基于知识矩阵跨维度迁移的电网调度快速优化方法与流程
1.本发明属于电力系统技术领域,更具体地,涉及一种基于知识矩阵跨维度迁移的电网调度快速优化方法。
背景技术:
2.近年来新能源、储能及电动车等技术的快速发展,不同类型能源与电网之间的用能互补正在成为提升电网弹性的一种重要方式。各类弹性资源参与电网调度后,虽然能够为电网调度带来更大的弹性空间,但是,随着源荷双侧可参与电网调度的弹性资源种类不断增多,无疑为电网优化调度问题带来了挑战。目前基于智能学习算法来解决电网调度问题存在一定的局限性,比如随着问题规模增大而出现“维数灾”、不同任务往往需要重新求解以及训练时间长等等。但实际上不同的学习任务常常互相关联,因此,如何利用已有的调度知识和经验,并将其迁移至新问题的求解中以提高学习效率,将是一个值得研究的问题。
技术实现要素:
3.针对现有技术中存在的不足之处,本发明提供一种基于知识矩阵跨维度迁移的电网调度快速优化方法。利用所提知识迁移方法得出源任务与目标任务间状态、动作的映射,再根据映射将源电网系统的调度知识迁移至目标电网系统,能够解决调度问题规模扩大时,由于状态或动作空间不同导致历史调度知识不能直接利用的问题,以加快算法收敛速度,提高学习效率,降低学习成本。
4.为实现上述目的,本发明采用如下技术方案:
5.基于知识矩阵跨维度迁移的电网调度快速优化方法,其特征在于,该方法包括如下步骤,
6.步骤1、首先构建不含弹性资源的源电网系统调度优化模型,分别将多组历史典型风光荷数据在不考虑弹性资源的源电网系统中应用q学习算法进行预学习,得到各个典型日学习优化后的q矩阵作为电网调度的历史知识矩阵并构成源任务库;
7.步骤2、弹性资源包括深度调峰机组和可削减负荷,建立深度调峰模型和可削减负荷响应模型,从而构建考虑弹性资源的目标电网系统调度优化模型;
8.步骤3、在日前调度阶段,获取电网系统未来一天各时段的负荷需求、风电出力和光伏出力数据作为目标任务;
9.步骤4、度量源任务与目标任务的相似性,利用负荷、风电和光伏的预测数据计算调度日的净负荷预测曲线,选取净负荷为任务间的相似性关联特征,基于欧氏距离与dtw距离综合度量目标任务净负荷与源任务库中各典型日净负荷的相似性,在源任务库中找出与目标任务距离最小的源任务;
10.步骤5、将与目标任务距离最小的源任务的q矩阵以及目标任务的q矩阵分别分解为状态空间特征矩阵和动作空间特征矩阵,基于pca降维和欧氏距离找出与目标任务中状态、动作距离最小的该源任务中的状态、动作,即构建源任务与目标任务中相似状态、动作
间的映射关系;
11.步骤6、将与目标任务距离最小的源任务的q矩阵按照映射关系对目标任务的q矩阵进行初始化来完成调度知识迁移,在此基础之上对目标任务采用q学习算法再进行优化求解,最后得到目标任务调度日的最优调度计划,有效提升了目标任务的学习效率。
12.本技术方案进一步的优化,所述源电网系统中不包含弹性资源,其内部资源包括火电机组、风力发电机组和光伏发电机组。
13.本技术方案进一步的优化,所述目标电网系统引入了源荷双侧弹性资源参与优化调度,其内部资源包括火电机组、深度调峰机组、风力发电机组、光伏发电机组及可削减负荷。
14.本技术方案进一步的优化,所述深度调峰模型和可削减负荷响应模型如下,
15.深度调峰模型:
16.深度调峰根据火电机组降出力调峰程度可分为不投油深度调峰和投油深度调峰,火电机组在不同的调峰阶段,其运行成本可分段表示为:
[0017][0018]
其中,pg为火电机组出力功率,c
coal
(pg)、c
life
(pg)、c
oil
(pg)分别为火电机组的煤耗成本、寿命损耗成本和附加投油成本,p
g,min
、p
g,max
为火电机组最小技术出力和最大技术出力;pa为火电机组不投油深度调峰稳燃负荷值;pb为火电机组投油深度调峰稳燃极限负荷值,当系统要求火电机组调峰出力低于pa时,需投油助燃。
[0019]
可削减负荷响应模型:
[0020]
通过给予用户激励补偿的方式,挖掘负荷侧响应的弹性可调空间。t时刻削减负荷量p
