基于对比学习和自适应注意力的图像描述生成方法及介质
1.本发明涉及人工智能技术领域,具体涉及一种基于对比学习和自适应注意力的图像描述生成方法及介质。
背景技术:
2.图像字幕任务是跨模态的视觉语言任务之一,其旨在自动生成自然语言句子来描述给定图像的视觉内容。目前其主要采用编码器-解码器框架,编码器提取视觉特征,解码器生成图像描述的句子,并通过引入注意机制来帮助模型在生成每个单词时关注相关位置。因此,改进图像字幕模型主要集中在两个主要方面:a)图像特征表示;b)模型结构。在视觉表示方面,模型往往采用图像的单层特征作为输入,如语义较弱的网格特征、语义中等的对象特征或语义较强的文本特征。然而,描述句中的不同词往往与不同层次的特征相关,如颜色单词可以从低层特征预测,量词可以从中层特征预测,因此将不同层次的特征结合起来预测句子具有重要意义。在模型结构方面,因为transformer架构能够在训练期间更好地并行捕获视觉特征和过程序列之间的关系,所以基于transformer的图像字幕模型在公共基准测试中一直处于领先地位。然而,由于视觉和语言之间存在语义鸿沟,即并非字幕中的所有单词都是视觉单词并具有相应的视觉信号,但transformer解码器层中基于scaled dot-product操作的注意力模块在预测每个单词的中间表示时,会将所有词的预测都平等对待,没有采取有效措施来对不同词(如,with和dog)所依赖的特征不同而进行不同的处理。因此,针对以上的不足,本方法提供了一种基于对比学习和自适应注意力的图像描述生成方法。
技术实现要素:
3.为了克服现有技术存在的缺点与不足,本发明提供一种基于对比学习和自适应注意力的图像描述生成方法及介质。
4.本发明采用如下技术方案:
5.一种基于对比学习和自适应注意力的图像描述生成方法,包括:
6.给定一张图片,提取全局特征表示、网格特征表示、区域对象特征表示及文本特征表示;
7.将全局特征表示分别与其它三个层次特征构建三个独立的自注意力网络模块,并分别得到网格注意力特征、区域对象注意力特征及文本注意力特征;
8.通过多模态双线性策略将图像区域注意力特征整合到网格注意力特征和文本注意力特征中,分别获得该图像的低层特征和高层特征,并利用门控机制生成图像的最终视觉特征表示;
9.将图像的最终视觉特征表示和之前已生成的单词序列输入到解码器中,得到当前预测词的隐藏状态表示;
10.将图像描述文本编码向量输入到预训练好的语言模型中,得到语言特征信号;
11.将当前预测词的隐藏状态表示、图像的最终视觉特征表示和语言特征信号作为自适应注意力模型的输入,用以度量视觉信息和语言信息对当前词预测的贡献,从而动态生成视觉词和非视觉词;
12.并通过对比学习的训练方式,提升图像描述的辨识度。
13.进一步,所述整合图像不同层次的特征信息,获得该图像的高层特征和低层特征,并生成图像的最终视觉特征表示,具体步骤如下:
14.通过分别将区域对象注意力特征输入文本注意力特征和网格注意力特征,并通过多模态双线性策略来探究图像不同层次特征之间的内在关系;
15.构建两个独立的残差网络,并分别将文本注意力特征和网格注意力特征及其与区域对象注意力特征之间的内在关系投影到统一的对象空间,形成图像的高层内容特征和低层位置信息;
16.通过门控机制有选择性的整合图像的高层特征和低层特征,生成图像的最终视觉特征表示。
17.进一步,所述将图像的最终视觉特征表示作为视觉信号,将预训练bert模型的输出作为文本信号,度量视觉信息和语言信息对当前词预测的贡献,从而动态生成视觉词和非视觉词。
18.进一步,所述将图像的文本描述用预训练好的语言模型进行处理,得到了文本信号,并加入了masked注意力模块,以自回归的方式加入到当前词的预测过程中。
19.进一步,所述自适应注意力模型为一个多头自注意力模块。
20.进一步,三个独立的自注意力网络模型的为相同结构,注意力特征获取流程具体如下:
[0021][0022][0023][0024]
其中,其中,ao,a
p
,a
t
分别表示区域注意特征、网格注意特征和文本注意特征,是上一时刻解码器的隐藏状态,w
t
是当前时间步的预测词,e是将one-hot表示映射到嵌入空间的嵌入函数。
[0025]
进一步,所述对比学习,具体步骤为:
[0026]
构建正样本和负样本图像文本对,利用本模型自动生成正负样本描述的单词序列,计算生成的文本描述与图片原始描述语句之间的余弦相似度,并最大化图文对匹配的相似度,最小化图文对不匹配的相似度。
[0027]
进一步,采用对称的交叉熵损失函数对余弦相似度分数进行训练。
[0028]
进一步,使用在imagenet上预训练的resnet101的最后一个卷积层提取图像的全局特征表示vg和网格特征表示v
p
,使用faster r-cnn提取图像的区域对象特征表示vo,采用以resnet101为主干的文本分类预测器提取图像的文本语义特征v
t
。
[0029]
一种存储介质,其上存储有计算机程序,所述计算机程序被处理器执行实现所述的图像描述生成方法。
