基于flink的高效同步实时数据到ClickHouse的方法及装置与流程
基于flink的高效同步实时数据到clickhouse的方法及装置
技术领域
1.本发明属于数据库技术领域,具体涉及一种基于flink的高效同步实时数据到clickhouse的方法及装置。
背景技术:
2.clickhouse是近年来备受关注的开源列式数据库,主要用于数据分析(olap)领域。使用clickhouse实时数据分析的首要条件是实现将数据从业务数据库实时同步到clickhouse中,业务数据库例如可为mysql数据库、阿里云的rds这种类mysql数据库等。数据实时同步是将数据从源数据库迁移至目的数据库,实时数据实时同步则是保证源数据库和目的数据库在全量数据的基础上实时保持一致的过程。
3.然而,clickhouse像elasticsearch一样具有数据分片(shard)的概念,这也是分布式存储的特点之一,即通过并行读写提高效率。clickhouse依靠distributed引擎实现了distributed(分布式)表机制,在所有分片(本地表)上建立视图进行分布式查询。
4.distributed表引擎自身不会存储任何数据,在集群内部自动开展数据的写入、分发、查询、路由等工作;通过读取或写入其他远端节点上的表进行数据处理的表引擎。为此,clickhouse需要先将数据写入到分布式表再同步到本地表,存在很大的性能问题。
技术实现要素:
5.本发明的目的是要解决上述的技术问题,提供一种基于flink的高效同步实时数据到clickhouse的方法及装置。
6.为了解决上述问题,本发明按以下技术方案予以实现的:
7.第一方面,本发明提供了一种基于flink的高效同步实时数据到clickhouse的方法,应用于flink分布式框架,所述方法包括如下步骤:
8.获取源数据库的变化数据,根据变化数据的操作类型,用相匹配的数据插入操作方式将变化数据储存;
9.当检测到源数据库同步数据操作被触发时,将变化数据加载至clickhouse中,具体包括:
10.检测用户配置为写入本地表时,查询clickhouse集群中所有分片的链接列表;
11.基于预设分片规则,从链接列表中查找对应分片的机器;
12.将变化数据写入对应分片的机器的本地表中。
13.结合第一方面,本发明还提供了第一方面的第1种优选实施方式,基于预设分片规则,从链接列表中查找对应分片的机器,具体包括:
14.获取链接列表中的分片连接,基于轮训、随机或哈希的查询方式在分片连接中确定对应分片的机器;
15.所述查询方式根据变化数据的主键,基于一致性哈希算法确定对应分片的机器。
16.结合第一方面,本发明还提供了第一方面的第2种优选实施方式,所述用户配置可
指定目标分片和目标本地表,将变化数据根据预设分片规则直接写入到用户配置的目标本地表。
17.结合第一方面,本发明还提供了第一方面的第3种优选实施方式,根据变化数据的操作类型,用相匹配的数据插入操作方式将变化数据储存,具体包括:
18.预设所述数据插入操作方式包括生成插入语句、设置标记位的值和设置版本号;
19.解析变化数据的操作类型,根据操作类型生成插入语句,插入语句包括删除标记位;
20.根据操作类型,设置插入语句中的删除标记位的值,生成操作语句;
21.设置操作语句的版本号。
22.结合第一方面,本发明还提供了第一方面的第4种优选实施方式,所述生成插入语句包括:
23.若操作类型为数据插入操作,设置删除标记位为新增标识,生成一条插入语句;
24.若操作类型为数据删除操作,设置删除标记位为删除标识,生成一条插入语句;
25.若操作类型为数据更新操作,则将更新前和更新后的数据,分别生成两条新增语句,设置更新前的数据的删除标记位为删除标识,设置更新后的数据的删除标记位为新增标识。
26.结合第一方面,本发明还提供了第一方面的第5种优选实施方式,所述设置标记位的值包括:
27.若操作类型为数据插入操作,将删除标记位设置为,用户配置中新增标识对应的删除标记位的值,若用户配置没有设定,则默认为1;
28.若操作类型为数据删除操作,将删除标记位设置为,用户配置中删除标识对应的删除标记位的值,若用户配置没有设定,则默认为-1;
29.若操作类型为数据更新操作,分别将更新前和更新后的数据的删除标记位,设置为用户配置中的新增标识和删除标识对应的值,若用户配置没有设定,则设置默认值。
30.结合第一方面,本发明还提供了第一方面的第7种优选实施方式,所述设置版本号包括:
31.判断变化数据的版本号字段是否存在于源数据库的表中;
32.若是,则将源表数据的值设置为版本号;
