基于GMQN的协同作战控制方法、系统、设备及介质
基于gmqn的协同作战控制方法、系统、设备及介质
技术领域
1.本发明属于优化调度领域,更具体地,涉及一种基于gmqn的协同作战控制方法、系统、设备及介质。
背景技术:
2.现代战争呈现作战体系网络化的特点,即基于网络信息体系将各种作战资源、武器装备、探测装备、指挥系统等融合集成,各种作战要素通过网络连为一体形成一体化联合作战体系。分布于战场空间的各类作战实体单元及其作战关系,构成了联合作战体系的作战网络。因此,未来能否取得战争胜利不再取决于单个作战要素的性能,而是整个作战体系的战斗能力。
3.传统的武器-目标分配方案通常是人为设计目标函数,利用传统优化算法如遗传算法进行求解,比如最大化目标的毁伤,这极有可能对某些目标造成武器浪费,甚至可能在将来遭遇敌军时无法反击。另一类方案是对目标的特征进行威胁性评估,再选择合适的武器进行打击,该类方法极大地损失了本方作战体系的全局特征。这些方法都没有全面地考虑全局作战信息的问题。
技术实现要素:
4.针对现有技术的缺陷和改进需求,本发明提供了一种基于gmqn的协同作战控制方法、系统、设备及介质,其目的在于解决传统武器-目标分配方案难以全面地考虑全局作战信息的问题。
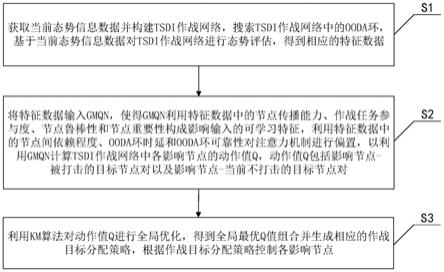
5.为实现上述目的,按照本发明的一个方面,提供了一种基于gmqn的协同作战控制方法,包括:s1,获取当前态势信息数据并构建tsdi作战网络,搜索所述tsdi作战网络中的ooda环,基于所述当前态势信息数据对所述tsdi作战网络进行态势评估,得到相应的特征数据;s2,将所述特征数据输入gmqn,使得gmqn利用所述特征数据中的节点传播能力、作战任务参与度、节点鲁棒性和节点重要性构成影响输入的可学习特征,利用所述特征数据中的节点间依赖程度、ooda环时延和ooda环可靠性对注意力机制进行偏置,以利用gmqn计算所述tsdi作战网络中各影响节点的动作值q,所述动作值q包括影响节点-被打击的目标节点对以及影响节点-当前不打击的目标节点对;s3,利用km算法对所述动作值q进行全局优化,得到全局最优q值组合并生成相应的作战目标分配策略,根据所述作战目标分配策略控制各所述影响节点。
6.更进一步地,所述构建tsdi作战网络包括:根据所述当前态势信息数据中装备的类型,将装备映射为目标节点t、传感节点s、决策节点d和影响节点i;根据映射后各节点之间的交互关系对各节点进行连边,得到所述tsdi网络,连边类型包括探测关系、协同关系、指控关系和行动关系。
7.更进一步地,所述搜索所述tsdi作战网络中的ooda环包括:利用邻接矩阵正向连乘获取设定结构的环路数量,再利用逆向广度优先搜索在所述tsdi作战网络中搜索具有所
述设定结构的ooda环。
8.更进一步地,所述特征数据中的作战任务参与度为:
[0009][0010]
其中,lbti为节点vi的作战任务参与度,分别为通过节点vi、节点vj的ooda环的环数,nv为tsdi作战网络中所有节点的数量。
[0011]
更进一步地,所述特征数据中的节点鲁棒性为:
[0012][0013]
其中,nrbi为节点vi的节点鲁棒性,为通过节点vi的ooda环的环数,为通过节点vi的ooda环lm包含的边数,tk为ooda环lm中边ek的时延,pk为ooda环lm中边ek构成的概率。
[0014]
更进一步地,所述特征数据中的节点重要性为:
[0015][0016]
其中,nimpi为节点vi的节点重要性,nrbi为节点vi的节点鲁棒性,nv为tsdi作战网络中所有节点的数量,lbti、lbtj分别为节点vi、节点vj的作战任务参与度,dis
ij
为节点vi与节点vj之间的最短距离。
[0017]
