一种学情数据分析模型训练方法及系统
1.本发明属于人工智能技术领域,涉及一种学情数据分析模型训练方法及系统。
背景技术:
2.随着学校信息化系统的持续建设,各类信息化系统积累了海量的学情数据,通过对这些学情数据进行分析挖掘能够形成学生画像,利用学生的画像数据可以帮助教师掌握学生的学习状态,为提高教师的学生管理水平和教学水平提供数据支撑。
3.学情数据的分析挖掘包括数据采集、数据分析、特征工程、训练模型、模型评估等步骤,学情数据分析的训练模型对于学情分析至关重要。
技术实现要素:
4.本发明的目的在于克服现有技术中的不足,提供一种学情数据分析模型训练方法及系统。
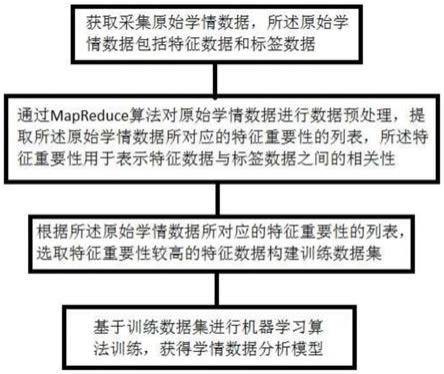
5.第一方面,本发明提供了一种学情数据分析模型训练方法,所述方法包括:
6.获取采集原始学情数据,所述原始学情数据包括特征数据和标签数据;
7.通过mapreduce算法对原始学情数据进行数据预处理,提取所述原始学情数据所对应的特征重要性的列表,所述特征重要性用于表示特征数据与标签数据之间的相关性;
8.根据所述原始学情数据所对应的特征重要性的列表,选取特征重要性较高的特征数据构建训练数据集;
9.基于训练数据集进行机器学习算法训练,获得学情数据分析模型。
10.进一步的,所述特征数据包括班级排名、专业排名、学科排名、处分类型、奖励等级、考勤次数、学科成绩。
11.进一步的,所述标签数据包括学习态度、动手能力、学习动力、学习兴趣。
12.进一步的,所述通过mapreduce算法对原始学情数据进行数据预处理包括以下步骤:
13.在map阶段,读取原始学情数据集文件,将原始学情数据集文件分解为若干小文件,通过计算获得每个小文件所对应的特征数据的特征重要性的列表;
14.在reduce阶段,汇总形成所述原始学情数据所对应的特征重要性的列表。
15.进一步的,所述若干小文件均包括全部特征数据和1个标签数据。
16.进一步的,通过随机森林算法计算获得每个小文件所包含的特征数据的特征重要性列表。
17.第二方面,本发明还提供了一种学情数据分析模型训练系统,所述系统包括:
18.数据获取单元,用于采集获取原始学情数据,所述原始学情数据包括特征数据和标签数据;
19.数据预处理单元,用于通过mapreduce算法对原始学情数据进行数据预处理,提取所述原始学情数据所对应的特征重要性的列表,所述特征重要性用于表示特征数据与标签
数据之间的相关性;
20.模型训练单元:用于根据所述原始学情数据所对应的特征重要性的列表,选取特征重要性较高的特征数据构建训练数据集,基于训练数据集进行机器学习算法训练,获得学情数据分析模型。
21.进一步的,所述数据预处理单元包括控制模块、若干任务模块和算法训练模块;
22.在map阶段,所述控制模块读取原始学情数据集文件,将原始学情数据集文件分解为若干小文件,所述控制模块将所述若干小文件发送至若干任务模块,所述任务模块调用所述算法训练模块计算每个小文件所对应的特征重要性的列表;
23.在reduce阶段,所述若干任务模块将所述若干小文件的特征重要性列表发送给控制模块,所述控制模块汇总形成所述原始学情数据所对应的特征重要性的列表。
24.进一步的,所述若干小文件均包括全部特征数据和1个标签数据。
25.进一步的,通过随机森林算法计算获得每个小文件所包含的特征数据的特征重要性列表。
26.与现有技术相比,本发明的有益效果为:本发明通过mapreduce算法对原始学情数据进行数据预处理,选择特征重要性较高的特征数据构建训练数据集,大大降低训练模型的计算规模和计算时间,提高了模型的训练效率和模型质量。
附图说明
27.图1是本发明实施例学情数据分析模型训练方法流程图;
28.图2是本发明实施例学情数据分析模型训练系统数据预处理单元结构图;
29.图3是本发明实施例学情数据分析模型训练系统数据预处理单元运行流程图。
具体实施方式
30.下面结合附图对本发明作进一步描述。以下实施例仅用于更加清楚地说明本发明的技术方案,而不能以此来限制本发明的保护范围。
31.实施例1:
32.如图1所示,本发明提供了一种学情数据分析模型训练方法,基于mapreduce算法建立学情数据分析模型,具体包括:
33.获取采集原始学情数据cvs文件,原始学情数据包括特征数据和标签数据,特征数据包括班级排名、专业排名、学科排名、处分类型、奖励等级、考勤次数、学科成绩等,标签数据包括学习态度、动手能力、学习动力、学习兴趣,cvs文件可以表示为cvs[x1,x2,
…
,xn,t1,t2,
…
,tm],其中x1,x2,
…
