时间序列异常检测的制作方法
时间序列异常检测
1.相关申请的交叉引用
2.本技术涉及songtao guo、robert perrin reeves、bo yang、wan qi gao、william tang、patrick ryan driscoll、shan zhou、taylor shelby burfield和adriana dominique meza与本技术在同一天同时提交的题为“time series anomaly ranking”的申请,其全部内容通过引用并入本文。
技术领域
3.本公开总体涉及机器学习中遇到的技术问题。更具体而言,本公开涉及时间序列异常检测。
背景技术:
4.互联网的兴起引起了两种不同但是相关的现象:在线网络的存在增加,其中,其对应的用户简档对大量人员可见;以及使用这些在线网络提供内容的增加。在线网络能够收集和跟踪关于各种实体(包括组织和公司)的大量数据。例如,在线网络能够跟踪从一家公司转移到另一家公司的用户,并且因此,总体而言,这些在线网络能够确定例如在特定时间段内有多少用户离开了特定公司。额外的细节可能是已知的和/或被添加到这些类型的度量,诸如用户离开公司去了哪些公司,以及在相同时间段期间有多少用户加入了特定公司。另外,存在在线网络可以确定关于用户可能感兴趣的这些公司的许多其他度量。
5.然而,在确定如何处理该信息时出现问题。存在太多潜在度量和针对所述度量的值,以至于难以确定向用户传达哪个度量/值可能更重要。
6.在大型在线网络的上下文中出现了额外的技术问题。具体而言,当处理大型在线网络时,待分析的数据量是巨大的。这样,任何潜在的解决方案将都需要可扩展以在大型在线网络中操作。
附图说明
7.通过示例而非限制的方式,在附图的图中图示了本技术的一些实施例。
8.图1是图示了根据示例性实施例的客户端-服务器系统的框图。
9.图2是示出了与本公开的一些实施例一致的在线网络的功能组件的框图,包括在本文中被称为搜索引擎的数据处理模块,以用于生成和提供针对搜索查询的搜索结果。
10.图3是更详细地图示出根据示例性实施例的图2的应用服务器模块的框图。
11.图4是图示了根据示例性实施例的时间序列中的模型拟合窗口和预测窗口的图。
12.图5是更详细地图示出根据示例性实施例的异常检测器的框图。
13.图6是根据示例性实施例的过滤和分解的示例。
14.图7是图示了根据示例性实施例的gui的洞察屏幕的屏幕截图。
15.图8是图示了根据示例性实施例的gui的异常报告屏幕的屏幕截图。
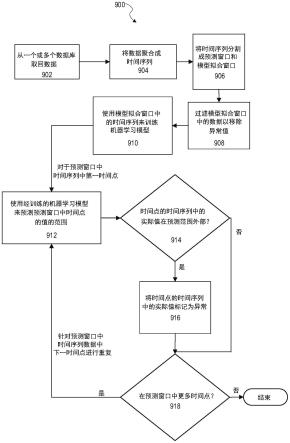
16.图9是图示了根据示例性实施例的训练和使用机器学习模型的方法的流程图。
17.图10是图示了根据示例性实施例的软件架构的框图。
18.图11图示了根据示例性实施例的计算机系统形式的机器的图解表示,在所述计算机系统内可以执行指令集合以使得所述机器执行在本文中所讨论的方法中的任意一种或多种方法。
具体实施方式
19.概述
20.本公开描述了个体地提供各种功能的方法、系统和计算机程序产品等。在以下描述中,出于解释的目的,阐述了许多具体细节以便提供对本公开的不同实施例的各个方面的透彻理解。然而,对于本领域技术人员而言将显而易见的是,可以在没有所有具体细节的情况下实践本公开。
21.在示例性实施例中,机器学习模型被训练以专门识别时间序列数据中的异常点。所述模型能够同时并行地应用于许多不同的时间序列,从而得到针对大规模在线网络的可扩展的解决方案。所述模型对在指定的时间窗口内的每个数据点进行分类,并且针对下游应用输出丰富的上下文信息,诸如对异常数据点的排名和显示。
22.描述
23.所公开的实施例提供了一种用于使用机器学习算法来训练机器学习模型以识别离散时间序列中的异常数据点的方法、装置和系统。离散时间序列包括由时间间隔分开的数据点。这些时间间隔可以是有规律的(例如,一个月一次)或者无规律的(例如,每次用户登录时)。尽管本公开将提供时间间隔是规律的特定示例,但是本领域普通技术人员将认识到,可能存在本公开中所描述的技术能够被应用于具有无规律时间间隔的离散时间序列的情况。
24.图1是图示了根据示例性实施例的客户端-服务器系统100的框图。联网系统102经由网络104(例如,互联网或广域网(wan))向一个或多个客户端提供服务器侧功能。例如,图1图示了在相应客户端机器110和112上执行的网络客户端106(例如,浏览器)和程序化客户端108。
25.应用程序接口(api)服务器114和网络服务器116被耦合到一个或多个应用服务器118,并且分别向一个或多个应用服务器118提供程序化和网络接口。(一个或多个)应用服务器118托管一个或多个应用120。(一个或多个)应用服务器118继而被示为被耦合到一个或多个数据库服务器124,所述数据库服务器124促进对一个或多个数据库126的访问。尽管(一个或多个)应用120在图1中被示为形成联网系统102的一部分,但是将意识到,在替代实施例中,(一个或多个)应用120可以形成与联网系统102分开并且不同的服务的一部分。
26.此外,尽管在图1中所示的客户端-服务器系统100采用客户端-服务器架构,但是本公开当然并不限于这样的架构,并且同样可以应用于例如分布式或对等架构系统中。各种应用120也可以被实现为独立的软件程序,其不一定具有联网能力。
27.网络客户端106经由由网络服务器116支持的网络接口访问各种应用120。类似地,程序化客户端108经由由api服务器114提供的程序化接口访问由(一个或多个)应用120提供的各种服务和功能。
28.图1还图示了在第三方服务器130上执行的第三方应用128,其具有经由由api服务
器114提供的程序化接口对联网系统102的程序化访问。例如,第三方应用128可以利用从联网系统102取回的信息来支持由第三方托管的网站上的一项或多项特征或功能。例如,第三方网站可以提供由联网系统102的相关应用120支持的一项或多项功能。