33.若否,则将源表数据的哈希值设置为版本号。
34.结合第一方面,本发明还提供了第一方面的第8种优选实施方式,
35.所述源数据库同步数据操作包括自动触发条件,在检测到源数据库满足数据导入的自动触发条件时,从flink分布式框架中将变化数据写入至clickhouse中;
36.所述触发条件包括当检测到变化数据的操作记录数达到预设次数阈值或检测到当前时刻满足预设周期,将变化数据加载至clickhouse中。
37.第二方面,本发明还提供了一种基于flink的高效同步实时数据到clickhouse的装置,应用于flink分布式框架,所述装置包括:
38.获取模块,其用于获取源数据库的变化数据;
39.转换模块,其用于根据变化数据的操作类型,用相匹配的数据插入操作方式将变化数据储存;
40.配置模块,其用于设置用户配置;
41.本地表写入模块,其用于当检测到源数据库同步数据操作被触发时,将变化数据加载至clickhouse中,具体包括:
42.检测用户配置为写入本地表时,查询clickhouse集群中所有分片的链接列表;
43.基于预设分片规则,从链接列表中查找对应分片的机器;
44.将变化数据写入对应分片的机器的本地表中。
45.结合第二方面,本发明还提供了第二方面的第1种优选实施方式,所述转换模块基于预设分片规则,从链接列表中查找对应分片的机器,具体执行如下操作:
46.获取链接列表中的分片连接,基于轮训、随机或哈希的查询方式在分片连接中确定对应分片的机器;
47.所述查询方式根据变化数据的主键,基于一致性哈希算法确定对应分片的机器。
48.结合第二方面,本发明还提供了第二方面的第2种优选实施方式,根据变化数据的操作类型,用相匹配的数据插入操作方式将变化数据储存,具体包括:
49.预设所述数据插入操作方式包括生成插入语句、设置标记位的值和设置版本号;
50.解析变化数据的操作类型,根据操作类型生成插入语句,插入语句包括删除标记位;
51.根据操作类型,设置插入语句中的删除标记位的值,生成操作语句;
52.设置操作语句的版本号;
53.其中,所述生成插入语句包括:
54.若操作类型为数据插入操作,设置删除标记位为新增标识,生成一条插入语句;
55.若操作类型为数据删除操作,设置删除标记位为删除标识,生成一条插入语句;
56.若操作类型为数据更新操作,则将更新前和更新后的数据,分别生成两条新增语句,设置更新前的数据的删除标记位为删除标识,设置更新后的数据的删除标记位为新增标识;
57.其中,所述设置标记位的值包括:
58.若操作类型为数据插入操作,将删除标记位设置为,用户配置中新增标识对应的删除标记位的值,若用户配置没有设定,则默认为1;
59.若操作类型为数据删除操作,将删除标记位设置为,用户配置中删除标识对应的删除标记位的值,若用户配置没有设定,则默认为-1;
60.若操作类型为数据更新操作,分别将更新前和更新后的数据的删除标记位,设置为用户配置中的新增标识和删除标识对应的值,若用户配置没有设定,则设置默认值;
61.其中,所述设置版本号包括:
62.判断变化数据的版本号字段是否存在于源数据库的表中;
63.若是,则将源表数据的值设置为版本号;
64.若否,则将源表数据的哈希值设置为版本号。
65.与现有技术相比,本发明的有益效果是:
66.本技术的查询clickhouse集群中所有分片的链接列表,基于预设分片规则,从链接列表中查找对应分片的机器,将变化数据写入对应分片的机器的本地表中。现有的flink不支持按照分片规则写入本地表的方式,数据写入到分布式表再同步到本地表存在很大的
性能问题。本发明提供了直接将数据写入本地表的技术手段,而避免通过分布式表再写入本地表中,写入速度极大提升,且不存在数据一致性的问题。
附图说明
67.下面结合附图对本发明的具体实施方式作进一步详细的说明,其中:
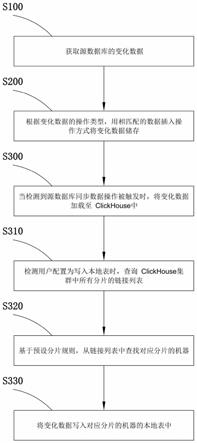
68.图1是本发明的基于flink的高效同步实时数据到clickhouse的方法的流程示意图;
69.图2是本发明的基于flink的高效同步实时数据到clickhouse的方法的流程示意总图;
70.图3是本发明的基于flink的高效同步实时数据到clickhouse的装置的组成图。
具体实施方式
71.以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
72.clickhouse是近年来备受关注的开源列式数据库,主要用于数据分析(olap)领域。目前国内社区火热,纷纷跟进大规模使用:
