用于生成合成深度数据的系统、方法和存储介质与流程
1.本公开涉及用于基于2维数据生成合成深度数据以增强用于图像识别和其他目的的2维的系统、方法和存储介质。
背景技术:
2.面部识别是一个活跃的研究领域,由于诸如alexnet、vgg、facenet和resnet之类的已知深度神经网络的可用性,该领域最近见证了相当大的进展。如本文中所使用的“神经网络”(有时被称为“人工神经网络”)指的是神经元的网络或电路,其可以被实现为在一个或多个计算机处理器上执行的计算机可读代码。神经网络可以由用于解决人工智能(ai)问题的人工神经元或节点组成。节点的连接被建模为权重。正的权重反映了兴奋性连接,而负值意味着抑制性连接。输入可以通过权重修改并求和。这种活动被称为线性组合。最后,激活函数控制输出的幅度。例如,可接受的输出范围通常介于0和1之间,或者其可能介于-1和1之间。神经网络可以用于预测建模、自适应控制和其中它们可以经由数据集训练的应用。从经验产生的自学习可以发生在网络内,网络可以从复杂且看似不相关的信息集合导出结论。深度神经网络可以学习鉴别性表示,这些表示已经能够处理广泛范围的挑战性视觉任务,诸如图像识别,并且甚至在某些情况下超过人类识别能力。
3.基于2维的图像识别方法(诸如面部识别方法)一般倾向于对环境变化敏感,所述环境变化比如照明、遮挡、视角和姿态。通过利用深度信息连同2维图像数据(诸如rgb数据),模型可以学习面部和其他对象的更鲁棒的表示,因为深度提供了关于面部固有形状的补充几何信息,从而进一步提高了识别性能。此外,已知rgb和深度(rgb-d)面部识别方法对姿态和照明改变不太敏感。然而,尽管rgb和其他2维传感器无处不在,但是深度传感器却不太普遍,从而导致仅过度依赖2维数据。
4.已经证明生成对抗网络(gan)及其变型(例如,cgan、pix2pix、cyclegan、stackgan和stylegan)是许多应用领域中数据合成的可行解决方案。在面部图像的背景下,当在大规模数据集(诸如ffhq和celeba-hq)上训练时,gan已经被广泛用于生成非常高质量的rgb图像。在少数情况下,已经尝试从对应的rgb图像合成深度。例如,stefano pini、filippo grazioli、guido borghi、roberto vezzani和rita cucchiara的“learning to generate facial depth maps”,2018,international conference on 3d vision (3dv),第634
–
642页,ieee,2018;dong-hoon kwak 和seung-ho lee的“a novel method for estimating monocular depth using cycle gan and segmentation”,sensors, 20(9):2567, 2020;以及 jiyun cui、hao zhang、hu han、shiguang shan、和 xilin chen的“improving 2d face recognition via discriminative face depth estimation”,international conference on biometrics,第140
–
147页,2018,教导了用于从2维数据合成深度数据的各种方法。
5.尽管cgan已经使用成对的rgb-d集合实现了令人印象深刻的深度合成结果,但是其不容易推广到针对其成对的示例不可用的新测试示例,尤其是当图像来自具有显著不同
estimating monocular depth using cycle gan and segmentation”,sensors,20(9):2567,2020)提出了一种基于cyclegan的解决方案,用于生成深度和图像分割图。为了估计深度信息,由于cyclegan的一致性损失,图像信息被变换成深度信息,同时保持rgb图像的特性。该参考文献还教导了添加分割的一致性损失,以在模糊或被rgb图像的较大特征隐藏的地方生成深度信息。
10.早期rgb-d面部识别方法是基于经典(非深度)方法提出的。goswami 等人(gaurav goswami、samarth bharadwaj、mayank vatsa和richa singh的“on rgb-d face recognition using kinect”,international conference on biometrics: theory, applications and systems,第1
