一种基于知识蒸馏和多模态融合的视频分类方法
1.本发明涉及一种基于知识蒸馏和多模态融合的视频分类方法,属于数字图像处理、深度学习领域。
背景技术:
2.视频分类是计算机视觉领域的一项重要任务,视频分类任务的主要目标是理解视频中包含的内容,确定视频对应的关键主题。基于深度学习的视频分类算法可以自动分析视频包含的语义信息,对视频进行自动分类、标注和描述,可以有效对大规模视频进行操作。
3.视频中包含丰富的多模态信息,比如视觉对象、运动、声音和文本(字幕或通过语音识别得到的文字)信息,这些不同模态的信息能够为多模态融合中的特征学习提供相似但不相同、可转移的语义信息(如颜色、纹理、事件和位置等)。因此多模态学习的性能通常优于单模态学习。但根据2021年du等人的研究显示,多模态学习存在称之为模态失效的性能退化现象,同时多模态联合训练目标对单模态网络的性能存在负面的影响。
4.知识蒸馏方法是由hinton在2015年提出的一种模型压缩策略,将知识从一个大规模的教师网络提取到小规模的学生网络中。2018年开始研究人员发现知识蒸馏方法不仅可以用于模型压缩,还可以通过神经网络的互学习、自蒸馏等蒸馏策略用于进一步提升模型性能。通过不同初始化相同模型进行自蒸馏,学生网络可以学习相同网络学到的不同视角的特征,起到类似集成学习的效果。但自蒸馏策略与模型压缩策略相比缺少了丰富的外部知识。
5.综上所述,构建一种基于知识蒸馏和多模态融合的视频分类方法,不仅可以通过知识蒸馏缓解多模态学习的一系列问题,而且可以通过多模态融合把其它模态特征作为外部知识来引导学生网络,进一步推动视频分类的发展。
技术实现要素:
6.针对目前多模态融合与自蒸馏方法中各自存在的问题与不足,本发明提出一种结合基于知识蒸馏和多模态融合的视频分类方法,突破目前多模态学习存在的一些局限性,在多模态学习框架内添加知识蒸馏模块并将其用于视频分类任务,进一步提高卷积神经网络的视频处理能力。
7.为了实现上述目的,本发明的技术方案如下:本发明为解决上述技术问题采用以下技术方案:
8.本发明提供一种基于知识蒸馏和多模态融合的视频分类方法,具体步骤如下:
9.步骤1,提取音频、视觉数据集并预处理
10.1.1,音频数据集构建,采用ffmpeg提取视频数据集中的音频,单通道采样率为16000,格式为wav;
11.1.2,音频的特征提取,先对音频数据进行傅里叶变换得到频谱图,再进行对数变
换,最后经过归一化并转为张量;
12.1.3,视觉数据集构建,采用ffmpeg提取视频数据集中的图像帧,从中均匀采样出32帧图像表示视频模态,同时使用视频中间的图像帧表示图像模态,一共33帧;
13.1.4,视觉的特征提取,先对视觉数据随机缩放0.8到1.2倍后,中心裁剪至尺寸为224
×
224,最后归一化转化为张量;
14.步骤1的优势在于:通过固定采样率的音频数据以及相同的频谱图变换过程,可以得到大小一致的张量作为音频网络输入;视觉数据集包含33帧图像,既可以使用视频模态作为3维卷积网络输入,又可以使用图像模态作为2维卷积网络输入;采用归一化和数据增强方法,使数据集多样化并更容易收敛到最优解。
15.步骤2,搭建知识蒸馏架构
16.2.1,根据1.1至1.4中的方法提取的两个模态数据,选择相同的卷积神经网络,调整参数多次训练,选择最佳的模型作为单模态教师网络;
17.2.2,采用模型输出作为传递的知识,即使用kl散度损失作为蒸馏损失衡量教师网络和学生网络输出差别;
18.步骤2的优势在于:采用知识蒸馏方法,可以使多模态融合网络中的单模态学生网络获得不同参数下教师网络的视图特征,使模型更加泛化,并加速模型收敛。
19.步骤3,多模态融合学生网络
20.3.1,使用与教师网络相同的卷积神经网络作为单模态学生网络,并且采用与教师网络不同的随机初始化;
21.3.2,在得到各自单模态特征用于知识蒸馏后,对视觉和音频模态学生网络各层特征采用中期融合方式进行融合;
22.3.3,对视觉和音频模态学生网络的最后一层特征,使用平均后加se模块的方式进行晚期融合。
