一种解决分布式混合流水车间总延迟时间优化的强化学习蛙跳算法
1.本发明涉及车间调度领域,具体是一种解决分布式混合流水车间总延迟时间优化的强化学习蛙跳算法。
背景技术:
2.混合流水车间调度问题是一类广泛存在于化工、冶金、纺织、钢铁、半导体等工业过程的典型调度问题,是流水车间调度问题和并行机调度问题的综合。随着经济全球化的不断深入发展以及市场竞争的日益加剧,企业之间的并购、合作生产和协作生产越来越多,分布式生产成为一种常见的生产制造模式。分布式生产系统能够充分利用多个工厂(车间)或者加工中心的生产制造资源,通过对资源的合理规划和共享,实现以合理的成本快速高效地完成产品的加工制造。在分布式制造环境下,多个工厂的调度都包含混合流水车间调度问题,这类问题称为分布式混合流水车间调度问题。与混合流水车间调度问题相比,分布式混合流水车间调度问题往往包括机器分配、工厂分配和调度三个子问题,其子问题更多,且子问题之间耦合关系更加复杂,如工厂分配直接影响机器分配和调度的优化内容,如果工件在所分配的工厂无法得到最优的机器分配和调度,即使工厂分配达到最优,整个问题的解也难以达到最优。另外,在实际的生产过程中,产品往往需要由多种部件装配而成,现有关分布式混合流水车间调度问题的研究只考虑了加工阶段而忽略了运输和装配阶段。
技术实现要素:
3.本发明的目的就是为了克服现有技术的不足,提供一种解决分布式混合流水车间总延迟时间优化的强化学习蛙跳算法。
4.本发明采用的技术方案是:
5.一种解决分布式混合流水车间总延迟时间优化的强化学习蛙跳算法,包括以下步骤:
6.(1)q-学习算法
7.q-学习的计算形式如下:
[0008][0009]
其中α表示学习比例,γ是折扣因子,r
t+1
表示在环境状态为s
t
时执行动作a
t
获得的回报,指q-表中状态为s
t+1
时最大的q值;
[0010]
动作选择依赖于q值,最初,所有q值都是0,说明agent没有任何可供使用的学习经验,ε-greedy选择是一种常用的动作选择策略,其描述如下:如果随机数rand<ε,随机选择一个动作;否则,选择当前状态下q值最大的动作a,即其中rand是[0,1]中服从均匀分布的随机数;
[0011]
(2)编码和解码
[0012]
采用三串编码方式表达一个解,对于一个具有n个工件和f个工厂且考虑运输和装配的dhfsp,编码方案包括三个部分:工厂分配串[θ1,θ2,
…
,θn],工件排列[π1,π2,
…
,πn]和部件排列其中h0=0,πi∈{1,2,
…
,n},ηw表示工件ji的一个部件,h
i-1
+1≤w≤hi,θi∈{1,2,
…
,f},工件ji的部件为h
i-1
+1,h
i-1
+2,
…
,hi,而是这些部件的排列。
[0013]
解码过程如下:
[0014]
1)根据工厂分配串将工件分配到各个工厂,由工件排列和部件排列确定每个工厂中工件和部件的排列;
[0015]
2)根据工件和部件的排列,依次执行加工、运输和装配。当部件在第l个阶段加工时,选择m
l
台并行机中可利用时间最小的机器;
[0016]
初始种群p由随机产生的n个解组成;
[0017]
(3)邻域搜索
[0018]
动作a
t
由全局搜索、邻域搜索和解的接收准则组成,首先是包含3种交叉操作的全局搜索和包含12种邻域结构的邻域搜索;
[0019]
应用了12种邻域结构n
1-n
12
,n1的具体过程如下:随机选择工件ji和jg(θg=θi),假设i=πv,g=πu,v>u,将i插入到工件排列的位置u;n2与n1类似,区别为θg≠θi,令θi=θg,即将工件ji从其当前工厂转移到工件jg所在的工厂,n3和n1的区别在于交换工件ji和jg,而不是插入;
[0020]
n4的具体步骤如下:随机选择工件ji和jg(θg≠θi),交换工件排列中的ji和jg,交换工厂分配串中的θi和θg;n5描述如下:随机选择一个工件ji,随机选择工件ji的部件ηv和ηu(v>u),将ηv插入到部件排列的位置u;n6与n5类似,区别在于交换ηv和ηu;
[0021]
