一种基于加权植被时序属性特征曲线的分类方法
1.本发明属于图像处理领域,主要涉及极化sar遥感数据时序特征提取与分类,具体是一种基于加权植被时序属性特征曲线的分类方法。
背景技术:
2.近些年来,合成孔径雷达(sar)技术在遥感研究领域受到广泛关注,因其具备全天时、全天候、高分辨、大幅宽、穿透力强等多种特点,能弥补光学数据缺失、云雾遮挡等缺陷。极化sar具有多个极化通道,通过极化散射和极化植被指数等可获取到光学遥感不能监测到的植被信息,因此近些年在水汽含量较高的植被茂密区域应用较广,也被用于监测植被的整个生长周期。
3.植被大多具有一定的季相和物候特点,因此遥感影像植被时序分析对于植被信息的提取至关重要。目前对植被时序曲线的研究主要是基于物候信息提取与相似度两个方向。物候信息提取是从构成的植被时序特征曲线中获取具有代表性、能反映植被随时间的生长状态的特殊点用于不同植被的区分;相似度则是从曲线本身出发,计算曲线间的距离作为曲线的相似性度量,以此相似性对曲线所属类别进行分类。动态时间规整法(dynamic time warping,dtw)通过将时间序列进行拉伸,来计算两个时间序列之间的相似性。但dtw曲线的相似性度量是基于整条曲线进行计算和分析的,少有针对局部时段重点分析。
4.另外,以往的遥感研究大多基于像元进行分析,而忽视了目标地物的形状、纹理以及空间拓扑关系等相关特征属性。采用面向对象的遥感影像分析方法在顾及以上特征属性的同时可以有效避免由于高分辨率影像中同类地物光谱变异较大而引起的“胡椒盐效应”。此外,针对不同区域特征最优分割尺度,面向对象多尺度分割能将把影像划分成若干个互不相交的区域,保证对象信息的一致,也大大减少了分类所需的时间并进一步提高了分类精度。
5.本发明针对多时序极化sar数据,提出了一种基于面向对象分割和加权植被时序属性特征相结合的分类方法,以分割单元为对象,以植被生长季为重点监测时段,通过求得各对象的植被时序属性(dtw)曲线的相似性后进行分类。
技术实现要素:
6.本发明目的在于提出一种基于加权植被时序属性特征曲线的分类方法,选取一年内的多景双极化sentinel-1数据,采用面向对象多尺度分割方法对影像进行分割并以分割后的单元为对象,根据植被生长季状况对其时序特征进行加权分析,运用植被生长季加权dtw获取对象时序曲线间相关性作为新的时序属性特征曲线,然后采用最近邻分类(k-nearest neighbor,knn)算法进行分类。通过加大生长季的权重,使得时序曲线相似性度量的计算分析更有针对性,分类精度更高。
7.由此,一种基于加权植被时序属性特征曲线的分类方法,具体的,步骤如下所示;
8.步骤1,下载一年内多景双极化sentinel-1sar影像并进行辐射定标、多视滤波和
配准操作,以消除或减弱相干斑噪声,提高图像的目视解译效果;
9.步骤2,从预处理后的多景影像中选取一景进行面向对象多尺度分割并选取不同类别的对象作为训练样本;
10.步骤3,提取各景影像的极化植被指数;
11.步骤4,对各景极化植被指数特征影像中的各分割对象求平均后按序构成面向对象的极化植被指数时序折线;
12.步骤5,对各对象植被时序折线进行平滑滤波;
13.步骤6,采用加权dtw方法提取各对象植被时序曲线的变换属性并构成属性曲线;
14.步骤7,采用knn算法根据训练样本的属性曲线对待分类对象的属性曲线进行分类;
15.进一步的,所述步骤2中,采用面向对象多尺度分割方法,根据目标地物的形状、纹理以及空间位置关系特征,对像元进行自下而上的区域合并,使得上述特征在同一对象内表现出一致性或相似性,最佳分割尺度通过多次实验的方法结合对分割结果的目视解译获取。
16.进一步的,所述步骤3中,极化植被指数rvi(radar vegetation index)公式如下:
[0017][0018]
以上公式中和分别为极化影像数据后向散射系数。
[0019]
