一种基于自适应时间结构深度网络的偷窃行为识别方法
1.本发明涉及人物行为识别技术领域,尤其涉及一种基于自适应时间结构深度网络的偷窃行为识别方法。
背景技术:
2.为了维护公共治安稳定,保护人民财产安全,需要对偷窃行为进行监管。随着深度学习和计算机视觉技术的发展,针对偷盗的智能行为识别正逐步引起重视。
3.中国专利申请公布号cn111444861a《一种基于监控视频的车辆偷盗行为识别方法》,提出了一种基于监控视频的车辆偷盗行为识别方法。利用三维卷积提取特征,加入时空联合注意力机制,聚焦行为的时空位置,分类实现偷盗行为识别。但是该方法对于多阶段、长时视频的处理效果并未进行验证。中国专利申请公布号cn109800717b《基于强化学习的行为识别视频帧采样方法及系统》,提出了一种基于lstm确定待测重要性得分,根据得分确定关键帧,对关键帧行为预测,继而得到视频行为预测的方法。但是只根据关键帧进行的预测很容易造成信息缺失甚至造成误判。中国专利申请公布号cn109919031b《一种基于深度神经网络的人体行为识别方法》提出了一种基于深度神经网络的人体行为识别方法,将卷积神经网络单元用于帧图像高层语义特征学习,循环神经网络单元用于视频行为运动特征学习。但是该方法计算量较大,难以对异常行为做到实时的监测。
4.由于计算复杂问题常见于视频处理,针对关键帧的提取、处理方法逐渐用于视频人物行为识别。夏利民等人在《基于关键帧的复杂人体行为识别》中采用自分裂竞争学习提取简单行为片段的关键帧。最后根据行为片段中关键帧的相似度进行复杂人体行为的识别。周育新等人在《基于关键帧的轻量化行为识别方法研究》中将图像平均边缘强度和图像结构清晰度的乘积表示为图像特征量,以在行为视频片段中找到合适的关键帧。最后得到行为分类得分。李鸣晓等人在《基于片段关键帧的视频行为识别方法》中使用图像信息量评价的方法,在视频片段中找到含有最大信息量的图像帧即为关键帧,使用多时间尺度双流网络提取特征,实现行为识别。
5.然而,上述方法并未考虑长时视频中的时间自适应问题,以及缺少全局语义信息分析能力,会造成语义丢失问题。因此,我们提出了一种自适应时间结构深度网络的偷窃行为识别。该方法使用段内视频帧采样lstm模块实现了时间自适应;设计了子行为原型参数矩阵,学习每个视频段的子行为相关的语义描述实现全局语义分析。
技术实现要素:
6.本发明目的就是为了弥补已有技术的缺陷,提供一种基于自适应时间结构深度网络的偷窃行为识别方法。
7.本发明是通过以下技术方案实现的:
8.一种基于自适应时间结构深度网络的偷窃行为识别方法,具体包括以下步骤:
9.(1)提取偷窃行为视频帧特征;
10.(2)估计段内时间结构距离阈值;
11.(3)计算段内视频帧采样lstm的隐状态特征;
12.(4)计算基于子行为原型时间注意力的偷窃行为得分;
13.(5)求解自适应时间结构深度网络的参数集合;
14.(6)基于自适应时间结构深度网络进行偷窃行为识别。
15.步骤(1)所述的提取偷窃行为视频帧特征,具体步骤如下:
16.步骤1-1将偷窃行为视频,按照等时间间隔取ns个视频段,ns取值为8;
17.步骤1-2在每个视频段中,继续按照等时间间隔取ni个子区间,在每个子区间使用随机时间下标采集一个视频帧,在该视频段内共采集ni个视频帧,ni是段内视频帧的采样数量,ni取值为8;
18.步骤1-3使用预训练的resnet50模型,提取每个视频帧的特征,并将特征转换为行向量,获得视频帧的特征集合,x
v,s
={x
v,s,i
},其中x
v,s
是特征集合,v 表示视频编号,s表示视频段编号,i表示段内的视频帧编号,x
v,s,i
是一个行向量,行向量的特征维度为1x1000。
19.步骤(2)所述的估计段内时间结构距离阈值,具体步骤如下:
20.步骤2-1给定训练集中所有视频段的特征x
v,s
={x
v,s,i
};
21.步骤2-2计算段内两个视频帧特征之间的距离d
v,s,i,i+1
,距离计算公式为两个特征x
v,s,i
和x
v,s,i+1
之间的2范数,距离计算公式为表示为:
22.d
v,s,i,i+1
=||x
v,s,i-x
v,s,i+1
||223.步骤2-3对偷窃行为训练集的所有视频的所有段,计算段内两个视频帧特征之间的距离,获得距离集合,d={d
v,s,i,i+1
},v是训练集所有视频的编号,s是视频段编号,i是段内视频帧编号;
24.步骤2-4求出距离集合的均值ud,距离集合的均值公式表示为:
[0025][0026]
其中nv是视频的数量,ns是每个视频内段的数量;
[0027]
步骤2-5求出距离集合的方差,距离集合的方差公式表示为:
[0028][0029]
步骤2-6段内时间结构距离阈值估计公式表示为:
[0030]
τd=ud+σd。
[0031]
步骤(3)所述的计算段内视频帧采样lstm的隐状态特征,具体步骤如下:
[0032]
步骤3-1给定一个视频段的特征x
v,s
={x
v,s,i
};
[0033]
步骤3-2计算段内每个视频帧的二值采样标记;
[0034]
步骤3-2-1根据步骤2-2计算段内两个视频帧之间的距离d
v,s,i,i+1
;
[0035]
步骤3-2-2设置特征距离阈值τd,计算下一个视频帧的采样概率公式表示为:
[0036][0037]
当两个视频帧之间的距离d
v,s,i,i+1
=τd则采样概率为0.5,并随着距离的变大,有
更大的概率被采样;随着距离的变小,有更小的概率被采样;
[0038]
步骤3-2-3根据步骤3-2-2中计算得到的下一个视频帧的采样概率,进行二值0-1的伯努利采样,获得下一个视频帧的二值采样概率;即,使用[0,1]区间内的均匀分布z~u[0,1],产生一个随机数,如果该随机数大于段内采样权重,则返回0,表示下一个视频帧被采样,如果随机数小于段内采样阈值,则返回1,表示下一个视频帧不采样;段内视频帧采样公式表示为:
[0039][0040]
z为随机数,通过随机数z转换为随机性采样,保证样本采样时具有随机性,允许模型对特征权重小的样本进行采样;此时,获得段内每个视频帧的二值采样标记sm
v,s,i,i+1
,该二值采样标记与lstm时间节点对应,其中sm
v,s,1,2
二值采样标记为根据第一个视频帧和第二个视频帧特征距离,来估计第二个视频帧的二值采样标记;
[0041]
步骤3-3根据段内视频帧的下标,初始化lstm的时间节点,其中第i视频帧对应第i时间节点,第i视频帧的二值标记表示为sm
v,s,i-1,i
;
[0042]
步骤3-4对lstm模型添加初始节点,并将初始节点和第一个视频帧的二值采样标记设置为1,即sm
v,s,0,1
=1,获得添加初始节点的lstm的段内二值采样标记集合sm={sm
v,s,0,1
,sm
v,s,1,2
,...,sm
v,s,ni-1,ni
};
[0043]
步骤3-5初始化初始时间节点的记忆状态和隐状态;
[0044]
步骤3-5-1计算当前段的平均特征的公式表示为:
[0045][0046]
步骤3-5-2对当前段的平均特征,使用三层感知器,学习每段lstm初始节点的记忆状态,公式表示为:
[0047][0048]
其中φ
init,c
(
·
)为记忆状态的三层感知器。
[0049]
步骤3-5-3对当前段的平均特征,使用三层感知器,学习每段lstm初始节点的隐状态,公式表示为:
[0050][0051]
其中φ
init,h
(
·
)为隐状态的三层感知器;
[0052]
步骤3-6对当前段的第i个视频帧,即对应lstm中的第i个时间节点,进行段内lstm时间自适应节点更新;
[0053]
步骤3-6-1根据上一个节点的记忆状态c
v,s,i-1
、隐状态h
v,s,i-1
和当前节点的输入x
v,s,i
,使用lstm模块估计第i个节点的候选状态,估计方式为:
[0054][0055]
其中,第一行用于估计忘记门,f
v,s,i
是忘记门的输出,w
fx
、w
fh
和bf表示忘记门的lstm参数;第二行用于估计输入门,in
v,s,i
是输入门的输出,w
inx
、w
inh
和b
in
表示输入门的lstm参数;第三行用于估计选择门,g