假设工厂f是完成时间最大的工厂,在邻域结构n1中增加条件θg=θi=f可得到n7;n8的具体过程如下:随机选择工件ji(θi=f)和工件jg(θg≠f),将工件ji插入到工件jg在工件排列中的位置,令θi=θg;n9通过交换工件排列中属于同一工厂f的两个不同工件以产生新解;n
10
和n8类似,区别为交换工件排列中的工件ji,jg;当n5中工件ji的选择限制在工厂f时可得到n
11
;n
12
和n6类似,不同之处为从工厂f选择ji;
[0022]
当上述工厂f的最大完成时间减少时,最大完成时间很可能会降低;n
7-n
12
与工件和部件的移动有关,如工厂f内的插入和互换操作,工厂f和其他工厂间的插入和互换操作;
[0023]
利用上述邻域结构,设计两种邻域搜索ns1和ns2,ns1描述如下,对于解x,令b=1,w=0,重复以下步骤直到b=7或w=1:产生新解y∈nb(x),如果y优于x,则x=y,w=1,并利用y替换xg;否则,令b=b+1;ns2与ns1的步骤一样,只不过初始条件设为b=7,w=0,终止条件设为b=13或w=1。其中y替换xg的条件是:y优于xg;
[0024]
对于ns1中的邻域结构,工厂选择是随机的,ns2的n
7-12
中选择的工厂为完成时间最大的工厂;
[0025]
(4)全局搜索
[0026]
一个解由三个串组成,针对解x,z,设计三种交叉操作,解z的工件排列中位置k和l之间的工件的集合定义为k<l,工件排列的交叉操作描述如下:对于解x,z,随机产生k,
l,1≤k<l≤n,确定使解x中属于的工件按照这些工件在解z中的顺序排列;部件排列的交叉过程如下:对于解x,z,随机确定k,l,1≤k<l≤n和使解x中属于的工件的部件,按照这些部件在解z中的顺序排列;工厂分配串的交叉操作步骤如下:当确定以后,使解x中属于的工件对应的工厂分配串的值与z相同;解x,z之间的全局搜索描述如下:随机选择一个交叉操作,对x,z执行交叉操作产生一个新解;
[0027]
(5)q-学习过程
[0028]
q-学习算法主要包括状态s
t
、动作a
t
、回报r
t
和动作选择策略,为了实现q-学习过程,环境状态由种群评估结果确定,根据全局搜索、邻域搜索和解的接受准则设计动作,并重新定义回报的计算方式;
[0029]
种群p的状态由种群最好解xg的变化情况和种群的离散程度d
gen
决定,d
gen
计算如下:
[0030][0031]
其中表示种群p在第gen代的第i个解的最大完成时间,指p在第gen代所有解的平均最大完成时间;
[0032]
im用于描述xg的改进情况,如果xg在当代得到了改进,则im=1;否则,im=0;δd=d
gen-d
gen-1
,d
gen
通过对第gen代的种群p利用公式(3)计算得到;
[0033]
由于利用贪婪方式更新xg,种群p的xg不会变差,只存在im=0和im=1两种情况,随着种群p从第gen-1代进化到第gen代,δd可能会改善、恶化或保持不变,δd存在三种可能,这样由于两个指标的组合,存在6种状态;
[0034]
通常利用贪婪接收准则确定能否接收新解,即当新解y优于解x时,新解y替换x,给出了概率接收准则:如果新解y优于x,则利用y替换即x=y;否则,若随机数rand<β,则利用y替换x,其中β=0.1;动作集a包含4种动作,每种动作表示一种模因组搜索策略,a=[a(1),a(2),a(3),a(4)],全局搜索过程采用贪婪接受准则或概率接收准则,ns1和ns2中始终使用贪婪接受准则,
[0035]
模因组m
l
执行动作a(i)时,首先选择m
l
中的两个最好解假设优于动作a(1)描述如下:由和的全局搜索产生新解z,应用贪婪接收准则确定z能否替代若否,则利用和xg的全局搜索产生新解z,利用贪婪接收准则确定新解z能否替换若否,对执行ns1。动作a(2)与动作a(1)的步骤相同,只是利用ns2代替ns1。动作a(3),a(4)与动作a(1),a(2)的不同之处在于全局搜索采用概率接收准则;
[0036]
模因组搜索过程中,一旦选择一个动作,该动作作为模因组的搜索策略一直存在直到模因组搜索次数μ达到;