–
6页,ieee,2013)教导了融合从rgb和深度数据提取的视觉显著性和熵图。该参考文献进一步教导了可以使用定向梯度直方图从图像碎片提取特征,以然后馈送给分类器用于身份识别。li 等人(billy yl li、ajmal s mian、wanquan liu和aneesh krishna的“face recognition based on kinect. pattern analysis and applications”,19(4):977
–
987,2016)教导了使用3d点云数据来获得使用鉴别颜色空间变换的姿态校正的正面视图。该参考文献进一步教导了校正的纹理和深度图可以使用在训练阶段获得的单独字典进行稀疏近似。
11.最近的努力聚焦在用于rgb-d面部识别的深度神经网络。chowdhury 等人(anurag chowdhury、soumyadeep ghosh、richa singh和mayank vatsa的“rgb-d face recognition via learning-based reconstruction”,international conference on biometrics theory,applications and systems,第1
–
7页,2016)教导了使用自动编码器(ae)来学习rgb数据和深度数据之间的映射函数。然后,映射函数可以用于从用于标识的对应rgb重建深度图像。zhang 等人(hao zhang、hu han、jiyun cui、shiguang shan和xilin chen的“rgb-d face recognition via deep complementary and common feature learning”,ieee international conference on automatic face & gesture recognition,第8
–
15页, 2018)使用深度学习解决了多模态识别问题,聚焦在cnn嵌入的联合学习,以有效地将rgb和深度数据提供的公共和互补信息融合在一起。
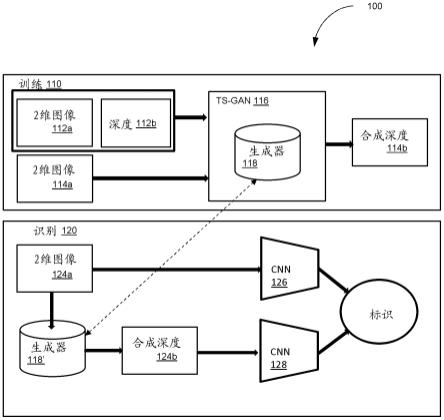
12.jiang 等人(luo jiang、juyong zhang和 bailin deng的“robust rgb-d face recognition using attribute-aware loss”,ieee transactions on pattern analysis and machine intelligence,42(10):2552
–
2566,2020) 提出了一种基于cnn的面部识别的属性感知损失函数,其旨在关于诸如性别、种族和年龄之类的软生物统计属性来调整学习表示的分布,从而提高识别结果。lin 等人(tzu-ying lin、ching-te chiu和ching-tung tang的“rgbd based multi-modal deep learning for face identification”,ieee international conference on acoustics,speech and signal processing,第1668
–
1672页,2020)通过引入新的损失函数(包括关联损失和鉴别性损失)教导了一种rgb-d面部标识方法,所述损失函数然后与softmax损失组合用于训练。
13.uppal 等人(hardik uppal、alireza sepas-moghaddam、michael greenspan和ali etemad的“depth as attention for face representation learning”,international conference of pattern recognition,2020) 教导了一种融合rgb和深度模态的两级注意力模块。第一注意力层选择性地聚焦在由卷积特征提取器获得的融合特征图,该融合特征图是通过lstm层循环学习的。然后,第二注意力层通过使用卷积层应用注意
力权重来聚焦在那些图的空间特征。uppal等人还教导了深度图像的特征可以用于聚焦在rgb图像中包含更突出的个人特定信息的面部区域。
