一种动态双模式张量管理设计方案的制作方法
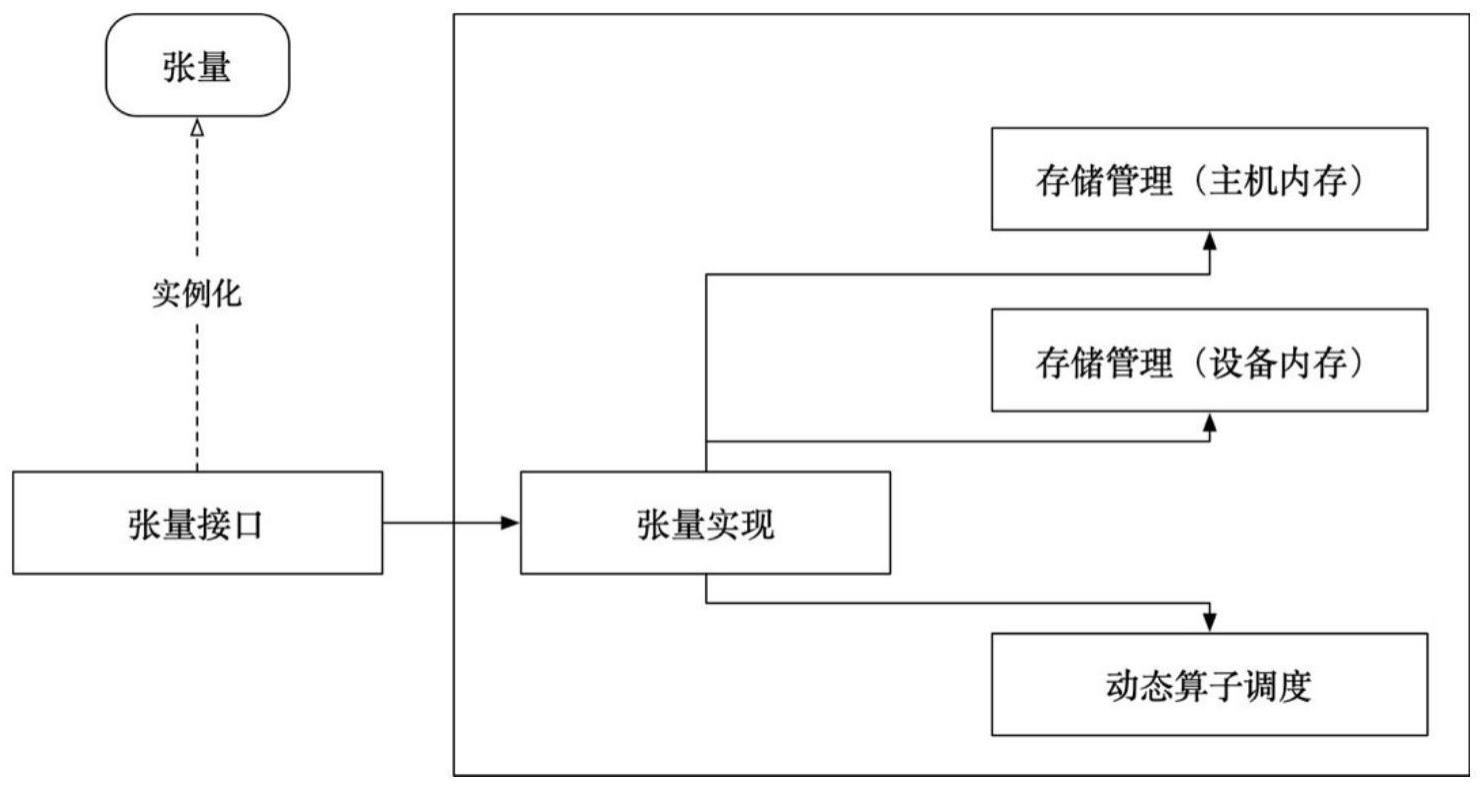
本发明涉及一种张量管理的设计,特别是一种基于神威深度学习加速器的动态双模式张量管理设计。
背景技术:
1、张量(tensor)是一种统一的用于描述多维数据的规范形式,提供了对多维数据统一的表示方式,同时在描述计算等方面简洁有效,是深度学习框架等人工智能基础软件的核心数据结构,被广泛应用于表示和描述深度学习模型的参数,输入数据(如rgb彩色图片可以表示为一个三维张量)以及模型计算过程中的中间结果。
2、工业界广泛使用的深度学习框架tensorflow以张量为核心构建了其对深度学习计算任务的核心抽象——数据流图(dataflow graph),其中图的节点为操作符(operator)表示计算,节点之间的连边为张量(tensor)表示数据,该边为有向边,其方向表示节点计算之间的依赖关系,即边的起点为产生该张量的操作符节点,终点为以该张量作为输入数据的操作符节点。数据流图形象地描述了基于张量构建的深度模型计算过程。
3、在学术研究领域逐渐占据主导地位的另一个深度学习框架pytorch在设计上则直接定位为“张量库”(a tensor library),其围绕张量这一核心抽象,定义了tensor数据结构,并构建了基于tensor的深度学习算子库,进一步形成了基于tensor的编程模型。同时,在框架内部,pytorch基于不同的硬件后端实现了特定的tensor实例。
4、因此,张量这一抽象成为了深度学习框架前端编程接口和内部实现机制融合与解耦的关键设计模块。
5、随着深度学习领域算法的不断进步,模型规模不断增大,对计算资源的需求越来越大,从gpu到领域专用的深度学习加速器,越来越多的高密度计算平台被越来越深地融合到人工智能基础设施中。
6、深度学习加速器的典型使用模式为配合一个主处理器(cpu)使用。主处理器拥有自己的内存(memory),同时运行着操作系统并负责所有的通用计算;深度学习加速器主要负责高密度深度学习算子的计算,加速器拥有自己独立的高速片上内存,主处理器内存与加速期内存之间的数据交换需要显示地调用数据传输接口完成。因此,对不同架构加速器高效适配和支持成为深度学习框架生态建设的重要内容。
7、目前,主流深度学习框架支持新硬件平台主要模式为针对不同的硬件(即深度学习加速器)实现特定的tensor实例,通过调用加速器运行时系统库提供的接口完成片上内存的申请释放和传输。不同的加速器平台有不同的高效数据布局模式,另一方面,深度学习算子类型繁多,张量维度各异,单一的数据布局模式很难发挥出加速器的性能优势,因此,如何针对不同的加速器设计高效的张量管理模式是一个重要且有挑战性的任务,也是本设计的核心目标和创新点。
