一种基于判别决策树的工业部件分类方法与流程
1.本发明涉及图像处理技术,具体涉及一种基于判别决策树的工业部件分类方法。
背景技术:
2.决策树算法可解释性强,准确率高以及参数少等优点使之成为最受欢迎的机器学习算法之一,并在各个领域都得到了广泛的应用。
3.在现代制造业中,将机器视觉技术应用到自动化生产线上的工业部件分类,能够进行更加灵活、客观和准确的判断,使生产更加自动化及智能化,并且利于企业的信息化管理。目前,常用于自动化工业部件分类方法主要分为三种,即模板匹配法,神经网络和支持向量机。模板匹配法建立在模板库基础上,比较被动缺乏智能,神经网络能够学习到更好的表征但是可能会出现较差的推广性,支持向量机具有一定鲁棒性但是解决多分类问题仍存在困难。所以,要获得更加具有表达力的特征向量以及选择何种分类方法,提高分类的准确性和稳定性,仍是基于机器视觉中进行工业部件分类面对的难题。
技术实现要素:
4.本发明的目的在于提供一种基于判别决策树的工业部件分类方法,相比于其他工业部件分类方法,更有效利用了工业部件各个关键点特征以及标签信息,提高了分类的准确率,克服分类不稳定、模型泛化性差等问题。
5.实现本发明目的的技术解决方案为:一种基于判别决策树的工业部件分类方法,包括如下步骤:
6.步骤1、标注工业部件图像中关键点,采用卷积神经网络从检测关键点位置,并根据检测结果使用残差网络提取局部区域特征;
7.步骤2、选择不同分裂属性即标注的关键点,赋予每个分裂属性不同权值以初始化各属性在决策树中的判别顺序;
8.步骤3、根据已标注好的分裂属性,使用线性判别分析(lda)对样本特征进行降维,计算样本与模板样本特征的成对距离(pair-wise distance)将样本数据划分到不同分支,再对非叶子节点的子节点递归调用该步骤方法直至达到终止条件;
9.步骤4、依据每类分裂属性上分类准确率的排序调整分裂属性在决策树中的判别顺序,使用新的顺序和步骤3中分裂方法再次划分样本数据预测样本类别。
10.本发明与现有技术相比,其显著优点为:
11.1)单独的rgb和灰度图像特征已难以满足现代工业应用中高识别准确率的要求,本发明利用神经网络分别提取零件rgb图像特征和灰度图像特征,将rgb特征和灰度特征进行线性串接,两者包含信息对彼此是有效的补充,从而获得特征更具有判别性;
12.2)对于关键点较多的工业部件,传统方法未能很好利用各关键点信息,本发明利用决策树对样本数据进行划分,充分利用关键点特征以及标签信息,并且对于不同的条件属性和分裂点,使用线性判别分析将相应特征降到低维,更能反映出样本间的差异,提高分
类准确率;
13.3)本发明利用每类分裂属性上样本分类准确率判断各分裂属性重要性,去除冗余信息,利用准确率这一先验知识重新调整判别决策树的结构,增强模型的鲁棒性与泛化性。
附图说明
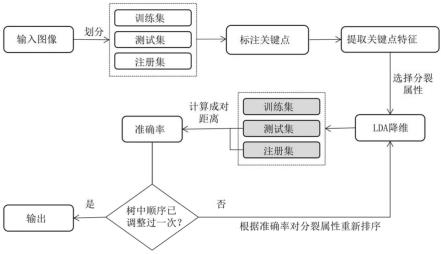
14.图1为本发明基于判别决策树的工业部件分类方法的流程图。
15.图2为样本特征存储方式。
16.图3为初始构建的判别决策树分类示意图。
17.图4为调整结构后的判别决策树分类示意图。
具体实施方式
18.下面结合附图和具体实施例,进一步说明本发明方案。
19.如图1所示,基于判别决策树的工业部件分类方法,包括如下步骤:
20.步骤1、提取关键点特征
21.作为一种具体实施方式,将样本数据划分为训练集、测试集以及注册集。其中注册集由每类样本中随机抽取的若干张图片样本组成。选用faster r-cnn和resnet网络作为基础卷积神经网络,提取关键点特征。首先对图片进行预处理,并标注需要检测关键点。采用faster r-cnn进行检测,标出候选框位置。特别地,选择工业部件中心固定比例大小区域作为圆盘属性。根据候选框位置,选用resnet网络获取第三层特征向量。
22.假设表示样本集合,第i个图片样本xi,包含m个属性对于第i个样本的第m个属性上的rgb特征向量和灰度特征向量串接为如图2所示,使用字典存储样本各个属性上的特征向量。
