一种精准识别断面尺度入河污染源类型的方法与流程
1.本发明涉及流域水环境污染治理技术领域,具体而言,涉及一种精准识别断面尺度入河污染源类型的方法。本发明申请人的同日申请,标题为“一种用于估算入河污染源排放量的方法”全文引用并结合到本文中。
背景技术:
2.我国境内河流众多,地形地貌复杂,生态环境脆弱,加上地区水资源的禀赋和经济发展空间匹配差异较大,不同流域存在不同程度的水环境压力,水污染原因复杂,水环境管理面临诸多困难。水环境的自然属性决定了水环境质量改善必须从流域尺度,统筹考虑点源和非点源污染传输全过程,综合分析水(降水、地表径流、壤中流等)、土壤、地形、植被、受纳水体的生态功能等多种要素对水环境质量的相互影响。水环境问题发现不及时、不全面的问题普遍存在,难以满足快速发现环境问题的需求。而且,以往水环境问题多重视水质超标,对水质恶化、临界超标等的原因追溯问题识别较少。
3.精准溯源需要污染源排放量的科学估算做支撑,而要能够实现对流域断面尺度入河污染源进行精准识别,对于科学管理和治理水环境问题异常重要。水污染源解析法是寻求水污染源的一种方法,从广义上看,水污染源解析(sourceapportionment)包含两层含义,一是运用多种技术手段定性识别水污染物不同来源;二是通过建立污染物与来源的因果对应关系定量计算各来源的相对贡献。源解析研究的污染来源,可以是具有某种共性的污染类型,也可以是流域产生污染的部位或是某种具体的输出单元,实际研究中需要根据研究的尺度和目标等因素确定源解析所要达到的“精度”。比如在较大的流域尺度上,可将点源和非点源作为来源类型研究其对污染发生的相对贡献,也可以将污染源解析到流域的不同部位(子流域)或者不同产出部门。在更小的尺度上,甚至可以将单一农业小流域产生的污染物源解析到流域内的不同种植类型。
4.现有的污染源解析技术主要方法大致可以分为三种:清单分析法、扩散模型和受体模型。清单分析法由于效率低下使用不多,扩散模型扩散模型需要众多研究流域的参数,一般难以得到,所以应用受限。为了适应现有水域管理中水域数据普遍不多的情况,需要一种水污染源模型及相应方法,以解决现有水域管理中水污染源难以精准识别的问题。
技术实现要素:
5.本发明旨在针对现有技术存在问题,提出一种精准识别断面尺度入河污染源类型的方法。根据本发明的方法,包括:包括:确定研究区域,所述研究区域为水资源丰富的区域;获得所述研究区域的入河污染源的排放量;基于所述研究区域的入河污染源类型、污染源入河浓度系数以及排放因子构建水环境cmb模型;选定断面,进行id表示;整理所述断面的水环境监测数据,形成每月的断面污染源统计数据表;根据所述断面污染源统计数据表和相应月份的污染源入河浓度系数,得到各个污染源的排放成分谱;经由所述cmd模型,计算断面尺度入河污染源贡献大小,得到每月一次的源解析结果;对cmd模型的计算结果进行
分析和验证,得到所需源解析结果。
6.优选地是,所述构建水环境cmb模型包括:
7.确定在受体上每种化学组分的浓度;所述浓度就是每一源类的化学组分的含量值和源贡献浓度值的乘积的线性相加和;具体为
[0008][0009]
式中:
[0010]ci
—环境受体中组分i的浓度测量值;
[0011]fij
—第j类源的化学组分i的含量值;
[0012]
sj—第j类源贡献的浓度计算值;
[0013]
j—污染源的数目;
[0014]
i—污染因子数目。
[0015]
只有当i》j时,方程有解。
[0016]
第j类源对受体第i个污染因子的贡献率为:
[0017]
η
ij
=sj×fij
/ci×
100%
[0018]
式中:ci—环境受体中第i个污染物的浓度测量值。
[0019]
优选地是,所述cmb模型采用有效方差最小二乘法,所述有效方差最小二乘法是使加权的化学组分测量值与计算值之差的平方和最小:
[0020][0021]
式中,v
eff,i
—有效方差,权重值。
[0022][0023]
式中:
[0024]
—受体测量值的标准偏差。
[0025]
—排放源元素测量值的标准偏差。
[0026]
优选地是,所述有效方差最小二乘法采用迭代法进行计算,即在前一步迭代计算的sj的基础上再来计算一组新的sj值;具体为:设上标k用于指定第k次迭代中的变量值,有效方差最小二乘法步骤:
[0027]
将源贡献的初始估计值设置为零:
[0028][0029]
计算有效方差矩阵ve的对角分量,该矩阵的所有非对角线分量都等于零;
[0030][0031]
计算sj的k+1步迭代值;
[0032][0033]
针对第k次迭代测试sj的第(k+1)次迭代;如果任何一个相差超过1%,则执行下一次迭代;如果所有的差异小于1%,则终止算法;
[0034][0035]
将第(k+1)次迭代结果分配给sj和σ,所有其他计算都使用这些最终值;
[0036][0037]
其中:c=(c1...ci),以ci作为第i个分量的列向量;
[0038]
s=(s1...sj),以sj为第j个分量的列向量;
[0039]
f,i
×
j维污染源组成矩阵;
[0040]
受体浓度ci测量的标准偏差不确定度;
[0041]fij
测量值的标准偏差不确定度;
[0042]ve
,有效方差的对角矩阵;
[0043]
源贡献的不确定度。
[0044]
优选地是,所述各个污染源的月排放成分谱由污染源统计结果与相应月份的入河浓度系数乘积得到,其包括:工业污染、城镇污染、养殖污染和面源,所述污染源的排放成分包括:总磷、氨氮、化学需氧量、氟化物、挥发酚和石油类。
[0045]
优选地是,所述计算断面尺度入河污染源贡献大小进一步包括:基于污染源入河浓度系数对cmb模型调试和优化,得到调整后的cmb模型;所述入河浓度系数是按月变化的,其根据研究区域降水和来水的影响,调整为相应月份的对应值。
[0046]
优选地是,经过调整后的cmb模型,对于总磷和氨氮,其测量值和cmb模型计算值吻合良好;对于四个污染源进行源解析时,不适合养殖污染源进行源解析;所述污染源类型调整为工业污染、城镇污染、面源污染以及未知源。
[0047]
优选地是,所述计算断面尺度入河污染源贡献大小进一步包括:对多种不同的排放因子进行组合选择,形成不同的溯源类型,根据所述所述溯源类型,选定工业污染、城镇污染、面源污染以及未知源进行cmb模型源解析,得到断面溯源结果。
[0048]
优选地是,对所述所需源解析结果进行评价,所述评价值为cmb模型的计算值与观测值的比值,所述比值趋近于1,表明cmb模型源解析结果成功。
[0049]
采用本发明的方法,可以避免大量的样品采集所带来的资金等方面的压力。能够检测出是否遗漏了某重要源,还可以检验其他方法的适用性。可以定量分析得到贡献率和不确定度,所得到的研究结果可以支撑后续的智能算法研究。
附图说明
[0050]
本公开的各种实施例或样例(“示例”)在以下的具体实施方式和附图中得以公开。
没必要将附图按比例绘制。一般而言,除非在权利要求中另有规定,否则可以任意顺序执行本发明所公开方法的操作。附图中:
[0051]
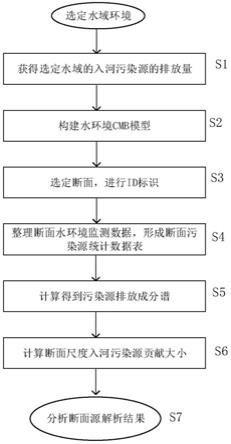
图1示出了根据本发明的用于精准识别断面尺度入河污染源类型的方法流程图。
具体实施方式
[0052]
在详细解释本公开的一个或多个实施例之前,应当理解,实施例不限于它们具体应用中的构造细节,以及下文实施方式或附图所提出步骤或方法。
[0053]