8、为支持特定的深度学习硬件加速器,现有解决方案主要采用单模式的张量管理设计。具体流程如图1所示,首先框架系统软件根据用户程序的选择,在设备端初始化一个设备张量的实例,其遵循一套统一的张量接口规范(编程接口);之后,在计算过程中,大部分的算子都可以基于存储在设备内存的张量数据完成计算,情况发生在当遇到设备不支持的特殊计算或需要打印输出张量数据、以及进行某些特定数据类型的转换时,将会触发设备张量到主机张量的转换。该转换过程的第一步为在主机端初始化一个主机张量的实例,其元数据与设备张量保持一致并据此计算出所需大小的内存空间,然后调用内存拷贝操作,将张量数据由设备内存拷贝到主机内存,然后完成后续操作。
9、单模式张量管理下主要的性能损失发生在设备张量和主机张量的转换过程中,包括如下三个方面:
10、首先,框架支持将一个张量以非连续内存布局的方式与一个连续存储的张量共享内存数据,在传输此类数据时需要调用跨步模式的内存拷贝操作,该模式的拷贝较难充分利用主机与加速器之间的传输带宽,效率较低;
11、另一方面,共享数据布局增加了张量复制的机率,比如对一个非连续模式存储的张量进行reshape/resize等操作时,为了维护数据一致性,框架运行时系统会首先复制一个新的实例然后完成后续操作;
12、最后,单模式张量管理下,模型全局数据流图仍为串行流,对于现代深度学习框架提供的对模型全局数据流图进行分析的能力,未进行利用。
13、现代深度学习框架提供了对模型全局数据流图进行分析的能力,数据流图的分析结果可以用于指导数据流图张量内存布局的统一优化设计,即在模型计算开始时即完成张量布局向最优算子库布局的转换,避免计算过程中再进行频繁转换的开销。
14、而目前的双模式设计对神威深度学习加速器及对应算子库最优内存布局并不感知,无法利用全数据流的信息。
15、其次,神威架构加速器的深度学习加速库对张量的内存布局有性能要求,即只有符合特定模式的存储布局才能发挥硬件架构的计算性能。
16、神威深度学习加速器就是基于国产神威众核架构设计的面向人工智能深度模型计算任务的专用处理器。因此,如何针对神威ai加速器设计高效的张量管理模式是一个重要且有挑战性的任务,也是本设计的核心目标和创新点。
技术实现思路
1、针对上述问题,本发明给出了一种双模式张量管理设计方案,通过将主机内存和设备内存纳入统一的存储管理模块,动态的使用主机和设备内存,极大减少了频繁数据拷贝带来的系统开销;同时,针对性地设计了支持全数据流图范围内张量内存布局优化的分析引擎,结合双模式的内存管理,能够在保证框架编程灵活性的同时,充分发挥底层深度学习加速库的性能,可适用于神威深度学习加速器。
2、本发明的一种双模式张量管理设计方案,是根据给定的训练模型数据流图g、给定的深度学习加速器算子库性能特性描述表t,输出一个“主机—加速器”之间数据传输量较少的执行方案p;其中,
3、所述训练模型数据流图g用于表达深度模型的结构,表达方式为g(v,e),其中,v为结点,代表计算操作符(即算子)的集合;e为边集,即算子之间连接关系(即张量)的集合,代表数据依赖,对应数据传输操作。