技术实现要素:
14.所公开的实现包括一种深度生成方法,其使用新颖的师生gan架构(ts-gan)来生成2维图像的深度图像,并且由此增强2维数据,其中没有对应的深度信息可用。一个示例模型由两个组件——一个教师和一个学生——组成。该教师由作为生成器的全卷积编码器-解码器网络连同作为鉴别器的全卷积分类网络组成。gan的生成器部分通过并入来自鉴别器的反馈来学习创建数据。它学习使鉴别器将其输出分类为真实的。gan中的鉴别器仅仅是分类器。它将真实数据与生成器创建的数据区分开来。鉴别器可以使用适合于其正在分类的数据类型的任何网络架构。在所公开的实现中,生成器将rgb图像取作输入,并旨在输出对应的深度图像。本质上,教师旨在学习rgb和配准的深度图像之间的初始潜在映射。
15.学生本身由以编码器-解码器形式的两个生成器连同全卷积鉴别器组成,所述生成器中的一个与教师“共享”。如本文中用于描述生成器之间关系的术语“共享”意味着生成器使用相同的权重操作。生成器可以是单个实例,或者可以是生成器的不同实例。另外,生成器可以在相同的物理计算设备上或在不同的计算设备中实现。学生将对应的深度图像不可用的rgb图像作为其输入,并如由教师指导将其映射到深度域上,以生成合成的深度数据(在本文中也称为“幻觉”深度数据)。学生可操作来进一步细化教师所学习的严格映射,并允许通过较少约束的训练方案进行更好的泛化。
16.所公开的实现的一个方面是一种由神经网络实现的方法,用于确定为从2维图像数据生成合成深度图像数据而优化的映射函数加权,该方法包括:接收训练数据,该训练数据包括多个2维图像数据集和对应的配准深度图像数据;用训练数据训练第一生成器,以开发映射函数加权集,用于在2维图像数据集和对应的配准深度图像数据之间进行映射;由第二生成器将映射函数加权应用于第一2维图像数据集,以由此生成对应于该2维图像数据集的合成深度数据;由逆生成器处理合成深度数据,以将深度数据变换成第二2维图像数据集;将第一2维图像数据集与第二2维图像数据集进行比较,并基于该比较生成误差信号;基于误差信号调整映射函数加权集;以及重复应用、处理比较和调整步骤,直到满足指定的结束准则为止。
17.所公开的实现的另一方面是实现神经网络的计算系统,用于确定为从2维图像数据生成合成深度图像数据而优化的映射函数加权,该系统包括:至少一个硬件计算机处理器,可操作来执行计算机可读指令;以及其上存储计算机可执行指令的至少一个非瞬态存储器设备,当由所述至少一个硬件计算机处理器执行时,该指令使所述至少一个硬件计算机处理器执行以下方法:接收训练数据,该训练数据包括多个2维图像数据集和对应的配准深度图像数据;利用训练数据训练第一生成器,以开发映射函数加权集,用于在2维图像数据集和对应的配准深度图像数据之间进行映射;由第二生成器将映射函数加权应用于第一2维图像数据集,以由此生成对应于该2维图像数据集的合成深度数据;由逆生成器处理合成深度数据,以将深度数据变换成第二2维图像数据集;将第一2维图像数据集与第二2维图像数据集进行比较,并基于该比较生成误差信号;基于误差信号调整映射函数加权集;以及重复应用、处理比较和调整步骤,直到满足指定的结束准则为止。
18.所公开的实现的另一方面是其上存储有计算机可读指令的非瞬态计算机可读介质,当由计算机处理器执行时,该计算机可读指令使计算机处理器执行一种由神经网络实现的方法,用于确定为从2维图像数据生成合成深度图像数据而优化的映射函数加权,该方法包括:接收训练数据,该训练数据包括多个2维图像数据集和对应的配准深度图像数据;利用训练数据训练第一生成器,以开发映射函数加权集,用于在2维图像数据集和对应的配准深度图像数据之间进行映射;由第二生成器将映射函数加权应用于第一2维图像数据集,以由此生成对应于该2维图像数据集的合成深度数据;由逆生成器处理合成深度数据,以将深度数据变换成第二2维图像数据集;将第一2维图像数据集与第二2维图像数据集进行比较,并基于该比较生成误差信号;基于误差信号调整映射函数加权集;以及重复应用、处理比较和调整步骤,直到满足指定的结束准则为止。
19.本技术的这些和其他特征和特性,以及相关结构元件的操作方法和功能、以及零件的组合和制造的经济性,将在参考附图考虑以下描述和所附权利要求后变得更加显而易见,所有这些形成了本说明书的一部分,其中类似的附图标记指定各种图中的对应部分。然而,应该明确地理解,附图仅是出于说明和描述的目的,而不是作为对本发明的限制的定义。如在说明书和权利要求中所使用的,单数形式的“一”、“一个”和“该”包括复数指示物,除非上下文另有清楚规定。