r,t
与激励补偿价格ε
r,t
的函数关系可近似表示为:
[0021][0022]
假设从t时刻运行至t+
△
t,可削减负荷削减量的补偿成本可表示为:
[0023][0024]
其中,p
r,max
为削减负荷最大弹性可调量,ε
r,min
、ε
r,max
分别为最小激励补偿价格和最大激励补偿价格,α、β、γ分别为关系曲线参数。
[0025]
本技术方案进一步的优化,所述源任务与目标任务的相似性度量按如下步骤进行:
[0026]
步骤5.1:在电网运行中,考虑到负荷需求的波动及新能源消纳,将风电、光伏出力看作反向负荷,通过净负荷曲线p
nl
(即各时刻负荷需求与新能源出力之差)间的距离来表征源任务与目标任务的相似性,则在源任务φ及目标任务ψ中,第k个决策周期的净负荷功率
分别为:
[0027][0028][0029]
其中,p
load,k
、p
wind,k
、p
pv,k
分别为第k个决策周期的负荷需求预测功率、风力发电预测功率及光伏发电预测功率。
[0030]
步骤5.2:按照式(6)计算净负荷时间序列与之间的欧氏距离(euclidean distance),以表征源任务与目标任务之间净负荷在数值上的相似性:
[0031][0032]
步骤5.3:计算净负荷时间序列和之间的动态时间弯曲距离(dynamic time warping,dtw),以表征源任务与目标任务之间净负荷在形态上的相似性:
[0033]
构建一个与之间大小为k
×
k的矩阵γ,矩阵内各元素γ(i,j)为两个序列各点之间的距离,一般采用欧氏距离,即
[0034]
矩阵γ中从(1,1)到(k,k)的路径称为弯曲路径,记为:w={w1,w2,
…
,w
l
},k≤l≤2k-1,w∈ω,对弯曲路径集合ω中每一条弯曲路径w,需满足以下约束:
[0035][0036]
其中,l为路径中元素(i,j)的总个数。dtw算法的目的在于找到一条最优弯曲路径,使得这条路径上的累积距离最小,累计距离即为与之间的dtw距离,如式(8)所示。
[0037][0038]
步骤5.4:结合欧氏距离和dtw距离综合衡量源任务与目标任务之间的相似性,按照式(9)计算源任务与目标任务之间净负荷的距离,距离越小则表示任务间越相似:
[0039][0040]
其中λe、λd分别为欧氏距离和dtw距离的权重系数,λe+λd=1。
[0041]
本技术方案进一步的优化,所述源任务与目标任务间知识矩阵的跨维度迁移方法包括以下步骤:
[0042]
步骤6.1、对于q学习算法,在状态s下是利用q(s,a)的值来指导动作a的选择,而q矩阵则可以看作为当前调度任务的知识矩阵,假设距离最小源任务的知识矩阵为q
φ
,大小为m
×
n,状态空间特征矩阵为s
φ
=(s
φ,1
,s
φ,2
,
…
,s
φ,m
)
t
,动作空间特征矩阵为a
φ
=(a
φ,1
,a
φ,2
,
…
,a
φ,n
)
t
;同理,目标任务的知识矩阵为q
ψ
,大小为p
×
q,状态空间特征矩阵为s
ψ
=(s
ψ,1
,s
ψ,2
,
…
,s
ψ,p
)
t
,动作空间特征矩阵为a
ψ
=(a
ψ,1
,a
ψ,2
,
…
,a
ψ,q
)
t
。其中,s
φ,i
、a
φ,i
、s
ψ,j
、a
ψ,j
分别为由源任务与目标任务中每个状态、动作下包含的信息所组成的特征向量;
[0043]
步骤6.2、若源任务的状态特征向量s
φ,i
与目标任务的状态特征向量s
ψ,j
维度相同,则跳至步骤6.3;否则先将源任务与目标任务的状态特征向量统一至相同维度,目标任务状态特征向量降维后的状态特征矩阵和动作特征矩阵分别为s
′
ψ
=(s
′
ψ,1
,s
′
ψ,2
,
…
,s
′
ψ,p
)
t
、a
′
ψ
=(a
′
ψ,1
,a
′
ψ,2
,
…
,a
′
ψ,q
)
t
;
[0044]
步骤6.3、计算源任务与目标任务状态特征向量之间的欧式距离矩阵ds(s
φ,i
,s
′
ψ,j