[0037]
6种状态的序号为1,2,3,4,5,6,显然,状态1最好,状态6最差,因为状态1中不仅xg得到了改善,而且种群p的离散程度也增加了,而状态6正好相反,状态的序号越小说明种群的状态越好,因此,当模因组搜索过程采用动作a(i)时,如果状态从l转移到w,w<l,该动作就会获得奖励;如果状态从l转移到w,该动作就会得到惩罚,回报函数定义为:r
t+1
=l-w,其中s
t
=l,s
t+1
=w;
[0038]
动作选择采用ε-greedy选择策略;
[0039]
(6)算法描述
[0040]
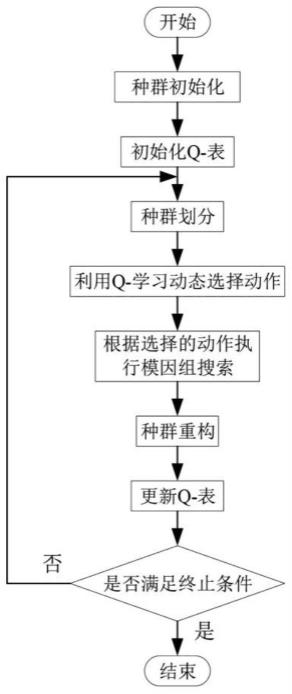
强化学习蛙跳算法是蛙跳算法和q-学习的集成,初始种群p随机产生,然后划分为s个模因组,模因组搜索过程利用q-学习动态选择搜索策略,模因组搜索结束后,利用所有模因重新构建种群p,基于q-学习的dsfla的流程图如附图5所示;
[0041]
强化学习蛙跳算法描述如下:
[0042]
1)随机产生包含n个解的种群p,q-表的初始值设为0,gen=1;
[0043]
2)执行种群划分;
[0044]
3)利用q-学习动态选择一个动作;
[0045]
4)根据选择的动作,对每一个模因组执行模因组搜索;
[0046]
5)进行种群重构,更新q-表,gen=gen+1;
[0047]
6)若不满足终止条件,重复2)~5),否则,输出结果。
[0048]
本发明的有益效果:本方法以蛙跳算法为框架,设计三串表示方法对分布式混合流水车间调度问题进行编码,利用强化学习蛙跳算法解决该问题。将q-学习嵌入到蛙跳算法的模因组搜索过程中,q-学习算法包括由全局搜索、邻域搜索和解的接收准则组成的动作集合和基于种群精英解和离散度而构建的6种状态。在算法运行的过程中,根据种群的状态,利用q-学习动态的选择执行的模因组搜索策略。本发明提高了分布式混合流水车间调度方案的质量,可为车间生产过程提供高效的调度方案。
附图说明
[0049]
图1是实例的调度甘特图;
[0050]
图2是六个邻域结构的过程;
[0051]
图3是三个交叉操作的过程;
[0052]
图4是im和δd的的每种状态发生的比例;
[0053]
图5是基于q-学习的dsfla的流程图;
[0054]
图6是6个算法关于指标的计算结果箱线图;
[0055]
图7是6个算法关于指标的计算结果箱线图;
[0056]
图8是6个算法关于指标的计算结果箱线图;
[0057]
图9是案例的调度甘特图。
具体实施方式:
[0058]
下面结合附图对发明进一步说明:
[0059]
(1)问题描述
[0060]
考虑运输和装配的dhfsp描述如下:存在n个工件j1,j2,
…
,jn,工件ji的部件集合为ψi。所有工件的总部件数假设部件1,2,
…
,|ψ1|属于工件1,工件ji的部件为|ψ
i-1
|+1,
…
,|ψ
i-1
|+|ψi|,i>1。
[0061]
存在f个同构工厂,每个工厂为一个装配混合流水车间,每个工厂包含加工、运输和装配三个过程。存在s个加工阶段,第l个加工阶段由m
l
台同速并行机组成。m
flk
表示工厂f第l个加工阶段的第k台机器。每个工厂f包含一台运输机器tmf和一台装配机器amf。部件首先分配到工厂f完成加工,当属于同一工件的部件全部加工完成后,这些部件由运输机tmf收集并运送到装配机amf处装配。p
jl
表示部件j在第l阶段的加工时间,tri和asi分别表示工件ji的运输时间和装配时间。
[0062]
问题存在如下工件约束和机器约束:加工机器在同一时刻只能加工一个部件,运输机器和装配机器同一时刻只能运输和装配一个工件;部件在同一时刻只能在一台机器加工,属于同一工件的部件同一时刻只能在一台机器上运输或装配;加工、运输或装配不能中断;所有机器在任意时刻都可用。
[0063]
考虑运输和装配的dhfsp由工厂分配、机器分配和调度三个子问题组成。三个子问题之间存在强耦合关系。另外,调度子问题还包含工件调度和部件调度。工件调度决定工件的加工顺序,部件调度确定部件的加工顺序。
[0064]