v,s,i
是选择门的输出,w
gx
、 w
gh
和bg表示选择门的lstm参数;第四行用于估计输出门,o
v,s,i
是输出门的输出,w
ox
、w
oh
和bo表示输出门的lstm参数;第五行用于估计下一节点的候选记忆状态第六行用于估计下一节点的候选隐状态σ(
·
)和tanh(
·
)表示 sigmoid和tanh激活函数,
⊙
表示哈达马积;
[0056]
步骤3-6-2根据步骤3-3,获得第i个视频帧,即第i个时间节点的二值采样标记sm
v,s,i-1,i
;
[0057]
步骤3-6-3根据二值采样标记sm
v,s,i-1,i
,估计第i个节点的记忆状态c
v,s,i
和隐状态h
v,s,i
,具体方式为:
[0058][0059]
如果二值采样标记sm
v,s,i-1,i
为1,表示采样该节点,则使用lstm更新的第 i个节点的候选记忆状态作为第i个节点的记忆状态,使用lstm更新的第i个节点的候选隐状态作为第i个节点的隐状态;如果二值采样标记sm
v,s,i-1,i
为0,表示不采样该节点,则使用lstm第i-1个节点的记忆状态作为第i个节点的记忆状态,使用lstm第i-1个节点的隐状态作为第i个节点的隐状态;
[0060]
步骤3-7对段内的所有节点进行更新,计算段内lstm最后一个时间节点的隐状态特征;
[0061]
步骤3-7-1如果当前节点不是ni,则说明该段内还有下一个时间节点,执行步骤3-3-5,对段内下一个的时间节点进行处理,求出下一个时间节点的记忆状态c
v,s,i
和隐状态h
v,s,i
;
[0062]
步骤3-7-2重复执行步骤3-6,直到当前节点是段内最后一个时间节点;
[0063]
步骤3-7-3如果当前节点是ni,则说明该段内没有下一个时间节点,返回 lstm中最后一个时间节点的隐状态特征h
v,s,ni
。
[0064]
步骤(4)所述的计算基于子行为原型时间注意力的偷窃行为得分,具体步骤如下:
[0065]
步骤4-1执行步骤3,获得第v个视频每个段的最后一个时间节点的输出隐状态h
v,s,ni
,其中s=1,2,..,ns,第ni个时间节点是该段中最后一个时间节点;
[0066]
步骤4-2设置子行为原型参数矩阵,z={zk},其中k=1,2,..,k共k个原型,原型是特定类别的子行为的描述,每个原型的向量特征维度是1x1000;
[0067]
步骤4-3计算每个视频段的时间注意力;
[0068]
步骤4-3-1计算第s个视频段最后一个时间节点的输出的隐状态,与第k个子行为原型距离,具体形式为:
[0069]
dist
v,s,k
=||h
v,s,ni-zk||2[0070]
步骤4-3-2重复步骤4-3-1,计算获得第s个视频段的隐状态与所有子行为原型的距离向量,具体形式为:
[0071]
dist
v,s
={dist
v,s,k
}
[0072]
步骤4-3-3输入第s个视频段的隐状态与所有子行为原型的距离向量,使用三层感知器和sigmoid函数,学习第s个视频段的时间注意力,具体形式为:
[0073]
α
v,s
=sigmoid(mlp(dist
v,s
))
[0074]
其中mlp是三层感知器,sigmoid(.)是sigmoid激活函数;
[0075]
步骤4-4计算每个视频段的时间注意力增强后的隐状态特征,即,根据第s 个视频段的时间注意力,对隐状态h
v,s,ni
进行特征增强,增强后的隐状态特征为:
[0076][0077]
步骤4-5对视频所有视频段的增强后的隐状态特征串联,获得整个视频的行为表达,并使用三层感知器预测偷窃行为的得分,具体形式为:
[0078][0079]
步骤(5)所述的求解自适应时间结构深度网络的参数聚合,具体步骤如下:
[0080]
步骤5-1执行步骤1,对偷窃行为训练集中的所有视频,进行视频段划分,视频帧采样和特征提取,获得视频的特征集合x
v,s
={x
v,s,i
};
[0081]
步骤5-2执行步骤3,获得每个视频每个段的最后一个时间节点的输出隐状态h
v,s,ni
