一种基于标签和文本块注意力机制的极限多标签分类数据增强方法
1.本发明属于计算机应用技术领域,具体涉及数据挖掘,极限多标签分类,特别是一种基于标签和文本块注意力机制的极限多标签分类数据增强方法。
背景技术:
2.近年来,随着互联网的快速发展,社交媒体、电商网站等平台积累了大量的带标签的文本数据。由于标签集的数量庞大,极限多标签分类任务即是从大量的标签集中找到文本最相关的几个标签。通过极限多标签分类任务从而进行数据挖掘对各行业的发展具有重要意义,例如对电商网站中的商品评价数据进行分析,可以帮助商家了解消费者的购买倾向,进而为其提供有效的决策支持,帮助其对现有产品和服务进行改进。由于这种数据通常具有文本长度长、整体标签集大、部分标签出现次数很少等特点,现有的方法对数据集中出现次数较少的标签分类效果较差,进而影响了整体的分类性能,目前通常把在整个数据集中出现次数少的标签称为“长尾”标签,因此如何通过一种新的数据增强方法增加“长尾”标签的数量进而提升分类的效果是本发明专利研究的核心任务。
3.目前,国内外已有很多工作针对极限多标签分类任务开展了相关研究,并且取得了一定的研究成果。现有的相关研究方法主要可以分为两类:基于传统机器学习的方法和基于神经网络的方法。
4.在基于传统机器学习的方法中,这些方法把多标签分类任务看作多个二分类任务。proxml[1]对每个标签进行分类,判断是否与文本相关,这种方法被统称为一对多方法。虽然这种方法取得了一定的效果,但是面临着大量的计算资源消耗并且空间复杂度较高。为了缓解这种问题,基于树的方法被提出,jasinska[2]等人使用一个概率标签树去划分了标签集,进而缓解了大量的计算消耗等问题。但是基于树的方法仍有一些问题,“长尾”标签会被错误地和一些完全不相关的标签分到一起,从而影响了整体的分类性能。
[0005]
近年来,随着神经网络的发展,许多基于神经网络的方法也被提出。xmlcnn[3]首次通过一个卷积神经网络和一个全连接层去解决极限多标签分类问题。attentionxml[4]将传统机器学习中的概率树和循环神经网络进行了结合,抓住了标签和文本之间的关系,在性能上有了较大的提升。lightxml[5]采取了bert[6]作为文本的编码器,获得了较好的文本表示,并在标签召回缓解采用了负采样,具有了目前最好的极限多标签分类的效果。
[0006]
虽然上述方法均在一定程度上对分类性能有了提升,但是都仍未解决或减轻极限多标签分类的根本问题,“长尾”标签的存在对分类器分类的影响依然很大,这些方法在长尾标签相关的数据上单独进行分类效果都不理想。
技术实现要素:
[0007]
本发明目的是针对现有技术无法在出现次数少的标签上获得较好分类效果的问题,提供一种基于标签和文本块注意力机制的极限多标签分类数据增强方法,增强出现次
数较少标签相关的数据,从而提升各类模型在此类标签上的分类性能。
[0008]
本发明认为,通过数据增强方法增加数据集中“长尾”标签(数据集中出现频数少的标签)出现的数量进而基于已有方法提升极限多标签分类的性能是一种有效的解决“长尾”标签分类性能差的途径。由此,如何设计一种数据增强方法有针对性地增加“长尾”标签相关数据是本发明主要解决的问题。
[0009]
针对上述问题,本发明构建了一种基于标签和文本块注意力机制的极限多标签分类数据增强方法,本发明认为,一个标签一般与文本中的一部分相关,因此本发明将数据中的每条文本等长切分成若干个文本块,设计了一个方法学习标签和文本之间的关系,找到每个标签相关性最强的文本块,将原始数据集中不带“长尾”标签的文本中一些不重要的文本块替换成与“长尾”标签强关联的文本块,从而形成了新的数据加入到原始数据集中形成新的数据集,以改善“长尾”标签的分类效果,进而提升整体的极限多标签分类效果。
[0010]
本发明的技术方案如下
[0011]
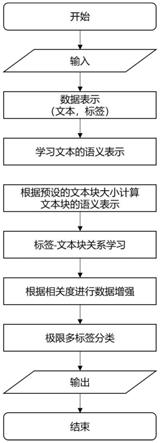
如附图2所示,一种基于标签和文本块注意力机制的极限多标签分类数据增强方法,包括:
[0012]
步骤1)选择原始数据集和设置每条文本需要分成的文本块块数;
[0013]
步骤2)每条输入文本经过基于变压器的双向编码器(bert)的分词器后获得浅层的每个词的向量表示,由于标签的形式不一定是文本,因此将通过随机初始化获得标签的向量表示,并将标签的向量表示设为有梯度状态,使得标签的表示在后续的训练中可以继续学习更新;
[0014]
步骤3)基于步骤2中的文本浅层向量表示,学习文本中每个词的高层语义表示;
[0015]
根据步骤2中输出的每个词的浅层向量表示,利用bert编码器以序列的方式对文本中的词进行高层的语义编码。
[0016]
步骤4)根据步骤3的输出和预设的文本块大小,计算文本块的语义表示;
[0017]
根据步骤3的输出,得到了每个词的高层语义表示,基于预设的文本块大小,将文本切分成等长的若干个文本块,通过对文本块内每个词的高层语义表示求平均,获得整个文本块的表示。
[0018]
步骤5)根据步骤4中获得的每个文本块的表示和步骤2中的标签的向量表示,通过注意力机制计算两种表示的相关度,并根据相关度对所有文本块的表示进行融合,随后将融合后的文本表示送入分类器进行分类,进而更新注意力机制中的query和key之间的权重参数,经过训练后得到了完整的标签-文本块关系模型,如附图1所示。
[0019]
