一种面向Pareto多目标遗传算法对抗样本自动生成方法
一种面向pareto多目标遗传算法对抗样本自动生成方法
技术领域
1.本发明涉及一种面向pareto多目标遗传算法对抗样本自动生成方法,属于机器学习和网络安全技术领域。
背景技术:
2.近年来,随着互联网的不断发展,移动设备已经成为人生活工作中不可或缺的一部分,至此大数据资产越来越庞大,用户的数据以及个人隐私受到了来自恶意软件的威胁;根据网络安全报告显示,2021年新增安全漏洞以及恶意软件相比2020年呈现出不断上升的趋势,恶意软件增加的种类主要集中在勒索软件、蠕虫病毒以及新变种,它们主要攻击大型企业,造成了重大经济损失;这给我们国家的网络安全带来了严峻的挑战。
3.恶意软件的检测、分析以及防御是安全专业研究人员所关注的重点,对于每天新增的恶意软件变种,其形态多样化,分析情况复杂给安全人员带来了大量工作,传统的面向签名的检测手段已经不在适用。机器学习的发展给安全人员以及商业引擎带来了曙光;目前机器学习在恶意软件检测领域已经逐渐成熟,以及新出现的深度学习应用神经网络对恶意软件进行特征提取,其检测速度快,成功率可以接近100%。
4.不同的机器学习模型以及商业引擎针对恶意软件检测在特征方面侧重点不同;为了逃避分类器检测,攻击者对恶意软件进行细微的修改、加壳打包或者字符混淆生成对抗样本,对检测模型进行攻击,从中获得相关信息来生成新变种逃避检测。针对对抗性技术的研究,为了保证生成样本的真实可用性,大部分使用黑盒攻击场景,可以从生成的对抗样本中加以利用训练,提升模型的准确率以及鲁棒性。
5.目前对抗技术在图像领域取得较好结果,在图像上对像素进行修改添加细微扰动就可以达到欺骗效果,攻击成功率为90%以上;但对于二进制可执行文件来说,文件形式复杂,根据图像领域的方法生成图像,对像素进行修改添加扰动可能造成文件格式损坏、恶意功能消失以及不可执行,目前可以生成的对抗样本对于模型的攻击成功率远低于图像领域;因此如何针对上述问题自动生成与原始功能保持一致、相似度高(扰动规模小)且添加动作无冗余的恶意代码pe对抗样本来提高模型的攻击成功率是目前的研究方向。
技术实现要素:
6.本发明要解决的技术问题是提供一种面向pareto多目标遗传算法对抗样本自动生成的方法,保证样本在不需要人工干预的条件下自动生成原始恶意功能存在,减少动作冗余,保证添加修改动作个数少,与原始样本相似度高的对抗样本,其中动作策略库中一个动作section append中注入内容从良性可执行pe文件中提取,用来提高攻击成功的概率,符合生成对抗样本的真实可执行性。
7.为解决上述技术问题,本发明采用的技术方案是:
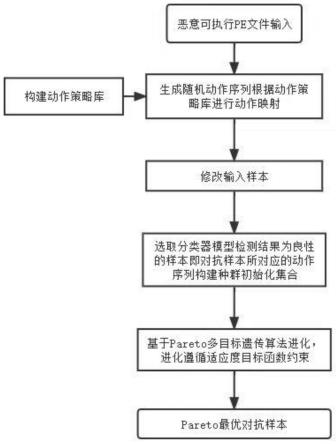
8.本发明一种面向pareto多目标遗传算法对抗样本自动生成的方法,采用以下步骤:
9.步骤一、构建动作策略库;
10.步骤二、设计适应度目标函数;
11.步骤三、选择分类器模型,分类器模型检测结果返回添加动作修改后的样本是恶意还是良性样本;
12.步骤四、以恶意可执行pe文件作为样本输入,生成随机动作序列根据动作策略库中进行动作映射,修改输入样本,修改后的样本经过步骤三选择的分类器模型检测,保留检测结果为良性的样本即对抗样本,对保留的对抗样本的所对应的动作序列构造种群初始化集合以便后续进化得到pareto最优对抗样本。
13.本发明步骤一中构建动作策略库中其中一个动作为section append,该动作对恶意可执行pe文件section中注入的内容从良性可执行pe样本中提取,使用第三方pefile库对良性可执行pe文件进行文件解析,获取包括偏移量pionterrawdata映射到section内容以及对应section名称。
14.本发明步骤二中所述适应度目标函数包括:
15.2.1).验证原始恶意功能是否存在以及对抗样本与原始输入样本之间的相似度,以确保在添加动作时注入或者删除的内容改动较小,其表达式如下:
16.f(m,m
′
)=s(m,m
′
)+fun(m
′
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
17.其中,m表示恶意可执行pe样本输入,m