73.如今日头条的内部用clickhouse来做用户行为分析,内部一共几千个clickhouse节点,单集群最大1200节点,总数据量几十pb,日增原始数据300tb左右。腾讯内部用clickhouse做游戏数据分析,并且为之建立了一整套监控运维体系。携程内部从18年7月份开始接入试用,目前80%的业务都跑在clickhouse上,每天数据增量十多亿,近百万次查询请求。快手内部也在使用clickhouse,存储总量大约10pb,每天新增200tb,90%查询小于3s。
74.olap类业务对于事务需求较少,通常是导入历史日志数据,或搭配一款事务型数据库并实时从事务型数据库中进行数据同步。
75.经申请人研究发现,clickhouse依靠distributed引擎实现了distributed(分布式)表机制,在所有分片(本地表)上建立视图进行分布式查询。distributed表引擎自身不会存储任何数据,在集群内部自动开展数据的写入、分发、查询、路由等工作;通过读取或写入其他远端节点上的表进行数据处理的表引擎。为此,clickhouse需要先将数据写入到分布式表再同步到本地表,存在很大的性能问题,主要包括:
76.(1)性能问题:分布式表引擎需要依赖各个节点的本地表来创建,数据写入分布式表的时候,会创建一个临时表存储数据,然后将数据发送到本地表,如果数据量很大的情况下,会受制于转发的机器的性能,存在单点问题,并且数据经过中间层转发,速度受限于机器网络的速度,多一层转发,速度就会受阻。分布式表接收到数据后会将数据拆分成多个parts,并转发数据到其它服务器,会引起服务器间网络流量增加、服务器merge的工作量增加,导致写入速度变慢,并且增加了其他问题的可能性。
77.当业务数据量日增极大时,分布式表在写入时会在本地节点生成临时数据,会产生写放大,对cpu及内存造成一些额外消耗;分布式表写的临时block会把原始block根据sharding_key和weight进行再次拆分,会产生更多的block分发到远端节点,也增加了merge的负担。
78.(2)数据一致性问题:数据先在分布式表所在的机器进行落盘,然后异步的发送到本地表所在机器进行存储,中间没有一致性的校验,而且在分布式表所在机器时如果机器出现问题,会存在数据丢失风险。同时,数据写入默认是异步的,短时间内可能造成不一致的问题。
79.为此,本发明提供了一种基于flink的高效同步实时数据到clickhouse的方法,应用于flink分布式框架,所述方法包括如下步骤:获取源数据库的变化数据,根据变化数据的操作类型,用相匹配的数据插入操作方式将变化数据储存;当检测到源数据库同步数据操作被触发时,将变化数据加载至clickhouse中,具体包括:检测用户配置为写入本地表时,查询clickhouse集群中所有分片的链接列表;基于预设分片规则,从链接列表中查找对应分片的机器;将变化数据写入对应分片的机器的本地表中。本发明提供了一种创新的直接将数据写入本地表的技术手段,而避免通过分布式表再写入本地表中,写入速度极大提升,且不存在数据一致性的问题。
80.如图2所述,本发明所述基于flink的高效同步实时数据到clickhouse的方法的总流程示意图。
81.如图1所述,本发明所述基于flink的高效同步实时数据到clickhouse的方法的流程示意图。本方法应用于flink分布式框架,所述方法包括如下步骤:
82.s100:获取源数据库的变化数据。
83.在本发明中,变化数据的捕获可简称cdc,cdc大体分为两种:侵入式和非侵入式。常用的4种cdc方法是:基于时间戳的cdc、基于触发器的cdc、基于快照的cdc和基于日志的cdc,其中前三种是侵入式的。
84.s200:根据变化数据的操作类型,用相匹配的数据插入操作方式将变化数据储存,
85.经申请人研究发现,clickhouse实时数据分析的首要条件是实现将数据从业务数据库实时同步到clickhouse中,业务数据库例如可为mysql数据库、阿里云的rds这种类mysql数据库等。
86.而现有flinkcdc的支持sql方式的同步方式,无法支持源表且没有相应的版本号和删除标记字段;在此情况下插入数据库的时候,无法生成自动有效的版本号值和删除标记字段值。同时,不支持将源数据表的增删改,统一转换为带有版本号和标记字段的插入的方式,在clickhouse上面做更新和删除操作存在很大性能。
87.在本发明一种优选实例中,根据变化数据的操作类型,用相匹配的数据插入操作方式将变化数据储存,具体包括:预设所述数据插入操作方式包括生成插入语句、设置标记位的值和设置版本号。
