基于关联注意力的少样本文字风格迁移方法
1.本发明属于文字生成方法技术领域,涉及一种基于关联注意力的少样本文字风格迁移方法。
背景技术:
2.在视觉设计中,字体的样式十分重要,不同的字体为视觉设计带来的氛围感完全不同。然而,设计一种新的字体是一项费时费力的工作,不仅需要考虑诸多因素,如笔画、纹理、颜色等,而且,所有字符都需要保持一致的风格和适当的大小。创作字库从画稿到上线,是设计师团队通力合作、一笔一画调整修改而来,一套适合推广、商用的字体需要2-3年,其中绝大部分的时间用在从基本字形向上千字形的扩充、拼组、调试上,且这部分工作由较高素质的字体设计师完成,是一项重复性、严谨的工作,另外字体设计师花费极大的精力用在遵循设定好的框架、规则中去完成工作,没有创作的空间。通常字体设计师为拉丁字母设计一种字体通常几周或者几个月的时间,对于某些语言(如汉语和朝鲜语),他们包含大量字符(汉语最多50000个字,朝鲜语最多11172个字符),所以如何更高效的设计一套风格化字体成为一个急需解决的任务。
3.随着深度学习(deep learning)的兴起,无需人工干预的字体自动生成成为可能。字体自动生成可视为字体的风格迁移,旨在通过学习不同字体域之间的映射,保证字体语义内容不变的同时对字体的字形作相应的转换。这极大的缩短了字库的制作时间,降低了制作成本,极大满足文化教育、娱乐传媒和商业等领域的用字需求。尽管基于深度学习的文字风格迁移有了一定的发展,但这些方法在许多实际场景中的应用是不切实际的,如生成手写字库时,收集这类训练样本困难且耗时巨大。而少样本文字风格迁移利用少量的风格参考集生成一套完整的字库,更能符合实际应用要求,具有更高的应用价值,另一方面,大多数多样本任务无法生成训练时未见过的风格字体,当需要对训练时未见过的字体进行风格迁移,重新训练模型是极其费时的。
4.在少样本文字风格迁移问题中,我们希望通过使用少量风格参考集去生成新的字形,并且不需要额外的微调,例如在测试时仅通过六个风格参考图像生成一套完整风格化字库。为了在少量风格参考集中充分学习到风格特征,当前的主流方法是特征分离引导文字风格迁移,分别使用内容编码器和风格编码器学习内容和风格特征。为了提高字符的生成质量,一些方法为生成模型添加先验信息,将复杂的字形拆解成部件或笔画,还有一些方法通过使用注意力机制关注风格特征的上下文注意力加强特征的提取。但是这些方法未考虑内容编码器提取的内容特征和风格编码器提取的风格特征之间的关联性,这会导致多域字体之间的风格迁移结果较差。
技术实现要素:
5.本发明的目的是提供一种基于关联注意力的少样本文字风格迁移方法,解决了现有技术中存在的现有字体风格迁移方法的风格特征学习不充分导致风格迁移结果较差的
问题。
6.本发明所采用的技术方案是,基于关联注意力的少样本文字风格迁移方法,包括以下步骤:
7.步骤1、构建训练数据集和测试数据集;训练数据集包括内容参考集、风格参考集;
8.步骤2、构建基于关联注意力的生成对抗网络,生成对抗网络包括生成器网路、鉴别器网络;
9.步骤3、设置损失函数;
10.步骤4、利用步骤3构建的损失函数训练生成对抗网络;
11.步骤5、利用测试数据集测试训练完的生成器网络,完成少样本文字风格迁移。
12.本发明的特点还在于:
13.步骤2具体包括以下步骤:
14.步骤2.1、构建生成器模块,生成器网络包括内容特征提取模块、风格特征提取模块及解码模块;
15.步骤2.2、构建鉴别器网络,鉴别器包括内容鉴别器和风格鉴别器。
16.内容特征提取模块用于将输入的源字体图像c压缩为内容特征向量fc:
17.fc=ec(c)
ꢀꢀ
(1)。
18.风格特征提取模块包括5个卷积块、关联注意力模块,关联注意力模块包括上下文感知注意力模块和相似性特征注意力模块;风格特征提取模块的操作具体为:
19.a.先将风格参考集按照通道维度拼接后经过第一、二、三层卷积层得到特征图v1,再经过第四层卷积层、第五层卷积层分别得到特征图v2、v3;
20.b.将特征图v1、v2、v3分别输入到上下文感知注意力模块得到具有上下文信息、局部以及全局信息的风格变量f
s1
;
21.c.将特征图v1、内容特征向量fc输入到相似性特征注意力模块,输出整合所有局部风格信息的风格特征f
s2
;
22.d.最后,f
s1
和f
s2
相加融合得到最终的风格特征fs:
23.fs=f
s1
+f
s2
ꢀꢀ
(11)。
24.上下文感知注意力模块的操作具体为:
25.b1.首先通过自注意力层整合特征图{vr}
r=1∶3
上下文信息,得到特征向量hr:
26.hr=fa(vr)
ꢀꢀ
(2);
27.上式中,fa表示自注意力层;
28.b2.然后使用注意力机制给每个特征向量hr的区域打分,得到注意力分数ar;
29.b3.接着将注意力分数匹配到对应特征图vr上,得到三个具有上下文信息的特征向量{fr}
r=1∶3
:
30.fr=v
rar
ꢀꢀ
(5);
31.b4.最后通过层级注意力网络为特征向量{fr}
r=1∶3
打分,得到隐变量z,进而得到风格特征f
s1
。
32.使用注意力机制给每个特征向量hr的区域打分,得到注意力分数ar具体包括:
33.先将特征向量hr输入到单层神经网络中得到ur:
34.ur=tanh(wchr+bc)
ꢀꢀ
(3);
35.上式中,wc、bc表示可学习参数,tanh表示激活函数tanh;
36.再通过softmax层得到标准化的注意力分数ar:
[0037][0038]
上式中,uc是随机初始化向量,表示向量ur的转置。
[0039]
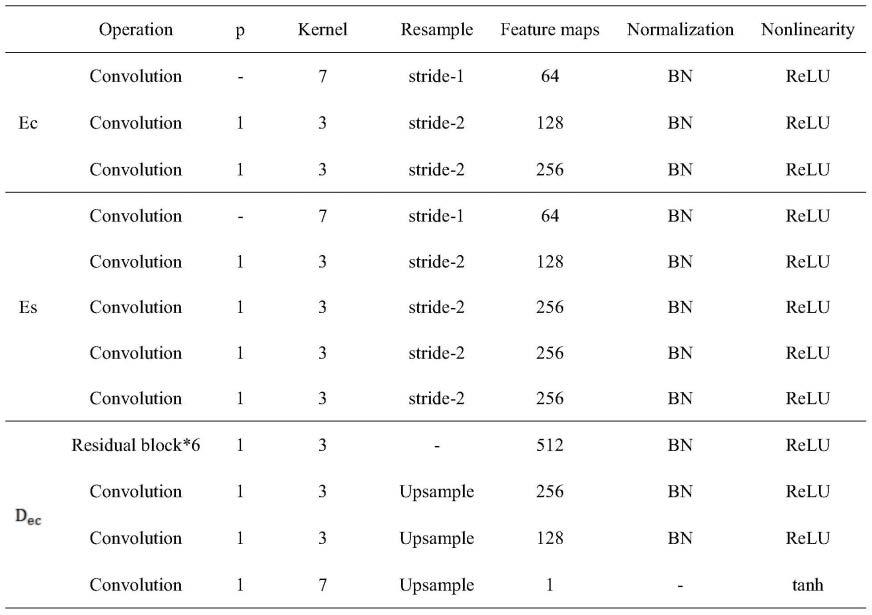
通过层级注意力网络为特征向量{fr}
r=1∶3
打分,得到隐变量z,进而得到风格特征f
s1
具体包括:
[0040]
首先为不同的特征向量匹配不同的权重:
[0041]
w1,w2,w3=f
l
(ym)
ꢀꢀ
(6);
[0042]
上式中,ym为将特征向量v3进行展平后的特征向量,将ym输入到f
l
(
·
)中,f
l
层是一个全连接层和softmax层,再对输出按照通道进行划分,得到权重w1、w2、w3;
[0043]
其次,使用权重w1、w2、w3为不同特征向量加权,得到隐变量z:
[0044][0045]
通过隐变量z得到风格特征f
s1
:
[0046][0047]
相似性特征注意力模块的操作具体为:
[0048]
c1.首先计算fc和v1注意力权重
[0049][0050]
上式中,表示v1在通道下的均值方差标准化,同理。f(
·
)和g(
·
)分别表示通道数为256的1*1卷积单元,表示对进行转置,softmax(
·
)是一个softmax层;
[0051]
c2.再将注意力图匹配到特征图v1上,得到最终的风格特征f
s2
:
[0052][0053]
上式中,h(
·
)表示通道数为256的1*1卷积单元。
[0054]
解码模块的操作过程为:
[0055]
将内容特征fc与风格特征fs在通道维度上拼接后输入解码模块d
ec
生成具有源图像语义信息和风格图像风格信息的目标字体图像x:
[0056]
x=d
ec
(fc⊙fs
)
ꢀꢀ
(12)。
[0057]
鉴别器网络的具体操作为:将目标字体图像x和内容图像c在通道维度上拼接,输入到内容鉴别器中,判别拼接的图像是否与真值具有相同的内容;将生成的图像x和风格图像s在通道维度上拼接,输入到风格鉴别器中,判别拼接的图像是否与真值具有相同风格。
[0058]
本发明的有益效果是:本发明的基于关联注意力的少样本文字风格迁移方法,使用关联注意力机制多角度融合不同风格特征,一方面关注特征上下文之间的联系,使模型学习到局部和全局风格特征,另一方面考虑内容编码器提取的内容特征和风格编码器提取的风格特征之间的关联性,更关注和内容图像相似的风格图像像素点;在多对多字体的风
格迁移上表现良好,模型充分提取了风格信息和内容信息,生成的字符笔画更加完整,与真实值更加相近,在多域文字风格迁移中生成更高质量、更和谐的字符图像。
附图说明
[0059]
图1是本发明基于关联注意力的少样本文字风格迁移方法中生成对抗网络的结构图;
[0060]
图2是本发明基于关联注意力的少样本文字风格迁移方法中上下文感知注意力模块的结构图;
[0061]
图3是本发明基于关联注意力的少样本文字风格迁移方法中相似性特征注意力模块;
[0062]
图4是本发明基于关联注意力的少样本文字风格迁移方法在可见文字内容但未见文字风格数据集上测试结果;
[0063]
图5是本发明基于关联注意力的少样本文字风格迁移方法在可见文字风格但未见文字内容数据集上测试结果。
具体实施方式
[0064]
下面结合附图和具体实施方式对本发明进行详细说明。
[0065]
基于关联注意力的少样本文字风格迁移方法,包括以下步骤:
[0066]
步骤1、构建训练数据集和测试数据集;训练数据集包括内容参考集、风格参考集;
[0067]
步骤1.1、下载不同类型的truetype字体文件,将每种字体文件生成若干张常用中文字符图像,得到训练集,并将其分为内容参考集、风格参考集;
[0068]
本实施例中,下载780个不同类型的truetype字体文件,网站地址:https://chinesefontdesign.com。每种字体文件使用程序生成981张常用中文字符图像,其中929张作为内容参考集,52张作为风格参考集。
[0069]
步骤1.2、测试数据集包括训练时可见文字内容但未见文字风格的字符图像、训练时可见文字风格但未见的文字内容的字符图像。
[0070]
a)具体的,可见文字内容但未见文字风格:下载11种训练集没有的truetype字体文件,网站地址同上,每种字体文件使用程序生成981张常用中文字符图像,其中929张作为内容参考集,52张作为风格参考集;测试时随机选取11种字体的任意一种字体作为内容字体,任意一种字体作为风格字体(风格字体和内容字体不同),之后在内容字体的929张内容参考集中随机采样一张内容图像,风格字体的52张风格参考集中采样6张风格图像,生成具有内容图像的内容和风格图像的风格的目标字体图像。
[0071]
b)可见文字风格但未见文字内容:在训练集的truetype字体文件中随机挑选15种字体,使用程序生成81张中文字符图像,其中29张是未见过的中文字符作为内容参考集,52张与训练时相同内容的中文字符图像作为风格参考集。测试时随机选取15种字体的任意一种字体作为内容字体,任意一种字体作为风格字体(风格字体和内容字体不同),之后在内容字体的29张内容参考集中随机采样一张内容图像,风格字体的52张风格参考集中采样6张风格图像,生成具有内容图像的内容和风格图像的风格的目标字体图像。