),i=1,2,
…
,m,j=1,2,
…
,p;
[0045]
步骤6.4、找出与每个目标任务状态s
′
ψ,j
距离最小的源任务状态s
φ,i
,保存s
φ,i
在ds(s
φ,i
,s
′
ψ,j
)中对应的行索引值index
s,j
=i,该索引值即为s
φ,i
在源任务中的状态编号。同时得到状态索引向量indexs=(index
s,1
,index
s,2
,
…
,index
s,p
),表示与目标任务q矩阵中状态s
′
ψ,j
即s
ψ,j
距离最小的状态为源任务q矩阵中行索引为index
s,j
的状态;
[0046]
步骤6.5、同理,执行步骤6.2~6.4,得到源任务与目标任务动作特征向量之间的欧式距离矩阵da(a
φ,i
,a
′
ψ,j
),i=1,2,
…
,n,j=1,2,
…
,q,以及动作索引向量indexa=(index
a,1
,index
a,2
,
…
,index
a,q
),表示与目标任务q矩阵中动作a
′
ψ,j
即a
ψ,j
距离最小的动作为源任务q矩阵中列索引为index
a,j
的状态;
[0047]
步骤6.6:将源任务的调度知识迁移至目标任务,即将求得的状态索引向量和动作索引向量按照式(10)构成索引矩阵index
p
×q,根据index
p
×q将源任务q矩阵中对应的q值作为目标任务的初始q值。
[0048][0049]
本技术方案进一步的优化,所述将源任务与目标任务的状态/动作特征向量统一至相同维度采用的是pca降维方法。
[0050]
本技术方案进一步的优化,所述q学习算法如下:
[0051]
步骤a:初始化系统模型参数、学习参数、当前学习步数step=0、当前决策周期k=0以及q矩阵;
[0052]
步骤b:确定系统在决策时刻tk的状态,由当前状态和q矩阵采用贪婪策略选择动作,并根据式(11)计算系统在一个决策周期k内产生的总运行代价c
total,k
,更新目标任务的q矩阵;
[0053]ctotal,k
=c
g,k
+c
r,k
+c
a,k
+c
b,k
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(11)
[0054]
其中,c
g,k
、c
r,k
、c
a,k
、c
b,k
分别为决策周期k内的火电机组运行代价、可削减负荷补偿成本、弃风弃光惩罚和失负荷惩罚;
[0055]
步骤c:令k=k+1,若k《k,则返回步骤b;否则令k=0;
[0056]
步骤d:令step=step+1,若step《m,m为总的学习步数,更新探索率并返回步骤b;否则结束程序。
[0057]
区别于现有技术,上述技术方案有益效果如下:针对电力系统日前优化调度问题,基于强化学习算法,本发明给出了一种知识矩阵间跨维度的映射方法,对历史任务的调度经验加以利用。区别于一般机器学习的知识迁移,本发明的迁移机制解决了当调度问题规
模扩大,状态动作空间不同或维度发生变化时,原有的历史调度知识不能直接利用的问题。在电网调度任务或状态动作维度发生变化时,本发明的迁移机制可以有效的利用历史调度知识,加快目标任务的求解,避免重复学习,降低学习成本。
附图说明
[0058]
图1为源电网系统调度资源和目标电网系统内部资源示意图;
[0059]
图2为基于迁移强化学习的电力系统优化调度算法流程示意图;
[0060]
图3为知识矩阵迁移方法示意图。
具体实施方式
[0061]
为详细说明技术方案的技术内容、构造特征、所实现目的及效果,以下结合具体实施例并配合附图详予说明。
[0062]
本发明公开了一种基于知识矩阵跨维度迁移的电网调度快速优化方法,考虑到源荷双侧各类弹性资源的加入,对于强化学习类算法来说,其状态动作空间无疑将会增大,容易产生“维数灾”、求解慢,历史调度知识不能直接利用等问题。故本发明将源荷双侧弹性资源纳入电网调度问题,并利用历史调度知识通过迁移学习的方法来加快目标调度优化问题的求解。
[0063]