29.在一些实施例中,在本文中所提及的任意网站可以包括可以在各种设备上呈现的在线内容,所述设备包括但不限于:台式个人计算机(pc)、膝上型计算机、以及移动设备(例如,平板计算机、智能手机等)。在该方面中,这些设备中的任意设备可以被用户用于使用本公开的特征。在一些实施例中,用户能够使用移动设备(机器110、112和第三方服务器130中的任意一个可以是移动设备)上的移动应用来访问和浏览在线内容,诸如在本文中所公开的在线内容中的任意在线内容。移动服务器(例如,api服务器114)可以与移动应用和(一个或多个)应用服务器118通信以便使本公开的特征在移动设备上可用。
30.在一些实施例中,联网系统102可以包括在线网络的功能组件。图2是示出了与本公开的一些实施例一致的在线网络的功能组件的框图,所述功能组件包括在本文中被称为搜索引擎216的数据处理模块,以用于生成和提供针对搜索查询的搜索结果。在一些实施例中,搜索引擎216可以驻留在图1中的(一个或多个)应用服务器118上。然而,设想到了其他配置也在本公开的范围之内。
31.如在图2中所示的,前端可以包括用户界面模块(例如,网络服务器116)212,其接收来自各种客户端计算设备的请求并且将适当的响应传送给请求客户端设备。例如,(一个或多个)用户界面模块212可以接收超文本传输协议(http)请求或者其他基于网络的api请求形式的请求。另外,用户交互检测模块213可以被提供用于检测用户与不同应用120、服务和所呈现的内容的各种交互。如在图2中所示的,在检测到特定交互时,用户交互检测模块213在用户活动和行为数据库222中记录所述交互,包括交互类型以及与交互相关的任意元数据。
32.应用逻辑层可以包括一个或多个各种应用服务器模块214,其结合(一个或多个)用户界面模块212来生成具有从数据层中的各种数据源取回的数据的各种用户界面(例如,网页)。在一些实施例中,个体应用服务器模块214被用于实现与各种应用120和/或由在线网络提供的服务相关联的功能。
33.如在图2中所示的,所述数据层可以包括若干数据库126,诸如用于存储包括用户简档数据和针对各种组织(例如,公司、学校等)的简档数据两者的简档数据的简档数据库218。与一些实施例一致的,当个人最初注册成为在线网络的用户时,将提示所述个人提供一些个人信息,诸如他的或她的姓名、年龄(例如,出生日期)、性别、兴趣、联系信息、家乡、地址、配偶和/或家庭成员的姓名、教育背景(例如,学校、专业、入学和/或毕业日期等)、工作经历、技能、专业组织等。该信息例如被存储在简档数据库218中。类似地,当组织的代表最初向在线网络注册组织时,可以提示所述代表提供关于所述组织的特定信息。例如,该信息可以被存储在简档数据库218或另一数据库(未示出)中。在一些实施例中,可以处理所述简档数据(例如,在后台或离线地)以生成各种导出的简档数据。例如,如果用户已经提供了关于所述用户在相同组织或不同组织中担任的各种职务头衔的信息以及持续多长时间,则能够使用该信息来推断或导出指示用户的总体资历级别或者在特定组织内的资历级别的用户简档属性。在一些实施例中,从一个或多个外部托管的数据源导入或者以其他方式访问数据可以丰富针对用户和组织两者的简档数据。例如,特别是针对组织而言,财务数据可
以从一个或多个外部数据源导入,并且成为组织的简档的一部分。在本文档中稍后将更详细地描述对组织数据的这种导入以及对数据的丰富。
34.一旦注册,用户就可以邀请其他用户,或者被其他用户邀请,以经由在线网络进行连接。“连接”可以构成用户的双边协议,使得双方用户都承认连接的建立。类似地,在一些实施例中,用户可以选择“关注”另一用户。与建立连接相反,“关注”另一用户的概念通常是单边操作,并且至少在一些实施例中,不需要被关注的用户的确认或批准。当一个用户关注另一用户时,关注的用户可以接收由被关注的用户的状态更新(例如,在活动或内容流中)或者由被关注的用户发布的、与被关注的用户进行的各种活动相关的其他消息。类似地,当用户关注组织时,所述用户就有资格接收代表所述组织发布的消息或状态更新。例如,代表用户关注的组织而发布的消息或状态更新将出现在用户的个性化数据馈送中,通常被称为活动流或内容流。在任意情况下,用户与其他用户或者与其他实体和对象建立的各种关联和关系在社交图数据库220中的社交图内进行存储和维护。
35.当用户与经由在线网络可用的各种应用120、服务和内容交互时,可以跟踪用户的交互和行为(例如,所查看的内容、所选择的链接或按钮、所响应的消息等),并且可以由用户活动和行为数据库222来记录或存储关于用户的活动和行为的信息,例如,如在图2中所指示的。然后,搜索引擎216可以使用该记录的活动信息来确定针对搜索查询的搜索结果。
36.在一些实施例中,数据库218、220和222可以被并入到图1中的(一个或多个)数据库126中。然而,其他配置也在本公开的范围之内。
37.尽管未示出,但是在一些实施例中,社交网络系统210提供api模块,应用120和服务能够经由所述api模块来访问由在线网络提供或维护的各种数据和服务。例如,使用api,应用能够请求和/或接收一个或多个推荐。这样的应用120可以是基于浏览器的应用120或者可以是特定于操作系统的。具体地,一些应用120可以驻留在具有移动操作系统的一个或多个移动设备(例如,电话或平板计算设备)上并且(至少部分地)在其上执行。此外,尽管在许多情况下,利用所述api的应用120或服务可以是由操作在线网络的实体开发和维护的应用120和服务,但是除了数据隐私问题外,没有任何其他因素阻止api在特殊布置下被提供给公众或者特定第三方,由此使得导航推荐对第三方应用128和服务可用。