′
表示对抗样本,s(m,m
′
)表示恶意可执行pe样本与对抗样本之间的相似度得分,fun(m
′
)表示验证对抗样本原始恶意功能的奖惩机制,验证方法采用本地搭建cuckoo沙箱,如果cuckoo沙箱执行对抗样本恶意功能存在则对该样本进行奖励,奖励为1,即:
[0018][0019]
2.2).减少修改动作个数,确保对恶意可执行pe样本修改最小化,防止添加动作冗余使文件改动过大引起检测异常,计算随机动作序列a=[a0,a1,
…
,aj]的非零元素个数,其表达式如下:
[0020][0021]
其中,ai=0或1,j表示步骤一中动作策略库中动作个数。
[0022]
本发明步骤四中恶意可执行pe文件生成对抗样本具体步骤如下:
[0023]
步骤4.1).根据动作策略库中动作个数生成随机动作序列,使用动作策略库进行动作映射;
[0024]
步骤4.2).根据动作映射对输入恶意可执行pe文件进行修改;
[0025]
步骤4.3).使用步骤三分类器模型检测步骤4.2中生成的修改后的样本,检测结果若为良性即对抗样本,保留该对抗样本,对保留的对抗样本的所对应的动作序列构造种群初始化集合;
[0026]
步骤4.4).对种群初始化集合进行多目标遗传算法进化,进化过程中遵循步骤二中两个适应度目标函数约束;
[0027]
步骤4.5).计算适应度目标函数值,按照适应度目标函数值进行非支配排序以及拥挤度计算,最终获得满足适应度目标函数的多个pareto最优对抗样本。
[0028]
本发明所述非支配排序取任意两个恶意可执行pe文件mi,mj:当且仅当,对于权利要求3中所述的适应度目标函数f(m,m
′
)和g有f(mi,m
′i)》f(mj,m
′j)且gi《gj,则mi支配mj;若存在一个函数满足:f(mi,m
′i)》f(mj,m
′j)或gi《gj,则mi和mj互不支配;对于恶意可执行pe文件没有被支配的解时,则mi被称为pareto最优解;
[0029]
拥挤度计算根据所述适应度目标函数公式(1)和公式(2)对种群所对应的对抗样本计算值的大小的升序顺序排序,计算种群中所对应的对抗样本与相邻两个个体在每个适应度目标函数值上距离差之和,其表达式如下:
[0030][0031]
其中,m为目标函数的个数,适应度目标函数值中最大值和最小值所对应的对抗样本拥挤度p
dis
[i]=∞,fm代表第m个适应度目标函数,fm(i+1)代表第m个适应度目标函数第i+1个对抗样本的函数值,为第m个适应度目标函数按照升序顺序排序后的最大值,为第m个适应度目标函数按照升序顺序排序后的最小值。
[0032]
本发明对公式(1)中s(m,m
′
)计算恶意可执行pe文件输入样本与对抗样本之间相似度,将恶意可执行pe文件m和对抗样本m
′
转化为灰度图;使用差异哈希算法进行图片相似度计算,该算法的作用是对每张图片生成一个指纹字符串,比较两张图片的指纹,计算指纹之间的汉明距离,最终得到相似度得分。
[0033]
本发明所述步骤三中的分类器模型为预训练好的深度学习模型。
[0034]
本发明所述步骤4.3中经过步骤三分类器检测结果为良性的样本即对抗样本为第一条件实施后续进化。
[0035]
本发明步骤4.4进化过程中采取精英保留策略,获得的对抗样本个数根据算法中初始化参数设置而得,并且获得的对抗样本受步骤二中适应度函数约束,为pareto最优对抗样本。
[0036]
采用上述技术方案所取得的技术效果在于:
[0037]
本发明对恶意可执行pe文件进行动作插入,生成新的样本,对新的样本经过分类器检测,检测结果为良性的样本根据适应度目标函数约束进行多目标遗传算法进化,进化后获得pareto最优对抗样本。在黑盒攻击的场景下,利用面向pareto的多目标遗传算法保证生成对抗样本与原始输入样本恶意功能不被破坏且相似度高,添加的动作个数少,无动作冗余的多个pareto最优对抗样本;其中对于动作策略库中一个动作section append中注入内容是从良性可执行pe文件中获取,可增加生成对抗样本成功攻击的可能性。
附图说明
[0038]
图1是本发明的方法流程图。
具体实施方式
[0039]
下面结合附图和具体实施方式对本发明作进一步详细的说明。
[0040]