在满足所有约束的条件下最小化最大完成时间。
[0065][0066]
其中ci表示工件ji的完成时间,c
max
指所有工件的最大完成时间。
[0067]
一个实例的加工信息如表1和表2所示,该实例包含5个工件、2个工厂和2个加工阶段,每个加工阶段都有2台并行机。附图1给出了该实例的甘特图。
[0068]
表1 5个工件的实例信息
[0069][0070]
表2p
jl
的加工信息
[0071][0072]
(2)q-学习算法
[0073]
q-学习的计算形式如下:
[0074][0075]
其中α表示学习比例,γ是折扣因子,r
t+1
表示在环境状态为s
t
时执行动作a
t
获得的回报,指q-表中状态为s
t+1
时最大的q值。
[0076]
动作选择依赖于q值。最初,所有q值都是0,说明agent没有任何可供使用的学习经验。ε-greedy选择是一种常用的动作选择策略,其描述如下:如果随机数rand<ε,随机选择一个动作;否则,选择当前状态下q值最大的动作a,即其中rand是[0,1]中服从均匀分布的随机数
[0077]
(3)编码和解码
[0078]
采用三串编码方式表达一个解。对于一个具有n个工件和f个工厂且考虑运输和装配的dhfsp,编码方案包括三个部分:工厂分配串[θ1,θ2,
…
,θn],工件排列[π1,π2,
…
,πn]和部件排列其中h0=0,πi∈{1,2,
…
,n},ηw表示工件ji的一个部件,h
i-1
+1≤w≤hi,θi∈{1,2,
…
,f}。工件ji的部件为h
i-1
+1,h
i-1
+2,
…
,hi,而是这些部件的排列。
[0079]
解码过程如下:
[0080]
1)根据工厂分配串将工件分配到各个工厂,由工件排列和部件排列确定每个工厂中工件和部件的排列;
[0081]
2)根据工件和部件的排列,依次执行加工、运输和装配。当部件在第l个阶段加工时,选择m
l
台并行机中可利用时间最小的机器。
[0082]
对于问题描述中的给出的实例,一个可能解为工件排列[4,2,3,1,5],部件排列[4,2,3,1,5,6,8,9,7,11,10,12,13,15,14]和工厂分配串[1,2,1,2,2]。工件1和工件3在工厂1中加工,工件排列为3,1,对应的部件排列为8,9,7,4,2,3,1。附图1给出了该解的调度甘特图。
[0083]
初始种群p由随机产生的n个解组成。
[0084]
(4)邻域搜索
[0085]
动作a
t
由全局搜索、邻域搜索和解的接收准则组成,首先介绍包含3种交叉操作的全局搜索和包含12种邻域结构的邻域搜索。
[0086]
应用了12种邻域结构n
1-n
12
。n1的具体过程如下:随机选择工件ji和jg(θg=θi),假设i=πv,g=πu,v>u,将i插入到工件排列的位置u;n2与n1类似,区别为θg≠θi,令θi=θg,即将工件ji从其当前工厂转移到工件jg所在的工厂。n3和n1的区别在于交换工件ji和jg,而不是插入。
[0087]
n4的具体步骤如下:随机选择工件ji和jg(θg≠θi),交换工件排列中的ji和jg,交换工厂分配串中的θi和θg。n5描述如下:随机选择一个工件ji,随机选择工件ji的部件ηv和ηu(v>u),将ηv插入到部件排列的位置u。n6与n5类似,区别在于交换ηv和ηu。附图2给出了6个邻域结构的过程。
[0088]
假设工厂f是完成时间最大的工厂。在邻域结构n1中增加条件θg=θi=f可得到n7。n8的具体过程如下:随机选择工件ji(θi=f)和工件jg(θg≠f),将工件ji插入到工件jg在工件排列中的位置,令θi=θg。n9通过交换工件排列中属于同一工厂f的两个不同工件以产生新解。n
10
和n8类似,区别为交换工件排列中的工件ji,jg。当n5中工件ji的选择限制在工厂f时可得到n
11
。n
12
和n6类似,不同之处为从工厂f选择ji。
[0089]
当上述工厂f的最大完成时间减少时,最大完成时间很可能会降低。n
7-n
12
与工件和部件的移动有关,如工厂f内的插入和互换操作,工厂f和其他工厂间的插入和互换操作。