进一步的,所述步骤5中,对提取出的极化植被指数时序折线采用差值法与savitzky-golay滤波器(通常简称为s-g滤波器)对其进行平滑滤波,获得时序拟合曲线。这种滤波器最大的特点在于在滤除噪声的同时可以确保时序曲线的形状、宽度不变。s-g滤波器所含的两个参数包括滑动窗口数值与多项式阶数。为防细节被过滤掉或平滑效果不明显,滑动窗口数值一般在3到7之间,使之参与拟合的值多,效果较好;多项式则一般在2到4之间,阶数越低,平滑效果越好。
[0020]
进一步,所述步骤6中,由于每条时序内每个时间点上的值都可以作为这条时序的属性值,它们是影响相似性度量结果的重要因素,时序属性能够更有效地度量它们相互间的相关度以及分析精度。一般时序分析是基于时序内时间值作为属性进行分析,本发明则利用植被生长季加权dtw的相似度量算法,计算每两个分割对象时序曲线的相似性度量值构成新的属性时序曲线,再通过分析变换属性后的对象时序曲线的相似性进行下一步分析。
[0021]
加权dtw是在dtw的基础上在植被生长季范围内进行距离加权,有针对性的根据植被生长季获取曲线间的相似性度量值。采用设置权重界限方面灵活的改进logistic权重函数(mlwf)进行加权。
[0022][0023]
式中i=2,3,
…
,m表示矩阵的行索引,j=2,3,
…
,n表示矩阵的列索引。d(i,j)是路径的最小累积值。i1《i《i2指植被生长季,d
ij
为两时序曲线构成的矩阵中两个数值的欧氏距离。v
i-j
为两时序曲线匹配点间的权重。权重函数如下所示:
[0024][0025]
其中i=1,2,
…
m,m是序列的长度,mc是序列的中点。v
max
是权重参数的期望上限,g是控制函数曲率(斜率)的经验常数,最优g的范围分布在0.01~0.6,g越大则所占权重越大;
[0026]
进一步的,所述步骤7中,根据上一步获得的变换属性时序计算待分类对象与训练样本的欧氏距离,然后采用最近邻分类(knn)算法进行分类。欧氏距离如下所示:
[0027][0028]
其中x与y分别为训练样本对象曲线与待分类样本对象曲线;n指两条曲线上随机选取对应的点;xi为x曲线上第i个点的值;yi为y曲线上第i个点的值。找寻与待分类对象最近邻的k个训练样本,这k个训练样本属于哪类的数目最多,就把该待分类对象归属到这个类别下。
[0029]
本发明提供的一种基于加权植被时序属性特征曲线的分类方法,具有的技术效果:有针对性的加大植被生长季间的权重并以此提取各对象的植被时序曲线间的相似性作为属性值构成新的时序属性曲线,通过挖掘深层次属性曲线之间的相关性,提高植被类别的分类精度。
附图说明
[0030]
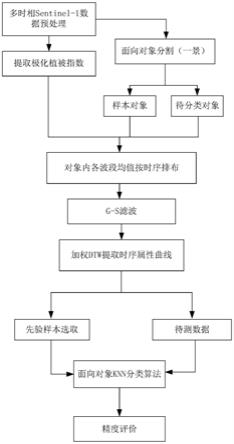
图1为本发明提供的一种基于加权植被时序属性特征曲线的分类方法的流程示意图;
[0031]
图2为本发明提供的时序属性变换的示意图;
[0032]
图3为本发明提供的dtw(dynamic time warping)动态时间规整算法的示意图;
[0033]
图4为本发明提供的植被生长季加权区域示意图。
具体实施方式
[0034]
以下实施例仅用于更清楚地说明本发明的技术方案,流程图如图1:
[0035]
步骤1,下载一年内多景sentinel-1时序影像并进行辐射定标、多视滤波、配准等预处理,以消除或减弱相干斑噪声,提高图像的目视解译效果;sentinel-1时序影像的选择以研究区域与对象的生长季影像数据为主,淡季为辅。
[0036]
步骤2,从预处理后的多景影像中选取一景进行面向对象多尺度分割,获取不同形状大小的地物对象并选取不同类别的对象作为后续分类的样本;面向对象多尺度分割可以根据目标地物的形状、纹理以及空间位置关系等特征,对像元进行自下而上的区域合并,最佳分割尺度通过多次实验的方法结合对分割结果的目视解译获取。
[0037]
步骤3,提取各景影像的极化植被指数;极化植被指数rvi(radar vegetation index)公式如下:
[0038][0039]
以上公式中和分别为极化影像数据后向散射系数。极化植被指数公式仅针对双极化数据,全极化的极化植被指数公式与本发明中所展示的不同。
[0040]