步骤6)基于步骤5获得的训练后的标签-文本块关系模型,通过标签向量表示和文本块向量表示的相关度进行数据增强;
[0020]
根据步骤5获得的标签-文本块关系模型,在数据集中找出“长尾”标签(数据集中出现频数少的标签)相关的文本块,而由于“长尾”标签相关数据本身较少,因此首先找出非“长尾”标签相关的文本块,在“长尾”和非“长尾”标签同时存在的数据中,将非“长尾”标签相关的文本块排除,剩余的文本块则作为“长尾”标签的相关联文本块。若一条数据中存在多个“长尾”标签,则文本块属于相关度最强的“长尾”标签。随机选择一个“长尾”标签和一条数据,将数据中若干个与原始标签都不相关的文本块替换为该“长尾”标签的文本块,并将该“长尾”标签加入到该条原始数据的标签集合中,形成新的一条数据加入到原始数据集
中,反复随机选择“长尾”标签和数据,最终获得了新的数据集。
[0021]
步骤7)根据步骤6中获得的新数据,重新用已有的极限多标签分类模型进行训练,可以看到性能的提升。
[0022]
步骤8)输出新数据集。
[0023]
本发明的优点和有益效果:
[0024]
本发明基于论文摘要及其所属标签数据实现对其极限多标签分类,提出的方法考虑了标签和文本块之间的关系,利用模型学习标签和文本之间的关联性,并得到标签相关联的文本块,基于“长尾”标签相关联的文本块对原始数据中不重要的文本块进行替换,并增加对应长尾标签,形成新的数据加入到原始数据集中,各种已有模型在新数据集上的多标签分类效果获得了显著的提升。
附图说明
[0025]
图1是本发明的标签-文本块关系学习模型示意图。
[0026]
图2是本发明的基于标签和文本块注意力机制的极限多标签分类数据增强方法处理流程图。
具体实施方式
[0027]
实施例1:
[0028]
下面结合附图和具体实施例对本发明提供的基于标签和文本块注意力机制的极限多标签分类数据增强方法进行详细说明。
[0029]
本发明主要采用自然语言处理相关的理论和方法,为了保证方法的正常运行,在具体实施中,要求所使用的计算机平台配备不低于16g的内存,cpu核心数不低于4个且主频不低2.6ghz、linux操作系统,并安装python 3.6及以上版本、pytorch框架等必备软件环境。
[0030]
在步骤1,2)中:原始的数据集可以表示为xn:
[0031][0032]
其中n表示数据集中数据的数量,xi表示一条文本,yi∈{0,1}
l
,对应这条数据的标签集合,用一个l维的独热编码的向量表示,l是整个数据集中标签的总个数。
[0033]
同时,可以预设将每条文本分成t个等长的文本块,t为正整数,每个文本块用w
ik
表示。
[0034]
所有标签的表示可以被初始化为c:
[0035]
c=[c1,c2,c3,...,c
l
)
[0036]
其中,c∈r
l
×g,g表示每个标签向量表示的维度,ci表示每一个标签的向量表示,r表示维度符号。
[0037]
在步骤3)中,基于步骤2中的文本浅层表示,学习文本中每个词的高层语义表示:
[0038]
通过将浅层的文本表示x送入bert,获得文本的高层语义表示h
t
:
[0039]ht
=bert(x),h
t
∈rd[0040]
其中,t∈[0,z],t表示x的第t个词,z是输入文本中词的最大数量,d表示高层语义表示h
t
的维度。
[0041]
在步骤4)中,基于步骤3获得的高层表示和步骤1中预设的文本块块数,通过平均池化每个块内所有字符的表示来获得整个文本块的表示
[0042][0043]
l是每个文本块中词的数量,l=z/t。
[0044]
随后,可以得到融合后整体文本的表示h:
[0045][0046]
在步骤5)中,以步骤4融合后整体的文本表示作为输入,利用标签表示通过注意力机制选择文本中与每个标签相关的文本块,可通过下式生成注意力权重向量a:
[0047]
a=softmax(cwh
t
)
[0048][0049]
其中,w是模型的标签和文本块向量表示之间的权重矩阵参数。
[0050]
在得到注意力权重向量a的基础上,利用下式得到基于标签不同关注度的文本表示s:
[0051]
s=ah
[0052]
其中,s∈r
l
×d[0053]
随后,将融合后的文本表示送入全连接层进行分类:
[0054]
g(s)=σ(wss
t
+bs)
[0055]
经过多轮训练后,可以得到能较准确捕获标签和文本块关系的模型,模型结构如附图1所示。
[0056]
步骤6)根据在步骤5中得到的标签-文本块关系模型,如果yi同时包括“长尾”标签y
il
和一些非“长尾”标签,对于xi中的文本块wk,若:
[0057]
a(wk,yi)≤α
[0058]
则将wk储存到用来存放“长尾”标签及其相关文本块的集合中,其中α是初始人为设定的阈值,用来判断权重分值的高低;遍历整个原始数据集xn,对整个数据集执行上述步骤,找出“长尾”标签相关的文本块;
[0059]
随后针对整个原始数据集,随机选择出一条数据(xq,yq),其中,xq表示输入文本,yq表示文本对应的标签,从所有“长尾”标签的集合m中随机选择一个“长尾”标签ya,对(xq,yq)中的文本块wk,若a(wk,ya)<β,则从标签yq对应的文本块集合中随机选择文本块w
t
,将wk替换为w
t
,重复执行此操作,直到替换的次数达到设定次数r,则形成一条新的数据,并将对应的ya加入到yq中。
[0060]
