基于空间尺度延展与数据融合的城乡垃圾产量预测方法
1.本发明属于环境技术领域,具体涉及基于空间尺度延展与数据融合的城乡垃圾产量预测方法。
背景技术:
2.垃圾的宏观规划管理,已经在国内外发展成为重要的新兴产业,引发了广泛的关注。近年来,我国农村垃圾的产生量,已经达到了2亿吨/年之巨。为了满足村镇场景下卫生环境的精细化管理建设需求,有必要将垃圾相关数据的量级,进行时间与空间尺度上的细化分析。
3.在社会统计空间化分析过程中,由于农村垃圾产生量少、分散、组分复杂,垃圾空间产生分布特征未明确,基础管理数据缺乏,数据管理断链的现实状况,所以难以进行行之有效的数据分析与产量预测;并且,传统的垃圾数据统计方法往往基于车次以及载重来进行统计,难以追溯至具体地理单元以及村民聚落的垃圾产生状况,所以有必要形成相关方法,以便服务于村镇垃圾收运设置装置的提前布局。
技术实现要素:
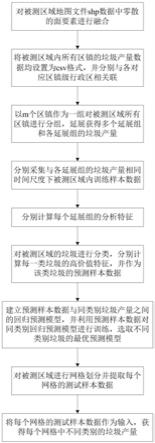
4.为解决上述背景技术中提出的问题。本发明提供了基于空间尺度延展与数据融合的城乡垃圾产量预测方法,具有解决某些地区垃圾分布特征不明确、缺乏基础管理数据不易管理,进而导致难以对产量进行预测问题的特点。
5.为实现上述目的,本发明提供如下技术方案:基于空间尺度延展与数据融合的城乡垃圾产量预测方法,包括以下步骤:
6.s1:从开源网络中获取被测区域地图文件shp数据,利用geoscene pro2.1软件的融合功能对被测区域地图文件shp数据中零散的面要素进行融合,使得被测区域内每个区镇都由单独的面要素构成;
7.s2:将被测区域内所有区镇不同种类的垃圾产量数据均设置为csv格式,并分别与各对应区镇级行政区相关联;
8.s3:将被测区域所包含的区镇总数记为n,以m个区镇作为一组对n个区镇进行分组,延展获得多个延展组,将各延展组内所有区镇的垃圾产量总数作为各延展组的垃圾产量,其中m≤n;
9.s4:分别采集与各延展组的垃圾产量相同时间尺度下的训练样本数据,并裁剪掉训练样本数据中属于被测区域之外的部分,训练样本数据包括在开源网络上采集的:定居点数据、人口密度数据、viirs/dnb夜间灯光数据、osm路网数据和水体轮廓数据;
10.s5:分别计算每个延展组对应的定居点数据的总值和平均值、人口密度数据的总值和平均值、以及viirs/dnb夜间灯光数据的总值和平均值,按照区镇级行政区的边界将每个延展组中的osm路网和水体打断,并计算每个延展组中各区镇的osm路网总长度和水体总面积,将每个延展组对应的定居点数据的总值和平均值、人口密度数据的总值和平均值、
viirs/dnb夜间灯光数据的总值和平均值、osm路网总长度和水体总面积均作为分析特征;
11.s6:根据被测区域所属行政区的垃圾分类政策对被测区域的垃圾进行分类,分别计算每一类垃圾的高价值特征,并作为该类垃圾的预测样本数据;
12.s7:分别用lightgbm算法、catboost算法、xgboost算法和模型融合算法建立预测样本数据与同类别垃圾产量之间的回归预测模型,并利用预测样本数据对同类别回归预测模型进行训练,选取同一类回归预测模型中mae值最小的回归预测模型作为该类别垃圾的最优预测模型,从而获得不同类别垃圾的最优预测模型;
13.s8:利用空间渔网对被测区域进行网格划分,并提取每个网格的测试样本数据,测试样本数据包括被测区域实际的:定居点数据、人口密度数据、viirs/dnb夜间灯光数据、osm路网数据和水体轮廓数据;
14.s9:将每个网格的测试样本数据作为不同类别垃圾的最优预测模型的输入,获得每个网格中不同类别的垃圾产量,进而实现对整个被测区域不同种类的垃圾产量预测。
15.本发明中进一步的,所述步骤s3中,m的取值分别为:2n、0.25n、0.5n、0.75n、n-1和n,且当前m的取整方式为向下取整。
16.本发明中进一步的,所述步骤s3中,延展组的选取方法为:
17.当m≤n/2或m=n时,以m个区镇作为一组随机在n个区镇中进行选取,各延展组中的区镇互不交叉,若选取过程中剩余区镇的个数不足m,则完成当前m取值下延展组的选取;
18.当m》n/2且m≠n时,以m个区镇作为一组随机在n个区镇中进行选取,各延展组中的区镇存在交叉且不完全相同。
19.本发明中进一步的,所述步骤s5中,定居点数据、人口密度数据以及viirs/dnb夜间灯光数据均以栅格数据的方式表达,该栅格数据的总值为所有栅格中数据的总和,该栅格数据的平均值为总值与栅格数量之商,定居点数据、人口密度数据以及viirs/dnb夜间灯光数据的总值和平均值是利用geoscene pro2.1软件的以表格显示分区统计功能计算的。