步骤4,对各景极化植被指数特征影像中的各分割对象求平均后按序构成面向对象的极化植被指数时序折线,所有的对象都有一条代表其内部特征的时序折线并进行下一步分析。
[0041]
步骤5,对各对象植被时序折线进行平滑滤波:对提取出的极化植被指数时序折线采用差值法与savitzky-golay滤波器(通常简称为s-g滤波器)对其进行平滑滤波,获得时序拟合曲线。这种滤波器最大的特点在于在滤除噪声的同时可以确保时序曲线的形状、宽度不变。s-g滤波器所含的两个参数包括滑动窗口数值与多项式阶数。为防细节被过滤掉或平滑效果不明显,滑动窗口数值一般在3到7之间,使之参与拟合的值多,效果较好;多项式则一般在2到4之间,阶数越低,平滑效果越好。
[0042]
步骤6,采用加权dtw方法提取各对象植被时序曲线的变换属性;由于每条时序内每个时间点上的值都可以作为这条时序的属性值,它们是影响相似性度量结果的重要因素,时序属性能够更有效地度量它们相互间的相关度以及分析精度。一般时序分析是基于时序内时间值作为属性进行分析,本发明则利用植被生长季加权dtw的相似度量算法,计算每两个分割对象时序曲线的相似性度量值构成新的属性时序曲线,再通过分析新的属性曲线进行下一步分析,如图2。
[0043]
此外,基础的动态时间规整算法(dtw,dynamic time warping),是一种计算2个时间序列尤其是不同长度序列相似度的一种动态规划算法。给定两条时间序列曲线a与b,它们的长度分别是m和n(遥感数据处理时m=n)。
[0044]
a=a1,a2,a3...am[0045]
b=b1,b2,b3...bn[0046]
先构造一个n
×
m的矩阵d以进行对齐操作,矩阵元素d
ij
表示ai和bj两个点之间的距离d(ai,bj),这个距离计算采用的是欧式距离,即
[0047][0048]
dtw算法就是寻找一条从原点出发到(am,bn)的最短路径。路径定义为w,w={w1,w
2,
w3…
wk},w的第k个元素wk=(c
ij
)k,如图3。弯曲路径应满足以下三个条件:
[0049]
(1)有界性即w1=(1,1),w2=(m,n)且max{m,n}《k≤m+n-1;
[0050]
(2)连续性即若w
k-1
=(i',j'),则wk=(i,j)需满足(i-i')<<1和(j-j')<<1;
[0051]
(3)单调性即若w
k-1
=(i',j'),则wk=(i,j)需满足(i-i')>>0和(j-j')>>0;
[0052]
在满足条件的情况下找寻一条最短弯曲路径即最小累加距离dtw(a,b):
[0053][0054][0055]
其中i=2,3,
…
,m表示矩阵的行索引,j=2,3,
…
,n表示矩阵的列索引。d(i,j)是路径的最小累积值。
[0056]
而加权dtw是在dtw的基础上在植被生长季范围内进行距离加权,有针对性地根据植被生长季获取曲线间的相似性度量值。采用改进logistic权重函数(mlwf)进行加权,如图4。
[0057][0058]
式中i1《i《i2指植被生长季时间段,v
i-j
为两时序曲线匹配点间的权重。权重函数如下所示:
[0059][0060]
其中i=1,2,
…
m,m是序列的长度,mc是序列的中点。v
max
是权重参数的期望上限,g是控制函数曲率(斜率)的经验常数,最优g的范围分布在0.01~0.6,g越大则所占权重越大。
[0061]
步骤7,采用knn算法根据训练样本的属性曲线对待分类对象的属性曲线进行分类;采用欧式距离计算待分类样本的属性曲线与训练样本的属性曲线之间的距离并排序,距离公式如下:
[0062][0063]
其中x与y分别为训练样本对象曲线与待分类样本对象曲线;n指两条曲线上随机选取对应的点;xi为x曲线上第i个点的值;yi为y曲线上第i个点的值。通过确定的k值,即距离训练样本最近的待分类对象的个数,找寻与待分类样本最近邻的k个训练样本,统计这k个邻近训练样本出现次数最多的分类,就把该待分类对象归属到这个类别下。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1