一种基于小样本的特定领域多标签文本分类方法与流程
1.本发明涉及一种基于小样本的特定领域多标签文本分类方法。
背景技术:
2.在需要进行文本分类任务的系统上线初期,数据积累很少,只有少量的数据进行标注,本发明提出一种小样本的分类方法,使得在系统上线初期数据积累少的情况下,提升文本分类的准确率,并在系统运营的过程中持续使用新分类的数据自适应地提升分类模型准确率。
3.当前有论文提出了基于模版的小样本学习方法,但是它的效果好的前提是一开始就有大量的特定领域的数据集,仅仅只是标注的数据少。本方案则在该方法的基础上,解决标签数量和特定领域文本数量均很少的问题。
技术实现要素:
4.为了实现上述技术目的,本发明的技术方案是,
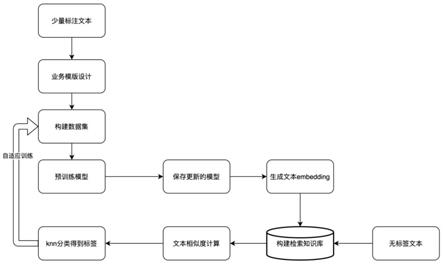
5.一种基于小样本的特定领域多标签文本分类方法,包括以下步骤:
6.步骤一,获取特定领域的原始语料,并提取其中小部分语料,为语料中每个句子都标注上标签,并以相同的标签为一类,记录下标签的总类数;
7.步骤二,将标注的标签加入到句子之前并对标签进行掩码,同时在标签的首尾分别增加固定词语以标识出标签并构成新的句子,再在新的句子头尾加上特定符号;然后加入用于标识当前标签是否正确的标识标签,再复制句子并将原标签内容依次更换为其他句子所标注且与原标签不同的标签,同时将标识标签从正确改为错误,从而扩充步骤一中提取的小部分语料;
8.步骤三,向预训练语言模型中输入扩充后的语料,然后执行掩码语言模型任务,从而对预训练模型的参数进行更新;
9.步骤四,将更新后的模型作为语义特征提取器,从而将所有扩充后的语料转为语义向量并作为查询检索库;
10.步骤五,再从原始语料从提取部分语料,并为语料中的每个句子前都加入掩码且在掩码前后加入步骤二中的固定词语,同时按步骤一中记录的标签种类数来复制以得到同样数量的句子,然后输入到模型中,从而得到每个句子的语义向量;
11.步骤六,将得到的语义向量结果来与查询检索库进行相似度计算,并取相似度最高的前n条标签中出现次数最高的标签作为没有原始标签的语料的标签;
12.步骤七,返回步骤三,并以步骤六中得到的标签的语料作为模型的输入,继续更新模型的参数,直到损失函数达到收敛即完成模型训练;
13.步骤八,采用步骤七中训练完成的模型,对与步骤一中领域相同的语料进行标签标注,从而实现分类。
14.所述的一种基于小样本的特定领域多标签文本分类方法,所述的步骤一中,所述
的小部分语料为数量少于200条的文本语句。
15.所述的一种基于小样本的特定领域多标签文本分类方法,所述的步骤三中,执行掩码语言模型任务包括:
16.将每个句子输入到预训练语言模型后,得到映射的低维向量表示,对掩码位置计算低维向量与掩码位置标签mlm_label的损失函数,对于句首位置[cls]位置计算低维向量与标识标签eq_label的损失函数,两个损失函数相加作为为整个预训练语言模型的损失函数;对应的损失函数l公式如下:
[0017]
l=mlm_loss+eq_loss
[0018][0019]
eq_loss=-[yjlog(pj)+(1-yj)log(1-pj)]
[0020]
对于mlm_loss,其中v为mask的字的个数,yi表示被mask代替的标签的one-hot格式,pi表示模型预测的字的概率;对于eq_loss,yj表示eq_label的值,pj表示模型预测是否为正例的概率;其中mlm_label通过softmax计算,eq_label通过sigmoid计算;
[0021]
基于上述步骤,反复迭代直到模型损失值不断下降直到收敛。
[0022]
所述的一种基于小样本的特定领域多标签文本分类方法,所述的步骤四中,将所有扩充后的语料转为语义向量,是将不带标签的原始语句,以及标签本身分别通过模型的多层transformer输出映射到低维的向量中,并取所有字的均值作为该句子的语义向量。
[0023]
所述的一种基于小样本的特定领域多标签文本分类方法,所述的步骤五中,每个句子的语义向量包括低维向量均值和预测的mask向量均值,其中句子的低维向量均值是句子中每个字的向量取均值,mask向量的均值指的是句子中用mask代替的位置的字向量的均值。
[0024]
所述的一种基于小样本的特定领域多标签文本分类方法,所述的步骤六中,相似度计算是通过余弦相似度实现,其中计算公式为:
[0025][0026]
w1+w2=1
[0027]
其中w1、w2为两种相似度的权重,v
m1
、v
m2
分别表示模型预测的mask向量和实际的标签向量,v
s1
、v
s2
则表示为待预测的句子向量和检索库里的句子向量。
[0028]
所述的一种基于小样本的特定领域多标签文本分类方法,所述的步骤六中,取相似度最高的前n条标签作为没有原始标签的语料的标签,是对所有相似度计算的结果进行从大到小排序,取前n条结果,使用knn中投票表决的方法,前n条结果中出现次数最高的标签作为最相近的句子标签。
[0029]
本发明的技术效果在于,本发明基于预训练语言模型,在人工标签数量很小(只有200条)以及本领域数据很小的情况下,使用很少的标签数据,通过数据预处理扩充了训练的数据集,并通过mask language model对数据集进行了多任务的训练,使模型充分学习到领域的语义知识,在预测的阶段则使用知识库检索的方式,使用knn减少随机性,提升分类结果的准确性。在得到预测的结果后,继续将预测的结果当作人工标签重复上述步骤,使模