38.尽管本公开的特征在本文中被称为在网页的上下文中使用或呈现,但是设想到了任何用户界面视图(例如,在移动设备上或桌面软件上的用户界面)在本公开的范围之内。
39.在示例性实施例中,当用户简档被索引时,创建和存储前向搜索索引。搜索引擎216促进针对所述在线网络内的内容的索引和搜索,诸如索引和搜索被包含在所述数据层中的数据或信息,诸如简档数据(被存储在例如简档数据库218中)、社交图数据(被存储在例如社交图数据库220中)以及用户活动和行为数据(被存储在例如用户活动和行为数据库222中)。搜索引擎216可以在索引或者其他类似结构中收集、解析和/或存储数据,以响应于所接收到的、针对信息的查询来促进对信息的识别和取回。这可以包括但不限于:前向搜索索引、倒排索引、n-gram索引等。
40.图3是根据示例性实施例的更详细地图示出图2的应用服务器模块214的框图。尽管在许多实施例中,应用服务器模块214将包含被用于在社交网络系统210内执行各种不同动作的许多子组件,但是在图3中仅描绘了与本公开相关的那些组件。
41.洞察引擎300可以生成关于从一个或多个数据库获得的数据的一个或多个洞察。
这些数据库可以包括例如:简档数据库218、社交图数据库220、和/或用户活动和行为数据库222等。在示例性实施例中,洞察引擎300可以包括数据预处理器302、缩减器/组合器304、和异常检测器306。数据预处理器302用于从所述数据库收集相关信息并且基于所述信息来生成时间序列。由数据预处理器302执行的预处理操作可以包括提取针对指定段的度量,并且将那些度量聚合成时间序列格式。多个时间序列中的每个时间序列然后可以利用《键,值》对被流送到缩减器/组合器304。“键”是将被用于在并行处理期间均匀分布任务的随机键,而“值”表示时间序列。
42.在示例性实施例中,r编程语言环境可以被用于实现缩减器/组合器304。r是用于数据分析的计算环境并且提供用于并行计算的包。具体而言,r能够在hadoop数据库上提供并行的数据库内分析。hadoop数据库是能够在分布式环境中存储和管理极大量数据的数据库,并且因此通常被大型在线网络使用。
43.缩减器/组合器304经由高速缓存的r环境和脚本来接收所述时间序列。其可以对所述时间序列进行复制和排序(sort)并且启动两个处理线程——主线程308和收集器线程310。主线程308经由管线312将时间序列数据馈送到异常检测器306。然后,异常检测器306将所识别出的异常经由管线314馈送到缩减器/组合器304。然后,缩减器/组合器304能够输出所述异常以及其分类和上下文。
44.这提供了一种被构建在开源云框架上并且提供可靠的时间序列分析的高效可扩展解决方案。其允许每天评估数十亿个时间序列,而无需依赖商业时间序列引擎。在现有技术的软件解决方案中,异常检测需要串行地处理,并且因此无法在合理的时间量内在数百万或者甚至数十亿数据点的尺度上在时间序列数据中的异常检测。在示例性实施例中,所述异常检测能够对每个时间序列并行地执行,训练针对特定时间序列的模型以使用来自时间序列中较早的数据来检测时间序列中较晚数据中的异常,从而允许通过并行化计算而在合理的时间量内执行在数百万或数十亿个数据点的尺度上在时间序列数据中的异常检测。
45.具体而言,当分析针对大公司的数据时,诸如拥有数十万雇员的公司,并且当经由用户简档信息来收集数据时,诸如由社交网络服务收集和存储的用户简档,其中,用户列出其当前雇主(并且有时是以前的雇主),收集和分析所述数据会是非常耗时的。例如,为了确定当月的总人数,扫描当月的所有用户简档以识别已经将公司(或者相关条目)列为当前雇主的用户。然后,如果分析提供商想要为数百、数千、或者甚至数十万雇员提供分析,则需要针对每个公司重复该过程。另外,整个过程将需要定期地(例如,每个月)重复以计算针对每个雇主的时间序列。然后,需要将该数据馈送到分析组件中,以对时间序列中的所有数据执行数据分析。通过从被用于训练所述模型的时间序列(预测窗口)中排除所述数据中的一些数据,这节省了对预测窗口中的该时间序列数据的计算。
46.因此,如果以时间序列提供三年价值的数据,则现有技术解决方案将通过分析所有三年价值的数据来识别那些三年价值的数据中的异常。在示例性实施例中,一年的预测窗口长度和两年的模型拟合窗口长度将意味着,仅有三年数据中的前两年数据将被用于识别异常,并且其将仅被用于识别三年数据中的最近一年数据中的异常。因此,通过减少用于进行预测的数据点的数量和减少将对其进行那些预测的数据点的数量两者来节省计算。
47.通过以下事实来提供额外的节省:涉及预测针对时间序列数据的值的现有技术解决方案利用在多于一个时间序列上训练的模型(通常在可用时间序列数据整体上训练的,
能够按行业进行分解)。在示例性实施例中,对模型的训练仅对来自感兴趣的时间序列的数据执行,允许所述模型训练与针对其他时间序列的模型训练并行地执行。例如,如果可用数据包括针对五十个不同公司的三年价值信息,则现有技术的机器学习解决方案将使用针对所有公司的所有三年价值信息来训练全局模型,并且使用该全局模型来预测未来的时间序列数据。在具有一年的预测窗口长度和两年的模型拟合窗口长度的示例性实施例中,将训练五十个不同的模型,每个模型仅使用对应时间序列中的前两年数据进行训练。通过独立地对其进行训练,所述训练能够被并行化以改善性能。
48.异常检测器306实施机器学习模型316,机器学习模型316将时间序列中的数据点与估计进行比较。所述估计是使用时间序列分析执行的,并且结果表示所述机器学习模型在给定时间具有特定置信水平的值的期望。因此,例如,所述估计可以指示在时间序列中的特定时间点(例如,2020年4月)的雇员总人数应当在150到160之间,并且针对该时间点的实际值可以与估计进行比较以确定其是否异常。