23.3.4,为视觉和音频模态学生网络以及晚期融合后的输出添加各自的分类损失,分类损失采用交叉熵函数。
24.步骤3的优势在于:在后期融合这一范式的基础上添加了中期融合模块,在模型中间层开始进行特征融合更有利于网络的学习以及不同模态之间特征的交互。
25.作为本发明的进一步优化方案,该方法的软件环境为ffmpeg和python3.7,采用scipy提取窗口长度为512,重叠部分为274的频谱图,采用pil和torchvision作为视觉数据处理方式。
26.作为本发明的进一步优化方案,知识蒸馏使用教师、学生相同模型不同初始化的自蒸馏策略传递模型输出的知识,同时对视觉、音频两个模态进行蒸馏。
27.作为本发明的进一步优化方案,多模态融合方法同时使用中期融合和晚期融合,中期融合在得到单模态特征后,总损失为三个分类损失和两个蒸馏损失直接相加。
28.本发明采用以上技术方案与现有技术相比,具有以下技术效果:本发明缓解了背景技术中所介绍的多模态学习中的模态失效问题和联合训练目标的负面影响,同时多模态融合可以有效解决自蒸馏外部知识不足的问题。此方法使用的知识蒸馏及多次特征融合方案,可以在不更改基础网络结构的前提下,通过计算两个学生网络和融合输出分类损失、音频视觉教师学生蒸馏损失,有效提升学生网络的泛化能力和准确度,并学到更健壮的单模
态特征,进一步提升最终视频分类性能。
附图说明
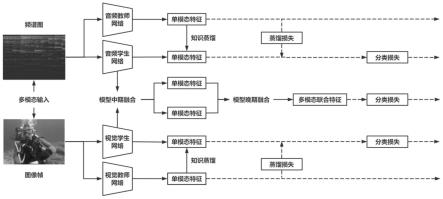
29.图1为一种基于知识蒸馏和多模态融合的视频分类方法的网络结构示意图;
30.图2为训练集图像帧示例;
31.图3为测试集图像帧示例;
32.图4为学生网络中间层特征融合示意图;
33.图5为学生网络输出晚期融合结构示意图
34.图6具体实施方式中所述的视频分类的结果:数据集vggsound在测试集上的测试正确率(1-test_acc)。
具体实施方式
35.为了使本技术领域的人员更好地理解本发明实施例中的技术方案,并使本发明实施例的上述目的、特征和优点能够更加明显易懂,下面结合附图对本发明实施例中的技术方案做进一步详细的说明。
36.实施例1:一种基于知识蒸馏和多模态融合的视频分类方法,具体步骤如下:
37.步骤1,提取音频、视觉数据集并预处理
38.1.1,音频数据集构建,采用ffmpeg提取视频数据集中的音频,单通道采样率为16000,格式为wav;
39.1.2,音频的特征提取,先对音频数据进行傅里叶变换得到频谱图,再进行对数变换,最后经过归一化并转为张量;
40.1.3,视觉数据集构建,采用ffmpeg提取视频数据集中的图像帧,从中均匀采样出32帧图像表示视频模态,同时使用视频中间的图像帧表示图像模态,一共33帧;
41.1.4,视觉的特征提取,先对视觉数据随机缩放0.8到1.2倍后,中心裁剪至尺寸为224
×
224,最后归一化转化为张量;
42.步骤2,搭建知识蒸馏架构
43.2.1,根据1.1至1.4中的方法提取的两个模态数据,选择相同的卷积神经网络,调整参数多次训练,选择最佳的模型作为单模态教师网络;
44.2.2,采用模型输出作为传递的知识,即使用kl散度损失作为蒸馏损失衡量教师网络和学生网络输出差别;
45.步骤3,多模态融合学生网络
46.3.1,使用与教师网络相同的卷积神经网络作为单模态学生网络,并且采用与教师网络不同的随机初始化;
47.3.2,在得到各自单模态特征用于知识蒸馏后,对视觉和音频模态学生网络各层特征采用mmtm模块进行中期融合;
48.3.3,对视觉和音频模态学生网络的最后一层特征,使用平均后加se模块的方式进行晚期融合。
49.3.4,为视觉和音频模态学生网络以及晚期融合后的输出添加各自的分类损失,分类损失采用交叉熵函数。
50.该方法的软件环境为ffmpeg和python3.7,采用scipy提取窗口长度为512,重叠部分为274的频谱图,采用pil和torchvision作为视觉数据处理方式。
