一种超大变量叶轮机械高效设计优化方法及系统及应用
1.本发明属于叶轮机械优化领域,特别涉及一种超大变量叶轮机械高效设计优化方法及系统及应用。
背景技术:
2.近年来,在叶轮机械领域,自动化的优化设计方法受到越来越广泛的应用。自动优化设计方法需要人为确定一个可以参数化的设计空间,空间中的每个样本都对应一个具体的几何设计方案。以计算机模拟计算的结果作为寻优的目标,借助特定的优化算法就可以自动化地设计得到性能优异的叶轮机械部件。自动化设计方法的使用可以有效减少对于设计人员经验的需求,快速高质量地完成设计。
3.优化算法往往是决定自动化优化设计方法效率的关键。以高效全局优化算法(ego)为代表的代理模型优化方法(sbo)在工程领域取得了显著的成果。代理模型优化算法往往能够很好地平衡全局搜索与局部寻优之间的关系,具有较高的优化效率。
4.然而随着工程问题研究的深入,目标问题必然朝着设计空间维度更高,单样本计算资源更大,设计变量间关系更加复杂的方向发展。更高的设计空间维度使得工程设计具有更大的自由度,可以探索更加丰富的设计可能;更大的计算资源需求则是更高精度计算模拟的结果;而复杂的变量与结果间的关系增加了自动化设计的必要性。对于这样的高维度大资源黑盒问题(或简称为heb问题),适用范围在15维以下的传统代理模型优化算法开始力不从心。传统代理模型优化方法的不适用体现在:(1)使用有限的样本无法建立准确的高维代理模型。从获取信息的角度,要建立相同精度的代理模型,所需的样本数量会随着问题维度的上升而指数增加。但在实际的工程优化中,样本的数量受到算力和时间的限制。(2)搜索加入新样本的前提是代理模型的准确性,在高维代理模型准确性较低的情况下无法指导后续的加点。(3)代理模型建立和优化搜索的时间复杂度随着样本数量和维度的增加而急剧增大。(4)kriging模型使用的高斯核函数是基于欧拉距离实现的,但在高维空间中存在欧拉距离失效的情况。
技术实现要素:
5.本发明的目的在于提供一种超大变量叶轮机械高效设计优化方法及系统及应用,以解决上述问题。
6.为了实现上述目的,本发明采用的技术方案是:
7.一种超大变量叶轮机械高效设计优化方法,包括以下步骤:
8.建立设计空间:以叶轮机械部件为设计对象,得到三维叶片的调整参数;
9.在建立的设计空间中使用lhs方法获得分布较为均匀的若干个样本坐标,对其进行性能评估获得这若干个设计样本的级效率值;
10.使用获得的样本坐标和样本值建立pce拟合模型建模后对模型预测最优值的坐标进行级效率的评估,将坐标和评估结果加入数据列表中;
11.选择所有样本中级效率最大的值作为核心点,将高维全局问题分解为r个低维问题,记录确定的分解参数{x
*
,i};
12.对r个低维问题同步地并行地完成操作:使用多保真度代理模型hk模型和最大期望提升加点准则在子问题空间内完成一次完整独立的优化搜索,优化得到的结果为x
best,j
;
13.使用所有已评估样本更新全局pce模型计算模型的最小预测值坐标,将坐标评估后加入数据集中;
14.对r个子问题优化结果进行排列组合,依据全局模型筛选出n
combine
个样本进行评估;重复上述,直到算法满足停止条件。
15.进一步的,建立设计空间中,对三维叶片对象截取若干个截面作为造型的特征截面,同时选择若干个设计参数来调整三维叶片进行积叠时的弯扭掠状态。
16.进一步的,将高维全局问题分解具体为:
17.找到所有已评估样本中评估值最小的样本,将其坐标记为x
*
;
18.随机地确定子空间变量分配方法i,i={i1,i2,i3,...,ir}来表示对各个变量的划分,其中
19.子空间内的坐标和高维全局空间内的坐标有如下一一对应关系:假设局部坐标记为x
local
,全局坐标记为x
global
,有x
local
∈sj,x
global
∈s;
20.x
global
=[x
1g
,x
2g
,x
3g
,...,x
dg
]
[0021][0022][0023]
进一步的,在不考虑对子空间的边界进行调整的情况下,有子空间在不考虑子空间重叠和对变量进行剪枝的情况下各子空间对应的变量具有如下关系:
[0024][0025]
进一步的,对r个低维问题同步地并行地完成操作:
[0026]