[0090]
利用上述邻域结构,设计两种邻域搜索ns1和ns2。ns1描述如下。对于解x,令b=1,w=0,重复以下步骤直到b=7或w=1:产生新解y∈nb(x),如果y优于x,则x=y,w=1,并利用y替换xg;否则,令b=b+1。ns2与ns1的步骤一样,只不过初始条件设为b=7,w=0,终止条件设为b=13或w=1。其中y替换xg的条件是:y优于xg。
[0091]
对于ns1中的邻域结构,工厂选择是随机的。ns2的n
7-12
中选择的工厂为完成时间最
大的工厂。
[0092]
(5)全局搜索
[0093]
一个解由三个串组成,针对解x,z,设计三种交叉操作。解z的工件排列中位置k和l之间的工件的集合定义为k<l。工件排列的交叉操作描述如下:对于解x,z,随机产生k,l,1≤k<l≤n,确定使解x中属于的工件按照这些工件在解z中的顺序排列。部件排列的交叉过程如下:对于解x,z,随机确定k,l,1≤k<l≤n和使解x中属于的工件的部件,按照这些部件在解z中的顺序排列。工厂分配串的交叉操作步骤如下:当确定以后,使解x中属于的工件对应的工厂分配串的值与z相同。附图3给出了三种交叉操作的具体过程。解x,z之间的全局搜索描述如下:随机选择一个交叉操作,对x,z执行交叉操作产生一个新解。
[0094]
(6)q-学习过程
[0095]
q-学习算法主要包括状态s
t
、动作a
t
、回报r
t
和动作选择策略。为了实现q-学习过程,环境状态由种群评估结果确定,根据全局搜索、邻域搜索和解的接受准则设计动作,并重新定义回报的计算方式。
[0096]
种群p的状态由种群最好解xg的变化情况和种群的离散程度d
gen
决定,d
gen
计算如下:
[0097][0098]
其中表示种群p在第gen代的第i个解的最大完成时间,指p在第gen代所有解的平均最大完成时间。
[0099]
im用于描述xg的改进情况,如果xg在当代得到了改进,则im=1;否则,im=0。δd=d
gen-d
gen-1
,d
gen
通过对第gen代的种群p利用公式(3)计算得到。
[0100]
根据im和δd定义6种状态,如表3所示。
[0101]
表3状态集
[0102][0103]
由于利用贪婪方式更新xg,种群p的xg不会变差,只存在im=0和im=1两种情况。随着种群p从第gen-1代进化到第gen代,δd可能会改善、恶化或保持不变,δd存在三种可能,这样由于两个指标的组合,存在6种状态。
[0104]
附图4给出了im和δd关于实例60
×3×
8和100
×5×
8在dsfla的整个搜索过程中每种情况发生的比例。由附图4可知,两个指标的每种情况都会发生,6种状态都出现了,因此,有必要设置6种状态。
[0105]
通常利用贪婪接收准则确定能否接收新解,即当新解y优于解x时,新解y替换x。给出了概率接收准则:如果新解y优于x,则利用y替换即x=y;否则,若随机数rand<β,则利用y替换x。其中β=0.1。动作集a包含4种动作,每种动作表示一种模因组搜索策略。a=[a(1),
a(2),a(3),a(4)],全局搜索过程采用贪婪接受准则或概率接收准则,ns1和ns2中始终使用贪婪接受准则。
[0106]
模因组m
l
执行动作a(i)时,首先选择m
l
中的两个最好解假设优于动作a(1)描述如下:由和的全局搜索产生新解z,应用贪婪接收准则确定z能否替代若否,则利用和xg的全局搜索产生新解z,利用贪婪接收准则确定新解z能否替换若否,对执行ns1。动作a(2)与动作a(1)的步骤相同,只是利用ns2代替ns1。动作a(3),a(4)与动作a(1),a(2)的不同之处在于全局搜索采用概率接收准则。
[0107]
模因组搜索过程中,一旦选择一个动作,该动作作为模因组的搜索策略一直存在直到模因组搜索次数μ达到。
[0108]
6种状态的序号为1,2,3,4,5,6。显然,状态1最好,状态6最差。因为状态1中不仅xg得到了改善,而且种群p的离散程度也增加了,而状态6正好相反,状态的序号越小说明种群的状态越好。因此,当模因组搜索过程采用动作a(i)时,如果状态从l转移到w,w<l,该动作就会获得奖励;如果状态从l转移到w,该动作就会得到惩罚。回报函数定义为:r