,xn列为特征数据,t1,t2,
…
,tm列为标签数据。
[0034]
在map阶段,读取原始数据集cvs文件,将cvs文件分解为小文件块,小文件块的数量与cvs[x1,x2,
…
,xn,t1,t2,
…
,tm]的标签列的数量相同,每个小文件块由[x1,x2,
…
,xn和某一个标签数据列tk(k的取值范围为[1,m])组成,小文件块可以表示为f《[x1,x2,
…
,xn],tk》(k的取值范围为[1,m]);将f《[x1,x2,
…
,xn],tk]》对应数据的保存到csv数据集fk(k的取值范围为[1,m])中,通过随机森林算法对csv数据集fk进行训练。
[0035]
将数据集fk拆分为训练集feature_train、feature_test和目标集target_train、target_test,然后设置n_estimators、max_depth、min_samples_leaf和max_features等参
数,加载随机森林算法对feature_train,target_train进行拟合运算;最后使用随机森林算法对feature_test进行预测,获得[x1,x2,
…
,xn]对应的特征重要性列表feature_importances,特征重要性列表feature_importances可以表示为fik[《x1,i1》,《x2,i2》,
…
,《xn,in》],其中[i1,i2,
…
,in]为[x1,x2,
…
,xn]对应的特征重要性值。
[0036]
在reduce阶段,创建特征重要性feature_importances矩阵m,然后将收到的所有fik(k的取值范围为[1,m])进行合并,生成feature_importances矩阵m,特征重要性feature_importances矩阵m为n行m列的结构,可表示如下:
[0037]
t1,t2,
…
,tm
[0038]
x1 i11,i12,
…
,i1m
[0039]
x2 i21,i22,
…
,i2m
[0040]
……
,
…
,
…
,
…
[0041]
xn in1,in2,
…
,inm
[0042]
其中矩阵m的数据i11为特征数据x1与标签数据t1对应的feature_importances值,数据i12为特征数据x2与标签数据t2对应的feature_importances值,其他的数据的含义以此类推。
[0043]
对feature_importances矩阵m的元素ipq(p的取值为[1,n],p的取值范围为[1,m])进行筛选,如果元素ipq的值较高,则将对应的特征数据xp和标签数据tq保存到csv文件,根据保存有对应的特征数据xp和标签数据tq的csv文件构建训练数据集,基于训练数据集进行机器学习算法训练,获得学情数据分析模型。
[0044]
实施例2:
[0045]
本发明还提供了一种学情数据分析模型训练系统,包括:
[0046]
数据获取单元,用于采集获取原始学情数据,所述原始学情数据包括特征数据和标签数据;
[0047]
数据预处理单元,用于通过mapreduce算法对原始学情数据进行数据预处理,提取所述原始学情数据所对应的特征重要性的列表,所述特征重要性用于表示特征数据与标签数据之间的相关性;
[0048]
模型训练单元,用于根据所述原始学情数据所对应的特征重要性的列表,选取特征重要性较高的特征数据构建训练数据集,基于训练数据集进行机器学习算法训练,获得学情数据分析模型。
[0049]
具体的,如图2所示,数据预处理单元包括控制模块、若干任务模块和算法训练模块。
[0050]
map阶段:
[0051]
控制模块加载python的pandas库,通过pandas库的read_csv()函数读取原始数据集cvs文件,cvs文件可以表示为cvs[x1,x2,
…
,xn,t1,t2,
…
,tm]。然后将cvs[x1,x2,
…
,xn,t1,t2,
…
,tm]转换为dataframe结构,记录为df[x1,x2,
…
,xn,t1,t2,
…
,tm];控制模块遍历df的所有列,获得所有的标签数据[t1,t2,
…
,tm],然后遍历标签数据[t1,t2,
…
,tm],通过pandas的append()函数将每一列标签数据与[x1,x2,
…
,xn]合并为一个新的dataframe结构,记为小文件块f《[x1,x2,
…
,xn],tk》(k的取值范围为[1,m])。小文件块的数量与标签数据[t1,t2,
…
,tm]的列数m相同;控制模块读取配置文件conf,配置文件记录
了所有任务模块对应的ip和端口。
[0052]