23.步骤2、选择不同分裂属性,赋予每个属性不同权值以初始化各属性在决策树中的判别顺序;
24.作为一种具体实施方式,确定样本关键点或属性类别对于每一分裂属性ak,确定该分裂属性下样本所属类别v(xi,ak)与实际样本的类别v(xi)的映射关系f
label
(v(xi),v(xi,ak))。给予各分裂属性不同权值确定各分裂属性在判别决策树中是否使用以及先后顺序,初步构建决策树。
25.步骤3、根据已标注好的分裂属性取值,使用lda对样本特征进行降维,计算训练或测试样本与注册样本的成对距离,将样本数据划分到不同分支,再对非叶子节点的子节点递归调用该方法直至达到终止条件;
26.作为一种具体实施方式,已得各分裂属性特征向量作为输入数据,从第一个分裂属性a1开始,根据属性a1的属性值不同分为c1个类别对n1个训练样本的a1属性特征向量使用lda将特征向量x
tr
∈rn×d降到c
1-1维,得到新的特征向量当c1>1,将测试样本和注册样本经过训练好的lda模型,否则,舍弃该属性。其过程可以表示为以下形式:
[0027][0028]
其中表示在属性a1上使用lda进行特征降维。接着,计算测试集中每一样本与注册集中所有样本的成对距离选择与距离最小注册集样本确定注册样本在属性a1上属性值v(xj,a1),以及实际类别v(xj),作为的预测类标签p(xi,a1)和p(xi),其中p(xi)为在某一属性下预测类标签对应的实际样本类标签。类似地,按照属性初始顺序,将原始特征向量x
type
依次输入下一层,重复以上准则,自顶向下进行递归训练直至考虑完m个属性。其过程可表示为以下形式:
[0029][0030]
对于每一有效属性a,计算测试样本在属性a上类别分类准确率:
[0031][0032]
其中,n1为训练样本数量。
[0033]
步骤4、依据样本在每个分裂属性上分类准确率调整分裂属性在树中的判别顺序,使用新的顺序和步骤3中分裂方法再次划分样本数据预测样本分类。
[0034]
对步骤3所得按照从大到小顺序进行排序,调整判别决策树的结构。分类准确率越高的属性往树的上层调整,特别地,由于圆盘属性相较于其它较小关键点,检测更为准确,相应特征更稳定,所以当该属性排序在树的第三层以下,将其固定在树的第三层。根据调整后的决策树,重复步骤3,重新训练判别决策树并且预测测试样本类别。
[0035]
从根节点开始,对每一属性ak(ck>1),有测试样本在该属性上预测类标签以及对应实际类别标签。找到子节点后,继续进行匹配,递归上述操作,最终测试样本到达叶子节点处。具体地,从根节点开始,假设测试样本在判别决策树的第k层,预测类别标签p(xi,ak),对应样本实际标签p(xi)。若p(xi,k-1)中只含有一个元素,则认为p(xi,k-1)为最终预测类标签,到达叶子节点。若p(xi,k-1)中元素大于1,取k与k-1层交集,如果交集不为空,交集作为第k层预测类标签,否则,取p(xi,k-1)作为第k层预测类标签。其过程可表示为以下形式:
[0036][0037]
其中set(p(xi,k))表示p(xi,k)中所含元素个数。为了得到最终预测类标签,依次递归直到到达判别决策树的最后一层。
[0038]
实施例
[0039]
为了验证本发明方案的有效性,进行如下实验。
[0040]
首先,标注好待检测的零件图片需检测的属性类别以及每种属性分类。共13类零件,细化分属性共7种:轴套,圆盘,恒温孔,螺栓包装孔,浊度传感器孔,出气口,排水管。当样本较少,可使用角度增广以及光照增广增加样本数量。划分训练集测试集以及注册集。其中注册集中需包含所有类别样本,每类样本同等数量,约占训练集20%。采用faster r-cnn检测出关键点(属性)位置。使用resnet-50网络提取第三层特征。得到的rgb和灰度特征向量均为1024
×2×