t+1
=l-w,其中s
t
=l,s
t+1
=w。
[0109]
动作选择采用ε-greedy选择策略。
[0110]
为了展示q-表的更新过程给出一个示例,共有6种状态和4种动作。假设当前状态s
t
=2下一个状态s
t+1
=3,当前动作a
t
=2,α=0.1,γ=0.9,此时,回报r
t+1
=-1。当q-表更新后,根据公式(3-2)可知q(2,2)=8.820。表4给出了q-表的更新过程。
[0111]
表4q-表的更新过程
[0112][0113]
(7)算法描述
[0114]
强化学习蛙跳算法是蛙跳算法和q-学习的集成。初始种群p随机产生,然后划分为s个模因组。模因组搜索过程利用q-学习动态选择搜索策略。模因组搜索结束后,利用所有模因重新构建种群p。基于q-学习的dsfla的流程图如附图5所示。
[0115]
强化学习蛙跳算法描述如下:
[0116]
1)随机产生包含n个解的种群p,q-表的初始值设为0,gen=1。
[0117]
2)执行种群划分。
[0118]
3)利用q-学习动态选择一个动作。
[0119]
4)根据选择的动作,对每一个模因组执行模因组搜索。
[0120]
5)进行种群重构,更新q-表,gen=gen+1。
[0121]
6)若不满足终止条件,重复2)~5),否则,输出结果。
[0122]
(8)实验验证
[0123]
随机产生80个实例,其中p
jl
∈[1,100],tri∈[1,100],asi∈[1,100],|ψi|∈[2,5],m
l
∈[2,5]。以上所有数据都是整数,实例表示为n
×f×
s。蛙跳算法的参数设置为n=60,s=6,μ=50,α=0.1,γ=0.9,ε=0.1。其中,n,s,μ,α,γ,ε分别表示种群数量、模因组数量、模因组搜索次数、学习比例、折扣因子和选择概率。
[0124]
rpd
min
定义如下:
[0125]
rpd
min
=(min-min
*
)/min
*
×
100%
ꢀꢀ
(5)
[0126]
min
*
表示所有算法获得的最小min。当min替换成avg或max时,可得到rpd
avg
或rpd
max
。
[0127]
从表5、表6、表7、附图6、附图7和附图8的计算结果可以看出,本发明涉及的一种解决分布式混合流水车间总延迟时间优化问题的强化学习蛙跳算法具有显著优势。其中,qsfla、sfla、cma、hpso、hvns和idcoa分别表示强化学习蛙跳算法、基本的蛙跳算法、竞争文化基因算法、混合粒子群优化算法、混合变邻域搜索算法和改进的离散布谷鸟优化算法。
[0128]
表5六种算法关于min的部分计算结果
[0129]
[0130][0131]
表6六种算法关于avg的部分计算结果
[0132][0133]
表7六种算法关于max的部分计算结果
[0134]
[0135][0136]
(9)实际案例
[0137]
给出一个家具厂的实际案例,该公司生产多种家具,如不同类型的抽屉式卧式介质储物柜,每个储存柜由一些部件装配而成,这些部件会在加工完成后运输到装配车间装配。每个部件的加工包含冲压阶段、钣金阶段、焊接阶段、电动压紧阶段和钻孔阶段。
[0138]
混合流水车间包含4个产品、2个工厂和5个阶段。表8和表9给出了实例的加工数据。强化学习蛙跳算法获得的调度方案如附图9所示,其中c
max
=1120。从附图9中可以看出,工件1和3的部件分配到工厂1,工件2和4的部件分配到工厂2。工厂1和2的最大完成时间分别为1115和1120。很明显,两个工厂的最大完成时间非常接近。
[0139]
因此本发明涉及的一种解决分布式混合流水车间总延迟时间优化问题的强化学习蛙跳算法可以很好的解决实际问题。
[0140]
表8加工信息
[0141][0142]
表9加工数据
[0143]
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1