4、所述深度学习加速器算子库性能特性描述表t用于描述算子计算特性的函数,描述方式是t(v),即给定算子op∈v,t(op)返回该算子在给定张量数据布局、输入张量位置情况下的归一化计算时间,该数值越大表示性能越差,即相应的计算时间越长;若该算子在当前设备不支持,则输出无穷大。
5、所述执行方案p包括:在训练模型数据流图g上添加每个算子的执行信息,所述执行信息包括:主机端执行或者设备端执行;以及,对每个边对应的数据传输的执行进行标记。
6、所述双模式张量管理设计方案的执行流程为:
7、(1)对数据流图g进行拓扑排序;
8、(2)按顺序从g中取出计算节点op,若该算子标记为已处理,则跳过;否则,对op以函数t(v)计算归一化计算时间t,即t=t(op);
9、t越大表示性能越差,即相应的计算时间越长,若该算子在当前设备不支持,则输出无穷大;
10、(3)依据t的结果标记计算节点op的执行位置:
11、若t为无穷大,则标记该算子在主机端执行;否则,标记为在设备端执行;
12、(4)标记该计算节点op为已处理;
13、(5)重复执行步骤(2)至(4)直到所有算子都被标记为已处理。
14、于一实施例中,步骤(3)还包括,当前计算节点op是从g中取出的第n个计算节点时,对当前计算节点op的输出数据即对应张量的生成位置以如下方式进行标记:
15、当前计算节点op的输出数据存储于主机端或设备端;
16、当n>1时,修改第n-1个计算节点op的输出数据存储位置与当前计算节点op的执行位置一致。
17、于一实施例中,可以进一步对数据布局优化:考虑到加速器设备对张量数据存储布局的性能要求,在本发明所述的双模式张量管理设计下,先对计算图全部操作符结点的最优数据布局进行统计,并选择使用数目最多的布局做为该数据流图的数据存储布局,对全数据流图的输入张量布局进行转换。
18、全数据流图输入张量布局的转换采用贪心的优化策略:
19、s1、依据算子库性能特性描述表t为数据流图上的每一个算子选定其最优的数据布局;
20、s2、以数据布局格式为标记将数据流图上的算子划分为不同的子图,在数据布局变化的子图之间添加布局转换操作;
21、s3、对规模(即包含的算子个数)小于给定值的子图,考虑采用邻近子图的数据布局,并重新计算性能开销,在布局转换开销和子图算子计算性能之间权衡,选择归一化计算时间最小的方案。
22、于一实施例中,步骤(3)还包括,对当前计算节点op的输出数据的版本进行标记;该方案还包括运算调度执行器,用于在方案执行时对执行方案p进行动态优化,当对从g中取出计算节点op进行计算时,运算调度执行器是基于版本号以如下方式对主机端或设备端的存储数据进行同步:
23、将当前存储设备的存储数据与待拷贝存储设备的存储数据进行版本比较,如果版本一致,则放弃拷贝数据,避免了冗余的数据拷贝。
- 还没有人留言评论。精彩留言会获得点赞!