更进一步地,所述利用km算法对所述动作值q进行全局优化包括:将影响节点i和action分别作为第一类节点和第二类节点,将gmqn计算得到的动作值q作为影响节点i和action连边的权重,action为节点执行的动作;扩充nv
t
个虚拟影响节点作为第一类节点,将所有不存在动作值q的影响节点i和action连边赋予虚拟权重v,nv
t
为目标节点t的数量;利用km算法对所有权重进行全局优化,得到二分图最大权匹配,删除虚拟节点对应的匹配后,得到所有影响节点i的全局最优q值组合。
[0018]
按照本发明的另一个方面,提供了一种基于gmqn的协同作战控制系统,包括:获取及评估模块,用于获取当前态势信息数据并构建tsdi作战网络,搜索所述tsdi作战网络中的ooda环,基于所述当前态势信息数据对所述tsdi作战网络进行态势评估,得到相应的特征数据;输入计算模块,用于将所述特征数据输入gmqn,使得gmqn利用所述特征数据中的节点传播能力、作战任务参与度、节点鲁棒性和节点重要性构成影响输入的可学习特征,利用所述特征数据中的节点间依赖程度、ooda环时延和ooda环可靠性对注意力机制进行偏置,以利用gmqn计算所述tsdi作战网络中各影响节点的动作值q,所述动作值q包括影响节点-被打击的目标节点对以及影响节点-当前不打击的目标节点对;优化控制模块,用于利用km算法对所述动作值q进行全局优化,得到全局最优q值组合并生成相应的作战目标分配策略,根据所述作战目标分配策略控制各所述影响节点。
[0019]
按照本发明的另一个方面,提供了一种电子设备,包括:处理器;存储器,其存储有计算机可执行程序,所述程序在被所述处理器执行时,使得所述处理器执行如上所述的基
于gmqn的协同作战控制方法。
[0020]
按照本发明的另一个方面,提供了一种计算机可读存储介质,其上存储有计算机程序,所述程序被处理器执行时实现如上所述的基于gmqn的协同作战控制方法。
[0021]
总体而言,通过本发明所构思的以上技术方案,能够取得以下有益效果:
[0022]
(1)利用tsdi网络描述作战场景,搜索出可能的ooda环描述作战行动,利用改进的图神经网络的强大表达能力表达作战态势,极大程度地保留了作战态势的全局信息和局部信息,不仅包括双方各个装备的属性信息,也包括作战中信息流、能量流等交互关系的拓扑结构信息;将对作战能力有重大意义的ooda环信息和基于节点和环的态势评估结果作为特征,影响图神经网络的输入和注意力机制的偏置,得到一种改进的图神经网络gmqn,提高了辅助作战决策的效果;
[0023]
(2)使用每个tsdi网络搜索到的ooda环信息作为decoder部分的输入,适配了动作空间动态变化的情况,且在搜索ooda环的阶段就约束好了每个agent的可行动作空间;同时encoder部分可以适配不同节点数量的网络和拓扑结构,整体做到了针对不同作战态势甚至不同作战场景的统一表达;
[0024]
(3)利用图神经网络的连边表达多agent强化学习中的信息交互过程,输出多agent的q值并配合最优化算法做到了仅需一次前向推理,即可获得所有agent的动作,且该联合动作充分考虑了全局关系,提高了全局作战决策的效果。
附图说明
[0025]
图1为本发明实施例提供的基于gmqn的协同作战控制方法的流程图;
[0026]
图2为本发明实施例提供的gmqn的结构示意图;
[0027]
图3为本发明实施例提供的gmql强化学习的流程图;
[0028]
图4为本发明实施例提供的基于gmqn的协同作战控制系统的框图;
[0029]
图5为本发明实施例提出的电子设备的框图。
具体实施方式
[0030]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
[0031]
在本发明中,本发明及附图中的术语“第一”、“第二”等(如果存在)是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。