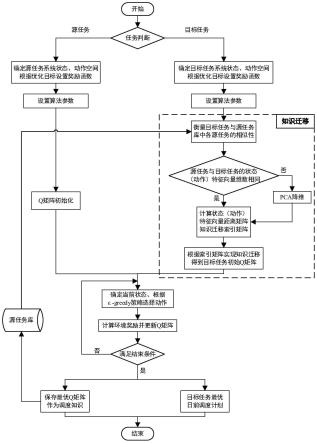
本发明具体以区域电网系统为例进行阐述,下面结合具体实施例和附图,对本发明作进一步的详细说明。参阅如图1所示,为源电网系统调度资源和目标电网系统内部资源示意图。源电网系统内部资源包括:火电机组、光伏机组、风电机组;目标电网系统内部资源包括:火电机组、深度调峰机组、光伏机组、风电机组和可削减负荷。其中,深度调峰机组是具备深度调峰能力的火电机组,可通过对火电机组进行灵活性改造得到。参阅如图2所示,基于迁移强化学习的电力系统优化调度算法流程示意图。以目标任务的优化算法流程为例,本实施例中基于强化学习的电网调度优化及知识矩阵迁移方法,包括如下步骤,
[0064]
步骤1:假设调度日内时刻t的负荷需求预测值为p
load,t
,风电出力预测值为p
wind,i
,光伏出力预测值为p
pv,t
;火电机组按照运行成本分为i、ii、iii类火电机组,源电网系统中三类火电机组全部为火电机组,目标电网系统中将第iii类火电机组设定为可深度调峰机组,在时刻t三类火电机组的出力功率分别为p
g1,t
、p
g2,t
、p
g3,t
。
[0065]
步骤2:建立深度调峰模型和可削减负荷响应模型,
[0066]
深度调峰模型:
[0067]
深度调峰根据火电机组降出力调峰程度可分为不投油深度调峰和投油深度调峰。火电机组在不同的调峰阶段,其运行成本可分段表示为:
[0068][0069]
其中,pg为火电机组出力功率,c
coal
(pg)、c
life
(pg)、c
oil
(pg)分别为火电机组的煤耗成本、寿命损耗成本和附加投油成本,p
g,min
、p
g,max
为火电机组最小技术出力和最大技术出
力;pa为火电机组不投油深度调峰稳燃负荷值;pb为火电机组投油深度调峰稳燃极限负荷值,当系统要求火电机组调峰出力低于pa时,需投油助燃。
[0070]
可削减负荷响应模型:
[0071]
通过给予用户激励补偿的方式,挖掘负荷侧响应的弹性可调空间。t时刻削减负荷量p
r,t
与激励补偿价格ε
r,t
的函数关系可近似表示为:
[0072][0073]
假设从t时刻运行至t+δt,可削减负荷削减量的补偿成本可表示为:
[0074][0075]
其中,p
r,max
为削减负荷最大弹性可调量,ε
r,min
、ε
r,max
分别为最小激励补偿价格和最大激励补偿价格,α、β、γ分别为关系曲线参数。
[0076]
步骤3:将一个调度日分为0~k-1共k个决策周期,第k(0≤k<k)个决策周期的决策时刻为tk;将i类火电机组允许输出的功率范围离散为0~n
g1
共n
g1
+1个等级,将i类火电机组在爬坡约束限制范围内的功率变化区间离散-n
c1
~n
c1
为共2n
c1
+1个等级,则决策时刻tk,i类火电机组的发电功率等级为n
g1,k
,功率调整等级为n
c1,k
。类似地,将ii类火电机组允许输出的功率范围离散为0~n
g2
共n
g2
+1个等级,将ii类火电机组在爬坡约束限制范围内的功率变化区间离散-n
c2
~n
c2
为共2n
c2
+1个等级,则决策时刻tk,ii类火电机组的发电功率等级为n
g2,k
,功率调整等级为n
c2,k
。将iii类火电机组允许输出的功率范围离散为0~n
g3
共n
g3
+1个等级,将iii类火电机组在爬坡约束限制范围内的功率变化区间离散-n
c3
~n
c3
为共2n
c3
+1个等级,则决策时刻tk,iii类火电机组的发电功率等级为n
g3,k
,功率调整等级为n
c3,k
。
[0077]
步骤4:为挖掘可削减负荷的弹性调节空间,将激励补偿价格设定为0~nr共nr+1个等级,其中,等级0表示该时刻无激励,则决策时刻tk的激励等级为n
r,k
,补偿价格为ε
r,k
,再按照式(2)确定削减负荷量为p
r,k
。
[0078]
步骤5:在决策时刻tk,源电网系统的状态特征向量可表征为式(4),动作特征向量可表征为式(5),目标电网系统的状态特征向量可表征为式(6),动作特征向量可表征为式(7)。其中,n