[0030]
本发明的有益效果:
[0031]
本方法基于transformer框架,提取图像的网格特征、对象特征和文本特征作为输入,并采用不同的注意力机制生成相应的注意力特征。
[0032]
为了更好地整合不同层次的注意力特征,本方法将不同层次的特征投影到一个统一的目标空间中,探索不同层次的特征空间之间的内在关系,并引入了上下文门控机制,以平衡低级上下文和高级上下文的贡献,使得在生成描述语句中的词的时候能够更细粒度的关注图像的不同层次特征。
[0033]
为了衡量视觉信息和语言上下文信息对细粒度字幕生成的贡献,本方法构建了基于语言上下文和视觉信号的自适应注意模块,便于区分句子中的视觉词和非视觉词,并加入了预测哪个文本作为一个整体与哪个图像配对的对比学习任务,以便生成的字幕更具可辨性。
[0034]
本方法在基准数据集上实取得了较大性能的提升,通过大量实验验证了本方法的可行性和通用性。
附图说明
[0035]
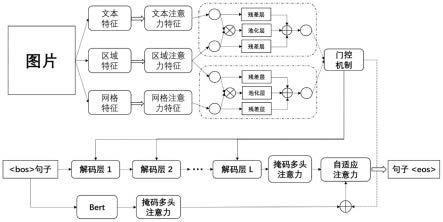
图1是本发明的流程示意图。
具体实施方式
[0036]
下面结合实施例及附图,对本发明作进一步地详细说明,但本发明的实施方式不限于此。
[0037]
实施例
[0038]
如图1所示,一种基于对比学习和自适应注意力的图像描述生成方法,其神经网络模型主要是由编码器和解码器构成。
[0039]
其主要利用图像不同层次特征之间的关系,生成了更加详细的图像描述句子,在当前词预测阶段,针对视觉词和非视觉词进行了不同处理,使得他们在预测生成过程中关注了不同的视觉特征信号和文本特征信号,加入了对比学习任务,使生成的句子具有更好的可辨性。
[0040]
具体包括如下步骤:
[0041]
s1图像特征提取
[0042]
给定一张图片,使用在imagenet上预训练的resnet101的最后一个卷积层提取图像的全局特征表示vg和网格特征表示v
p
;使用faster r-cnn提取图像的区域对象特征表示vo;文本特征是指与图像相关的语义概念,包括形容词、动词和名词,使用由resnet101的主干和三个全连接层组成的文本分类预测器提取图像的文本语义概念,然后通过embedding函数转换为文本特征表示v
t
。
[0043]
s2注意力特征计算
[0044]
为了关注当前时间步与单词最相关的特征,本方法在三个层次特征上构建三个独立的自注意力网络模块细化各个特征得到网络注意力特征、区域对象注意力特征及文本注意力特征。由于生成序列中的非视觉词与对象和文本特征无关,因此本方法在最后一个时间步将对象特征与全局特征、文本特征与解码器的语义特征连接起来,以提供额外的全局
信息来参与。
[0045]
注意力特征计算公式如下:
[0046][0047][0048][0049]
其中,其中,ao,a
p
,a
t
分别表示区域对象注意力特征、网格注意力特征和文本注意力特征,是上一时刻解码器的隐藏状态,w
t
是当前时间步的预测词,e是将one-hot表示映射到嵌入空间的嵌入函数。
[0050]
s3整合不同层次的图像特征。
[0051]
分别将区域对象特征信息提供给文本特征信息和网格特征信息,通过多模态双线性策略来探究图像不同层次特征之间的内在关系,分别获得该图像的低层特征和高层特征,并利用门控机制生成图像的最终视觉特征表示;
[0052]
具体步骤为:
[0053]
s3.1分别将区域注意力特征整合到网格注意力特征和文本注意力特征中,通过多模态双线性策略来探究图像不同层次特征之间的内在关系,如公式(4)和(5)所示:
[0054][0055]rt
,r
p
=avgpool(z
t/p
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
[0056]
其中,w,w
′
代表权重矩阵,
·
表示哈达玛积,r表示不同层次特征之间的关系特征,avgpool表示平均池,a
t/p
是a
t
和a
p
的简写,以下情况类似。
[0057]
s3.2构建两个独立的残差网络,分别将网格注意力特征和文本注意力特征及其与区域对象注意力特征之间的内在关系投影到对象空间,从而形成图像的高层内容特征和低层位置信息,如公式(6)和(7)所示。
[0058]hp
,h
t
=a
p/t
+relu(wa
p/t
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0059]ml
,mh=ao+h
p/t
+r
p/t
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
[0060]
其中,relu是非线性激活函数,h表示投影特征,r表示不同层次特征之间的关系特征,m
l/h
表示m
l
和mh,分别表示图像的高层内容特征和低层位置信息。
[0061]