[0032]
图1为本发明实施例提供的基于gmqn的协同作战控制方法的流程图。参阅图1,结合图2-图3,对本实施例中基于gmqn的协同作战控制方法进行详细说明,方法包括操作s1-操作s3。
[0033]
操作s1,获取当前态势信息数据并构建tsdi作战网络,搜索tsdi作战网络中的ooda环,基于当前态势信息数据对tsdi作战网络进行态势评估,得到相应的特征数据。
[0034]
当前态势信息数据是指当前时刻的态势信息数据。本实施例中,态势信息数据包括:装备,包括雷达、无人歼击机、轰炸机、指挥部等;装备的基本信息,包括型号、阵营、位
置、速度等;装备拥有的能力列表以及每种能力的描述和数据;装备拥有的通讯功能列表以及每种通讯方式的描述和数据;所有指挥部的设立位置、指挥部的级别以及其有权限指挥的装备。
[0035]
根据本发明的实施例,操作s1包括子操作s11-子操作s14。
[0036]
在子操作s11中,获取当前态势信息数据,根据当前态势信息数据中装备的类型,将装备映射为目标节点t、传感节点s、决策节点d和影响节点i。具体地,针对敌我双方作战体系中装备的能力类型,将装备映射为目标节点t、传感节点s、决策节点d和影响节点i。特别地,针对某些具有复合能力的装备,将其映射为多个节点的集合,如无人歼击机同时拥有侦查和打击能力,映射为一个传感节点s和一个影响节点i。
[0037]
在子操作s12中,根据映射后各节点之间的交互关系对各节点进行连边,得到tsdi网络,连边类型包括探测关系、协同关系、指控关系和行动关系,分别对应ooda循环中的观察(observe)、判断(orient)、决策(decide)和行动(act)。本实施例中,对作战网络中所有节点间可能存在的关系进行连边,构建完成后得到全局tsdi网络。
[0038]
在子操作s13中,搜索tsdi作战网络中的ooda环。具体包括:利用邻接矩阵正向连乘获取设定结构的环路数量,再利用逆向广度优先搜索在tsdi作战网络中搜索具有设定结构的ooda环。该具有设定结构的ooda环路包括基本ooda环和扩展的广义ooda环。
[0039]
在子操作s14中,基于当前态势信息数据对tsdi作战网络进行态势评估,得到相应的特征数据。
[0040]
本实施例中,态势评估的指标包括:节点传播能力(node degree,ndg)、作战任务参与度(loop betweenness,lbt)、节点间依赖程度(node dependency,ndp)、节点鲁棒性(node robustness,nrb)、节点重要性(node importance,nimp)、ooda环时延(loop time delay,ltd)、ooda环可靠性(loop reliability,lrl)。
[0041]
态势评估中各指标的具体计算方式为:
[0042][0043][0044][0045][0046][0047][0048]
归一化后的节点鲁棒性和节点重要性为:
[0049][0050][0051]
其中,lbti为节点vi的作战任务参与度,分别为通过节点vi、节点vj的ooda环的环数,nv为tsdi作战网络中所有节点的数量;ndp
ij
为节点vi与节点vj之间的依赖程度,dis
ij
为节点vi与节点vj之间的最短距离;nrbi为节点vi的节点鲁棒性,为通过节点vi的ooda环lm包含的边数,tk为ooda环lm中边ek的时延,pk为ooda环lm中边ek构成的概率;nimpi为节点vi的节点重要性;ltd
l
为ooda环l的时延,lrl
l
为ooda环l的可靠性,ne
l
为ooda环的总数;nrb
′i、nimp
′i分别为归一化后的节点鲁棒性、节点重要性。
[0052]
进一步地,将得到的特征数据进行组合,得到相应的特征向量或矩阵:
[0053][0054][0055]
lbt=[lbt