g3,k
、n
c3,k
为源目标电网系统中第iii类火电机组的发电功率等级和调整功率等级;为目标电网系统中第iii类深度调峰机组的发电功率等级和调整功率等级。
[0079][0080][0081][0082][0083]
步骤6:确定系统的优化目标,即系统日运行代价最低,
[0084]
[0085]
其中,c
total
为日运行总代价,c
total,k
为一个决策周期k内的运行代价,c
g,k
、c
r,k
、c
a,k
、c
b,k
分别为决策周期k内的火电机组运行代价、可削减负荷补偿成本、弃风弃光惩罚和失负荷惩罚。
[0086]
步骤7:初始化系统模型参数、学习参数;以净负荷为任务间的相似性关联特征,在源任务库中计算找到与目标任务距离最小的源任务,根据所提知识矩阵迁移方法利用距离最小源任务的历史调度知识初始化目标任务的q矩阵。
[0087]
步骤8:初始化当前学习步数step=0,当前决策周期k=0。
[0088]
步骤9:确定系统在决策时刻tk的状态,由当前状态和q矩阵采用贪婪策略选择动作,并根据式(8)计算系统在一个决策周期k内产生的总运行代价c
total,k
,更新目标任务的q矩阵。
[0089]
步骤10:令k=k+1,若k<k,则返回步骤9;否则令k=0。
[0090]
步骤11:令step=step+1,若step<m,m为总的学习步数,更新探索率并返回步骤9;否则结束程序。
[0091]
上述步骤7中源任务选取与知识迁移包括如下步骤,知识矩阵迁移方法示意图参阅如图3所示。
[0092]
步骤7.1:在电网运行中,考虑到负荷需求的波动及新能源消纳,将风电、光伏出力看作反向负荷,通过净负荷曲线p
nl
(即各时刻负荷需求与新能源出力之差)间的距离来表征源任务与目标任务的相似性,则在源任务φ及目标任务ψ中,第k个决策周期的净负荷功率分别为:
[0093][0094][0095]
其中,p
load,k
、p
wind,k
、p
pv,k
分别为第k个决策周期的负荷需求预测功率、风力发电预测功率及光伏发电预测功率。
[0096]
步骤7.2:按照式(11)计算净负荷时间序列与之间的欧氏距离(euclidean distance),以表征源任务与目标任务之间净负荷在数值上的相似性:
[0097][0098]
步骤7.3:计算净负荷时间序列和之间的动态时间弯曲距离(dynamic time warping,dtw),以表征源任务与目标任务之间净负荷在形态上的相似性:
[0099]
构建一个与之间大小为k
×
k的矩阵γ,矩阵内各元素γ(i,j)为两个序列各点之间的距离,一般采用欧氏距离,即
[0100]
矩阵γ中从(1,1)到(k,k)的路径称为弯曲路径,记为:w={w1,w2,
…
,w
l
},k≤l≤2k-1,w∈ω,对弯曲路径集合ω中每一条弯曲路径w,需满足以下约束:
[0101]
[0102]
其中,l为路径中元素(i,j)的总个数。dtw算法的目的在于找到一条最优弯曲路径,使这条路径上的累积距离最小,累计距离即为与之间的dtw距离,如式(13)所示:
[0103][0104]
步骤7.4:结合欧氏距离和dtw距离综合衡量源任务与目标任务之间的相似性,按照式(14)计算源任务与目标任务之间净负荷的距离,距离越小则表示任务间越相似:
[0105][0106]
其中λe、λd分别为欧氏距离和dtw距离的权重系数,λe+λd=1。
[0107]
步骤7.5:将q矩阵定义为包历史调度经验的知识矩阵,假设距离最小源任务的知识矩阵为q
φ
,大小为m
×
n,状态空间特征矩阵为s
φ
=(s
φ,1
,s
φ,2
,
…
,s
φ,m
)
t
,动作空间特征矩阵为a
φ
=(a
φ,1
,a
φ,2
,
…
,a
φ,n
)
t
;同理,目标任务的知识矩阵为q
ψ
,大小为p
×
q,状态空间特征矩阵为s
ψ
=(s
ψ,1
,s
ψ,2
,
…
,s
ψ,p
)
t
,动作空间特征矩阵为a
ψ
