一种基于transformer的假视频检测方法
1.本发明涉及deepfake检测方法技术领域,具体涉及一种基于transformer的假视频检测方法。
背景技术:
2.deepfake是利用基于深度学习的技术autoencoder、gan等深度学习算法将源视频中的人脸换成目标视频人脸。到目前为止,已经有大量deepfake视频在网上流传,这些视频通常用于损害名人名誉,引导舆论,极大威胁社会稳定。目前常用的deepfake检测方法有迁移学习,注意力机制,以上检测方法是基于有明显造假视觉伪影的假视频设计的,并且只在具有相同操纵算法的内部数据集上检测性能较高,方法泛化性差。利用注意力机制的检测方法可以捕获局部特征间的关系,但没有明显考虑图像不同像素之间的全局关系,因此难以应用普及。
3.现存的deepfake视频通过改进的生成算法合成的假视频质量越来越逼真,并通过添加噪声,形变等使其更接近真实世界的deepfake视频分布。传统的deepfake检测算法不适用于检测改进的生成技术合成的假视频,泛化性较差。因此,deepfake检测面临新挑战并需进一步改善。
技术实现要素:
4.本发明为了克服以上技术的不足,提供了一种首先对一个视频帧的脸图像全局空间信息学习提取空间特征,然后对每帧脸图像空间特征的全局时间信息学习提取时间特征,从而将时间和空间特征结合进行检测deepfake视频的方法。
5.本发明克服其技术问题所采用的技术方案是:
6.一种基于transformer的假视频检测方法,包括如下步骤:
7.a)利用读视频算法对k个视频中的每个视频提取连续的视频帧,利用脸识别算法提取每个视频的连续的视频帧中的人脸图像;
8.b)对人脸图像进行预处理,利用特征提取模块得到人脸的局部特征;
9.c)将特征提取模块提取的人脸的局部特征输入空间视觉transformer模型中,得到该视频帧的人脸图像的全局空间特征;
10.d)将步骤c)得到的人脸图像的全局空间特征输入时间视觉transformer模型中,得到该视频帧的人脸的全局时间空间特征;
11.e)将步骤d)得到的人脸的全局时间空间特征输入分类器经过softmax进行二分类真假检测。
12.进一步的,步骤a)中利用python中的读视频算法videoreader类对视频提取,得到连续的t个视频帧,对提取的视频帧利用人脸识别算法dlib库中的get_frontal_face_detector函数提取脸图像,将得到的脸放入该视频文件夹下,在该视频文件夹下得到连续帧的t张人脸图像。
13.进一步的,步骤a)中得到的连续帧的t张人脸图像的宽高分别调整为224、224,利用均值为[0.4718,0.3467,0.3154],方差为[0.1656,0.1432,0.1364]对人脸图像进行归一化,将归一化后的连续帧的t张人脸图像封装为[b,t,c,h,w]的张量x
i
∈r
b
×
t
×
c
×
h
×
w
,r为向量空间,其中视频标签为[b,0/1],x
i
为第i个视频批次,i∈{1,
…
,k/b},b为每批次视频的个数,c为每张人脸图像通道数,h为每张人脸图像的高,w为每张人脸图像的宽,0表示假视频,1表示真视频。
[0014]
进一步的,步骤b)包括如下步骤:
[0015]
b
‑
1)建立由五个连续的块组成特征提取模块,第一个块、第二个块、第三个块均由三个连续的卷积层和一个最大池化层构成,第三个块和第四个块均由四个连续的卷积层和一个最大池化层构成,每个卷积层均设置有3
×
3的kernel,每个卷积层的stride和padding为1,每个最大池化层均有一个2
×
2像素的窗口,每个最大池化层的步长等于2,第一个块的第一个卷积层有32个通道,第五个块的第四个卷积层有512个通道;
[0016]
b
‑
2)将x
i
∈r
b
×
t
×
c
×
h
×
w
维度变换为[b*t,c,h,w]后输入特征提取模块,输出维度为[b*t,512,7,7]的特征图x
f
=f(x
i
,θ),x
f
∈r
(b*t)
×
c
×
h
×
w
,θ为模型参数。进一步的,步骤c)的步骤为:
[0017]
c
‑
1)将特征图x
f
∈r
(b*t)
×
c
×
h
×
w
沿着通道利用torch库里的reshape函数拉平为二维图像块序列x
p
∈r
(b*t)
×
n
×
(p*q
·
c)
,其中p为二维图像块的宽度,q为二维图像块的高度,n为patch的数量,n=hw/p*q;
[0018]
c
‑
2)通过公式计算得到带有位置信息的二维图像块序列z0,式中为第i个二维图像块,i∈{1,
…
,n},n为二维图像块序列中二维图像块的总数,x
class
为类embedding,e为每一个图像块的位置embedding,e∈r
(p*q
·
c)
×
d
,d为不变的隐向量,e
pos
为位置embedding,e