1 lbt2ꢀ…ꢀ
lbt
nv
]
[0056][0057]
nrb=
é
[nrb
′
1 nrb
′2ꢀ…ꢀ
nrb
′
nv
]
[0058]
nimp=[nimp
′
1 nimp
′2ꢀ…ꢀ
nimp
′
nv
]
[0059]
ltd=[ltd
1 ltd2ꢀ…ꢀ
ltd
nl
]
[0060]
lrl=[lrl
1 lrl2ꢀ…ꢀ
lrl
nl
]
[0061]
其中,分别为节点vi的传播能力指标中的入度、出度。
[0062]
操作s2,将特征数据输入gmqn,使得gmqn利用特征数据中的节点传播能力、作战任务参与度、节点鲁棒性和节点重要性构成影响输入的可学习特征,利用特征数据中的节点间依赖程度、ooda环时延和ooda环可靠性对注意力机制进行偏置,以利用gmqn计算tsdi作战网络中各影响节点的动作值q,动作值q包括影响节点-被打击的目标节点对以及影响节点-当前不打击的目标节点对。
[0063]
本发明实施例中,利用上述特征数据改变transformer神经网络的结构,从而形成为gmqn网络,如图2所示。gmqn作为强化学习的内置神经网络,在感知战场时能很好地表达态势信息。
[0064]
gmqn包含encoder部分和decoder部分,分别由若干个encoderlayer和decoderlayer构成。
[0065]
encoder部分具体为:
[0066][0067][0068][0069]mlbt
=lbt
t
·wlbt
[0070]mnrb
=nrb
t
·wnrb
[0071]mnimp
=nimp
t
·wnimp
[0072][0073][0074][0075][0076][0077][0078][0079][0080][0081][0082][0083]
其中,xv∈r
nv
×
dv
,wlbt
∈r1×
dv
,m
lbt
∈r
nv
×
dv
,w
nrb
∈r1×
dv
,m
nrb
∈r
nv
×
dv
,w
nimp
∈r1×
dv
,m
nimp
∈r
nv
×
dv
,e
(0)
∈r
nv
×
dv
,,,lm∈l
ij
,mhba
en(l)
∈r
nv
×
dv
,表示一个节点的属性向量;xv∈r
nv
×
dv
表示所有节点的属性矩阵;nv为节点数;dv为节点属性向量的长度;w为可训练的权重参数;e
(l)
表示encoder的第l层encoderlayer;en(l)(h)表示第l层encoderlayer的第h个注意力头;hs
en(l)(h)
表示第l层encoderlayer第h个注意力头的大小;nh
en(l)
表示第l层encoderlayer具有的注意力头数;d、dffn为隐藏层节点数;l
ij
表示同时通过节点vi和节点vj的所有环的集合。
[0084]
decoder部分具体为:
[0085][0086]d(0)
=x
l
[0087][0088][0089][0090][0091][0092][0093][0094][0095][0096]
[0097][0098]
qs=d
(dls)
.w
out
[0099]
其中,x
l
∈r
nl
×
dl
,d
(0)
∈r
nl
×
dl
,,,mha
de(l)
∈r
nl
×
dl
,,,mha
dec(l)
∈r
nl
×
dl
,w
om
∈r
dl
×1,qs∈r
nl
×1。表示一个环属性向量;x
l
∈r
nl
×
dl
表示所有环属性矩阵;nl为环数;dl为环性向量的长度;d
(l)
表示decoder的第l层decoderlayer;de(l)(h)表示第l层decoderlayer的第h个自注意力机制头;hs
de(l)(h)
表示第l层decoderlayer第h个自注意力机制头的大小;nh
de(l)