附图说明
20.图1是根据一个或多个实现的系统和方法的两种模式的示意图;图2是根据一个或多个实现的学生教师网络的示意图;图3是根据一个或多个实现的用于确定映射加权的方法的流程图;图4图示了替代方法和公开的实现生成的深度;图5图示了从resnet-50网络生成的嵌入的t-sne可视化,用于由公开的实现生成的rgb图像、基准真值深度图像和合成深度图像;图6图示了由所公开的实现基于各种测试数据集生成的合成深度。
具体实施方式
21.所公开的实现包括一种新型师生对抗架构,其从单个2维图像(诸如2维(例如rgb)图像)生成逼真的深度图像。使用学生架构来细化教师所学习的2维和深度(d)域之间的严格潜在映射,以获得更可泛化和更少约束的关系。合成深度可以用于增强用于rgb-d图像识别(诸如面部识别)的2维数据。
22.图1图示了公开实现的总体框架100。在训练阶段110,利用包括一个或多个2维图像数据集112a和对应的深度数据112b的训练数据来训练ts-gan 116,以确定生成器118响应于以已知方式接收到2维图像数据114a而用于生成合成深度数据114b的加权。在识别阶段120,2维图像数据124a由生成器118’处理以创建合成深度数据124b。卷积神经网络(cnn)126处理2维数据126,并且cnn 128处理合成深度数据124b。cnn 126和cn 128的输出被融合并应用于标识。重要的是,生成器118和118’在教师组件和学生组件之间“共享”,如下面所描述的。
23.如上所述,所公开的实现解决了在没有对应深度信息的情况下rgb图像
的深度生成问题,其中我们被提供有rgb-d数据,我们称之为教师数据集,其中a
t
为rgb图像,以及b
t
为对应的配准深度图像。教师数据集用于学习映射生成器函数g
a2b
,该函数g
a2b
可以准确地生成目标rgb图像ar的深度图像。
24.如上所述,根据公开的实现,ts-gan的架构由教师组件和学生组件(本文中也仅称为“教师”和“学生”)组成。教师学习a
t
和b
t
之间的潜在映射。然后,学生利用另一个生成器-鉴别器对通过进一步训练生成器来细化所学习的ar映射。
25.图2示意性图示了根据公开的实现的ts-gan系统配置。ts-gan系统200可以由执行“程序模块”的一个或多个计算设备来实现,所述“程序模块”即当由计算机处理器执行时施行指定功能的可执行代码。系统200包括教师210和学生220。对于教师,我们为生成器218连同鉴别器212(d
depth
)创建映射函数。然后,映射函数的损失被公式化为:(1)其中: 是从采样的2维图像,其是教师数据集中2维图像的分布。
26.深度鉴别器212的损失可以表达为:其中:表示从采样的深度图像,其是教师数据集中深度图像的分布。
27.合成深度和基准真值深度之间的附加欧几里德损失可以表达为:学生组件旨在将单个2维图像ar从其中无深度信息可用的2维数据集转换为目标深度图像br。这是使用生成器218’的映射函数g
a2b
(等式1)连同生成器217的逆映射函数以及鉴别器219(d
rgb
)来完成的。映射函数的损失和鉴别器的损失然后表述为:其中:表示从采样的2维图像,其是2维目标数据集的分布。
28.区分基准真值2维图像和所生成的2维图像的鉴别器219的损失为:
。
29.逆生成器217 g
b2a
将映射从合成深度逆回到2维数据。这样做是为了保留对象的身份(在图像是人的图像的示例中,诸如面部图像),并以循环一致的方式提供附加的监督。因此,循环一致性损失可以表达为:教师210的总损失可以概括为:其中是上面等式3中描述的像素损失的加权参数。
30.学生220的总损失可以概括为:其中是上面等式6中描述的循环损失的加权参数。
31.系统200的示例操作算法的伪代码在下面阐述。
32.如算法1所示,从p
train
(a
t
)对2维图像a
t
进行采样,作为生成器218的输入。生成器218的输出是对应的深度图像,该深度图像被馈送到鉴别器212以被分类为例如真实的或虚假的。使用等式2中描述的损失,鉴别器212也利用b
t
以及生成的深度图像b
t
来训练。除了对抗损失之外,训练还借助于以欧几里德损失形式的像素损失(等式3)来促进,为此定义了加
权参数λ
pixel
。在训练教师210之后,从目标2维数据p
