数据处理装置以及数据处理方法与流程
本发明涉及数据处理装置以及数据处理方法。
背景技术:
1、在作为上述的数据处理装置之一的专利文献1中记载的声音模型学习辅助装置中,在学习之后追加地进行再学习。
2、现有技术文献
3、专利文献
4、专利文献1:日本特开2016-161823号公报
技术实现思路
1、发明要解决的课题
2、但是,在上述的声音模型学习辅助装置中,在所述再学习时,使用在所述学习中使用的全部已学习数据。由此,存在如下课题:尽管是在已经进行了所述学习的范围内且不需要新进行所述再学习的范围内,但是有时仍进行所述再学习。
3、此外,在上述的声音模型学习辅助装置中,在所述再学习时,除了所述多个已学习数据以外,还新使用要追加到所述多个已学习数据中使用的多个候选数据中的、根据与所述多个已学习数据的关系(例如所述多个候选数据的中间特征量与所述多个已学习数据的中间特征量的关系)选择的候选数据。由此,还存在如下课题:尽管是在已经进行了所述学习的范围外且希望新进行所述再学习的范围内,但是有时仍不进行所述再学习。
4、本发明的目的在于,抑制在进行了所述学习的范围内且不需要进行所述再学习的范围内进行所述再学习、以及促进在进行了所述学习的范围外且希望进行所述再学习的范围内进行所述再学习中的至少一个。
5、用于解决课题的手段
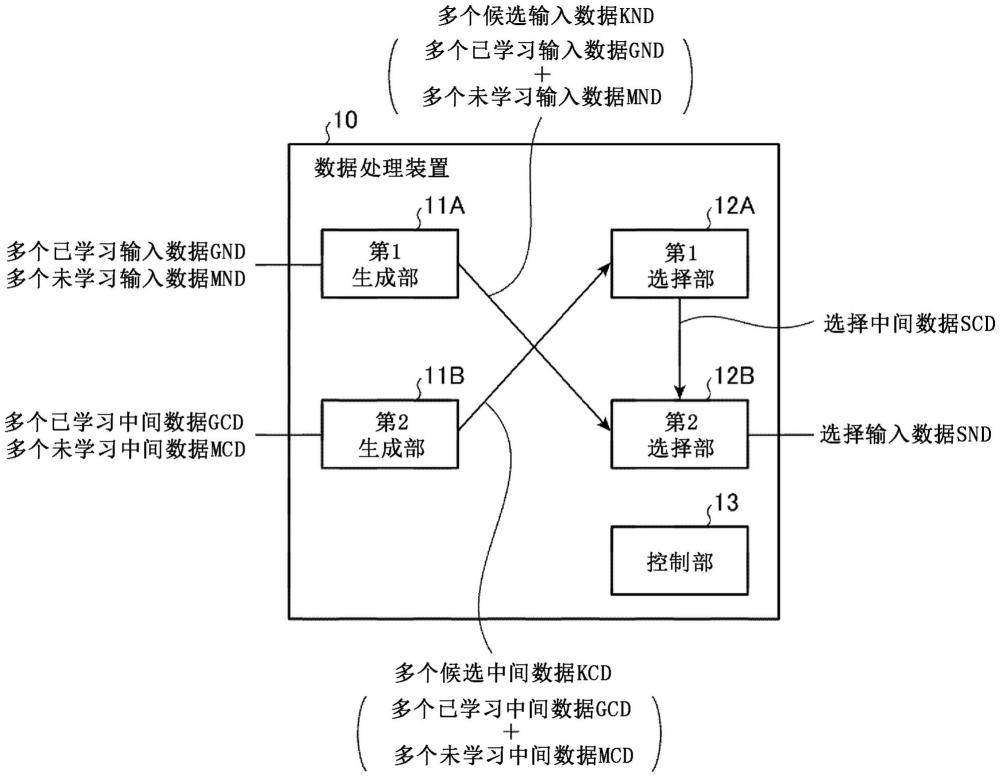
6、为了解决上述的课题,本发明的数据处理装置包含:第1生成部,其将机器学习模型的第1学习中使用的多个已学习输入数据和所述第1学习中未使用的多个未学习输入数据汇总,由此生成多个候选输入数据;第2生成部,其将通过向所述机器学习模型输入所述多个已学习输入数据而被给予的已学习中间数据和通过向所述机器学习模型输入所述多个未学习输入数据而被给予的未学习中间数据汇总,由此生成多个候选中间数据;第1选择部,其选择所述多个候选中间数据中的一个候选中间数据,并且,与由已经选择出的已学习中间数据即选择已学习中间数据和已经选择出的未学习中间数据即选择未学习中间数据构成的选择中间数据相比,更优先选择在所述第1学习之后的第2学习中使用时为异质的程度更大的所述一个候选中间数据;以及第2选择部,其选择所述多个候选输入数据中的、与所述选择出的一个候选中间数据对应的一个候选输入数据,以在所述第2学习时使用。
7、发明效果
8、根据本发明的数据处理装置,能够抑制在进行了所述学习的范围内且不需要进行所述再学习的范围内进行所述再学习,此外,能够促进在进行了所述学习的范围外且希望进行所述再学习的范围内进行所述再学习。
技术特征:
1.一种数据处理装置,其中,该数据处理装置包含:
2.一种数据处理装置,其中,该数据处理装置包含:
3.一种数据处理装置,其中,该数据处理装置包含:
4.一种数据处理方法,其中,
5.一种数据处理方法,其中,
6.一种数据处理方法,其中,
技术总结
数据处理装置(10)包含:第1生成部(11A),其生成由多个已学习输入数据(GND)和多个未学习输入数据(MND)构成的多个候选输入数据(KND);第2生成部(11B),其生成由已学习中间数据(GCD)和未学习中间数据构成的多个候选中间数据(KCD);第1选择部(12A),其选择多个候选中间数据(KCD)中的一个候选中间数据(KCD),并且与选择中间数据(SCD)相比,更优先选择在第1学习之后的第2学习中使用时为异质的程度更大的一个候选中间数据(KCD);以及第2选择部(12B),其选择多个候选输入数据(KND)中的、与选择出的一个候选中间数据(KCD)对应的一个候选输入数据(KND),以在第2学习时使用。
技术研发人员:峯泽彰
受保护的技术使用者:三菱电机株式会社
技术研发日:
技术公布日:2024/2/25
- 还没有人留言评论。精彩留言会获得点赞!