在子空间中使用拉丁超立方算法进行初始加点,初始加点个数为n
lj,ini
,一般的n
lj,ini
=2||ij||;
[0027]
在子空间中建立多保真度代理模型,其中高保真度来源为子空间内的样本加点,低保真度的来源为全局模型中位于该子空间中的部分;模型的建立公式如下:
[0028]
对于已经建立的模型计算其在子空间范围内的ei值,并搜索得到在子空间范围内ei值最大的坐标位置,在该位置进行加点评估;
[0029]
重复上述,直到迭代次数达到最大迭代次数iter
max
,iter
max
=8||ij||;
[0030]
从全部子空间的已评估样本中选择样本值最优的样本作为优化的结果。
[0031]
进一步的,对r个子问题优化结果进行排列组合:
[0032]
获得包含2
r-r-2个样本的潜在组合样本集合x
pcombine
,并使用全局模型获得所有潜在组合样本的预测值和每个潜在组合样本和已有样本的欧式距离之和dist(x
pcombine
);
[0033]
以预测值为依据升序排序得到x
sortpredict
,以距离和为依据升序排序得到x
sortdist
;
[0034]
按顺序从两个序列中选出n
combine
个样本,一般的n
combine
=||ij||/2
[0035]
对选出的样本进行评估。
[0036]
进一步的,一种超大变量叶轮机械高效设计优化系统,包括:
[0037]
设计空间建立模块,用于以压气机动叶片标模作为设计对象,得到三维叶片的调整参数;
[0038]
级效率值获得模块,用于在建立的设计空间中使用lhs方法获得分布较为均匀的若干个样本坐标,对其进行性能评估获得这若干个设计样本的级效率值;
[0039]
拟合模型建立模块,用于使用获得的样本坐标和样本值建立pce拟合模型建模后对模型预测最优值的坐标进行级效率的评估,将坐标和评估结果加入数据列表中;
[0040]
分解模块,用于选择所有样本中级效率最大的值作为核心点,将高维全局问题分解为r个低维问题,记录确定的分解参数{x
*
,i};
[0041]
优化搜索模块,用于对r个低维问题同步地并行地完成操作:使用多保真度代理模型hk模型和最大期望提升加点准则在子问题空间内完成一次完整独立的优化搜索,优化得到的结果为x
best,j
;
[0042]
模型更新模块,用于使用所有已评估样本更新全局pce模型计算模型的最小预测值坐标,将坐标评估后加入数据集中;
[0043]
评估模块,用于对r个子问题优化结果进行排列组合,依据全局模型筛选出n
combine
个样本进行评估;重复上述,直到算法满足停止条件。
[0044]
进一步的,一种超大变量叶轮机械高效设计优化系统的应用,用于叶轮机械高效设计。
[0045]
与现有技术相比,本发明有以下技术效果:
[0046]
本发明借助分解方法和迁移学习来完成高维全局优化:使用多项式混沌展开(pce)方法和所有的样本建立全局模型,同时将高维问题分解成多个低维子问题,在每个子问题中利用由全局模型传递来的迁移信息进行加速优化,从而实现对高维问题的有效分解降维和在子问题中对于所有评估样本信息的高效利用。通过使用分解方法,将一个高维度的优化设计问题分解成为多个低维度的子问题,然后使用基于迁移学习的分层克里金代理模型(hk)来对子问题进行优化,这样既降低了需要处理问题的维度,同时也保持了样本信息的有效利用率,提高了优化的效率。
附图说明
[0047]
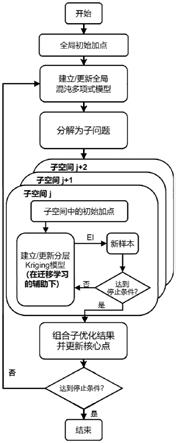
图1为本发明实施例的原理图。
[0048]
图2为本发明实施例的子空间迁移学习优化具体流程示意图。
具体实施方式
[0049]
下面结合附图和实施例详细说明本发明的实施方式。
[0050]
如图1所示,本实施例提供了一种超大变量叶轮机械高效设计优化方法并应用于压气机叶片造型优化设计中,具体包括以下步骤:
[0051]
1.设计空间的建立
[0052]
本施例选择最为广泛使用的nasa rotor37压气机动叶片标模作为设计对象该叶片由nasa glenn中心的reid和moore设计并测试。对三维叶片对象截取5个截面作为造型的特征截面,在每个截面的吸力面上选取5个控制点来调整吸力面曲线的造型。同时选择3个设计参数来调整三维叶片进行积叠时的弯扭掠状态。如上所示,该设计空间共包括28个设计变量,明显超出一般代理模型优化设计方法的设计变量数量范围。