target
(ar)采样2维图像ar,该2维图像ar被馈送到在学生和教师之间“共享”的生成器218’。换句话说,生成器218和218’在功能上是等同的,例如,通过共享加权或者通过作为生成器的相同实例。生成器218’生成的深度图像被馈送到教师网络流中的鉴别器212,从而提供信号来生成逼真的深度图像。合成深度图像还被馈送到逆生成器217,以使用等式6表达的损失将深度变换回2维。如上所述,这保留了深度图像中的身份信息,同时允许通过原始潜在的2维到3d映射的细化来学习2维和深度之间的更泛化的映射。也可以遵循全卷积结构的鉴别器219被采用以为逆生成器提供附加信号,从而创建逼真的2维图像。
33.图3是根据公开的实现的方法300的流程图。在302处,接收训练数据。训练数据包括多个2维图像数据集和对应的配准的深度图像数据。在304处,利用训练数据训练教师组件,以开发映射函数加权集,用于在2维图像数据集和对应的配准的深度图像数据集之间进行映射,并且可以应用于学生生成器。在步骤306处,由学生生成器将映射函数加权应用于第一2维图像数据集,以由此生成对应于该2维图像数据集的合成深度数据。在308处,由学生逆生成器处理合成深度数据,以将深度数据变换成第二2维图像数据集。在310处,将第一2维图像数据集与第二2维图像数据集进行比较,并且基于该比较生成误差信号。在312处,可以调整基于误差信号的映射函数加权集,并且可选地,可以重复步骤306-312,直到由误差信号表示的误差小于预确定量或者满足任何其他结束条件为止。例如,结束条件可以是预确定次数的迭代或诸如此类。
34.下面公开了特定实现细节的示例。全卷积结构可以用于启发生成器,其中大小为128
ꢀ×ꢀ
128
ꢀ×ꢀ
3的输入图像用于输出具有相同尺寸的深度图像,如下面的表1中所概括的。
35.表1:
。
36.生成器的编码器部分包含具有relu激活的三个卷积层,其中特征图的数量逐渐增加(64,128,256),其中第一层的核大小为7
ꢀ×ꢀ
7,并且步幅为1。后续层使用3
ꢀ×ꢀ
3的核大小和2的步幅。继之以6个残差块,由2个卷积层组成,每个卷积层的核大小为3
ꢀ×ꢀ
3,并且步幅为2,以及256个特征图,如表1中所描述的。生成器的最终解码器部分遵循类似的结构,除了使用去卷积层进行上采样而不是卷积,具有递减的特征图(128,64,3)。用于将特征映射回图像的最后一个去卷积层使用7
ꢀ×ꢀ
7的核大小和1的步幅,与编码器的第一层相同,但具有tanh激活。
37.全卷积架构可以用于鉴别器,其中输入大小为128
×
128
×
3。该网络使用4个卷积层,其中过滤器的数量逐渐增加(64、128、256、256),其中固定核为4
ꢀ×ꢀ
4,并且步幅为2。所有卷积层都使用实例归一化和斜率为0.2的泄漏relu激活。最后的卷积层使用相同的参数,除了仅使用1个特征图。
38.为了稳定模型,可以使用来自例如50个生成的图像而不是由生成器立即产生的图像的缓冲池的图像更新鉴别器。该网络可以使用tensorflow 2.2在英伟达gtx 2080ti gpu上从头开始训练。可以使用adam optimizer和1的批大小。此外,0.0002和0.000002的两个不同的学习率可以分别用于教师和学生组件。教师的学习可以在第25轮(epoch)开始衰减,其中衰减率为0.5,比学生更快,其中学习率衰减可以在第50轮之后开始。权重λ
cyc
和λ
pixel
可以根据经验分别确定为5和10。
39.另外,存在可以用于训练的若干众所周知的数据集。例如,可以使用curtinfaces、iiit-d rgb-d、eurecom kinectfacedb或野外标记脸部(lfw)数据集。在研究示例的训练阶段,整个curtinfaces数据集用于训练教师,以便学习rgb和深度之间的严格潜在映射。该数据集的rgb和基准真值深度图像分别用作a
t
和b
t
。
40.为了训练学生,我们使用来自iiit-d rgb-d和eurecom kinectfacedb的rgb图像的训练子集。iiit-d tgb-d有一个用五重交叉验证策略的预定义协议,所述策略被严格遵守。对于eurecom kinectfacedb,数据在训练集和测试集之间按50-50的拆分进行划分,从而得到每个集合中总共468个图像。在野外lfw rgb数据集的情况下,使用整个数据集,从62个对象中的每一个留出20个图像用于识别实验,总计11,953个图像。