20.本发明中进一步的,所述步骤s6中,计算每一类垃圾的高价值特征的方法均相同,具体方法为:将步骤s5中获得的八种分析特征分别与对应延展组的垃圾产量进行灰色关联度分析,获得每种分析特征的灰色关联度分析值,并将获得的每种分析特征的灰色关联度分析值由大到小进行排序,选取排在前五位的灰色关联度分析值对应的分析特征作为高价值特征。
21.本发明中进一步的,所述步骤s7中,模型融合算法是将lightgbm算法、catboost算法和xgboost算法进行融合。
22.本发明中进一步的,所述步骤s8中,空间渔网的单位尺寸为500m
×
23.500m。
24.与现有技术相比,本发明的有益效果是:
25.1、本发明首度利用空间遥感数据的融合对长时间范畴内的垃圾产量变化进行了机器学习回归预测,并比较了不同机器学习算法的应用效果,实现了在时间与空间上对不同种类垃圾产量变化特征的分析,能够得到难以进行数据统计的偏远地区的垃圾产生状况,以及城乡垃圾的变化情况,尤其是应用于难以管理的农村区域。
26.2、本发明的预测结果能够服务于农村垃圾的产生-收集-运输-转运-处理-回收等过程,此过程不仅仅是垃圾物质流能量流的运转,也服务于各个关键环节间的空间联动与
匹配协调,在城乡不同场景下的固废智能管理领域都有广大的应用前景。
附图说明
27.图1为本发明基于空间尺度延展与数据融合的城乡垃圾产量预测方法的流程图;
28.图2为香港地区2019年垃圾分类产量统计图;
29.图3为采用本发明方法2d空间下预测模型效果图;
30.图4为采用本发明方法3d空间下建筑垃圾的预测模型效果图;
31.图5为采用本发明方法3d空间下城市垃圾的预测模型效果图;
32.图6为采用本发明方法3d空间下居家垃圾的预测模型效果图;
33.图7为采用本发明方法3d空间下工商业垃圾的预测模型效果图;
34.图8为采用本发明方法3d空间下垃圾总量的预测模型效果图。
具体实施方式
35.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
36.请参阅图1,本发明提供以下技术方案:基于空间尺度延展与数据融合的城乡垃圾产量预测方法,包括以下步骤:
37.s1:从开源网络中获取被测区域地图文件shp数据,利用geoscene pro2.1软件的融合功能对被测区域地图文件shp数据中零散的面要素进行融合,使得被测区域内每个区镇都由单独的面要素构成;
38.s2:将被测区域内所有区镇不同种类的垃圾产量数据均设置为csv格式,并分别与各对应区镇级行政区相关联;
39.s3:将被测区域所包含的区镇总数记为n,以m个区镇作为一组对n个区镇进行分组,延展获得多个延展组,其中,m的取值分别为:2n、0.25n、0.5n、0.75n、n-1和n,且当前m的取整方式为向下取整,延展组的选取方法为:
40.当m≤n/2或m=n时,以m个区镇作为一组随机在n个区镇中进行选取,各延展组中的区镇互不交叉,若选取过程中剩余区镇的个数不足m,则完成当前m取值下延展组的选取;
41.当m》n/2且m≠n时,以m个区镇作为一组随机在n个区镇中进行选取,各延展组中的区镇存在交叉且不完全相同,
42.将各延展组内所有区镇的垃圾产量总数作为各延展组的垃圾产量;
43.s4:分别采集与各延展组的垃圾产量相同时间尺度下的训练样本数据,并裁剪掉训练样本数据中属于被测区域之外的部分,训练样本数据包括在开源网络上采集的:定居点数据、人口密度数据、viirs/dnb夜间灯光数据、osm路网数据和水体轮廓数据;
44.s5:定居点数据、人口密度数据以及viirs/dnb夜间灯光数据均以栅格数据的方式表达,该栅格数据的总值为所有栅格中数据的总和,该栅格数据的平均值为总值与栅格数量之商,利用geoscene pro2.1软件的以表格显示分区统计功能分别计算每个延展组对应的定居点数据的总值和平均值、人口密度数据的总值和平均值、以及viirs/dnb夜间灯光数
据的总值和平均值,按照区镇级行政区的边界将每个延展组中的osm路网和水体打断,并计算每个延展组中各区镇的osm路网总长度和水体总面积,将每个延展组对应的定居点数据的总值和平均值、人口密度数据的总值和平均值、viirs/dnb夜间灯光数据的总值和平均值、osm路网总长度和水体总面积均作为分析特征;
45.s6:根据被测区域所属行政区的垃圾分类政策对被测区域的垃圾进行分类,分别计算每一类垃圾的高价值特征,并作为该类垃圾的预测样本数据,计算每一类垃圾的高价值特征的方法均相同,具体方法为:
46.将步骤s5中获得的八种分析特征分别与对应延展组的垃圾产量进行灰色关联度分析,获得每种分析特征的灰色关联度分析值,并将获得的每种分析特征的灰色关联度分析值由大到小进行排序,选取排在前五位的灰色关联度分析值对应的分析特征作为高价值特征;
47.s7:分别用lightgbm算法、catboost算法、xgboost算法和模型融合算法建立预测样本数据与同类别垃圾产量之间的回归预测模型,其中,模型融合算法是将lightgbm算法、catboost算法和xgboost算法进行融合,并利用预测样本数据对同类别回归预测模型进行训练,选取同一类回归预测模型中mae值最小的回归预测模型作为该类别垃圾的最优预测模型,从而获得不同类别垃圾的最优预测模型;
48.s8:利用500m
×
500m的空间渔网对被测区域进行网格划分,并提取每个网格的测试样本数据,测试样本数据包括被测区域实际的:定居点数据、人口密度数据、viirs/dnb夜间灯光数据、osm路网数据和水体轮廓数据;
49.s9:将每个网格的测试样本数据作为不同类别垃圾的最优预测模型的输入,获得每个网格中不同类别的垃圾产量,进而实现对整个被测区域不同种类的垃圾产量预测。
50.具体实施例:
51.参照图2至8具体说明本实施例,本实施例以2021年3月香港特别行政区以及其周边乡镇的生活垃圾的时空分布情况为例,以香港岛、九龙、新界、离岛等四大片区域以及18个小区域为统计单位,面向探明当地垃圾时空产量分布的需求,开展了垃圾分类产生反演研究,得到了2020年生活垃圾的时空分布反演情况,为未来生活垃圾收储运体系的布局提供了决策支持,具体实施过程为:
52.研究区域地图:获取香港地区元朗、屯门等18个小地区的地图,对其零散的面要素进行融合,获取18个地区完整的面要素,融合18个地理单元,获得香港全境的面要素,提取香港岛、九龙、新界等地区的相关行政区进行融合,获得三个大区的面要素,上述共计22个面要素,合并为一个面要素,用于空间地理数据的提取;
53.垃圾产量数据整理:于香港环境保护署的2014~2019年固体废物监察报告,提取每一年的垃圾产量情况,连接到对应的行政区面要素内,如图2所示;
54.进行空间尺度延展:于现有十八个行政区进行随机取样,构建由随机两个行政区域形成的地理单元9个、随机由4个行政区域形成的地理单元4个、随机由9个行政区域形成的地理单元2个,随机取出其中4个行政区后组成的地理单元4个,随机由17个地理单元组成的行政单元18个,配合过去形成的22个行政单元,最后构建的地理单元样本包含59个,统计体量增长近两倍,每一组地理单元对应的人口、垃圾等统计数据由13~19年七年的数据组成,即后续机器学习的训练用样本数据集包含413组;
55.夜间灯光、人口等栅格类遥感数据处理:于网络开源途径,下载2014~2020年的worldpop定居点、人口密度(100m)、viirs/dnb夜间灯光数据(6月),进行基于步骤三所述的香港59个地理单元,进行裁剪与数据提取,并导出csv表格;
56.水体、路网等矢量数据处理:于网络开源途径,下载2014-2020年的水体轮廓数据、osm路网数据,进行基于步骤三所述的香港59个地理单元,进行裁剪与数据提取,并导出csv表格;
57.机器学习模型构建:基于上述数据,构建包含区域名称、空间地理特征、垃圾产量的机器学习模型数据集,首先进行灰色相关性关联分析,筛除低相关度数据,如区域平均人口、平均夜间灯光、平均定居点等类别的数据,三类均值特征的去除提升了模型精确度:进行lightgbm、catboost、xgboost、模型融合四种方式的建模效果比较,其中xgboost最优;
58.进行垃圾产量的分类预测:将上一步训练好的四类垃圾预测模型,进行保存,对整个香港区域进行500m的空间网格划分,生成网格面与网格点,根据渔网布设的位置提取路网、人口、定居点、夜间灯光数据,特征工程,为表达无灯光、人口、定居点的的区域垃圾产量理论上也是0,所以将特征与垃圾产量同时为0的数据加入数据集中,一并进行训练,将特征导出表格并输入模型,得到预测结果,并连接回到渔网网格中,模型结果需要降噪,由于在无灯光、人口、定居点的的区域,机器学习拟合结果为接近0的小数却不可能正好为0,所以对所有相似点归0,得到如图3所示结果;
59.通过基于空间尺度延展与网格数据融合的村镇垃圾产量预测方法,最终得到了三维展示如图4-8所示的垃圾分类结果,完成了香港当地居家垃圾、工商业垃圾、建筑垃圾、城市垃圾、总垃圾量的空间预测结果,其中包含了难以进行数据统计的香港内部农村的垃圾产生数据。
60.尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1