,其中s=1,2,..,ns,第ni个时间节点是该段中最后一个时间节点;
[0082]
步骤5-3执行步骤4,获得增强后的隐状态特征并获得预测偷窃行为的得分pyv;
[0083]
步骤5-4计算自适应时间结构深度网络的损失函数;
[0084]
步骤5-4-1根据偷窃行为训练集的真实标记和预测获得的偷窃行为标记py={pyv},计算预测得分损失函数,具体形式为:
[0085][0086]
其中,偷窃行为训练集的真实标记表示是偷窃行为,表示不是偷窃行为;
[0087]
步骤5-4-2根据子行为原型参数矩阵z,计算子行为原型的损失函数,具体形式为:
[0088]
lossz=||z
·zt-i||2[0089]
其中z是子行为原型参数矩阵,z的矩阵尺寸是k
×
1000,i是单位矩阵,i的矩阵尺寸为kxk,k为原型的数量,i中对角线元素为1,其余元素为0,该损失函数估计各个子行为原型相互之间的向量乘积接近于0,即各子行为原型特征相互之间接近正交,此时各子行为特征之间具有较大的差异;
[0090]
步骤5-4-3模型训练的总损失函数为,预测得分损失函数和子行为原型的损失函数的总和,即:
[0091]
loss=lossy+lossz[0092]
步骤5-5使用步骤5-4-3计算获得的总损失函数作为梯度,使用反向传播算法,依次对模型的参数求解,在反向传播过程中,需要求解的参数包括:步骤 4-5中的三层感知器中的参数、步骤4-2中的子行为原型参数矩阵、步骤3-6中的lstm模型参数、步骤3-5-3中的隐状态的三层感知器参数、步骤3-5-2中的记忆状态的三层感知器参数;当训练结束后,获得模型的最佳参数集合。
[0093]
步骤(6)所述的基于自适应时间结构深度网络进行偷窃行为识别,具体步骤如下:
[0094]
步骤6-1对测试视频,执行步骤1,对偷窃行为训练集中的所有视频,进行视频段划分、视频帧采样和特征提取,获得视频的特征集合x
test,s
={x
test,s,i
};
[0095]
步骤6-2对测试视频,使用步骤5.5学习获得的模型的最佳参数集合,执行步骤3,获得每个视频每个段的最后一个时间节点的输出隐状态h
test,s,ni
,其中 s=1,2,..,ns,第ni个时间节点是该段中最后一个时间节点;
[0096]
步骤6-3执行步骤4,使用步骤5-5学习获得的模型的最佳参数集合,获得增强后的隐状态特征并预测获得偷窃行为标记py
test
,如果预测标记 py
test
>0.5则说明是偷窃视频,如果预测标记py
test
<0.5则说明不是偷窃视频。
[0097]
本发明的优点是:本发明通过获取停车位的监控视频,实现偷窃行为识别;本发明采用分段方式,实现对长时视频的处理;针对段内特征相似度高而产生的信息冗余问题,通过估计段内时间结构的距离阈值,来计算段内每个视频帧的二值采样标记,去除段内冗余的视频帧,减少段内模型计算量;针对视频段的语义信息重要性估计问题,设计了子行为原型参数矩阵,学习每个视频段的子行为相关的语义描述,并估计视频段的时间注意力,进行视频段的特征增强;最后,对多视频段的特征串联,并使用三层感知器,实现偷窃行为识别;本文发明具有时间自适应能力强,对长时视频中段内的冗余视频帧,和段间的语义信息分析,都具有较好的鲁棒处理能力,可有效实现偷窃行为识别。
附图说明
[0098]
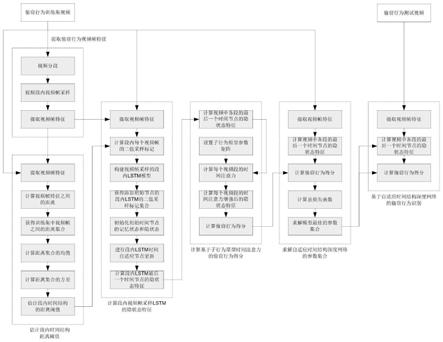
图1自适应时间结构深度网络的偷窃行为识别流程图。
[0099]
图2基于自适应时间结构深度网络的偷窃行为识别流程示意图。
[0100]
图3计算段内视频帧采样lstm的隐状态特征模块。
[0101]
图4计算基于子行为原型时间注意力的偷窃行为得分模块。
[0102]
图5求解自适应结构深度网络的参数集合模块。
[0103]
图6基于自适应时间结构深度网络的偷窃行为识别模块。
具体实施方式
[0104]
如图1-6所示,一种基于自适应时间结构深度网络的偷窃行为识别方法,具体步骤如下:
[0105]
步骤(1)提取偷窃行为视频帧特征:
[0106]
步骤1-1将偷窃行为视频,按照等时间间隔取8个视频段,s是视频段的下标,s的取
值是1,2,...,ns,ns是视频中段的采样数量。
[0107]
步骤1-2在每个视频段中,继续按照等时间间隔取ni个子区间,在每个区间使用随机时间下标采集一个视频帧,在该视频段内共采集ni个视频帧,ni是段内视频帧的采样数量,ni取值为8。
[0108]
步骤1-3使用预训练的resnet50模型,提取每个视频帧的特征,并将特征转换为行向量,获得视频帧的特征集合,x
v,s
={x
v,s,i
},其中x
v,s
是特征集合,v 表示视频编号,s表示视频段编号,i表示段内的视频帧编号,x
v,s,i
是一个行向量,行向量的特征维度为1x1000。
[0109]
步骤(2)估计段内时间结构距离阈值:
[0110]
步骤2-1给定训练集中所有视频段的特征x
v,s
={x
v,s,i
};
[0111]
步骤2-2计算段内两个视频帧特征之间的距离d
v,s,i,i+1
,距离计算公式为两个特征x
v,s,i
和x
v,s,i+1
之间的2范数,距离计算公式为表示为:
[0112]dv,s,i,i+1
=||x
v,s,i-x
v,s,i+1
||2[0113]
步骤2-3对偷窃行为训练集的所有视频的所有段,计算段内两个视频帧特征之间的距离,获得距离集合,d={d
v,s,i,i+1
},v是训练集所有视频的编号,s 是视频段编号,i是段内视频帧编号。
[0114]
步骤2-4求出距离集合的均值ud,距离集合的均值公式表示为:
[0115][0116]
其中nv是视频的数量,ns是每个视频内段的数量。
[0117]
步骤2-5求出距离集合的方差,距离集合的方差公式表示为:
[0118][0119]
步骤2-6段内时间结构距离阈值估计公式表示为:
[0120]
τd=ud+σd[0121]
步骤(3)计算段内视频帧采样lstm的隐状态特征:
[0122]
步骤3-1给定一个视频段的特征x
v,s
={x
v,s,i
};
[0123]
步骤3-2计算段内每个视频帧的二值采样标记;
[0124]
步骤3-2-1根据步骤2-2计算段内两个视频帧之间的距离d
v,s,i,i+1
;
[0125]
步骤3-2-2设置特征距离阈值τd,计算下一个视频帧的采样概率公式表示为:
[0126][0127]
这个公式可以解释为,当两个视频帧之间的距离d
v,s,i,i+1
=τd则采样概率为 0.5,并随着距离的变大,有更大的概率被采样;随着距离的变小,有更小的概率被采样。
[0128]
步骤3-2-3根据步骤3-2-2中计算得到的下一个视频帧的采样概率,进行二值0-1的伯努利采样,sm
v,s,1,2
获得下一个视频帧的二值采样概率;即,使用[0,1] 区间内的均匀分布z~u[0,1],产生一个随机数,如果该随机数大于段内采样权重,则返回0,表示下一个视频帧被采样,如果随机数小于段内采样阈值,则返回1,表示下一个视频帧不采样。段内视频帧采样公式表示为:
[0129][0130]
引入随机数z的目的在于避免根据采样权重进行确定性采样,确定性采样会导致过度信任特征权重;通过随机数z转换为随机性采样,这样能保证样本采样时具有随机性,允许模型对特征权重小的样本进行采样。此时,获得段内每个视频帧的二值采样标记sm
v,s,i,i+1
,该二值采样标记与lstm时间节点对应,其中sm
v,s,1,2
二值采样标记可以解释为根据第一个视频帧和第二个视频帧特征距离,来估计第二个视频帧的二值采样标记。
[0131]
步骤3-3根据段内视频帧的下标,初始化lstm的时间节点,其中第i视频帧对应第i时间节点,第i视频帧的二值标记表示为sm
v,s,i-1,i
;
[0132]
步骤3-4对lstm模型添加初始节点,并将初始节点和第一个视频帧的二值采样标记设置为1,即sm
v,s,0,1
=1,获得添加初始节点的lstm的段内二值采样标记集合sm={sm
v,s,0,1
,sm
v,s,1,2
,...,sm
v,s,ni-1,ni
};
