器k+1正忙于加工前一个工件,工件i必须在机器k上被阻止,导致该机器也无法加工后续工件。调度目标是找到能够产生最小总加工时间的工件生产序列。
[0091]
1.2数学模型
[0092]
假设我们有一个工件生产序列π={π(1),π(2),...,π(n)}来表示工件处理的顺序,此外,c
i,k
表示工件i离开机器k的时刻;工件生产序列π的最大完工时间可以推导计算如下:
[0093]c1,0
=0
[0094]c1,k
=c
1,k-1
+p
1,k
k∈{1,2,...,m}
[0095]ci,0
=c
i-1,1
i∈{2,3,...,n}
[0096]ci,k
=max{c
i,k-1
+p
i,k
,c
i-1,k+1
}k∈{1,2,...,m-1},i∈{2,3,...,n}
[0097]ci,m
=c
i,m-1
+p
i,m
i∈{2,3,...,n}
[0098]
上式的递推过程中,c
i,0
是第i个工件离开机器0的时刻也就是在第一台机器上开始加工的时刻;c
i,m
是第i个工件离开最后一个机器的时刻即加工完第i个工件的时刻;因为在阻塞流水车间调度问题中,工件在机器上加工完成后要等待下一个机器可用才能释放,所以工件离开机器的时刻比工件在当前机器上的完成加工时刻要大。通过上述循环可以得到订单最终最大完工时间,即目标函数为:
[0099]cmax
(π)=c
n,m
[0100]
式中,c
max
(π)为工件加工序列π的最大完工时间,即第n个工件离开机器m的时刻c
n,m
;
[0101]
以总流水时间为目标的bfsp问题就是找得一个最优工件生产序列π
*
,使得对于任意的序列π,都有c
max
(π
*
)≤c
max
(π)。
[0102]
3.改进麻雀搜索优化方法解决阻塞流水车间调度问题
[0103]
该算法中的种群显示麻雀的位置,并由以下矩阵考虑:
[0104][0105]
式中,d表示决策变量的维数,n表示麻雀的数量,x
i,j
表示第i个麻雀个体的第j维位置信息,i=1,2,...,n;j=1,2,...,d。
[0106]
3.1编码方式
[0107]
采用整数编码方式对生产序列进行编码处理;麻雀种群中的个体xi=(x
i,1
,x
i,2
,kx
i,d
)的每一维x
i,j
都是0到1之间的实数,将麻雀个体的d个实数按照最小排列准则记录对应顺序并将此顺序序列记为工件生产序列πi。例如有6个工件的情况,一个麻雀个体的位置向量可以表示为xi=(0.54,0.24,0.85,0.20,0.35,0.64),则排列后的工件序列可以表示为πi={4,2,5,1,6,3},即先加工工件4,最后加工工件3。
[0108]
3.2参数初始化
[0109]
对算法用到的参数进行初始化,包括种群大小sizepop、最大迭代次数maxgen、发现者所占比例p_percent、上界ub、下界lb、动态权重最大值wmax和最小值wmin;其中令sizepop=100,maxgen=500,_percent=0.2b=1,lb=0,wmax=0.9,wmin=0.6。
[0110]
3.3种群初始化
[0111]
采用改进tent混沌映射和设计的基于分解的启发式算法(h/d)协同使用产生初始化种群,使得初始种群具有一定质量和多样性,种群初始化过程包括四个步骤:
[0112]
3.3.1改进tent混沌序列
[0113]
首先根据如下表达式:
[0114][0115]
产生np(np=sizepop/2)个初始解,其中mod1代表除以1的余数,rand(0,1)是[0,1]范围内的随机数,使用改进tent混沌映射产生初始种群时x0随机生成,根据上式迭代产生np个初始解。
[0116]
3.3.2反向学习
[0117]
反向学习思想是对原始解执行反向操作,具体表达式为:
[0118]
x
′i=lb+ub-xi[0119]
应用反向学习思想对已经生成的np个初始解x
np
={x1,x2,...,x
np
}进行反向学习得到np个反向解x'
np
={x
′1,x'2,...,x'
np
};将x
np
和x'
np
混合成一个具有2np个初始解的群体,然后根据适应度值排序选出适应度值较小的np个初始解。此举可减少优秀解的丢失。
[0120]
3.3.3基于分解的启发式算法(h/d)
[0121]
step1:随机初始化np个麻雀个体的初始解;
[0122]
step2:破坏和重建阶段:在破坏阶段,对每个个体随机选择q个元素移除,q=0.01
×
sizepop
×
n;在重建阶段,移除的作业将按顺序重新插入麻雀个体的随机位置;如果新解适应度值更好,则替换旧的解;否则,保留旧解;
[0123]
step3:局部细化:对所有麻雀个体执行交换操作。即随机选择麻雀个体的两个元素进行交换,若交换后的适应度值更好则替换当前解,并一直执行下去,直到交换后适应度值不比当前解更好为止。