表示第l层decoderlayer具有的自注意力机制头数;dec(l)(h)表示第l层decoderlayer的第h个交叉注意力机制头;hs
dec(l)(h)
表示第l层decoderlayer第h个交叉注意力机制头的大小;nh
dec(l)
表示第l层decoderlayer具有的交叉注意力机制头数;qs为输出的q值向量。
[0100]
以上模型中使用w
lbt
、w
nrb
、w
nimp
、w
loop
、w
ndp
、w
ffn
等参数进行的变换可改为其他函数或神经网络模型,只需满足输入输出空间与上述一致即可。利用环路特征作为decoder部分输入以适应数量变化的动作值。
[0101]
进一步地,构建强化学习环境训练神经网络模型,如图3所示。例如在联合作战仿真平台上搭建区域防空作战场景,设置敌方轰炸机随机时间和路线进行轰炸,进行10000次仿真并收集数据从而进行基于图的多q值优化强化学习(gmql)。
[0102]
具体地,参阅图3,将一次作战分为若干决策阶段,将每一个影响节点i视为angent进行序贯决策,构成多agent的马尔可夫决策过程。对每个agent而言,state为全局tsdi网络,并萃取处gmqn的9部分输入;action为从通过该节点的环中选取一个进行实施或暂时保持现状(idle)。共用所有agent的state,且每一个agent的动作可对应为decoder部分的一个输入向量,进而gmqn的输出对应为每个动作的q值。最后设置每个agent的reward为作战目的相关函数,进行基于图的多q值优化强化学习。
[0103][0104][0105]
[0106]
其中,ii表示第i个影响节点i;ti表示节点ii本次动作打击的目标;ω为各节点的权重,由装备的价值决定;
△
blood表示变化的血量;vs表示所有s节点的集合;vd表示所有d节点的集合;vi表示所有i节点的集合;v
t
表示所有t节点的集合;nvi表示i节点的数量;λs表示我方全局状态权重系数;λe表示敌方全局状态权重系数;γ为折扣系数;a为学习率。
[0107]
仿真或训练过程中,每一决策阶段的全局联合动作由kuhn-munkras(km)优化算法获得,即从所有action-q value对中选取满足约束的若干对,每一对代表一个agent的动作。
[0108]
强化学习训练之后,利用改进后的gmqn网络获取每个i-t节点对或i-idle动作对的q值。具体地,将改进的图神经网络进行一次前向推理,获取每个ooda环或i-idle动作对应的q值,每一个ooda环确定了一个i-t节点对。优选地,选取同时含有确定影响节点i、目标节点t的所有ooda环中q值最大的作为该影响节点i打击该目标节点t的q值。
[0109]
操作s3,利用km算法对动作值q进行全局优化,得到全局最优q值组合并生成相应的作战目标分配策略,根据作战目标分配策略控制各影响节点。
[0110]
根据本发明的实施例,利用km算法对动作值q进行全局优化包括:将影响节点i和action分别作为第一类节点和第二类节点,将gmqn计算得到的动作值q作为影响节点i和action连边的权重,action为节点执行的动作;扩充nv
t
个虚拟影响节点作为第一类节点,将所有不存在动作值q的影响节点i和action连边赋予虚拟权重v,nv
t
为目标节点t的数量;利用km算法对所有权重进行全局优化,得到二分图最大权匹配,删除虚拟节点对应的匹配后,得到所有影响节点i的全局最优q值组合,即每个影响节点i需要做的动作action。虚拟权重v满足:
[0111]
本实施例中,利用km算法进行全局优化,可以等效为求解以下优化问题:
[0112][0113][0114]
其中,nvi为影响节点i的数量;nv
t
为目标节点t数量;q(s,a
ij
)表示第i个影响节点i(agent)选择动作j时的q值。本实施例中的动作选择策略为gmqn的多智能体q值输出结合最优化算法,而非传统q-learning中的贪婪选择策略。