[0133]
步骤3-5初始化初始时间节点的记忆状态和隐状态;
[0134]
步骤3-5-1计算当前段的平均特征的公式表示为:
[0135][0136]
步骤3-5-2对当前段的平均特征,使用三层感知器,学习每段lstm初始节点的记忆状态,公式表示为:
[0137][0138]
其中φ
init,c
(
·
)为记忆状态的三层感知器。
[0139]
步骤3-5-3对当前段的平均特征,使用三层感知器,学习每段lstm初始节点的隐状态,公式表示为:
[0140][0141]
其中φ
init,h
(
·
)为隐状态的三层感知器。
[0142]
步骤3-6对当前段的第i个视频帧,即对应lstm中的第i个时间节点,进行段内lstm时间自适应节点更新;
[0143]
步骤3-6-1根据上一个节点的记忆状态c
v,s,i-1
和隐状态h
v,s,i-1
,和当前节点的输入x
v,s,i
,使用lstm模块估计第i个节点的候选状态,估计方式为:
[0144][0145]
其中,第一行用于估计忘记门,f
v,s,i
是忘记门的输出,w
fx
、w
fh
和bf表示忘记门的lstm参数;第二行用于估计输入门,in
v,s,i
是输入门的输出,w
inx
、w
inh
和b
in
表示输入门的
lstm参数;第三行用于估计选择门,g
v,s,i
是选择门的输出,w
gx
、 w
gh
和bg表示选择门的lstm参数;第四行用于估计输出门,o
v,s,i
是输出门的输出,w
ox
、w
oh
和bo表示输出门的lstm参数;第五行用于估计下一节点的候选记忆状态第六行用于估计下一节点的候选隐状态σ(
·
)和tanh(
·
)表示 sigmoid和tanh激活函数,
⊙
表示哈达马积。
[0146]
步骤3-6-2根据步骤3-3,获得第i个视频帧,即第i个时间节点的二值采样标记sm
v,s,i-1,i
;
[0147]
步骤3-6-3根据二值采样标记sm
v,s,i-1,i
,估计第i个节点的记忆状态c
v,s,i
和隐状态h
v,s,i
,具体方式为:
[0148][0149]
该更新过程可以解释为,如果二值采样标记sm
v,s,i-1,i
为1,表示采样该节点,则使用lstm更新的第i个节点的候选记忆状态作为第i个节点的记忆状态,使用lstm更新的第i个节点的候选隐状态作为第i个节点的隐状态;如果二值采样标记sm
v,s,i-1,i
为0,表示不采样该节点,则使用lstm第i-1个节点的记忆状态作为第i个节点的记忆状态,使用lstm第i-1个节点的隐状态作为第i个节点的隐状态,因此,二值采样标记sm
v,s,i-1,i
实现了对时间的采样,也同时实现了时间自适应。
[0150]
步骤3-7对段内的所有节点进行更新,计算段内lstm最后一个时间节点的隐状态特征;
[0151]
步骤3-7-1如果当前节点不是ni,则说明该段内还有下一个时间节点,执行步骤3-3-5,对段内下一个的时间节点进行处理,求出下一个时间节点的记忆状态c
v,s,i
和隐状态h
v,s,i
;
[0152]
步骤3-7-2重复执行步骤3-6,直到当前节点是段内最后一个时间节点;
[0153]
步骤3-7-3如果当前节点是ni,则说明该段内没有下一个时间节点,返回 lstm中最后一个时间节点的隐状态特征h
v,s,ni
;
[0154]
步骤(4)计算基于子行为原型时间注意力的偷窃行为得分:
[0155]
步骤4-1执行步骤3,获得第v个视频每个段的最后一个时间节点的输出隐状态h
v,s,ni
,其中s=1,2,..,ns,第ni个时间节点是该段中最后一个时间节点。
[0156]
步骤4-2设置子行为原型参数矩阵,z={zk},其中k=1,2,..,k共k个原型,原型是特定类别的子行为的描述,每个原型的向量特征维度是1x1000。
[0157]
步骤4-3计算每个视频段的时间注意力;
[0158]
步骤4-3-1计算第s个视频段最后一个时间节点的输出的隐状态,与第k 个子行为原型距离,具体形式为:
[0159]
dist
v,s,k
=||h