[0072]
步骤2、构建基于关联注意力的生成对抗网络,对抗网络结构如图1所示;生成对抗
网络包括生成器网络、鉴别器网络;
[0073]
步骤2.1、构建生成器网络,生成器网络包括内容特征提取模块,风格特征提取模块以及解码模块,生成器网络结构如表1所示;
[0074]
表1生成器网络结构
[0075][0076]
内容特征提取模块,表示为ec,包括依次设置的3个卷积块,每个卷积块包括卷积层、批量化归一层、relu激活层;第一个卷积块的卷积层卷积核大小k=7,扫描步长s=1,填充像素p=0,第二、三个卷积块的卷积层卷积核大小k=3,扫描步长s=2,填充像素p=1。内容特征提取模块用于将输入的源字体图像c压缩为内容特征向量fc:
[0077]
fc=ec(c)
ꢀꢀ
(1)。
[0078]
风格特征提取模块,表示为es,包括5个卷积块、关联注意力模块,关联注意力模块包括上下文感知注意力模块和相似性特征注意力模块;上下文感知注意力模块包括单层神经网络、softtmax层、层级注意力网络;每个卷积块包括都卷积层、批量化归一层、relu激活层,第一层卷积层卷积核大小k=7,扫描步长s=1,填充像素p=0,第二、三、四、五层卷积层卷积核大小k=3,扫描步长s=2,填充像素p=1。本实施例中,风格参考集s={s1,s2,s3,
…
,s6};风格特征提取模块的操作具体为:
[0079]
a.先将风格参考集按照通道维度拼接后经过第一、二、三层卷积层得到特征图v1,再经过第四层卷积层、第五层卷积层分别得到特征图v2、v3,v1、v2、v3的感受野分别为13
×
13、21
×
21、37
×
37;
[0080]
关联注意力模块有两个分支,一个是上下文感知注意力模块表示为att
context
,关注上下文之间的联系。一个是相似性特征注意力模块表示为att
sim
,关注风格特征和内容特征之间的联系。
[0081]
b.再将不同感受野大小的特征图v1、v2、v3分别输入到上下文感知注意力模块
att
context
得到具有上下文信息、局部以及全局信息的风格变量f
s1
。具体如下文,上下文感知注意力模块结构如图2所示。
[0082]
b1.首先通过自注意力层整合特征图{vr}
r=1∶3
上下文信息,得到特征向量hr:
[0083]hr
=fa(vr)
ꢀꢀ
(2);
[0084]
上式中,fa表示自注意力层,特征向量hr不仅包含其感受野的信息,还包含来自其他区域的上下文信息。
[0085]
b2.然后使用注意力机制给每个特征向量hr的区域打分,得到注意力分数ar;
[0086]
具体的,将特征向量hr输入到单层神经网络中得到ur:
[0087]
ur=tanh(wchr+bc)
ꢀꢀ
(3);
[0088]
上式中,wc、bc表示可学习参数,tanh表示激活函数tanh;
[0089]
通过softmax层得到标准化的注意力分数ar:
[0090][0091]
上式中,uc是随机初始化向量,是随机初始化向量,表示向量ur的转置;
[0092]
b3.接着将注意力分数匹配到对应特征图vr上,得到三个具有上下文信息的特征向量{fr}
r=1∶3
:
[0093]fr
=v
rar
ꢀꢀ
(5);
[0094]
b4.最后通过层级注意力网络为特征向量{fr}
r=1∶3
打分,得到隐变量z,进而得到风格特征f
s1
;
[0095]
具体的,首先为不同的特征向量匹配不同的权重:
[0096]
w1,w2,w3=f
l
(ym)
ꢀꢀ
(6);