[0115]
进一步地,将km算法获得的全局最优q值组合作为当前决策阶段的分配方案进行控制实施,循环上述操作s1-操作s4直至作战结束。共享状态多q值强化学习(gmql)利用图神经网络的连边表达多智能体间的信息交互,所有智能体共享全局状态;智能体仅在非行动期间可决策,在行动期间的智能体参与状态的贡献但不参与动作的分配,reward在该行动完成时进行结算,全局统一分配动作时考虑该约束,相当于各智能体进行异步决策和行动。
[0116]
图4为本发明实施例提供的基于gmqn的协同作战控制系统的框图。参阅图4,该基
于gmqn的协同作战控制系统400包括获取及评估模块410、输入计算模块420以及优化控制模块430。
[0117]
获取及评估模块410例如执行操作s1,用于获取当前态势信息数据并构建tsdi作战网络,搜索tsdi作战网络中的ooda环,基于当前态势信息数据对tsdi作战网络进行态势评估,得到相应的特征数据。
[0118]
输入计算模块420例如执行操作s2,用于将特征数据输入gmqn,使得gmqn利用特征数据中的节点传播能力、作战任务参与度、节点鲁棒性和节点重要性构成影响输入的可学习特征,利用特征数据中的节点间依赖程度、ooda环时延和ooda环可靠性对注意力机制进行偏置,以利用gmqn计算tsdi作战网络中各影响节点的动作值q,动作值q包括影响节点-被打击的目标节点对以及影响节点-当前不打击的目标节点对。
[0119]
优化控制模块430例如执行操作s3,用于利用km算法对动作值q进行全局优化,得到全局最优q值组合并生成相应的作战目标分配策略,根据作战目标分配策略控制各影响节点。
[0120]
基于gmqn的协同作战控制系统400用于执行上述图1-图3所示实施例中的基于gmqn的协同作战控制方法。本实施例未尽之细节,请参阅前述图1-图3所示实施例中的基于gmqn的协同作战控制方法,此处不再赘述。
[0121]
本公开的实施例还示出了一种电子设备,如图5所示,电子设备500包括处理器510、可读存储介质520。该电子设备500可以执行上面图1-图3中描述的基于gmqn的协同作战控制方法。
[0122]
具体地,处理器510例如可以包括通用微处理器、指令集处理器和/或相关芯片组和/或专用微处理器(例如,专用集成电路(asic)),等等。处理器510还可以包括用于缓存用途的板载存储器。处理器510可以是用于执行参考图1-图3描述的根据本公开实施例的方法流程的不同动作的单一处理单元或者是多个处理单元。
[0123]
可读存储介质520,例如可以是能够包含、存储、传送、传播或传输指令的任意介质。例如,可读存储介质可以包括但不限于电、磁、光、电磁、红外或半导体系统、装置、器件或传播介质。可读存储介质的具体示例包括:磁存储装置,如磁带或硬盘(hdd);光存储装置,如光盘(cd-rom);存储器,如随机存取存储器(ram)或闪存;和/或有线/无线通信链路。
[0124]
可读存储介质520可以包括计算机程序521,该计算机程序521可以包括代码/计算机可执行指令,其在由处理器510执行时使得处理器510执行例如上面结合图1-图3所描述的方法流程及其任何变形。
[0125]
计算机程序521可被配置为具有例如包括计算机程序模块的计算机程序代码。例如,在示例实施例中,计算机程序521中的代码可以包括一个或多个程序模块,例如包括521a、模块521b、
……
。应当注意,模块的划分方式和个数并不是固定的,本领域技术人员可以根据实际情况使用合适的程序模块或程序模块组合,当这些程序模块组合被处理器510执行时,使得处理器510可以执行例如上面结合图1-图3所描述的方法流程及其任何变形。
[0126]
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1