49.值得注意的是,针对给定的时间序列,机器学习模型316能够将所述时间序列分成两个窗口:模型拟合窗口和预测窗口。图4是图示了根据示例性实施例的时间序列中的模型拟合窗口400和预测窗口402的图。预测窗口402表示最近发生的数据点,其中,“最近”被定义为距当前时间段的预定数量的时间间隔。例如,如果所述时间序列中的时间间隔是月,则预测窗口402可以包括来自过去4个月的数据点,其中,较旧的数据点在模型拟合窗口400中。
50.尽管在一些示例性实施例中,预测窗口402的长度可以是预定的和固定的,但是在其他示例性实施例中,该长度可以是可变的和/或动态的。事实上,该长度可以针对不同的上下文进行个性化。例如,特定类型的时间序列可以具有比其他类型更长的预测窗口402长度,或者其可以基于数据适用的公司或查看者进行定制。在示例性实施例中,可以维持在上下文与长度之间的映射,使得该过程涉及确定当前上下文、从所述映射中取回对应的长度、以及将该长度用于预测窗口。在另一示例性实施例中,能够训练另一机器学习模型以输出针对输入上下文/用户/公司的长度。例如,关于用户a(或者与用户a相似的用户)与显示异常数据点的图形用户界面的过去交互的数据能够被用于训练模型,所述模型预测最有可能使得用户a与在图形用户界面中提供的时间序列分析的结果进行交互的预测窗口长度。
51.在示例性实施例中,可以通过首先获得一组样本数据中的过去交互来确定动态预测窗口长度。该组可以基于所述组中的样本数据之间的共同特性(无论是广义的还是狭义的)来确定,并且能够将所述共同特性选择为人们想要针对其进行“个性化”或定制长度的任意属性。在狭义的情况下,能够获得仅属于个体用户和与个体用户相似的用户(如通过不只用户简档信息的相似度阈值而确定的,诸如工作经历、教育、位置和技能)的样本数据。在更广义的情况下,能够获得与特定雇主聘用的所有用户有关的样本数据。无论所述共同特性如何,所述样本数据都可以包括用户之间的交互以及在图形用户界面中呈现的异常。这些交互可以是积极的(诸如选择或悬停在所呈现的异常上方以查看关于所呈现的异常的额外信息),也可以是消极的(诸如已经与异常一起呈现但是没有对其进行选择,或者在提供这样的选项时不对其进行理会)。积极的交互和消极的交互可以分别被标记为积极的或消极的,并且被馈送到机器学习算法以训练专门的预测窗口长度确定机器学习模型。所述训练可以包括要被应用于关于用户的特征数据的学习权重(系数)。所述预测窗口长度确定机
器学习模型然后可以将这些权重应用于所述图形用户界面可能当前被呈现给的特定用户的特征数据,输出针对特定用户的专门预测长度,因此动态地确定所述预测窗口长度并且潜在地影响向特定用户呈现哪些异常。例如,如果用户在过去6个月内并且没有更久的时间始终选择异常,则先前设置为12个月的预测窗口长度可能被更改为6个月。
52.可以采用类似的过程来动态地确定模型拟合窗口的长度。
53.返回到被用于预测针对时间序列中的数据点的值的机器学习模型,该模型能够以不同的置信水平来输出针对数据点的预测值范围。这也在图4中描绘。能够看到,在此机器学习模型已经输出了70%置信区间404和99%置信区间406,但是机器学习模型能够输出任意数量的不同置信区间范围。
54.在选定的置信区间之外的预测窗口中的数据值被认为是异常的。在示例性实施例中,99%置信区间406范围是用于对数据点是否异常进行分类的范围。然而,应当注意的是,该选择不一定是固定的或预先确定的。与预测窗口402长度一样,在其他示例性实施例中,该长度可以是可变的和/或动态的。实际上,该选择可以针对不同的上下文进行个性化。例如,特定类型的时间序列可以使用99%的置信区间,而其他类型的时间序列可以使用95%置信区间,或者可以基于数据适用的公司或查看者来定制所述区间。如下文将描述的,该确定可以由分类组件做出。在一些示例性实施例中,所述机器学习算法可以被用于基于与由图形用户界面的报告工具显示的关于异常的信息的用户交互来学习置信区间百分比。因此,例如,例行点击报告工具中所显示的异常的用户可能使得机器学习模型被重新训练以将置信区间从99%下调到95%以检测更多异常。
55.图5是更详细地图示出根据示例性实施例的异常检测器306的框图。在此,异常检测器306包括解析组件500。解析组件500解析原始输入并且创建归一化的时间序列。例如,在每月时间序列中,预期在给定时间范围内的每个月都应当具有有效值,即使其为零。如果原始输入缺少针对给定月份的数据点,则解析组件500对其做出推断。在示例性实施例中,该推断是通过在缺失数据点周围内插值来执行的。例如,如果存在针对2020年除了四月之外的所有月份的值,则解析组件500可以通过对三月和五月的值求平均值来推断针对四月的值。
56.分割组件502将所述时间序列分割成模型拟合窗口和预测窗口,如上文所描述的。这在数据的新鲜度与准确性(其受数据成熟度的影响)之间提供了很好的权衡。
57.分解和过滤组件504然后用于过滤不满足一些最低要求的任意时间序列。例如,如果时间序列太短而甚至无法覆盖预测窗口,或者不满足一些其他定义的最小长度要求,则可能被过滤掉。针对任何其他未过滤掉的时间序列,分解和过滤组件504然后可以用于将所述时间序列的模型拟合窗口部分分解为趋势、季节和噪声分量以用于建模。这允许每个时间序列中的预测窗口本质上基于相同时间序列的模型拟合窗口中的数据而具有其自己的模型。值得注意的是,所述模型拟合窗口中的异常值(outlier)能够消极地影响在所述预测窗口中的估计。可以移除这样的异常值。目标是利用辅助机器学习模型进行其预测和分类的能力的修改组件在模型拟合窗口内形成新的时间序列。
58.具体而言,时间序列t被分解为趋势c
trend
,最多m个季节分量c
seasonal
和噪声(剩余)分量c
noise
:
59.t=c
trend
+c
seasonal1
..+.+c
seasonalm
+c
noise
60.使用运行中值(具有默认窗口大小)来增强趋势分量(c
trend
)。经增强的趋势分量被表示为:
61.c'
trend