41.针对测试阶段,使用经训练的生成器为测试集中可用的每个rgb图像生成幻觉深度图像。然后使用rgb和深度图像以用于训练各种识别网络。针对rgb-d数据集,我们使用rgb和幻觉深度图像在训练集上训练识别网络,并在测试集上评估性能。关于lfw数据集,在测试阶段,我们使用了来自62个身份中的每一个的剩余20个图像,这些图像不用于训练。然后,我们使用输出的rgb和幻觉深度图像作为识别实验的输入。
42.首先,使用逐像素的质量评估指标,针对其他生成器验证深度图像生成的质量。这些指标包括逐像素绝对差、l1范数、l2范数和均方根误差(rmse),目的是通过将它们与原始配准的基础深度进行比较来评估幻觉深度的质量。此外,测量在某个误差阈值下的像素的百分比的阈值指标等式(δ)(等式9)被应用来提供相似性得分。该指标的等式表达如下:其中yi和yi*分别表示基准真值深度和幻觉深度中的像素值,并且val标示设置为1.25的阈值误差值。
43.该研究的目的是使用幻觉模态来提高识别性能。因为我们想要呈现不依赖于特定识别架构的结果,所以我们在评估中使用了标准深度网络——特别是vgg-16、inception-v2、resnet-50和se-resnet-50——的多种多样的集合。报告了具有和不具有rgb-d数据集的基准真值深度的排名1的标识结果,以及通过rgb和幻觉深度图像的组合获得的结果。对于lfw rgb数据集,我们自然没有基准真值深度,因此仅呈现了具有和没有幻觉深度的标识结果。此外,当组合rgb和深度图像时,使用了不同的策略,包括特征级融合、得分级融合、两级注意力融合和深度引导注意力。
44.为了进行质量评估,将ts-gan的性能与替代深度生成器——即全卷积网络(fcn)、图像到图像转换cgan和cyclegan——进行比较。在curtinfaces数据集上施行实验,其中52个对象中的47个用于训练生成器,并且剩余5个对象用于生成用于质量评估实验的深度图像。图4示出了由替代方法以及ts-gan实现生成的深度。可以看出,本文中公开的方法能够
生成非常类似于基准真值深度图像的逼真深度图像。
45.图5示出了通过所公开的方法从resnet-50网络为rgb图像、基准真值深度图像和幻觉深度图像生成的嵌入的t-sne可视化。这种可视化证明了基准真值和生成的深度图像之间非常高的重叠,从而描绘了它们的相似性。
46.表2示出了逐像素目标指标的结果。
47.表2:。
48.对于包括绝对差、l1范数、l2范数和rmse的前四个指标,较低的值指示较好的图像质量。可以观察到,本文中公开的方法始终优于其他方法。仅例外是绝对差指标,其中fcn示出略微更好的性能。这种观察的潜在原因是,fcn仅使用一个损失函数,其目的是最小化基准真值和生成的深度之间的绝对误差,自然得到最小的绝对差误差。对于阈值指标δ,阈值误差值1.25以下的像素百分比越高,表示图像的空间准确度越好。就这些指标而言,本文中公开的方法实现了比其他生成器好得多的准确度。
49.为了示出该生成器在应用于其他数据集进行测试时的泛化性,图6中示出了所得到的iiit-d和eurecom rgb-d数据集的幻觉深度样本(顶行和中间行)。在图6中,对于四个样本中的每一个,第一和第二列示出了输入rgb图像和生成的深度图像,而第三列示出了对应于rgb图像的基准真值深度图像。可以看出,所公开的方法可以适应目标数据集中存在的不同姿态、表情和遮挡。该图中的底行示出了为野外lfw rgb数据集生成的深度,其中所公开的方法能够适应在受约束的实验室获取的rgb-d数据集中不存在的非正面和不自然的姿态。
50.如上所述,排名1面部标识结果用于证明幻觉深度对面部识别的有效性。在这种背景下,映射函数(等式1)用于从rgb图像提取对应的深度图像,以用作识别流水线的输入。下面的表3示出了使用之前讨论的四个网络在iiit-d和kinectfacedb数据集上的识别结果。
51.可以观察到,当与单独使用rgb图像相比时,使用所公开的ts-gan的rgb和深度幻觉的融合跨所有cnn架构始终提供更好的结果。作为参考,还施行了利用rgb和基准真值深度的识别。