图1示出了根据本发明的用于精准识别断面尺度入河污染源类型的方法流程图,其包括如下步骤:如图1所示,在应用本发明的方法之前,需要选定水域环境,例如可以是重庆璧南河流域。步骤s1:识别入河污染源类型,需要获得研究区域的入河污染源的排放量。本发明申请人的同日申请“一种用于估算入河污染源排放量的方法”在此全文引用并结合到本发明中。同日申请详细的给出了计算入河污染源排放量的方法,并给出了例如是璧南河流域的入河污染源排放量。在本发明的示例中,入河污染源的排放数据可以直接取自本发明的同日申请。当然,别的水域环境的入河污染物排放量的数据也适合本发明的方法。由于本发明是采用基于已知污染源排放成分谱和受体浓度的cmd源解析法,因此需要入河污染源的排放量数据作为本发明方法的数据输入。步骤s2:构建水环境cmb模型,cmd模型及模型的计算方法在本发明的下文中有详细的描述。步骤s3:选定断面,进行id表示。断面的选择可根据实际需要进行选取,在本方的示例中,选取璧南河流域的两河口断面进行演算说明。步骤s4:整理断面水环境监测数据,形成每月的断面污染源统计数据表。步骤s5:根据断面污染源统计数据表和相应月份的污染物入河浓度系数,得到各个污染源的排放成分谱。步骤s6:经由cmd模型,计算出断面尺度入河污染源贡献大小,得到每月一次的源解析结果。由于cmd模型对污染源排放量统计数据有较高的要求,因此在进行源解析分析时,需要调整模型和优化参数,具体过程见下文的详细描写。最后,到步骤s7,对cmd模型的计算结果进行分析和验证,得到所需的源解析结果。
[0054]
一、cmb模型及模型计算方法
[0055]
化学质量平衡模型(cmb)最开始是应用于大气污染源管理的几种受体模型中的一种。本发明将化学质量平衡模型应用到水环境源解析中来。cmb模型的基本原理是质量守恒,假设存在对水体受体中的污染因子有贡献的若干种排放源类,并且满足以下假设:
[0056]
1)各种排放源类排放到环境中的颗粒物的化学组分有明显的差别;
[0057]
2)各种排放源类所排放的污染因子的化学组分相对稳定;
[0058]
3)各种排放源类所排放的污染因子在传输过程中的变化可以被忽略,并且所有的污染源成分谱是线性无关的;
[0059]
4)污染源种类低于或等于化学组分的种类。
[0060]
那么在受体上每种化学组分的浓度就是每一源类的化学组分的含量值和源贡献浓度值的乘积的线性相加和。
[0061][0062]
式中:
[0063]ci
—环境受体中组分i的浓度测量值;
[0064]fij
—第j类源的化学组分i的含量值;
[0065]
sj—第j类源贡献的浓度计算值;
[0066]
j—污染源的数目;
[0067]
i—污染因子数目。
[0068]
只有当i》j时,方程有解。
[0069]
第j类源对受体第i个污染因子的贡献率为:
[0070]
η
ij
=sj×fij
/ci×
100%
[0071]
式中:ci—环境受体中第i个污染物的浓度测量值。
[0072]
目前cmb模型最常用的算法是有效方差最小二乘法,特点:(1)提供了对源贡献不确定性的现实估计(将污染源数据和受体数据的不确定性纳入计算过程);(2)对来源和受体测量中不确定度较小的化学物质的影响要大于不确定度较高的化学物质。
[0073]
有效方差最小二乘法是使加权的化学组分测量值与计算值之差的平方和最小:
[0074][0075]
式中,v
eff,i
—有效方差,权重值。
[0076][0077]
式中:
[0078]
—受体测量值的标准偏差。
[0079]
—排放源元素测量值的标准偏差。
[0080]
有效方差最小二乘法在实际运算中采用迭代法,即在前一步迭代计算的sj的基础上再来计算一组新的sj值。设上标k用于指定第k次迭代中的变量值,有效方差最小二乘法步骤:
[0081]
将源贡献的初始估计值设置为零。
[0082][0083]
计算有效方差矩阵ve的对角分量。该矩阵的所有非对角线分量都等于零。
[0084][0085]