=runmed(c
trend
,k
window-size
)。
62.生成新的噪声分量:c'
noise
=c
noise
+c
trend-c'
trend
63.这是通过首先将所述时间序列数据分解为趋势、季节和噪声分量来实现的。针对每个时间序列存在仅一个趋势分量以及仅一个噪声分量,但是可能存在一个或多个季节分量。mstl可以被用于该过程。
64.mstl是处理潜在的多个季节时间序列的函数。其通过使用季节趋势分解(诸如stl)迭代地估计每个季节分量来操作。所述趋势分量是针对stl的最后一次迭代而计算的。stl是用于分解季节时间序列的过滤程序。stl包括两个递归程序:嵌套在外循环(loop)内部的内循环。在每次通过内循环时,季节和趋势分量都被更新一次。内循环的每次完整运行包括n(i)次这样的通过。外循环的每次通过都包括内循环,然后是对健壮性权重的计算。这些权重用于内循环的下一次运行,以减少瞬态、异常行为对趋势和季节分量的影响。在所有健壮性权重等于1的情况下执行外循环的初始通过,并且然后执行外循环的n(o)次通过。在示例性实施例中,n(o)和n(i)是预设的和静态的。
65.内循环的每次通过包括更新季节分量的季节平滑,随后是更新趋势分量的趋势平滑。具体而言,计算去趋势序列。然后,去趋势序列中的每个子序列都通过平滑器(诸如loess平滑器)进行平滑。然后,将低通滤波应用于经平滑的子序列,并且从经平滑和过滤的子序列中减去季节分量。这被称为对经平滑的子序列去趋势。然后,计算经去季节化的序列。然后,对经去季节化的序列进行平滑(诸如通过使用loess平滑器)。
66.然后,外循环定义针对其中时间序列没有缺失值的每个时间点的权重。这些权重被称为健壮性权重,并且反映剩余部分的极端程度(时间序列减去趋势分量减去季节分量)。可以使用双平方权重函数来计算所述健壮性权重。然后重复所述内循环,但是在平滑中,针对特定时间的值的邻域权重乘以对应的健壮性权重。
67.所述迭代可以继续直到已经发生预设次数的迭代。
68.然后,对噪声分量(c'
noise
)执行异常值检测并且移除检测到的噪声。无异常值噪声分量被表示为c”noise
。
69.然后,利用经修改的分量来形成新的时间序列:
70.t'=t-(c'
noise-c”noise
e)
71.图6是根据示例性实施例的过滤和分解的示例。时间序列数据600表示特定公司随时间的聘用数量。值得注意的是,在2018年12月存在一个明显的异常值602。可以假设模型拟合窗口包括2017年和2018年,并且因此该异常值602会显著影响针对预测窗口(其包括2019年)的预测,使得其在预测窗口中更难检测异常。然而,为了识别该异常值602确实是异常值,模型拟合窗口中的时间序列数据600被分解为趋势分量604、季节分量606和剩余分量608(本质上是噪声)。尽管季节分量606指示聘用存在一定的季节性,但是事实上即使将该分量分解出去,2018年12月的剩余分量608仍然相当强,这指示该点是异常值。因此,在用于预测之前,可以将其移除或简单地修改为更“典型”的水平(即,简单地忽略2018年12月的数据点或者将“46”更改为“3”以更符合过去的季节聘用趋势,诸如通过对周围值进行平均)。在该上下文中,异常值(诸如异常值602)被定义为高于或低于时间序列中的其他值超过预
定量或百分比的任意值。
72.返回参见图5,模型训练组件506然后使用模型拟合窗口中的(可能经修改的)时间序列数据来训练机器学习模型。在示例性实施例中,在该过程期间利用指数平滑(ets)和自回归综合移动平均线(arima)。
73.机器学习算法可以从许多不同的潜在监督或无监督机器学习算法中选择。监督学习算法的示例包括人工神经网络、贝叶斯网络、基于实例的学习、支持向量机、随机森林、线性分类器、二次分类器、k最近邻、决策树和隐马尔可夫模型。无监督学习算法的示例包括期望最大化算法、向量量化和信息瓶颈方法。在示例性实施例中,使用二元逻辑回归模型。二元逻辑回归处理因变量的观察结果仅能够具有两种可能类型的情况。逻辑回归被用于基于自变量(预测子)的值来预测一种情况的可能性或者另一情况的可能性。
74.神经网络是包含互连节点层的深度学习机器学习模型。每个节点是感知器,并且类似于多元线性回归。感知器将由多元线性回归产生的信号馈送到可能非线性的激活函数中。在多层感知器(mlp)中,感知器被布置在互连层中。输入层收集输入模式。输出层具有输入模式可以映射到的分类或输出信号。
75.隐藏层微调输入权重,直到神经网络的误差幅度最小。隐藏层推断输入数据中具有关于输出的预测能力的显著特征。
76.在示例性实施例中,还可以在稍后基于用户接收到的反馈或者基于自先前训练以来随时间接收到的额外(例如,新的)训练数据而重新训练所述机器学习模型。反馈可以是观看者(用户)与显示关于异常的信息的图形用户界面的报告工具的交互的形式。因此,例如,如果特定用户或特定类型的用户结束与报告工具中所显示的检测到的异常的显著交互,则该交互可以被用于重新训练所述模型,可能导致预测窗口的长度变化和/或置信区间百分比变化。
77.预测组件508然后可以应用经训练的模型来生成针对预测窗口中的时间序列中的数据的预测。这将针对每个数据点基于期望的预测水平置信度(例如,99%)而返回预测值(v
t
')和期望水平的预测区间([z
lower
,z
upper
])。预测区间量化从总体(population)估计的单个观察的不确定性。其与置信区间不同,置信区间量化估计出的总体变量的不确定性,诸如均值或标准偏差。预测区间比置信区间更宽,因为其考虑了与不可约误差相关联的不确定性。
[0078]
然后,分类组件510可以将每个数据点与预测区间进行比较,并且如果其落在预测区间的外部(低于z
lower
或高于z
upper