[0097]
上式中,ym为将特征向量v3进行展平后的特征向量,将ym输入到f
l
(
·
)中,f
l
层是一个全连接层和softmax层,再对输出按照通道进行划分,得到权重w1、w2、w3;
[0098]
其次,使用权重w1、w2、w3为不同特征向量加权,得到隐变量z:
[0099][0100]
通过隐变量z得到风格特征f
s1
:(由于风格特征提取模块输入六张图像,故生成了6个隐变量z,最终的风格特征fs是所有隐变量的平均值):
[0101][0102]
c.将v1、fc输入到相似性特征注意力模块att
sim
,考虑风格特征和内容特征的内部关联,让网络自动关注与内容字符结构相似的风格像素点,最终输出一个整合了所有局部风格信息的风格特征f
s2
,具体步骤如下,相似性特征注意力模块att
sim
具体结构如图3所示;
[0103]
c1.首先计算fc和v1注意力权重
[0104][0105]
上式中,表示v1在通道下的均值方差标准化,司理。f(
·
)和g(
·
)分别表示通道数为256的1*1卷积单元,表示对进行转置,softmax(
·
)是一个softmax
层;
[0106]
c2.再将注意力图匹配到特征图v1上,得到最终的风格特征f
s2
:
[0107][0108]
上式中,h(
·
)表示通道数为256的1*1卷积单元;
[0109]
d.最后,f
s1
和f
s2
相加融合得到最终的风格特征fs:
[0110]fs
=f
s1
+f
s2
ꢀꢀ
(11)。
[0111]
解码模块表示为d
ec
,包括六个残差块、三个反卷积层;具体操作为:
[0112]
将内容特征fc与风格特征fs在通道维度上拼接后输入解码模块d
ec
生成具有源图像语义信息和风格图像风格信息的目标字体图像x:
[0113]
x=d
ec
(fc⊙fs
)
ꢀꢀ
(12)。
[0114]
步骤2.3、构建鉴别器网络,鉴别器包括内容鉴别器和风格鉴别器,如表2所示,leakyrelu的坡度设置为0.2;
[0115]
表2内容鉴别器和风格鉴别器网络结构。
[0116][0117][0118]
内容鉴别器和风格鉴别器均包括5个卷积块;鉴别器网络的具体操作为:将目标字体图像x和内容图像c在通道维度上拼接,输入到内容鉴别器中,判别拼接的图像是否与真值具有相同的内容;将生成的图像x和风格图像s在通道维度上拼接,输入到风格鉴别器中,判别拼接的图像是否与真值具有相同风格。
[0119]
步骤3、设置损失函数;
[0120]
损失函数l包括生成器g的损失lg损失、判别器d的损失ld;
[0121]
l=λsl
styled
+λcl
contentd
+λsl
styleg
+λcl
contentg
+λ1l1ꢀꢀ
(13);
[0122]
lg损失包括l1范数损失、风格生成损失l
styleg
、内容生成损失l
contentg
和分类损失l
cls
:
[0123]
lg=λsl
styleg
+λcl
contentg
+λ1l1ꢀꢀ
(14);
[0124]
l1为生成的图像x和真实图像之间的像素误差:
[0125][0126]
上式中,x范数损失表示生成的字体图像,表示真实的字体图像,||
·
||1表示l1范数;
[0127]
l
styleg
=-e
x,s~p(x,s)
[d
style
(x,s)]
ꢀꢀ
(16);
[0128]
l
contentg
=-e
x,c~p(x,c)
[d
content
(x,c)]
ꢀꢀ
(17);
[0129]