计算sj的k+1步迭代值。
[0086][0087]
针对第k次迭代测试sj的第(k+1)次迭代。如果任何一个相差超过1%,则执行下一次迭代。如果所有的差异小于1%,则终止算法。
[0088]
[0089]
将第(k+1)次迭代结果分配给sj和σ。所有其他计算都使用这些最终值。
[0090][0091]
其中:c=(c1...ci),以ci作为第i个分量的列向量;
[0092]
s=(s1...sj),以sj为第j个分量的列向量;
[0093]
f,i
×
j维污染源组成矩阵;
[0094]
受体浓度ci测量的标准偏差不确定度;
[0095]fij
测量值的标准偏差不确定度;
[0096]ve
,有效方差的对角矩阵。
[0097]
源贡献的不确定度
[0098]
二、断面水环境监测数据解析与污染源排放成分谱
[0099]
1)断面数据整理解析
[0100]
以璧南河流域两河口为示例进行说明。通过对两河口等断面的环境监测数据进行分析整理,发现监测了高锰酸盐指数汞、五日生化需氧量、化学需氧量、硒、氟化物、砷、硫化物、ph值(无量纲)、挥发酚、石油类、氨氮、总磷、溶解氧、铜、镉、锌、铅、铬、氰化物等污染因子的数据,但是经统计分析,发现以下10个因子的数据比较齐全,且与水质比较相关,经整理后,如下表所示。
[0101]
表1 2015-2017年两河口断面数据表
[0102][0103]
2)污染源排放成分谱
[0104]
随着时间的变化,各类污染源的排放成分会发生变化,在使用cmb进行源解析时污染源成分谱的准确性对结果的影响较大,因此这里对四个污染源每个月的排放成分谱进行了单独核算,将污染源统计的结果,乘上相应月份的入河浓度系数即可,最终四个污染源的月排放成分谱如下表所示。
[0105]
表2源1:工业污染排放成分谱
[0106]
[0107][0108]
表3源2:城镇污染排放成分谱
[0109]
[0110][0111]
表4源3:养殖污染排放成分谱
[0112]
[0113][0114]
表5源4:面源排放成分谱
[0115]
[0116][0117]
(3)断面尺度入河污染源贡献率计算
[0118]
根据数据解析工作得到的断面因子数据以及计算得到的污染源排放成分谱数据,使用cmb模型进行源解析,每个月得到一次源解析结果。
[0119]
1)cmb模型调试和优化:
[0120]
(1)污染源入河浓度系数调整
[0121]
对六个污染源进行源解析,得到结果后发现,很多污染源的贡献度小于0,综合考
虑,原因在于:污染源的负荷统计不太精确,污染源数据庞杂,进行负荷计算时存在误差。随着月份的变化,水文条件不断发生变化,不同月份的浓度会不同,需要针对每个月进行污染源排放谱的核算。污染源较多时,由于有的污染源排放谱的相似,存在严重的共线性问题。
[0122]
当每个月采用平均浓度进行溯源时,发现计算值与测量值偏差较大(从表6可以发现,不管是绝对误差还是相对误差都比较大),特别是tp和nh
3-n,因为这二个参数本来的绝对值就较小,如果在拟合时相差较大,说明源数据与断面数据的相关性较差,在排除断面数据有误的情况下,应是污染源数据不应采用每个月都相同的浓度,因为降水和来水的影响,每月的入河浓度是有波动的。
[0123]
表6采用平均源浓度时6个污染源对两河口断面的拟合结果(2015年)
[0124][0125][0126]
因此通过改变不同月份的入河浓度系数,并计算得到不同月份的污染源的入河浓度,通过多次试算,发现采用不同的入河浓度系数来计算不用月份的入河浓度,并在此基础上开展研究后发现,对于tp和nh
3-n计算值与测量值吻合得很好(见表7所示,不管是绝对误差还是相对误差都特别的小),说明考虑降水量的入河系数可能反映了比较真实情况下的
入河浓度。在后续的研究中均先采用这样的入河浓度系数进行污染源溯源。