控制模块加载grpc模块,创建grpc通道对象channel,通过channel向所有的任务模块发起rpc请求,建立rpc消息通道。
[0053]
控制模块将小文件块f《[x1,x2,
…
,xn],tk》(k的取值范围为[1,m])封装为protocol buffer消息体,向指定的任务模块发送小文件块f《[[x1,x2,
…
,xn],tk》(k的取值范围为[1,m])。任务模块可以有多个,控制模块按照负载均衡的方式将所有的小文件块f发送给不同的任务模块。
[0054]
任务模块加载grpc模块,创建grpc通道对象channel,调用函数server()在指定端口监听控制模块的发起的grpc请求。收到控制模块发送过来的某个小程序块fk《[x1,x2,
…
,xn],tk]》(k的取值范围为[1,m])后,将小程序块fk转换为datafrma结构,然后调用pandas库的函数to_csv()将该小程序块fk保存到指定目录下,生成csv数据集fk,其中k的取值范围为[1,m]。
[0055]
任务模块向算法训练模块发送训练请求,算法训练模块加载pandas模块,通过函数read_csv()读取csv数据集fk,并将其转换为dataframe结构,记为dfk。
[0056]
算法训练模块加载sklearn模块,然后调用函数train_test_split()将dfk拆分为训练集feature_train、feature_test和目标集target_train、target_test。
[0057]
算法训练模块加载sklearn库,创建随机森林算法randomforestregressor的实例rfr,并设置实例rfr相关的参数n_estimators、max_depth,min_samples_leaf和max_leaf_nodes等。
[0058]
rfr调用sklearn模块的拟合函数fit()对feature_train,target_train进行计算,再使用rfr的函数predict()对feature_test进行预测,生成predict_results。最后调用sklearn模块的函数confusion_matrix(),输入参数target_test和predict_results,生成混淆矩阵conf_mat。
[0059]
算法训练模块获得混淆矩阵conf_mat的精度,判断拟合计算有效,则通过rfr获得特征重要性列表feature_importances,然后将feature_importances封装为训练应答消息返回给任务模块。特征重要性列表feature_importances可以表示为fik[《x1,i1》,《x2,i2》,
…
,《xn,in》],其中[i1,i2,
…
,in]为[x1,x2,
…
,xn]对应的特征重要性值。
[0060]
reduce阶段:
[0061]
任务模块将特征重要性fik[《x1,i1》,《x2,i2》,
…
,《xn,in》]封装为封装为protocol buffer消息体,然后将该消息体通过grpc通道对象channel返回给控制模块。
[0062]
任务模块通过pandas库的函数concat()将收到的所有fik[《x1,i1》,《x2,i2》,
…
,《xn,in》](k的取值范围为[1,m])合并为dataframe结构,该结构即为特征重要性feature_importances矩阵m。
[0063]
任务模块通过pandas库创建空的dataframe结构,记为dft。然后对feature_importances矩阵m的元素ipq(p的取值为[1,n],p的取值范围为[1,m])进行筛选,如果元素ipq的值较高,则将对应的特征数据xp和标签数据tq通过函数concat()插入到到dft中。最后调用pandas库的函数to_csv()将dft保存到指定的csv文件中。
[0064]
本技术是参照根据本技术实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流
程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0065]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0066]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0067]
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1