pos
∈r
(n+1)
×
d
;
[0019]
c
‑
3)设置由l个连续的transformer block组成的空间视觉transformer模型,每个transformer block由多头自注意力block和mlp block组成,多头自注意力block之前为layernorm层,多头自注意力block之后为残差层,mlp block之前为layernorm层,mlp block之后为残差层;
[0020]
c
‑
4)将z0输入第l
‑
1层的transformer block得到带有全局空间信息的二维图像块序列z
l
‑1,l∈{1,
…
,l},将z
l
‑1进行归一化后送入第l层的多头自注意力block进行全局多头注意力计算,得到计算结果msa(ln(z
l
‑1)),通过公式z
′
l
=msa(ln(z
l
‑1))+z
l
‑1计算得到二维全局空间特征z
′
l
,将z
′
l
进行层归一化后送入第l层的mlp block中得到二维空间特征图mlp(ln(z
′
l
)),通过公式z
l
=mlp(ln(z
′
l
))+z
′
l
计算得到第l层的二维空间特征图z
l
,将z
l
输入到第l个transformer block中得到归一化后的视频的人脸图像的全局空间特征z
′
l
∈r
(b*t)
×1×
d
。
[0021]
进一步的,步骤d)包括如下步骤:
[0022]
d
‑
1)将视频的人脸图像的全局空间特征z
′
l
∈r
(b*t)
×1×
d
利用torch库里的reshape函数将其维度变换为z
′
l
∈r
b
×
t
×
d
;
[0023]
d
‑
2)通过公式计算得到带有位置信息的视频帧序列s0,式中为第j个视频,j∈{1,
…
,m},m为视频帧序列中帧总数,z
class
为视频类embedding,u为每一个视频帧的位置embedding,u∈r
d
×
f
,f为视频帧隐向量的维度,u
pos
为位置embedding,u
pos
∈r
(m+1)
×
f
;d
‑
3)设置由l个连续的transformer block组成的时间视觉transformer模型,每个transformer block由多头自注意力block和mlp block组成,多头自注意力block之前为layernorm层,多头自注意力block之后为残差层,mlp block之前为layernorm层,mlp block之后为残差层;
[0024]
d
‑
4)将带有位置信息的视频帧序列s0输入第l
‑
1层的transformer block得到带有全局时间信息的视频帧序列s
l
‑1,l∈{1,
…
,l},将s
l
‑1进行归一化后送入第l层的多头自注意力block进行全局多头注意力计算,得到计算结果msa(ln(s
l
‑1)),通过公式s
′
l
=msa(ln(s
l
‑1))+s
l
‑1计算得到视频全局时间特征s
′
l
,将s
′
l
进行层归一化后送入第l层的mlp block中得到视频全局时间特征mlp(ln(s
′
l
)),通过公式s
l
=mlp(ln(s
′
l
))+s
′
l
计算得到第l层的视频全局时间特征s
l
,将s
l
输入到第l个transformer block中得到归一化后的视频全局空间时间特征表示s
′
l
∈r
b
×1×
f
,利用torch库里的reshape函数将s
′
l
维度变换为s
′
l
∈r
b
×
f
。进一步的,步骤e)中将视频的全局时间空间特征s
′
l
∈r
b
×
f
输入分类器模块的第一个输入维度为f输出维度为2*f的线性层后得到输出结果y,将y输入到分类器模块的第二个输入维度为2*f输出维度为m的线性层后得到模型预测视频类别表示y
′
=s
′
l
w
c
,w
c
∈r
f
×
m
,y
′
∈r
b
×
m
,w
c
为分类器参数,将模型预测视频类别表示y
′
=s
′
l
w
c
经过softmax函数转换为概率值,对y
′
每行元素取最大值索引,索引对应模型预测类别0或1,当模型预测类别为0则该视频为假视频,当模型预测类别为1则该视频为真视频。
[0025]
本发明的有益效果是:通过对一个视频连续帧的脸图像利用空间视觉transformer模型提取全局空间特征,避免了传统检测方法仅提取局部特征而导致泛化性能差,由于假视频通常在时间序列上具有不一致性,所以进一步通过时间视觉transformer模型捕获全局时间特征,从而使空间特征与时间特征结合来提高检测的准确性。适用于各种改进生成算法生成的deepfake检测,检测到的deepfake的准确度明显优于其他方法。
附图说明
[0026]
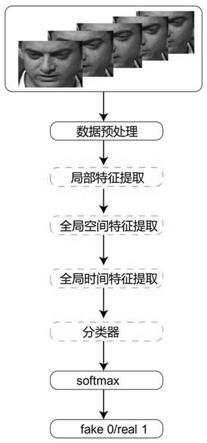
图1为本发明的方法流程图;
[0027]