反复随机选择“长尾”标签和原始数据集xn里面的数据,则可最终形成新的数据集
[0061]
步骤7)基于新的数据集在已有的各种极限多标签分类模型上进行训练,在“长尾”标签的分类准确率上有显著的提升,从而使得整体的分类准确率有显著提升。
[0062]
例如,在公开数据集eur-lex上,该增强方法增强后的数据基于attentionxml[4]在“长尾”标签相关数据的分类性能上提升0.9%,在全部数据的分类性能上提升1.2%。
[0063]
步骤8)反复进行上述步骤1-6,最终输出新的数据集。
[0064]
例如,针对公开数据集eur-lex,原始语句如下,并且与”cs.ai”,”cs.cv”标签相关:
[0065]
digital elevation models\(dem\)are images having terrain information embedded into them using cognitive mapping concepts for dem registration,has evolved from this basic idea ofusing the mapping between the space to objects and defining their relationships to form the basic landmarks that need to be marked,stored and manipulated in and about the environment or other candidate environments
…
[0066]
经过数据增强后的语句如下,并且与”cs.ai”,”cs.cv”,”physics.data-an”标签相关:
[0067]
and simulate real world complex into them using cognitive mapping estimation of the parameters by complex network,social network idea ofusing the mapping between the space to objects and defining their relationships to form the basic landmarks that need to be marked,stored and manipulated in and about the environment or other candidate environments
…
[0068]
参考文献:
[0069]
[1]babbar r,b.data scarcity,robustness and extreme multi-label classification[j].machine learning,2019,108(8):1329-1351.
[0070]
[2]jasinska k,dembczynski k,busa-fekete r,et al.extreme f-measure maximization using sparse probability estimates[c]//international conference on machine learning.pmlr,2016:1435-1444.
[0071]
[3]liu j,chang w c,wu y,et al.deep learning for extreme multi-label text classification[c]//proceedings of the 40th international acm sigir conference on research anddevelopment in information retrieval.2017:115-124.
[0072]
[4]you r,zhang z,wang z,et al.attentionxml:label tree-based attention-aware deep model for high-performance extreme multi-label text classification[j].arxiv preprint arxiv:1811.01727,2018.
[0073]
[5]jiang t,wang d,sun l,et al.lightxml:transformer with dynamic negative sampling for high-performance extreme multi-label text classification[j].arxiv preprint arxiv:2101.03305,2021.
[0074]
[6]devlin j,chang m w,lee k,et al.bert:pre-training ofdeep bidirectional transformers for language understanding[j].arxiv preprint arxiv:1810.04805,2018.
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1