=(a
ψ,1
,a
ψ,2
,
…
,a
ψ,q
)
t
。其中,s
φ,i
、a
φ,i
、s
ψ,j
、a
ψ,j
分别为由源任务与目标任务中每个状态、动作下包含的信息所组成的特征向量。
[0108]
步骤7.6:若源任务的状态特征向量s
φ,i
与目标任务的状态特征向量s
ψ,j
维度相同,则跳至步骤7.7;否则先将源任务与目标任务的状态特征向量统一至相同维度,目标任务状态特征向量降维后的状态特征矩阵和动作特征矩阵分别为s
′
ψ
=(s
′
ψ,1
,s
′
ψ,2
,
…
,s
′
ψ,p
)
t
、a
′
ψ
=(a
′
ψ,1
,a
′
ψ,2
,
…
,a
′
ψ,q
)
t
。
[0109]
步骤7.7:计算源任务与目标任务状态特征向量之间的欧式距离矩阵ds(s
φ,i
,s
′
ψ,j
),i=1,2,
…
,m,j=1,2,
…
,p。
[0110]
步骤7.8:找出与每个目标任务状态s
′
ψ,j
距离最小的源任务状态s
φ,i
,保存s
φ,i
在ds(s
φ,i
,s
′
ψ,j
)中对应的行索引值index
s,j
=i,该索引值即为s
φ,i
在源任务中的状态编号。同时得到状态索引向量indexs=(index
s,1
,index
s,2
,
…
,index
s,p
),表示与目标任务q矩阵中状态s
′
ψ,j
即s
ψ,j
距离最小的状态为源任务q矩阵中行索引为index
s,j
的状态。
[0111]
步骤7.9:同理,执行步骤7.6~7.8,得到源任务与目标任务动作特征向量之间的欧式距离矩阵da(a
φ,i
,a
′
ψ,j
),i=1,2,
…
,n,j=1,2,
…
,q,以及动作索引向量indexa=(index
a,1
,index
a,2
,
…
,index
a,q
),表示与目标任务q矩阵中动作a
′
ψ,j
即a
ψ,j
距离最小的动作为源任务q矩阵中列索引为index
a,j
的状态。
[0112]
步骤7.10:将源任务的调度知识迁移至目标任务,即将求得的状态索引向量和动作索引向量按照式(15)构成索引矩阵index
p
×q,根据index
p
×q将源任务q矩阵中对应的q值作为目标任务的初始q值。
[0113][0114]
本发明考虑到弹性资源的加入,导致源电网系统的历史调度知识不能直接利用,状态动作空间增大后重新进行优化学习收敛缓慢。为此,本发明提出一种知识矩阵间跨维度的迁移方法,在电网调度任务或状态动作维度发生变化时,本发明的调度知识迁移方法可以有效的利用历史调度知识,在一定程度上避免“维数灾”问题,能够有效加快日前调度
计划的求解速度,节约时空资源。
[0115]
需要说明的是,在本发明所提的知识迁移方法和附图3中,为方便表达是以源任务状态(动作)特征向量维度小于目标任务状态(动作)特征向量维度为例进行阐述,事实上,本文的知识迁移方法不拘泥于此限制,只需将两个任务中特征向量维度大的降维至与另一任务维度相同即可。
[0116]
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者终端设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者终端设备所固有的要素。在没有更多限制的情况下,由语句“包括
……”
或“包含
……”
限定的要素,并不排除在包括所述要素的过程、方法、物品或者终端设备中还存在另外的要素。此外,在本文中,“大于”、“小于”、“超过”等理解为不包括本数;“以上”、“以下”、“以内”等理解为包括本数。
[0117]
尽管已经对上述各实施例进行了描述,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例做出另外的变更和修改,所以以上所述仅为本发明的实施例,并非因此限制本发明的专利保护范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1