52.对于iiit-d数据集,利用rgb和生成的深度的识别得到的结果与利用rgb和基准真值深度图像的结果相当。关于eurecom kinectfacedb数据集,结果还示出,由于实现了与rgb和基准真值深度的结果相当的结果(略微低),由所公开的方法生成的深度为识别流水线提供了附加值。有趣的是,在iiit-d和kinectfacedb二者的某些情况下,幻觉深度提供了优于基准真值深度的性能。这最可能是由于以下事实:在iiit-d和kinectfacedb数据集中可用的一些深度图像是有噪声的,而所公开的生成器可以提供更干净的合成深度图像,因为它已经在curtinfaces数据集中可用的更高质量的深度图像上进行了训练。
53.下面的表4呈现了在野外lfw数据集上的识别结果,其中呈现了具有和没有我们的幻觉深度图像的结果。可以观察到,由所公开的示例生成的幻觉深度显著提高了跨所有cnn架构的识别准确度,对于vgg-16、inception-v2、resnet-50和se-resnet-50分别提高了3.4%、2.4%、2.3%、2.4%。当考虑到最先进的基于注意力的方法时,提高更加明显,这清楚地指示我们的合成深度图像对提高识别准确度的益处。
54.表4:。
55.为了评估所公开的解决方案的每个主要组件的影响,通过系统地移除组件来施行消融研究。首先,我们移除学生组件,从而得到教师。接下来,我们从教师移除鉴别器,从而仅留下如上面所描述的a2b生成器。结果在表5中呈现,并与我们完整的tsgan解决方案进行比较。所呈现的识别结果是使用特征级融合方案来组合rgb和幻觉深度图像而获得的。结果示出,对于所有四种cnn架构,移除每个组件都使性能遭受影响,这证明了所公开的方法的有效性。
56.表5:
。
57.所公开的实现教导了一种新型师生对抗架构,用于从诸如rgb图像之类的2维图像进行深度生成。所公开的实现提高了诸如面部识别系统之类的对象识别系统的性能。由生成器和鉴别器组成的教师组件遵循有监督方法学习2维数据和深度图像对之间的严格潜在映射。学生本身由生成器-鉴别器对连同与教师共享的生成器组成,然后通过学习没有对应配准深度图像的样本的2维和深度域之间的更泛化的关系来细化这种映射。在三个公共脸部数据集上的综合实验示出,所公开的方法和系统就深度质量和面部识别性能二者而言都优于其他深度生成方法。
58.可以通过用软件和/或固件编程的各种计算设备实现所公开的实现,以提供由硬件实现的可执行代码的所公开的功能和模块。软件和/或固件可以作为可执行代码存储在一个或多个非瞬态计算机可读介质上。计算设备可以经由一个或多个电子通信链路可操作地链接。例如,这样的电子通信链路可以至少部分地经由诸如互联网和/或其他网络之类的网络来建立。
59.给定计算设备可以包括被配置为执行计算机程序模块的一个或多个处理器。计算机程序模块可以被配置为使得与给定计算平台相关联的专家或用户能够与系统和/或外部资源对接。作为非限制性示例,给定计算平台可以包括服务器、台式计算机、膝上型计算机、手持式计算机、平板计算平台、智能电话、游戏控制台和/或其他计算平台中的一个或多个。
60.各种数据和代码可以存储在电子存储设备中,所述电子存储设备可以包括以电子方式存储信息的非暂时性存储介质。电子存储装置的电子存储介质可以包括与计算设备集成(即,大体上不可移除)提供的系统存储装置和/或可移除存储装置中的一个或两个,所述可移除存储装置经由例如端口(例如,usb端口、火线端口等)或驱动器(例如,磁盘驱动器等)可移除地可连接到计算设备。电子存储装置可以包括光学可读存储介质(例如,光盘等)、磁性可读存储介质(例如,磁带、磁性硬盘驱动器、软盘驱动器等)、基于电荷的存储介质(例如,eeprom、ram等)、固态存储介质(例如,闪存驱动器等),和/或其他电子可读存储介质中的一个或多个。
61.计算设备的(一个或多个)处理器可以被配置为提供信息处理能力,并且可以包括数字处理器、模拟处理器、设计用于处理信息的数字电路、设计用于处理信息的模拟电路、状态机和/或用于电子处理信息的其他机制中的一个或多个。如本文中所使用的,术语“模
块”可以指代施行归属于该模块的功能的任何组件或组件集。这可以包括执行处理器可读指令期间的一个或多个物理处理器、处理器可读指令、电路、硬件、存储介质或任何其他组件。
62.尽管基于目前认为最实用和优选的实现出于说明的目的已经对本技术进行了详细描述,但是应当理解,这样的细节仅用于该目的,并且该技术不限于所公开的实现,而相反,意图覆盖所附权利要求精神和范围内的修改和等同布置。例如,应当理解,本技术设想在尽可能的程度上,任何实现的一个或多个特征可以与任何其他实现的一个或多个特征相组合。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1