88.在一种实例中,源数据库是待处理数据的存储位置,clickhouse作为目的数据库作为待处理数据即将要迁移的位置,通过flink分布式框架读取中变化数据,然后调用flink分布式框架中的解析器如binlogmt reader来解析数据,并通过flink分布式框架中的数据处理器如clickhouse writer将解析的数据进行转换后写入clickhouse中。若源数据库为mysql,则对数据发生或潜在发生更改的sql语句,并以二进制的形式保存在磁盘中。
89.s210:解析变化数据的操作类型,根据操作类型生成插入语句,插入语句包括删除标记位;
90.s220:根据操作类型,设置插入语句中的删除标记位的值,生成操作语句;
91.s230:设置操作语句的版本号。
92.为此,本发明通过步骤s210-s240解决上述技术问题。使用flink分布式框架将源数据库的插入、更新、删除的数据均可进行转换和传输,实现了源端到目的端clickhouse的端到端的高性能数据实时同步,保证端到端的数据一致性,解决相关技术长时间处理极易出现数据同步不一致的现象,有效提升数据同步的实时性能,满足高性能的实时同步需求;此外,更新操作拆分为两条插入操作,更新前的记录带有删除标记位,更新后的记录带有新增标记位,支持版本号标识当前数据的版本。
93.clickhouse由于是列式存储的数据库,clickhouse的数据同步包括实时同步都仅支持插入数据,而不支持数据的修改和删除。而源数据库如随机读写的行式数据库mysql数据库,不可避免地有大量的更新和删除数据的操作,针对这一点,本实施例可利用clickhouse的replacing merge tree引擎,实现了实时同步mysql的数据插入、更新和删除操作,保证端到端的数据一致性,而不是仅支持数据的插入。
94.s300:当检测到源数据库同步数据操作被触发时,将变化数据加载至clickhouse中,具体包括:
95.s310:检测用户配置为写入本地表时,查询clickhouse集群中所有分片的链接列表。
96.在分布式模式下,clickhouse会将数据分为多个分片,并且分布到不同节点上。数据分片,让clickhouse可以充分利用整个集群的大规模并行计算能力,快速返回查询结果。当用户配置为吸入本地表时,先查找出集群中所有的分片的机器的链接,用户配置的要写入的clickhouse的表写为本地表的表名。
97.支持同步的时候指定分片选择方式,可以将数据按照分片规则直接写入到用户配置的本地表,并且只需要配置clickhouse集群中任意一个节点接入的链接即可。
98.s320:基于预设分片规则,从链接列表中查找对应分片的机器。
99.本发明通过指定的分片算法,来定位到集群中的具体分片的机器。在一种实施中,基于预设分片规则,从链接列表中查找对应分片的机器,具体包括:
100.获取链接列表中的分片连接,基于轮训、随机或哈希的查询方式在分片连接中确定对应分片的机器。所述查询方式根据变化数据的主键,基于一致性哈希算法确定对应分片的机器。
101.在一种优选实施中,所述用户配置可指定目标分片和目标本地表,将变化数据根据预设分片规则直接写入到用户配置的目标本地表。
102.s330:将变化数据写入对应分片的机器的本地表中。完成将数据写入到对应分片的机器的连接。
103.在数据同步过程中,为了实现将所有类型的增量数据均实时更新,clickhouse中实时同步的本地表可使用versionedcollapsingmergetree或replicatedversionedcollapsingmergetree的数据引擎,进行更高效的处理,并且可以处理数据乱序到达的问题,而现有技术无法解决数据乱序到达的问题。
104.为了减少数据频繁写入造成资源占用太大带来的不利影响,同时还需要保证数据实时保持一致,满足实时大数据量同步的需求,避免长时间处理带来的数据不一致。可预先设置源数据库同步数据操作的自动触发条件,在检测到源数据库的满足数据导入的自动触
发条件时,从flink分布式框架中将变化数据写入至clickhouse中。
105.在一种实例中,触发条件例如可为:读取批量设置的时间和记录数,如果只存在一个,则按照当前的配置进行批量写入操作,如果两个都存在则按照最先命中的批量条件进行批量写入操作。
106.具体的,当检测到源数据库中变化数据的操作记录数达到预设次数阈值或检测到当前时刻到达checkpoint周期,将数据加载至clickhouse中。此外,flink分布式框架还可以根据实际需要调整并发度,进一步满足高性能的实时同步需求。