v,s,ni-zk||2[0160]
步骤4-3-2重复步骤4-3-1,计算获得第s个视频段的隐状态与所有子行为原型的距离向量,具体形式为:
[0161]
dist
v,s
={dist
v,s,k
}
[0162]
步骤4-3-3输入第s个视频段的隐状态与所有子行为原型的距离向量,使用三层感
知器和sigmoid函数,学习第s个视频段的时间注意力,具体形式为:
[0163]
α
v,s
=sigmoid(mlp(dist
v,s
))
[0164]
其中mlp是三层感知器,sigmoid(.)是sigmoid激活函数。
[0165]
步骤4-4计算每个视频段的时间注意力增强后的隐状态特征,即,根据第s 个视频段的时间注意力,对隐状态h
v,s,ni
进行特征增强,增强后的隐状态特征为:
[0166][0167]
步骤4-5对视频所有视频段的增强后的隐状态特征串联,获得整个视频的行为表达,并使用三层感知器预测偷窃行为的得分,具体形式为:
[0168][0169]
步骤(5)求解自适应时间结构深度网络的参数集合:
[0170]
步骤5-1执行步骤1,对偷窃行为训练集中的所有视频,进行视频段划分,视频帧采样,和特征提取,获得视频的特征集合x
v,s
={x
v,s,i
};
[0171]
步骤5-2执行步骤3,获得每个视频每个段的最后一个时间节点的输出隐状态h
v,s,ni
,其中s=1,2,..,ns,第ni个时间节点是该段中最后一个时间节点;
[0172]
步骤5-3执行步骤4,获得增强后的隐状态特征并获得预测偷窃行为得分pyv。
[0173]
步骤5-4计算自适应时间结构深度网络的损失函数;
[0174]
步骤5-4-1根据偷窃行为训练集的真实标记和预测获得的偷窃行为标记py={pyv},计算预测得分损失函数,具体形式为:
[0175][0176]
其中,偷窃行为训练集的真实标记表示是偷窃行为,表示不是偷窃行为。
[0177]
步骤5-4-2根据子行为原型参数矩阵z,计算子行为原型的损失函数,具体形式为:
[0178]
lossz=||z
·zt-i||2[0179]
其中z是子行为原型参数矩阵,z的矩阵尺寸是k
×
1000,i是单位矩阵,i的矩阵尺寸为kxk,k为原型的数量,i中对角线元素为1,其余元素为0,该损失函数估计各个子行为原型相互之间的向量乘积接近于0,即各子行为原型特征相互之间接近正交,此时各子行为特征之间具有较大的差异。
[0180]
步骤5-4-3模型训练的总损失函数为,预测得分损失函数和子行为原型的损失函数的总和,即:
[0181]
loss=lossy+lossz[0182]
步骤5-5使用步骤5-4-3计算获得的总损失函数作为梯度,使用反向传播算法,依次对模型的参数求解,在反向传播过程中,需要求解的参数包括:步骤 4-5中的三层感知器中的参数、步骤4-2中的子行为原型参数矩阵、步骤3-6中的lstm模型参数、步骤3-5-3中的隐状态的三层感知器参数、步骤3-5-2中的记忆状态的三层感知器参数。当训练结束后,获得模型的最佳参数集合。
[0183]
步骤(6)基于自适应时间结构深度网络的偷窃行为预测:
[0184]
步骤6-1对测试视频,执行步骤1,对偷窃行为训练集中的所有视频,进行视频段划分,视频帧采样,和特征提取,获得视频的特征集合x
test,s
={x
test,s,i
};
[0185]
步骤6-2对测试视频,使用步骤5.5学习获得的模型的最佳参数集合,执行步骤3,获得每个视频每个段的最后一个时间节点的输出隐状态h
test,s,ni
,其中 s=1,2,..,ns,第ni个时间节点是该段中最后一个时间节点;
[0186]
步骤6-3执行步骤4,使用步骤5-5学习获得的模型的最佳参数集合,获得增强后的隐状态特征并预测获得偷窃行为标记py
test
,如果预测标记 py
test
>0.5则说明是偷窃视频,如果预测标记py
test
<0.5则说明不是偷窃视频。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1