上式中,x表示生成的字体图像,c表示源字体图像,s表示风格字体图像,d
style
表示风格鉴别器,d
content
表示内容鉴别器;d
style
(x,s)表示将生成图像和风格图像按通道维度拼接后输入风格鉴别器得到的概率矩阵,d
content
(x,c),同理,e
x,s~p(x,s)
[d
style
(x,s)]表示对该输出的期望。
[0130]
ld包括风格鉴别损失l
styled
和内容鉴别损失l
contentd
;
[0131]
ld=λsl
styled
+λcl
contentd
ꢀꢀ
(18);
[0132]
上式中,λs、λc取值都为1,min||
·
||表示取最小值。
[0133][0134]
上式中,min||
·
||表示取最小值,表示真实字符图像,x表示生成的字符图像,s表示风格图像,表示将真值和风格图像按通道维度拼接后输入风格鉴别器后得到的概率矩阵,d
style
(x,s)同理;
[0135][0136]
其中,c表示是源图像,即内容图像,d
content
表示内容鉴别器。
[0137]
步骤4、利用步骤3构建的损失函数训练生成对抗网络;
[0138]
利用步骤3构建的损失函数进行网络训练,在更新生成器网络g时固定判别器d的参数,而更新判别器网络d时则固定生成器网络g的参数。设置训练迭代次数epoch=20,学习率lr=0.0002,使用adam优化器。
[0139]
步骤5、利用测试数据集测试训练完的生成器网络,完成少样本文字风格迁移。
[0140]
采用测试数据集对训练好的模型进行字体风格迁移测试,此时模型只有生成器g起作用,通过结构相似性(ssim)、多层级结构相似性(ms-ssim)、均方误差(mse)和平均绝对误差(mae)来评价模型的性能。
[0141]
通过以上方式,本发明的基于关联注意力的少样本文字风格迁移方法,使用关联注意力机制多角度融合不同风格特征,一方面关注特征上下文之间的联系,使模型学习到局部和全局风格特征,另一方面考虑内容编码器提取的内容特征和风格编码器提取的风格特征之间的关联性,更关注和内容图像相似的风格图像像素点;在多对多字体的风格迁移上表现良好,模型充分提取了风格信息和内容信息,生成的字符笔画更加完整,与真实值更加相近,在多域文字风格迁移中生成更高质量、更和谐的字符图像。
[0142]
实例
[0143]
测试数据集一种包括11种可见文字内容但未见文字风格的字符图像集,每类有929张中文字符作为内容参考集,52张中文字符作为风格参考集。另一种是可见文字风格但未见文字内容的字符图像集。在测试时,任意选取两种字体分别作为源字体和风格字体,进行定性和定量评估。以下对比方法有:ftransgan,fcongan(本发明的方法)。
[0144]
表3定量评估
[0145][0146][0147]
结构相似性(ssim)、多尺度结构相似性(ms-ssim),都是衡量两幅图像相似度的指标,值越大表明生成图像质量越高,与真实图像越相似。平均绝对误差(mae)和均方误差(mse)损失是指生成图像和真实图像之间对应的像素损失,值越低表示生成图像质量越高。从表3来看,本方法定量指标在可见文字内容但未见文字风格的图片上有明显的提升,在可见文字风格但未见的文字内容图片上有一定的提升。
[0148]
定性评估结果如图4和图5,从图中可以看出,本发明的方法生成的字符内容特征更充分,笔画更加完整、流畅,同时与真值更加相似。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1