如图1所示,一种面向pareto多目标遗传算法对抗样本自动生成方法,包括如下步骤:
[0041]
步骤一、构建动作策略库;其中构建动作策略库中的其中一个动作为section append,该动作对恶意可执行pe文件section中注入的内容从良性可执行pe样本中提取,使用第三方pefile库对良性可执行pe文件进行文件解析,获取包括偏移量pionterrawdata映射到section内容以及对应section名称;
[0042]
步骤二、设计适应度目标函数;主要包括以下两部分:
[0043]
2.1).验证原始恶意功能是否存在以及对抗样本与原始输入样本之间的相似度,以确保在添加动作时注入或者删除的内容改动较小,其表达式如下:
[0044]
f(m,m
′
)=s(m,m
′
)+fun(m
′
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0045]
其中,m表示恶意可执行pe样本输入,m
′
表示对抗样本,s(m,m
′
)表示恶意可执行pe样本与对抗样本之间的相似度得分,相似度比较方法为:将原始输入样本m和对抗样本m
′
转化为灰度图;使用差异哈希算法进行图片相似度计算,该算法的作用是对每张图片生成一个指纹字符串,比较两张图片的指纹,计算汉明距离,最终得到相似度得分;fun(m
′
)表示验证对抗样本原始恶意功能的奖惩机制,验证方法采用本地搭建cuckoo沙箱,如果cuckoo沙箱执行该对抗样本恶意功能存在则对该样本进行奖励,奖励为1,即:
[0046][0047]
2.2).减少修改动作个数,确保对恶意可执行pe样本修改最小化,防止添加动作冗余使文件改动过大引起检测异常,计算随机动作序列a=[a0,a1,
…
,aj]的非零元素个数,其表达式如下:
[0048][0049]
其中,ai=0或1,j代表步骤一中动作策略库中动作个数;
[0050]
步骤三、选择分类器模型,分类器模型检测结果添加动作修改后的样本是恶意还是良性样本,本发明分类器模型为预训练好的深度学习模型;
[0051]
步骤四、以恶意可执行pe文件作为样本输入,生成随机动作序列根据动作策略库中进行动作映射,修改输入样本,修改后的样本经过步骤三选择的分类器模型检测,保留检测结果为良性的样本即对抗样本,对保留的对抗样本的所对应的动作序列构造种群初始化集合以便后续进化得到pareto最优对抗样本,具体步骤如下:
[0052]
步骤4.1).根据动作策略库中动作个数生成随机动作序列,使用动作策略库进行动作映射;该动作策略库中包含10种修改动作,因此生成随机动作序列为[a0,a1,...,a9],ai为0或1代表是否选择对应动作;
[0053]
步骤4.2).根据步骤4.1中的动作映射对输入恶意可执行pe文件进行修改;如果使用section append则从上述步骤一中获取良性可执行pe文件注入内容;
[0054]
步骤4.3).使用步骤三分类器模型检测步骤4.2中生成的修改后的样本,检测结果若为良性即对抗样本,保留该对抗样本,对保留的对抗样本的所对应的动作序列构造种群初始化集合;在进化过程中,将经过步骤三分类器检测结果为良性的样本即对抗样本为第一条件实施后续进化操作;设置该条件的目的在于能够减少整体进化时间,更快找到pareto最优对抗样本,加速算法收敛;
[0055]
步骤4.4).对种群初始化集合进行多目标遗传算法进化,进化过程中遵循步骤二
中两个适应度目标函数约束;本发明中算法进化次数为20代结束;对抗样本的生成不仅是要绕过分类器模型的检测,还要通过cuckoo沙箱进行恶意功能检测,观察对抗样本格式以及可执行性是否损坏,以保证生成对抗样本的真实性,提高攻击的成功率;
[0056]
步骤4.5).计算适应度目标函数值,按照适应度目标函数值进行非支配排序以及拥挤距离计算,最终获得满足适应度目标函数的多个pareto最优对抗样本,具体步骤如下:
[0057]
步骤4.5.1).将种群初始化中所对应的对抗样本根据步骤二中的适应度目标函数计算,首先对抗样本使用cuckoo沙箱执行,可以检测出样本的可执行性以及原始恶意功能的一致性,对于两者都存在的进行奖励,奖励分数为1,将该样本与原始输入pe样本通过转化生成256