),则其被分类为异常。在一些情况下,对低异常(值低于预测区间的异常)和高异常(值高于预测区间的异常)之间的分类进行区分,这可以稍后在针对异常执行排名和/或显示时使用。
[0079]
分类组件510还可以将上下文信息作为元数据附加到结果分类。该上下文信息可以包括以下内容:
[0080][0081][0082]
图7和图8是图形用户界面(gui)的示例,其呈现了关于使用上述方法检测到的异常的洞察。图7是图示了根据示例性实施例的gui的洞察屏幕700的屏幕截图。在此,异常的文本指示702连同供查看者选择查看整个报告的链接704一起被呈现。对链接704的选择使得图8中的gui被启动。图8是图示了根据示例性实施例的gui的异常报告屏幕800的屏幕截图。在此,异常802以图形方式突出显示,以图示出异常在时间序列中的位置以及其与其他数据点的不同。通过对所述模型的重新训练,在异常报告屏幕800(和/或者其他异常报告屏幕)中对异常802和/或者其他异常的用户选择可以使得所述模型在未来时间序列分析中动态改变预测窗口的置信区间百分比和/或长度。
[0083]
图9是图示了根据示例性实施例的训练和使用机器学习模型的方法900的流程图。在操作902处,从一个或多个数据库取回数据。在操作904处,所述数据被聚合成时间序列数据。在操作906处,所述时间序列数据被分割成预测窗口和模型拟合窗口。所述预测窗口包括针对特定时间点的时间序列数据和针对不早于多个时间点中的特定时间点的时间点的时间序列数据,并且所述模型拟合窗口包括不晚于特定时间点的时间序列数据。
[0084]
在操作908处,所述模型拟合窗口中的数据被过滤以移除异常值,具体地通过将所述数据分解成趋势、季节和剩余分量并且基于剩余分量来识别异常值。在操作910处,使用模型拟合窗口中的时间序列数据来训练机器学习模型以预测针对预测窗口中的时间点的
数据值范围。该范围可以基于特定百分比置信区间,其中所述百分比是在模型训练期间学习的。具体而言,所述百分比置信区间是指示置信区间的大小的值,并且该值可以基于用户交互数据在机器学习期间学习,如先前所描述的。
[0085]
然后,针对预测窗口中的一个或多个时间点中的每个时间点开始循环。在操作912处,所述机器学习模型被用于预测在预测窗口中针对对应时间点的值的范围。在操作914处,确定针对对应时间点的时间序列数据中的实际值是否在预测范围的外部。如果是,则在操作916处,将针对对应时间点的时间序列中的实际值标记为异常。如果否,则方法900跳到操作918而不执行操作916。在操作918处,确定在预测窗口中是否存在更多时间点。如果是,则方法900针对预测窗口中的时间序列数据中的下一时间点循环回到操作912。如果否,则方法900结束。
[0086]
图10是图示了能够被安装在如上文所描述的设备中的任意一个或多个设备上的软件架构1002的框图1000。图10仅仅是软件架构的非限制性示例,并且将意识到,能够实现许多其他架构以促进在本文中所描述的功能。在各种实施例中,软件架构1002由诸如图11的机器1100的硬件来实现,机器1100包括处理器1110、存储器1130和输入/输出(i/o)组件1150。在该示例性架构中,软件架构1002能够被概念化为层堆栈,其中,每个层可以提供特定功能。例如,软件架构1002包括诸如操作系统1004、库1006、框架1008和应用1010的层。在操作上,应用1010通过软件堆栈调用api调用1012,并且响应于api调用1012接收消息1014,与一些实施例一致。
[0087]
在各种实现方式中,操作系统1004管理硬件资源并且提供公共服务。操作系统1004包括例如内核1020、服务1022和驱动器1024。内核1020用作在硬件与其他软件层之间的抽象层,与一些实施例一致。例如,内核1020提供存储器管理、处理器管理(例如,调度)、组件管理、联网和安全设置等功能。服务1022能够为其他软件层提供其他公共服务。根据一些实施例,驱动器1024负责控制底层硬件或者与底层硬件接口。例如,驱动器1024能够包括:显示驱动器、相机驱动器、或低能量驱动器、闪存驱动器、串行通信驱动器(例如,通用串行总线(usb)驱动器)、驱动器、音频驱动器、电源管理驱动器等。
[0088]
在一些实施例中,库1006提供由应用1010利用的低级公共基础设施。库1006能够包括能够提供诸如存储器分配功能、字符串操纵功能、数学函数等功能的系统库1030(例如,c标准库)。另外,库1006能够包括api库1032,诸如媒体库(例如,支持对各种媒体格式的呈现和操纵的库,所述格式诸如是运动图像专家组4(mpeg4)、高级视频编码(h.264或avc)、运动图像专家组层3(mp3)、高级音频编码(aac)、自适应多速率(amr)音频编解码器、联合图像专家组(jpeg或jpg)或便携式网络图形(png))、图形库(例如,用于在显示器上的图形上下文中以二维(2d)和三维(3d)方式呈现的opengl框架)、数据库库(例如,提供各种关系数据库功能的sqlite)、网络库(例如,提供网络浏览功能的webkit)等。库1006还可以包括多种其他库1034以向应用1010提供许多其他api。
[0089]
根据一些实施例,框架1008提供能够由应用1010利用的高级公共基础设施。例如,框架1008提供各种图形用户界面功能、高级资源管理、高级位置服务等。框架1008能够提供能够由应用1010利用的广泛的其他api,其中的一些可以专用于特定操作系统1004或平台。
[0090]
在示例性实施例中,应用1010包括家庭应用1050、联系人应用1052、浏览器应用1054、书籍阅读器应用1056、位置应用1058、媒体应用1060、消息传递应用1062、游戏应用