[0124]
3.3.4协同使用由于两种方法会生成不同的初始解决方案,所以他们是协同使用的,即np=sizepop/2;一半个体由改进tent混沌映射产生,一半个体由h/d生成。
[0125]
3.4麻雀种群更新策略
[0126]
3.4.1多群动态学习策略
[0127]
将种群sizepop平均分为n个子群,子群之间进行交互学习,执行多群动态学习策略,附图2为多子群学习策略示意图。
[0128]
在每一次迭代中,对大小为sizepop的麻雀种群的n个子群分别进行适应度排序,每个子群中都存在一个最差的个体和一个最优的个体。对每一个子群中最差的个体执行操作:随机在n-1个麻雀子群中选择一个邻域子群,将邻域子群中最优个体的位置信息替换当前最差个体的位置信息,组成新的麻雀种群位置矩阵。
[0129]
3.4.2精英解集策略
[0130]
选取各个子群中的最优个体组成精英解集,如麻雀种群大小为n=100,分为十个子群,精英解es={pop1_best,pop2_best,...,pop10_best};
[0131]
3.4.3改进的发现者位置更新策略
[0132]
麻雀种群中的发现者个体根据如下表达式进行位置更新:
[0133][0134][0135]
式中,表示第t次迭代中麻雀个体i在第j维的位置信息,w为动态权重因子,rands(1)表示生成一个(-1,1)的随机数,q是一个服从正态分布的随机数,l表示元素都为1的大小为1
×
n的矩阵,w
max
是动态权重因子的最大值,w
min
为动态权重因子最小值。
[0136]
引入了动态权重因子w,其随着迭代次数的增加线性的减小,使其在迭代初期具有较大的值,能够更好地进行全局探索,在迭代后期自适应地减小,从而更好地迚行局部搜索,同时提高收敛速度。
[0137]
3.4.4改进的加入者位置更新策略
[0138]
本过程设置了概率阈值ps,每个加入者个体在每次迭代中都有两种并行的更新方式;随机生成一个随机数rand∈(0,1),若rand《ps,则加入者根据如下公式更新位置:
[0139][0140]
否则,加入者则根据如下公式更新位置:
[0141][0142][0143]
式中,a是一个元素随机赋1或-1的矩阵,矩阵大小为1
×
n,表示第t次迭代时精英解集中随机选择的一个精英个体;x
p
是目前发现者所占据的最优位置,表示当前迭代次数下的全局最差个体,δ表示控制步长,θ表示调整参数,取0.05。
[0144]
3.4.5警戒者位置更新策略
[0145]
假设意识到危险的麻雀占总数量的10%:20%,每次迭代过程中随机在种群中选择10%:20%的个体作为侦察者执行侦查预警行为,则侦察者的位置更新公式如下:
[0146][0147]
式中,为当前全局最优位置;β为步长控制参数,服从(0,1)正态分布;k为[-1,1]范围内的随机数;ε为一个避免出现零除误差的最小常数;fi表示当前麻雀个体的适应度值;fg表示当前全局最佳适应度值;fw表示当前全局最差适应度值;
[0148]
当fi》fg,表示当前麻雀个体处在种群边缘的位置,容易被捕食者所攻击,需要向种群中心靠拢;当fi=fg时,表示处于种群中心的个体意识到危险,需要离开最佳位置向其他麻雀靠拢以减少被捕食的风险
[0149]
3.5局部强化
[0150]
首先使用插入反向块邻近启发式;其次将概率参数ls应用交换或插入邻近启发式操作;最后设计了一种新的交叉操作;具体来说,三种不同的近邻启发式技术设计如下:
[0151]
3.5.1插入反向块邻近启发式
[0152]
对于精英个体x_es选取两个不同的随机位置,并反转它们之间的所有作业对,以产生修改后的新精英个体x_es';每次该启发式检查修改后的新精英个体序列是否优于原始精英个体,如果更好即f(x_es')《f(x_es),则替换原精英个体的解;例如,每个麻雀个体的维度为6,选择位置1和4,则插入反向块邻近启发式操作示意图如附图3。
[0153]
3.5.2交换或插入邻近启发式
[0154]
执行插入反向块邻近试探法后,调用交换或插入邻近试探法,我们使用最小二乘参数(使用概率参数ls)来确定选择插入或交换相邻启发式规则的概率,其工作原理如下:
[0155][0156]
式中,insert表示执行插入操作,swap表示执行交换操作,u[0,1]表示从均匀分布中生成一个随机数;
[0157]
在交换邻近试探中,使用最佳改进选择策略,由此精英个体每个位置信息与其他位置信息逐一交换,并且保留导致最佳状态的交换过程;另一方面,插入邻近试探法作为一个移位过程,由此每个被选定的位置被循环移位,并且导致最佳改进的插入位置被选择。例如,假定精英解包含六个位置信息,即维度d=6,那么一个精英解可以表示为x_es=(x1,x2,x3,x4,x5,x6)。然后将交换操作应用在x2和x5的位置,将产生新的精英解x_es'=(x