2,展开获得2个4096维特征向量并串接起来,得到8192维特征向量作为每个属性的特征表示。
[0041]
选择以上7种细划分属性,构建初始的判别决策树。如表1所示。使用数字分别代样本实际类别以及属性类别。赋予这些属性不同权重,确定它们在判别决策树中的判别顺序。以第3类零件为例,对应7类属性类别依次为5,4,0,2,1,2,2。将训练样本首先经过轴套属性,使用lda将8192维特征向量降至6维。接下来将测试样本和注册样本通过训练好的lda模型,获得6维特征向量。对于每个测试样本,计算其特征向量与注册样本特征向量的成对距离,并统计该属性的分类准确率。继续考虑圆盘属性。使用原始8192维特征向量,将训练样本通过lda降到12维,再将测试和注册样本通过在该属性上训练好的lda模型。计算测试样本与注册样本的特征向量成对距离和准确率。重复以上操作,直至考虑完最后的排水管属性。
[0042]
表1:分类属性标注
[0043][0044]
将以上7种属性的分类准确率进行排序,按从大到小顺序依次得到轴套,圆盘,螺栓包装孔,浊度传感器孔,恒温孔,排水管,出气口。按照该顺序调整决策树结构。分类过程如图3和图4所示,其中图4为调整顺序后的判别决策树。对于样本最终预测标签,以下以测试集中部分图片样本为例。对于第3类某张图片样本,首先经过轴套属性节点,使用训练好的lda将该样本特征向量降至6维,计算该样本特征向量与所有降维后注册样本特征向量成对距离,距离最近的样本类别即为预测类别。在该属性类别预测正确情况下得到该属性下预测类别5,以及实际样本类别{2,3,8,11}。继续考虑圆盘属性,使用lda将8192维特征向量降至12维,在该属性类别预测正确情况下得到该属性预测类别2和实际样本类别{3}。在判别决策树的第二层,{2,3,8,11}∩{3}作为该层的预测标签类别。由于交集中只含有一个元
素3,所以3作为最终预测类别。在恒温孔属性节点,上一层预测类别数量为1,故到达叶子节点。对于第5类某张样本图片,首先经过lda将8192维特征向量降至6维,在预测正确的情况下,得到属性类别标签2和实际类别{5,12}。继续考虑第二层圆盘属性,在预测正确情况下得到圆盘属性预测类别4和实际类别{5,12},由于{5,12}∩{5,12}={5,12},第二层预测图片样本类别为{5,12}。继续考虑第三层恒温孔属性,lda降维后,在预测正确情况得到恒温孔属性类别0和{1,5,6,9,10,12},由于{5,12}∩{1,5,6,9,10,12}={5,12},该层预测结果{5,12}中元素大于1,继续考虑第四层螺栓包装孔属性。重复以上操作,预测正确情况下得到螺栓包装孔属性类别0和实际类别{1,5,12},第四层预测结果为类别{5,12}。第五层浊度传感器孔预测正确情况下,预测类别与上一层预测类别交集为{5,12}。第六层出气口在预测正确情况下,得到出气口属性类别1和实际类别{4,5,8,11,13}。与上一层预测结果交集为{5}。预测结果只有一个元素,故到达叶子节点,最终类别为5。实验采用最终分类准确率作为评估指标。结果如表2所示,本发明取得了显著效果。此外,可看出样本在圆盘属性上的分类效果较为稳定,准确率较高。图片rgb特征和深度特征串接起来比单独使用其中一种特征,分类效果更佳。
[0045]
表2:工业部件图片分类准确率
[0046][0047]
由于零件的关键点众多且部分关键点不明显,检测过程中可能存在漏检和错检情况,导致分类不稳定和准确率不高问题。另外工业部件全局特征区分性不明显,直接使用全局特征丢失较多有用信息。利用本发明方法,获得更易于判别的有效特征,充分利用各关键点信息以及判别决策树的先验知识,从而提高工业部件分类准确率,得到更为鲁棒的分类模型,具有更好的泛化性。综上所述,本发明更好的考虑了工业部件图片自身的特点,提高了工业部件分类的准确率与鲁棒性。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1