×
256像素大小的灰度图,通过差异哈希算法生成图片指纹,计算指纹主要步骤为:缩小图片尺寸为9
×
8像素,计算差异值,根据尺寸大小每行9个像素之间产生8个不同的差异,共8行,形成64个差异值;获取指纹hash值,计算两个图片指纹之间的汉明距离,最终计算相似度得分,继而得到该对抗样本的公式(1)的函数值,公式(2)值的计算为步骤4.1生成随机动作序列的非零个数;
[0058]
即每个对抗样本有两个属性值:f(m,m
′
)和g,计算种群所对应对抗样本适应度目标函数值构成集合f和g,对对抗样本进行非支配排序,即选出同时满足max{f}以及min{g}的对抗样本,进行下一代进化;
[0059]
本发明有两个适应度目标函数f(m,m
′
)和g,其中非支配排序取任意两个恶意可执行pe文件mi,mj:当且仅当,对于步骤二中适应度目标函数f(m,m
′
)和g,有f(mi,m
′i)》f(mj,m
′j)且gi《gj,则mi支配mj;若存在一个函数满足:f(mi,m
′i)》f(mj,m
′j)或gi《gj,则mi和mj互不支配;对于恶意可执行pe文件没有被支配的解时,则mi被称为pareto最优解;其中m
′i表示恶意可执行pe文件mi生成的经过分类器模型检测的对抗样本,m
′j表示恶意可执行pe文件mj生成的经过分类器模型检测的对抗样本,gi和gj分别表示m
′i以及m
′j所对应的动作序列代入适应度目标函数计算非零个数的函数值;
[0060]
步骤4.5.2).使用精英保留策略,根据非支配等级的划分,选取最优样本形成第一代父代种群p
t
;
[0061]
步骤4.5.3).对父代种群p
t
遗传算法中选择、交叉、变异操作,选择方法为二元锦标赛选择方法,择优进行种群动作序列交叉、变异操作,保证种群优势,生成子代种群c,合并种群,个数为初始化种群的2倍;
[0062]
步骤4.5.4).对合并种群进行非支配排序,根据非支配等级划分进行同一非支配等级个体之间拥挤度计算,以保证种群个体多样性,避免陷入局部最优;两个个体择优时,如果处于不同非支配层,按照非支配等级选择,否则按照拥挤度进行判定;放入新种群p
t+1
中,直到此代种群数量等于初始化种群数量;
[0063]
所述拥挤度计算根据所述适应度目标函数公式(1)和公式(2)对种群所对应的对抗样本计算值的大小的升序顺序排序,计算种群中所对应的对抗样本与相邻两个个体在每个适应度目标函数值上距离差之和,其表达式如下:
[0064][0065]
其中,m为目标函数的个数,初始参数p
dis
[i]=0,适应度目标函数值中最大值和最小值所对应的对抗样本拥挤度p
dis
[i]=∞,fm代表第m个适应度目标函数,fm(i+1)代表第m
个适应度目标函数第i+1个对抗样本的函数值,为第m个适应度目标函数按照升序顺序排序后的最大值,为第m个适应度目标函数按照升序顺序排序后的最小值;
[0066]
步骤4.5.5).重复执行步骤4.5.3和4.5.4直到满足本发明设定的进化次数;形成pareto前沿,生成满足多目标约束的pareto最优对抗样本。
[0067]
本发明对恶意可执行pe文件进行动作插入,生成新的样本,对新的样本经过分类器检测,检测结果为良性的样本根据适应度目标函数约束进行多目标遗传算法进化,进化后获得pareto最优对抗样本。在黑盒攻击的场景下,利用面向pareto的多目标遗传算法保证生成对抗样本与原始输入样本恶意功能不被破坏且相似度高,添加的动作个数少,无动作冗余的多个pareto最优对抗样本;其中对于动作策略库中一个动作section append中注入内容是从良性可执行pe文件中获取,可增加生成对抗样本成功攻击的可能性。
[0068]
本发明在黑盒攻击的场景下,经过实验生成的pareto最优对抗样本构成对抗样本集合;对多个商业检测引擎进行攻击,攻击结果表明该方法的切实可行性以及生成对抗样本的真实性,攻击成功率显著提高。
[0069]
最后说明的是,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换或改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1