[0053]
2.性能评估模型的建立
[0054]
本次选择压气机的级效率作为优化设计的目标参数,即设计出级效率更高的叶栅几何模型。使用商业计算流体动力学(cfd)软件来评估几何设计模型的级效率,计算过程中的其他参数设置与rotor37叶片的标准设计工况一致。
[0055]
3.确定算法中的用户定义变量
[0056]
本施例中选择全局初始样本数量为50,分布方法为拉丁超立方设计方法(lhs);选择混沌多项式最高阶数为6;选择子优化初始样本数量为对应子空间维度的2倍;选择子优化最大迭代次数为对应子空间维度的6倍;确定整个算法的最大样本数量为1000。
[0057]
4.优化设计的具体过程
[0058]
参考图1,其具体过程如下:
[0059]
4a.在建立的设计空间中使用lhs方法获得分布较为均匀的50个样本坐标,对其进行性能评估获得这50个设计样本的级效率值。
[0060]
4b.使用4a中获得的样本坐标和样本值建立28维的pce拟合模型,建模后对模型预测最优值的坐标进行级效率的评估,将坐标和评估结果加入数据列表中。(由于默认优化过程中的目标为最小值,样本值设置为级效率乘以-1)
[0061]
4c.选择所有样本中级效率最大的值作为核心点,将28维问题随机分解为10个低维子问题(8个3维问题和2个2维问题)。
[0062]
4d.对10个低维问题同步地并行地完成操作,对3维问题采集6个样本作为初始样本,再进行18次迭代加点;对2维问题采集4个样本作为初始样本,再进行12次迭代加点。子空间内优化的具体过程参考图2。
[0063]
4e.将子空间优化中产生的样本及其评估值加入数据集中,使用数据集重新建立全局pce模型;
[0064]
4f.使用组合加点的方法基于10个子优化结果和更新后的全局模型选择出14个全局样本进行评估。
[0065]
4g.重复步骤4c~4f,直到样本的总数达到设置的数量1000。
[0066]
5.优化设计的结果
[0067]
在本次优化过程中共使用1000个样本,最终的级效率为87.08%较参考设计的级效率85.46%提升了1.62%,提升较为显著。
[0068]
本次优化过程中共计经历了6次分解过程,每次分解过程使用的样本数和优化结果如下表1所示。
[0069]
表1:优化结果细节
[0070][0071]
本发明的原理如下:
[0072]
本发明的最大特点是使用了创新的适用于高维度的优化算法。该方法能有效提高效率的特征是将全局模型的知识迁移到局部模型当中,这一过程是通过分层克里金模型来实现的。分层克里金模型是将两种不同精度的数据结合到一个代理模型中的算法,通常将两个数据来源分别称为高精度来源和低精度来源。在本发明的应用中,高精度来源是对应子问题中的样本,而低精度来源是上一轮更新后的全局多项式混沌拟合模型。前者随着子优化的进行会不断的添加样本,而后者在子优化的过程中始终保持不变。
[0073]
分层克里金模型的预测值公式为其中f
l
(x)是独立的确定的全局拟合模型,y
h-f
l
(xh)为子空间内模型的实际评估值与全局拟合模型预测值做差。当已经确定的模型f
l
(x)的趋势与实际子空间中的优化对象的趋势一致的时候,只需要少量的子空间中的样本就可以建立准确程度较高的代理模型并指导优化,大大加速了优化的进程。
[0074]
本发明设置超大变量的叶轮机械参数化方法;根据优化设计的设计工况设置cfd计算模型;全局范围内进行均匀的初始加点并计算评估值;在全局建立高维的pce拟合模型;将高维问题分解为多个低维子问题;对所有的子问题进行独立的代理模型优化,在优化过程中将全局pce模型作为低精度数据来源加入hk模型以实现知识迁移;将所有子问题优化结果进行组合得到一组全局样本并进行评估;更新全局模型并重复上述步骤,直到满足优化停止条件;该设计方法可以在样本数量可以接受的前提下增加设计的变量数从而扩大设计的自由度,且具有很强的并行扩展能力,设计时间短,计算效率高。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1