107.在一种优选实施中,步骤s210:解析变化数据的操作类型,根据操作类型生成插入语句,插入语句包括删除标记位中,所述生成插入语句具体包括:
108.若操作类型为数据插入操作,设置删除标记位为新增标识,生成一条插入语句;
109.若操作类型为数据删除操作,设置删除标记位为删除标识,生成一条插入语句;
110.若操作类型为数据更新操作,则将更新前和更新后的数据,分别生成两条新增语句,设置更新前的数据的删除标记位为删除标识,设置更新后的数据的删除标记位为新增标识。
111.在一种优选实施中,步骤s220:根据操作类型,设置插入语句中的删除标记位的值,所述生成操作语句具体包括:
112.若操作类型为数据插入操作,将删除标记位设置为,用户配置中新增标识对应的删除标记位的值,若用户配置没有设定,则默认为1;
113.若操作类型为数据删除操作,将删除标记位设置为,用户配置中删除标识对应的删除标记位的值,若用户配置没有设定,则默认为-1;
114.若操作类型为数据更新操作,分别将更新前和更新后的数据的删除标记位,设置为用户配置中的新增标识和删除标识对应的值,若用户配置没有设定,则设置默认值。
115.在一种优选实施中,s230:设置操作语句的版本号中,所述设置版本号包括:
116.判断变化数据的版本号字段是否存在于源数据库的表中;
117.若是,则将源表数据的值设置为版本号;
118.若否,则将源表数据的哈希值设置为版本号。
119.如图3所示,本发明还提供了基于flink的高效同步实时数据到clickhouse的装置,应用于flink分布式框架,本装置用于实现上述方法的步骤。具体的,所述装置包括:
120.获取模块,其用于获取源数据库的变化数据;
121.转换模块,其用于根据变化数据的操作类型,用相匹配的数据插入操作方式将变化数据储存;
122.配置模块,其用于设置用户配置;
123.本地表写入模块,其用于当检测到源数据库同步数据操作被触发时,将变化数据加载至clickhouse中,具体包括:
124.检测用户配置为写入本地表时,查询clickhouse集群中所有分片的链接列表;
125.基于预设分片规则,从链接列表中查找对应分片的机器;
126.将变化数据写入对应分片的机器的本地表中。
127.在一种优先实施中,所述转换模块基于预设分片规则,从链接列表中查找对应分片的机器,具体执行如下操作:
128.获取链接列表中的分片连接,基于轮训、随机或哈希的查询方式在分片连接中确定对应分片的机器;
129.所述查询方式根据变化数据的主键,基于一致性哈希算法确定对应分片的机器。
130.在一种优先实施中,根据变化数据的操作类型,用相匹配的数据插入操作方式将变化数据储存,具体包括:
131.预设所述数据插入操作方式包括生成插入语句、设置标记位的值和设置版本号;
132.解析变化数据的操作类型,根据操作类型生成插入语句,插入语句包括删除标记位;
133.根据操作类型,设置插入语句中的删除标记位的值,生成操作语句;
134.设置操作语句的版本号;
135.其中,所述生成插入语句包括:
136.若操作类型为数据插入操作,设置删除标记位为新增标识,生成一条插入语句;
137.若操作类型为数据删除操作,设置删除标记位为删除标识,生成一条插入语句;
138.若操作类型为数据更新操作,则将更新前和更新后的数据,分别生成两条新增语句,设置更新前的数据的删除标记位为删除标识,设置更新后的数据的删除标记位为新增标识;
139.其中,所述设置标记位的值包括:
140.若操作类型为数据插入操作,将删除标记位设置为,用户配置中新增标识对应的删除标记位的值,若用户配置没有设定,则默认为1;
141.若操作类型为数据删除操作,将删除标记位设置为,用户配置中删除标识对应的删除标记位的值,若用户配置没有设定,则默认为-1;
142.若操作类型为数据更新操作,分别将更新前和更新后的数据的删除标记位,设置为用户配置中的新增标识和删除标识对应的值,若用户配置没有设定,则设置默认值;
143.其中,所述设置版本号包括:
144.判断变化数据的版本号字段是否存在于源数据库的表中;
145.若是,则将源表数据的值设置为版本号;
146.若否,则将源表数据的哈希值设置为版本号。
147.以上所述,仅是本发明的较佳实施例而已,并非对本发明作任何形式上的限制,故凡是未脱离本发明技术方案内容,依据本发明的技术实质对以上实施例所作的任何修改、等同变化与修饰,均仍属于本发明技术方案的范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1