1064以及广泛种类的其他应用,诸如第三方应用1066。根据一些实施例,应用1010是执行在程序中定义的功能的程序。能够采用各种编程语言来创建以各种方式构建的应用1010中的一个或多个应用,诸如面向对象的编程语言(例如,objective-c、java或c++)或过程编程语言(例如,c或汇编语言)。在特定示例中,第三方应用1066(例如,由特定平台的供应商以外的实体使用android
tm
或ios
tm
软件开发工具包(sdk)开发的应用)可以是在移动操作系统(诸如ios
tm
、android
tm
、或者其他移动操作系统)上运行的移动软件。在该示例中,第三方应用1066能够调用由操作系统1004提供的api调用1012以促进在本文中所描述的功能。
[0091]
图11图示了根据示例性实施例的计算机系统形式的机器1100的图解表示,在所述计算机系统中可以运行指令集合以使得机器1100执行在本文中所讨论的方法中的任意一种或多种方法。具体而言,图11示出了计算机系统的示例性形式的机器1100的图解表示,其中,指令1116(例如,软件、程序、应用1010、小程序、app或者其他可执行代码)用于使得机器1100可以执行在本文中所讨论的方法中的任意一种或多种方法。例如,指令1116可以使得机器1100执行图9的方法900。另外地或替代地,指令1116可以实现图1-9,等等。指令1116将通用的非编程机器1100转换成被编程为以所描述的方式执行所描述和图示的功能的特定机器1100。在替代实施例中,机器1100作为独立设备操作或者可以被耦合(例如,联网)到其他机器。在联网部署中,机器1100可以在服务器-客户端网络环境中以服务器机器或客户端机器的能力来操作,或者作为对等(或者分布式)网络环境中的对等机器运行。机器1100可以包括但不限于:服务器计算机、客户端计算机、pc、平板计算机、膝上型计算机、上网本、机顶盒(stb)、便携式数字助理(pda)、娱乐媒体系统、蜂窝电话、智能手机、移动设备、可穿戴设备(例如,智能手表)、智能家居设备(例如,智能家电)、其他智能设备、网络设备、网络路由器、网络交换机、网桥或者能够依次或者以其他方式执行指令1116的任意机器,这些指令指定机器1100要采取的动作。此外,尽管仅图示了单个机器1100,但是术语“机器”还应当被视为包括单独或联合运行指令1116以执行在本文中所讨论的方法中的任意一种或多种方法的机器1100的集合。
[0092]
机器1100可以包括处理器1110、存储器1130和i/o组件1150,其可以被配置为诸如经由总线1102彼此通信。在示例性实施例中,处理器1110(例如,中央处理单元(cpu)、精简指令集计算(risc)处理器、复杂指令集计算(cisc)处理器、图形处理单元(gpu)、数字信号处理器(dsp)、专用集成电路(asic))、射频集成电路(rfic)、另一处理器或者其任何合适的组合)可以包括例如可以执行指令1116的处理器1112和处理器1114。术语“处理器”旨在包括多核心处理器1110,其包括可以同时地执行指令1116的两个或更多个独立处理器1112(有时被称为“核心”)。尽管图11示出了多个处理器1110,但是机器1100可以包括具有单个核心的单个处理器1112、具有多个核心的单个处理器1112(例如,多核心处理器)、具有单个核心的多个处理器1110、具有多个核心的多个处理器1110,或者其任意组合。
[0093]
存储器1130可以包括主存储器1132、静态存储器1134和存储单元1136,其全部都诸如经由总线1102对处理器1110可访问。主存储器1132、静态存储器1134和存储单元1136存储体现在本文中所描述的方法或功能中的任意一种或多种方法或功能的指令1116。在由机器1100运行期间,指令1116还可以完全或部分地驻留在主存储器1132内、在静态存储器1134内、在存储单元1136内、在处理器1110中的至少一个处理器内(例如,在处理器的高速
缓存内)或者其任意合适的组合。
[0094]
i/o组件1150可以包括多种组件以接收输入、提供输出、产生输出、传输信息、交换信息、捕获测量结果等。被包含在特定机器1100中的特定i/o组件1150将取决于机器1100的类型。例如,诸如移动电话的便携式机器将可能包括触摸输入设备或者其他这样的输入机制,而无头服务器机器可能不包括这样的触摸输入设备。将意识到,i/o组件1150可以包括在图11中未示出的许多其他组件。i/o组件1150根据功能进行分组仅仅是为了简化下文的讨论,并且分组绝不是限制性的。在各种示例性实施例中,i/o组件1150可以包括输出组件1152和输入组件1154。输出组件1152可以包括视觉组件(例如,诸如等离子显示面板(pdp)、发光二极管(led)显示器、液晶显示器(lcd)、投影仪或阴极射线管(crt)的显示器)、声学组件(例如,扬声器)、触觉组件(例如,振动电机、阻力机构)、其他信号生成器,等等。输入组件1154可以包括字母数字输入组件(例如,键盘、被配置为接收字母数字输入的触摸屏、光电键盘、或者其他字母数字输入组件)、基于点的输入组件(例如,鼠标、触摸板、轨迹球、操纵杆、运动传感器、或者其他定点仪器)、触觉输入组件(例如,物理按钮、提供位置和/或触摸力或触摸手势的触摸屏,或者其他触觉输入组件)、音频输入组件(例如,麦克风)等。
[0095]
在另外的示例性实施例中,i/o组件1150可以包括生物特征组件1156、运动组件1158、环境组件1160或位置组件1162、以及其他各种组件。例如,生物特征组件1156可以包括用于检测表情(例如,手部表情、面部表情、声音表情、身体姿势或眼动追踪)、测量生物信号(例如,血压、心率、体温、汗水或脑电波)、识别人(例如,语音识别、视网膜识别、面部识别、指纹识别或基于脑电图的识别)等的组件。运动组件1158可以包括加速度传感器组件(例如,加速度计)、重力传感器组件、旋转传感器组件(例如,陀螺仪)等。环境组件1160可以包括例如照度传感器组件(例如,光度计)、温度传感器组件(例如,检测环境温度的一个或多个温度计)、湿度传感器组件、压力传感器组件(例如,气压计)、声学传感器组件(例如,检测背景噪声的一个或多个麦克风)、接近传感器组件(例如,检测附近物体的红外传感器)、气体传感器(例如,气体检测传感器,用于检测危险气体的浓度以确保安全或测量大气中的污染物),或者可以提供与周围物理环境相对应的指示、测量或信号的其他组件。位置组件1162可以包括位置传感器组件(例如,全球定位系统(gps)接收器组件)、高度传感器组件(例如,检测可从中导出高度的气压的高度计或气压计)、定向传感器组件(例如,磁力计)等。