[0127]
表7采用不同入河浓度时6个污染源对两河口断面的拟合结果(2015年)
[0128][0129]
(2)污染源类型及个数调整
[0130]
采用四个污染源进行源解析时,其中的养殖污染贡献始终为负数,如表8所示,说明养殖污染源与其他源的共线性太强,尤其是与面源的共线性比较强,因此养殖污染源不适合进行源解析。
[0131]
表8 4个污染源时两河口2015年溯源结果
[0132][0133]
[0134]
最终采用三类污染源和一个未知源进行源解析,分别是工业污染、城镇污染、面源污染,以及未知源,并对2015年到2017年的基于断面的数据进行了源解析。
[0135]
2)断面尺度入河污染源解析结果与分析
[0136]
a选择污染因子
[0137]
结合污染源排放的成份数据和断面监测数据,经不断的测试,选择表9中11种不同的因子组合进行溯源。
[0138]
表9对应不同污染因子进行的溯源表
[0139][0140]
下面以上表第(1)种溯源类型为例,计算溯源结果。
[0141]
b应用cmb模型进行溯源分析,得到溯源结果
[0142]
在污染因子组合的基础上,应用cmb模型进行计算,发现可以得到较好的拟合结果,具体见表10。
[0143]
2015源解析结果:
[0144]
表10两河口2015年溯源结果
[0145]
[0146][0147]
2016源解析结果:
[0148]
表11两河口2016年溯源结果
[0149]
[0150][0151]
2017源解析结果:
[0152]
表12两河口2017年溯源结果
[0153]
[0154][0155]
c cmb模型源解析结果分析
[0156]
以2015年的结果为例,两河口断面2015年的源解析结果,得到了各个污染源的贡献率。根据cmb模型得到污染物的浓度计算值和测量值进行分析,如表13所示,tp和nh
3-n的比值基本接近于1,相对误差也非常小,说明cmb对于tp和nh
3-n的解析很成功。cod的比值在0.4到0.8之间,平均值为0.56,相对误差平均值为44.30%,对于cod的解析效果较差,也可能是没有解析到对cod贡献较大的污染源,总体上来说cmb源解析是成功的。
[0157]
表13 2015年源解析结果评价
[0158][0159]
根据源解析结果和2015年污染负荷统计(见表14)的结果进行比较发现:
[0160]
根据污染负荷统计,各污染源对tp的贡献:面源》城镇》工业,与溯源结果(2015年1月源解析结果,工业污染贡献率:6.40%、城镇污染贡献率28.80%、面源污染贡献率:65.00%)一致;
[0161]
根据污染负荷统计,各污染源对nh3-n的贡献,城镇》面源》工业,与溯源结果(2015年1月源解析结果,工业污染贡献率:25.10%、城镇污染贡献率50.20%、面源污染贡献率:25.60%)一致;
[0162]
根据污染负荷统计,各污染源对cod的贡献,工业污染的cod入河量比较少,城镇大于面源的cod入河量,与溯源结果(2015年1月源解析结果,工业污染贡献率:27.10%、城镇污染贡献率17.20%、面源污染贡献率:16.90%)有点差别,但未知源的贡献率较高,可能跟
1月份的未能统计到的污染扰动有关。
[0163]
表14 2015年污染负荷
[0164]
污染源类型cod入河量(t/a)nh
3-n入河量(t/a)tp入河量(t/a)工业污染667.7628.151.35城镇污染4047.795528.258.2面源污染2134.845141.970.74
[0165]
综合以上分析,结果表明cmb模型是可靠的,源解析得到的贡献率吻合实际情况。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1