s3.3通过门控机制(门机制)有选择性的整合图像的高层特征和低层特征,生成图像的整体视觉特征表示,用以指导句子的生成过程,如公式(8),(9)和(10)所示。
[0062][0063][0064]
m=[(1-g
ctx
)
·ml
,g
ctx
·
mh]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(10)
[0065]
其中,g
ctx
是一个512维的权重向量,m是融合图像不同层次特征后的整体视觉特征表示。
[0066]
s3.4语言特征表示
[0067]
将上述所得图像特征的中间表示输入解码器生成图像的句子描述序列,由于序列中每个单词是以自回归的方式生成的,因此需要添加一个masked注意力模块,即只将已生
成的序列(初始为一个开始字符《bos》)送入到预训练好的语言模型中,提取出生成序列的语言信息表示,并通过优化交叉熵的方式训练语言模型得到语言特征信号。如公式(11)和(12)所示:
[0068]
s=bert(w)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(11)
[0069][0070]
其中,bert是预训练的语言模型,mam是masked注意力模块,softmax是一个神经网络激活函数,w是单词序列,s表示单词序列对应的语言特征,pos为序列中单词的位置信息,即为序列中当前单词的语言信息表示。
[0071]
图1中《bos》为一个开始的字符,《eos》是句子的结束符。
[0072]
s3.5自适应注意力模块
[0073]
将当前预测词的隐藏状态表示、图像的最终视觉特征表示和语言特征信号作为自适应注意力模型的输入,用以度量视觉信息和语言信息对当前词预测的贡献,从而动态生成视觉词和非视觉词。
[0074]
具体为:
[0075]
之前基于transformer架构的图像描述模型直接使用解码器输出的单词的隐含状态来做单词预测,隐含状态的计算过程如公式(13)所示:
[0076]ht
=decoder(u,w
t
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(13)
[0077]
而本方法的自适应注意力模型是一个多头注意力模块,它使模型在做单词预测前再衡量一次视觉信息和语言信息对当前单词预测的贡献,以便动态地生成视觉词或者非视觉词。其计算过程如下:
[0078]
q=w
qht
;k=wk[m,s
t
];v=wv[m,s
t
]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(14)
[0079]
head=concate(head1,head2,
…
,headh)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(15)
[0080]
headi=attention(q,k,v)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(16)
[0081]
att=head*w
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(17)
[0082]
其中,wq,wk,wv,w是权重矩阵,headi是第i个头计算出的注意力值,att是自适应注意力模块输出的注意力值,concate表示拼接操作。att是多头注意在序列生成中的注意结果,并用其做当前词的预测。
[0083]
s3.6对比学习步骤
[0084]
构建正样本和负样本作为输入,正负样本都是图像-文本对,正样本的caption与图片是匹配的,负样本图片与正样本相同,但caption却是描述其他图片的。将正负样本输入模型,并计算字幕模型生成的文本与图片之间的余弦相似度,最大化图文对匹配的相似度,最小化图文对不匹配的相似度,针对余弦相似度分数采用对称的交叉熵损失函数进行训练,并在训练过程中不断优化降低该损失即可。
[0085]
本方法基于transformer框架,提取图像的网格特征、对象特征和文本特征作为输入,并采用不同的注意力机制生成相应的注意力特征。为了更好地整合不同层次的注意力特征,本方法将不同层次的特征投影到一个统一的目标空间中,探索不同层次的特征空间之间的内在关系,并引入了上下文门控机制,以平衡低级上下文和高级上下文的贡献。为了衡量视觉信息和语言上下文信息对细粒度字幕生成的贡献,本方法构建了基于语言上下文
和视觉信号的自适应注意模块,并加入了预测哪个文本作为一个整体与哪个图像配对的对比学习任务,以便生成的字幕更具可辨性。本方法在基准数据集上实取得了较大性能的提升,通过大量实验验证了本方法的可行性和通用性。
[0086]
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受所述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1