[0096]
可以使用多种技术来实现通信。i/o组件1150可以包括通信组件1164,其可操作用于分别经由耦合件1182和耦合件1172将机器1100耦合到网络1180或设备1170。例如,通信组件1164可以包括网络接口组件或者与网络1180进行接口的另一合适设备。在另外的示例中,通信组件1164可以包括有线通信组件、无线通信组件、蜂窝通信组件、近场通信(nfc)组件、组件(例如,lowenergy)、组件和其他通信组件以经由其他模态提供通信。设备1170可以是另一台机器或多种外围设备(例如,经由usb耦合的外围设备)中的任意一个。
[0097]
此外,通信组件1164可以检测标识符或者包括可操作用于检测标识符的组件。例如,通信组件1164可以包括射频识别(rfid)标签读取器组件、nfc智能标签检测组件、光学读取器组件(例如,用于检测诸如通用产品代码(upc)条形码的一维条形码、诸如快速响应(qr)码、aztec码、数据矩阵、dataglyph、maxicode、pdf417、ultra code、ucc rss-2d条形码
的多维条形码以及其他光学代码的光学传感器)或者声学检测组件(例如,用于识别标记的音频信号的麦克风)。另外,可以经由通信组件1164导出各种信息,诸如经由互联网协议(ip)地理定位的位置、经由信号三角测量的位置、经由检测可以指示特定位置的nfc信标信号的位置等等。
[0098]
可执行指令和机器存储介质
[0099]
各种存储器(即,1130、1132、1134和/或(一个或多个)处理器1110的存储器)和/或存储单元1136可以存储一组或多组指令1116和数据结构(例如,软件),其体现或利用在本文中所描述的方法或功能中的任意一种或多种方法或功能。这些指令(例如,指令1116)当由处理器1110运行时使得各种操作来实现所公开的实施例。
[0100]
如在本文中所使用的,术语“机器存储介质”、“设备存储介质”和“计算机存储介质”意指相同的事物并且可以互换地使用。这些术语指代存储可执行指令1116和/或数据的单个或多个存储设备和/或介质(例如,集中式或分布式数据库,和/或相关联的高速缓存和服务器)。相应地,这些术语应当被认为包括但不限于固态存储器以及光和磁介质,包括处理器1110内部或外部的存储器。机器存储介质、计算机存储介质和/或设备存储介质的特定示例包括非易失性存储器,例如包括半导体存储器设备,例如可擦除可编程只读存储器(eprom)、电可擦除可编程只读存储器(eeprom)、现场可编程门阵列(fpga)和闪存设备;磁盘,例如内置硬盘和可移动磁盘;磁光盘;以及cd-rom和dvd-rom磁盘。术语“机器存储介质”、“计算机存储介质”和“设备存储介质”明确排除了载波、调制数据信号和其他此类介质,其中至少一些包含在下文所讨论的术语“信号介质”之下。
[0101]
传输介质
[0102]
在各种示例性实施例中,网络1180的一个或多个部分可以是自组织网络、内联网、外联网、vpn、lan、wlan、wan、wwan、man、互联网、互联网的一部分、pstn的一部分、普通旧式电话服务(pots)网络、蜂窝电话网络、无线网络、网络、另一种类型的网络,或者两种或更多种这样的网络的组合。例如,网络1180或网络1180的一部分可以包括无线或蜂窝网络,并且耦合件1182可以是码分多址(cdma)连接、全球移动通信系统(gsm)连接或者其他类型的蜂窝或无线耦合。在该示例中,耦合件1182可以实现多种类型的数据传输技术中的任一种,例如单载波无线电传输技术(1xrtt)、演进数据优化(evdo)技术、通用分组无线电服务(gprs)技术、gsm演进增强数据速率(edge)技术、第三代合作伙伴计划(3gpp)(包括3g)、第四代无线(4g)网络、通用移动电信系统(umts)、高速分组接入(hspa)、微波接入全球互操作性(wimax)、长期演进(lte)标准、由各种标准制定组织定义的其他标准、其他远程协议或者其他数据传输技术。
[0103]
可以使用传输介质经由网络接口设备(例如,包含于通信组件1164中的网络接口组件)并且利用多种公知传输协议(例如,http)中的任意一种来通过网络1180发送或接收指令1116。类似地,可以使用传输介质经由耦合件1172(例如,对等耦合件)向设备1170发送或接收指令1116。术语“传输介质”和“信号介质”表示相同的事物并且在本公开中可以互换使用。术语“传输介质”和“信号介质”应当被认为包括能够存储、编码或携带由机器1100执行的指令1116的任何无形介质,并且包括数字或模拟通信信号或者其他无形介质以促进此类软件的通信。因此,术语“传输介质”和“信号介质”应当被视为包括任何形式的调制数据信号、载波等。术语“调制数据信号”是指以编码信号中的信息的方式设置或改变其一个或
多个特性的信号。
[0104]
计算机可读介质
[0105]
术语“机器可读介质”、“计算机可读介质”和“设备可读介质”表示相同的事物并且在本公开中可以互换地使用。这些术语被定义为包括机器存储介质和传输介质两者。因此,这些术语包括存储设备/介质和载波/调制数据信号。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1