图2为本发明的局部特征提取模块的流程图;
[0028]
图3为本发明的全局空间特征提取模块流程图;
[0029]
图4为本发明的全局时间特征提取模块流程图;
[0030]
图5为本发明的分类器结构图。
具体实施方式
[0031]
下面结合附图1至附图5对本发明做进一步说明。
[0032]
一种基于transformer的假视频检测方法,包括如下步骤:
[0033]
a)利用读视频算法对k个视频中的每个视频提取连续的视频帧,利用脸识别算法
提取每个视频的连续的视频帧中的人脸图像。
[0034]
b)对人脸图像进行预处理,利用特征提取模块得到人脸的局部特征。
[0035]
c)将特征提取模块提取的人脸的局部特征输入空间视觉transformer模型中,得到该视频帧的人脸图像的全局空间特征。
[0036]
d)将步骤c)得到的人脸图像的全局空间特征输入时间视觉transformer模型中,得到该视频帧的人脸的全局时间空间特征。
[0037]
e)将步骤d)得到的人脸的全局时间空间特征输入分类器经过softmax进行二分类真假检测。
[0038]
由于目前视频层面的检测模型大都首先结合一个视频帧的脸图像局部联系而没有结合全局联系提取特征,然后将特征送入时间特征提取模块,提取帧与帧之间的局部时间信息。因此本发明首先对一个视频帧的脸图像全局空间信息学习提取空间特征,然后对每帧脸图像空间特征的全局时间信息学习提取时间特征,从而将时间和空间特征结合进行检测假视频。基于transformer和fretal学习检测算法。对一个视频连续帧的脸图像利用空间视觉transformer模型提取全局空间特征,避免了传统检测方法仅提取局部特征而导致泛化性能差,由于假视频通常在时间序列上具有不一致性,所以进一步通过时间视觉transformer模型捕获全局时间特征,从而使空间特征与时间特征结合来提高检测的准确性。本发明方法适用于各种改进生成算法生成的deepfake检测,检测到的deepfake的准确度明显优于其他方法。
[0039]
实施例1:
[0040]
步骤a)中利用python中的读视频算法videoreader类对视频提取,得到连续的t个视频帧,对提取的视频帧利用人脸识别算法dlib库中的get_frontal_face_detector函数提取脸图像,将得到的脸放入该视频文件夹下,在该视频文件夹下得到连续帧的t张人脸图像。
[0041]
实施例2:
[0042]
步骤a)中得到的连续帧的t张人脸图像的宽高分别调整为224、224,利用均值为[0.4718,0.3467,0.3154],方差为[0.1656,0.1432,0.1364]对人脸图像进行归一化,将归一化后的连续帧的t张人脸图像封装为[b,t,c,h,w]的张量x
i
∈r
b
×
t
×
c
×
h
×
w
,r为向量空间,其中视频标签为[b,0/1],x
i
为第i个视频批次,i∈{1,
…
,k/b},b为每批次视频的个数,c为每张人脸图像通道数,h为每张人脸图像的高,w为每张人脸图像的宽,0表示假视频,1表示真视频。
[0043]
实施例3:
[0044]
步骤b)包括如下步骤:
[0045]
b
‑
1)建立由五个连续的块组成特征提取模块,第一个块、第二个块、第三个块均由三个连续的卷积层和一个最大池化层构成,第三个块和第四个块均由四个连续的卷积层和一个最大池化层构成,每个卷积层均设置有3
×
3的kernel,每个卷积层的stride和padding为1,每个最大池化层均有一个2
×
2像素的窗口,每个最大池化层的步长等于2,第一个块的第一个卷积层有32个通道,第五个块的第四个卷积层有512个通道。
[0046]
b
‑
2)将x
i
∈r
b
×
t
×
c
×
h
×
w
维度变换为[b*t,c,h,w]后输入特征提取模块,输出维度为[b*t,512,7,7]的特征图x
f
=f(x
i
,θ),x
f
∈r
(b*t)
×
c
×
h
×
w
,θ为模型参数。
[0047]
实施例4:
[0048]
步骤c)的步骤为:
[0049]
c
‑
1)将特征图x
f
∈r
(b*t)
×
c
×
h
×
w
沿着通道利用torch库里的reshape函数拉平为二维图像块序列x
p
∈r
(b*t)
×
n
×
(p*q
·
c)
,其中p为二维图像块的宽度,q为二维图像块的高度,n为patch的数量,n=hw/p*q。
[0050]
c
‑
2)通过公式计算得到带有位置信息的二维图像块序列z0,式中为第i个二维图像块,i∈{1,
…
,n},n为二维图像块序列中二维图像块的总数,x
class
为类embedding,e为每一个图像块的位置embedding,e∈r
(p*q
·
c)
×
d
,d为不变的隐向量,e
pos
为位置embedding,e
pos
∈r
(n+1)
×