型能够继续学习本领域的知识,并且检索知识库也越来越大,分类的结果也得到相应的提升。
[0030]
下面结合附图对本发明作进一步说明。
附图说明
[0031]
图1为本实施例的流程示意图。
具体实施方式
[0032]
本实施例通过以下步骤实现:
[0033]
步骤一,获取特定领域的原始语料,并提取其中小部分语料,为语料中每个句子都标注上标签,并以相同的标签为一类,记录下标签的总类数。本实施例中,小部分语料为数量少于200条的文本语句。根据情况也可对该数量进行相应调整。
[0034]
步骤二,将标注的标签加入到句子之前并对标签进行掩码,同时在标签的首尾分别增加固定词语以标识出标签并构成新的句子,再在新的句子头尾加上特定符号。然后加入用于标识当前标签是否正确的标识标签,再复制句子并将原标签内容依次更换为其他句子所标注且与原标签不同的标签,同时将标识标签从正确改为错误,从而扩充步骤一中提取的小部分语料。举例来说,假设特定领域为金融行业,语料中的一条句子为“老年人经常办理定期续存业务。”,那么打上的标签为“个人定期存款”。则步骤二中的处理,是将标签的字用[mask]替代,并在句子的头尾加上特定的符号[cls]和[sep],最后得到如下输入句子:“[cls]这是[mask][mask][mask][mask][mask][mask]业务,老年人经常办理定期续存业务。[sep]”。同时设定输入的标签有两个,一个是[mask]的标签mlm_label=’个人定期存款’,另一个标签确定是否是正例,eq_label=1。然后扩充过程是:将该条数据的标签设置为其他类别,例如另一个类别为“柜员管理”,输入句子变为“[cls]这是[mask][mask][mask][mask]业务,老年人经常办理定期续存业务。[sep]”,两个设置的标签mlm_label=’柜员管理’,该标签不是正确的类别,因此eq_label=0。那么假设标签的总类数为11类,则将这个句子复制10遍,每一遍都更换为其他的标签,数据总量则扩充了11倍。
[0035]
步骤三,向预训练语言模型中输入扩充后的语料,然后执行掩码语言模型任务,从而对预训练模型的参数进行更新。
[0036]
步骤四,将更新后的模型作为语义特征提取器,从而将所有扩充后的语料转为语义向量并作为查询检索库。
[0037]
步骤五,再从原始语料从提取部分语料,并为语料中的每个句子前都加入掩码且在掩码前后加入步骤二中的固定词语,同时按步骤一中记录的标签种类数来复制以得到同样数量的句子,然后输入到模型中,从而得到每个句子的语义向量。
[0038]
步骤六,将得到的语义向量结果来与查询检索库进行相似度计算,并取相似度最高的前n条标签中出现次数最高的标签作为没有原始标签的语料的标签。
[0039]
步骤七,返回步骤三,并以步骤六中得到的标签的语料作为模型的输入,继续更新模型的参数,直到损失函数达到收敛即完成模型训练。
[0040]
步骤八,采用步骤七中训练完成的模型,对与步骤一中领域相同的语料进行标签标注,从而实现分类。
[0041]
具体来说,步骤三中,执行掩码语言模型任务包括:
[0042]
将每个句子输入到预训练语言模型后,得到映射的低维向量表示,对掩码位置计算低维向量与掩码位置标签mlm_label的损失函数,对于句首位置[cls]位置计算低维向量与标识标签eq_label的损失函数,两个损失函数相加作为为整个预训练语言模型的损失函数。对应的损失函数l公式如下:
[0043]
l=mlm_loss+eq_loss
[0044][0045]
eq_loss=-[yjlog(pj)+(1-yj)log(1-pj)]
[0046]
对于mlm_loss,其中v为mask的字的个数,yi表示被mask代替的标签的one-hot格式,pi表示模型预测的字的概率。对于eq_loss,yj表示eq_label的值,pj表示模型预测是否为正例的概率。其中mlm_label通过softmax计算,eq_label通过sigmoid计算。
[0047]
基于上述步骤,反复迭代直到模型损失值不断下降直到收敛。
[0048]
进一步的,步骤四中,将所有扩充后的语料转为语义向量,是将不带标签的原始语句,以及标签本身分别通过模型的多层transformer输出映射到低维的向量中,并取所有字的均值作为该句子的语义向量。
[0049]
步骤五中,每个句子的语义向量包括低维向量均值和预测的mask向量均值,其中句子的低维向量均值是句子中每个字的向量取均值,mask向量的均值指的是句子中用mask代替的位置的字向量的均值。
[0050]
步骤六中,相似度计算是通过余弦相似度实现,其中计算公式为:
[0051][0052]
w1+w2=1
[0053]
其中w1、w2为两种相似度的权重,v
m1
、v
m2
分别表示模型预测的mask向量和实际的标签向量,v
s1
、v
s2
则表示为待预测的句子向量和检索库里的句子向量。
[0054]
步骤六中,取相似度最高的前n条标签作为没有原始标签的语料的标签,是对所有相似度计算的结果进行从大到小排序,取前n条结果,使用knn中投票表决的方法,前n条结果中出现次数最高的标签作为最相近的句子标签。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1