′1,x'5,x'3,x'4,x'2,x'6)。另一方面,如果我们在经营个体种应用插入邻近启发操作,将操作应用在在x2和x5的位置,则将产生新的精英解x_es'=(x
′1,x'3,x'4,x'2,x'5,x'6),这在附图4中可见。在插入和交换邻近试探法中,通过使用目标函数检查所得解的可行性,如果它优于原始解,则采用该方法。附图5给出了交换邻近试探的图示。
[0158]
3.5.3精英解集近邻插入
[0159]
这是局部强化的最后一个邻近启发式算法,其工作原理如下:随机确定一个数n1(n1《d),然后在选出的精英个体1和精英个体2中随机固定n1个位置信息,最后将精英个体1中不为这n1个数的其他维度的数依次按顺序插入到精英个体2中;这样形成一个新解,若新解的适应度值好于精英个体2,则替换它。例如精英个体1的位置信息对应的工序排列为x_es1=(4,3,1,5,6,2),精英个体2的位置信息对应的工序排列为x_es2=(1,6,3,4,5,2)。执行近邻插入操作,固定2,3,4三个位置信息,然后将精英个体1中不为2,3,4的数按顺序插入到精英个体2中,示意图如附图6。
[0160]
3.6改进麻雀搜索算法执行流程
[0161]
本发明解决阻塞流水车间调度最大完工时间问题的改进麻雀搜索算法流程图如附图1所示,具体流程如下:
[0162]
步骤1:参数初始化,麻雀种群初始化;
[0163]
步骤2:平均划分多个子群,并进行交互学习;
[0164]
步骤3:根据适应度值选择并更新精英解集;
[0165]
步骤4:发现者位置更新;
[0166]
步骤5:加入者位置更新;
[0167]
步骤6:警戒者位置更新;
[0168]
步骤7:局部强化;
[0169]
步骤8:更新局部最优和全局最优个体位置信息;
[0170]
步骤9:是否满足停止条件,满足则转至步骤10;否则,迭代次数加一并转至步骤2;
[0171]
步骤10:输出全局最优麻雀个体位置和适应度值并退出。
[0172]
4.实验结果与分析
[0173]
本发明公开了一种阻塞流水车间调度问题的改进麻雀搜索优化方法,该发明的效果通过以下实验进一步说明:
[0174]
本实验在cpu为intel(r)core(tm)i5-6300hq cpu@2.30ghz 2.30ghz、运行内存为8.00g的windows 10系统中使用matlab 2018a版本进行了仿真。仿真实验选择了taillard
案例中30个中大规模阻塞流水车间调度问题实例。工件数量分别有50、100;机器数量分别有5、10、20。taillard案例是学者们研究阻塞流水车间调度问题常用的测试集。
[0175]
仿真实验涉及的参数设置如下:种群大小sizepop=100、最大迭代次数maxgen=600、发现者所占比例p_percent=0.2、上界ub=1.0、下界lb=0、动态权重最大值wmax=0.9最小值wmin=0.6,加入者更新方式概率阈值ps=0.7、交换或插入概率参数ls=0.5、子群数量n=10。
[0176]
将改进的麻雀算法(msssa)和基本麻雀搜索算法(ssa)、自适应麻雀搜索算法(assa)、混沌麻雀搜索算法(cssa)、基于动态学习策略的粒子群算法(pso_dls)、随机游走狼群算法(rw_gwo)和二元蝙蝠算法(bba)进行对比测试,分别在30个中大规模的taillard案例上独立运行20次。通过比较各个算法的平均相对误差值来评价算法性能。平均相对误差值即算法运行20次后的平均值和对应案例已知最优值的相对误差。
[0177]
平均相对误差能够很好的反映算法在求具体问题时的有效性。根据表1中所得实验数据可知,除rw_gwo算法在测试集的6个问题中得到了最好的结果外,其余24个问题中本发明所提出的msssa算法较其他现有算法均得到了最好的调度结果。其中每一个问题的最优平均相对误差值都已用黑体表示出来,更好的调度方案可以实现节约生产时间、提高生产效率的目的。
[0178]
综上所述,本发明所提出的msssa算法可以有效实现解决阻塞流水车间调度问题,提高产线生产效率的目的。
[0179]
表1msssa和其他算法平均相对误差值对比
[0180]
[0181][0182]
综上所述,本发明应用新的种群初始化方案、改进的种群搜索策略、设计的局部强化机制等优化阻塞流水车间调度问题,以得到的更好的阻塞流水车间调度方案,提高生产效率;可以解决麻雀算法在迭代后期存在种群多样性减少,算法容易陷入局部最优的问题;可以使阻塞流水车间的加工效率得到有效提升,并提高工厂的经济效益。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1