d
。具体来说,首先特征提取模块输出的特征图reshape,然后设置每图像块分辨率(7,7),d为1024,将其沿着通道维度拉平二维tokens,维度为[b,t,1,512*7*7],根据公式计算embed to tokens得到特征图维度为[b,t,2,d],利用torch库里的reshape函数将其维度变换为[b*t,2,d]的特征图,接着将其传入空间视觉transformer模型便于为每张图像提取空间特征。
[0051]
c
‑
3)设置由l个连续的transformer block组成的空间视觉transformer模型,每个transformer block由多头自注意力(msa)block和mlp block组成,多头自注意力block之前为layernorm层,多头自注意力block之后为残差层,mlp block之前为layernorm层,mlp block之后为残差层。
[0052]
c
‑
4)将z0输入第l
‑
1层的transformer block得到带有全局空间信息的二维图像块序列z
l
‑1,l∈{1,
…
,l},将z
l
‑1进行归一化后送入第l层的多头自注意力block进行全局多头注意力计算,得到计算结果msa(ln(z
l
‑1)),通过公式z
′
l
=msa(ln(z
l
‑1))+z
l
‑1计算得到二维全局空间特征z
′
l
,将z
′
l
进行层归一化后送入第l层的mlp block中得到二维空间特征图mlp(ln(z
′
l
)),通过公式z
l
=mlp(ln(z
′
l
))+z
′
l
计算得到第l层的二维空间特征图z
l
,将z
l
输入到第l个transformer block中得到归一化后的视频的人脸图像的全局空间特征z
′
l
∈r
(b*t)
×1×
d
。
[0053]
实施例5:
[0054]
步骤d)包括如下步骤:
[0055]
d
‑
1)将视频的人脸图像的全局空间特征z
′
l
∈r
(b*t)
×1×
d
利用torch库里的reshape函数将其维度变换为z
′
l
∈r
b
×
t
×
d
。
[0056]
d
‑
2)通过公式计算得到带有位置信息的视频帧序列s0,式中为第j个视频,j∈{1,
…
,m},m为视频帧序列中帧总数,z
class
为视频类embedding,u为每一个视频帧的位置embedding,u∈r
d
×
f
,f为视频帧隐向量的维度,u
pos
为位置embedding,u
pos
∈r
(m+1)
×
f
。
[0057]
d
‑
3)设置由l个连续的transformer block组成的时间视觉transformer模型,每个transformer block由多头自注意力block和mlp block组成,多头自注意力block之前为
layernorm层,多头自注意力block之后为残差层,mlp block之前为layernorm层,mlp block之后为残差层。
[0058]
d
‑
4)将带有位置信息的视频帧序列s0输入第l
‑
1层的transformer block得到带有全局时间信息的视频帧序列s
l
‑1,l∈{1,...,l},将s
l
‑1进行归一化后送入第l层的多头自注意力block进行全局多头注意力计算,得到计算结果msa(ln(s
l
‑1)),通过公式s
′
l
=msa(ln(s
l
‑1))+s
l
‑1计算得到视频全局时间特征s
′
l
,将s
′
l
进行层归一化后送入第l层的mlp block中得到视频全局时间特征mlp(ln(s
′
l
)),通过公式s
l
=mlp(ln(s
′
l
))+s
′
l
计算得到第l层的视频全局时间特征s
l
,将s
l
输入到第l个transformer block中得到归一化后的视频全局空间时间特征表示s
′
l
∈r
b
×1×
f
,利用torch库里的reshape函数将s
′
l
维度变换为s
′
l
∈r
b
×
f
。
[0059]
实施例6:
[0060]
步骤e)中将视频的全局时间空间特征s
′
l
∈r
b
×
f
输入分类器模块的第一个输入维度为f输出维度为2*f的线性层后得到输出结果y,将y输入到分类器模块的第二个输入维度为2*f输出维度为m的线性层后得到模型预测视频类别表示y
′
=s
′
l
w
c
,w
c
∈r
f
×
m
,y
′
∈r
b
×
m
,w
c
为分类器参数,将模型预测视频类别表示y
′
=s
′
l
w
c
经过softmax函数转换为概率值,对y
′
每行元素取最大值索引,索引对应模型预测类别0或1,当模型预测类别为0则该视频为假视频,当模型预测类别为1则该视频为真视频。
[0061]
最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1