51.知识蒸馏使用教师、学生相同模型不同初始化的自蒸馏策略传递模型输出的知识,同时对视觉、音频两个模态进行蒸馏。
52.多模态融合方法同时使用中期融合和晚期融合,中期融合在得到单模态特征后,总损失为三个分类损失和两个蒸馏损失直接相加。
53.本发明所提出的一种基于知识蒸馏和多模态融合的视频分类方法的网络结构示意图如图1所示。该图主要由单模态网络、知识蒸馏模块、多模态融合模块以及总体损失函数4个部分组成。整体流程主要包含两个阶段:训练阶段和验证阶段。
54.训练阶段与技术方案中一致,在训练集进行,在训练出教师网络后,对相同模型学生网络进行知识蒸馏和多模态融合,通过5个损失函数进行本方法的训练。
55.验证阶段去掉了知识蒸馏模块,在验证集进行,使用训练阶段完成后的学生网络,通过多模态融合模块得到最后的分类结果,根据验证集结果进行参数调优。
56.最终采用经过调优后的网络参数,训练结束后,在测试集统计分类结果,计算准确度,对模型进行评估。到此,基于知识蒸馏和多模态融合的视频分类网络构造完毕并完成参数调优。
57.实施例2:下面以vggsound数据集为例来详细说明本发明的步骤。
58.实验环境:电脑配置为intel(r)处理器(3.2ghz)和16gb随机存取存储器(ram),ubuntu 20.04.1 64位操作系统,nvidia rtx 3090(24gb)显卡;软件环境为深度学习框架pytorch 1.8.1,py-opencv3.4.2。
59.实验对象:vggsound数据集包含有接近20万长度为10秒的视频剪辑,标注了309个声音类别,每个类别样本控制在300到1000,并去除了无法保证音视频一致性的类别。使用数据集定义好的训练集和测试集,训练集(如图2)和测试集(如图3)比例为9:1,训练集18万,测试集1.5万。数据集包含大量具有挑战性的视频分类任务,如人类行为识别(如歌唱、鼓掌、玩滑板等)、复杂事件检测(如人群聚集、警报蜂鸣、人们尖叫等)、乐器分类(如吹口琴、弹钢琴、弹古筝等)以及场景分类(如瀑布、游泳池、下雨天等)等。vggsound数据集提供一个csv文件,用于数据集下载。csv文件的每一行都有由以下定义的列:
60.youtube id:用于视频下载。
61.开始秒数:对应类别的10秒视频片段开始于当前视频第几秒。
62.标签:类别名称(英文)。
63.训练/测试集:区分训练集和测试集。
64.以单个视频为例,需要根据csv文件中的id,使用sox下载对应视频,再根据开始时间使用ffmpeg截取对应的视频片段。对视频片段使用ffmpeg提取单通道采样率为16000,格式为wav的音频数据和均匀采样33帧图像的视觉数据。最后根据根据csv文件构建训练集和测试集对应的json标注文件(字典包含文件名和独热标注),完成数据准备工作。
65.实验步骤:
66.实验使用resnet-18作为基础网络,采用优化算法adam,参数为b1=0.9,b2=0.999,学习率为1e-3,每过5个epoch降低为0.1。使用准确率(accuracy)作为视频分类结果的评价指标。
67.(1)训练阶段:
68.步骤1:训练集数据处理。对于resnet-18,使用视觉数据集第33帧图像帧(即视频中间的图像帧)作为输入。对于视觉数据特征提取,采用torchvision.transforms的随机缩放、中间裁剪和归一化,最终得到3
×
224
×
224大小的张量。对于音频数据特征提取,采用soundfile获得音频数据和采样率,对于不满足10倍采样率的音频,使用np.tile复制到指定长度。使用scipy.signal.spectrogram得到音频频谱图,参数为nperseg=512,noverlap=274,经过归一化最终得到1
×
274
×
671大小的张量。
69.步骤2:教师网络训练。使用resnet-18按上述配置进行多次训练,注意每次随机数种子不同,使用不同的随机初始化。对于视觉模态教师网络,在imagnet数据集的预训练模型上进行训练,最终得到最好的视觉教师网络准确度为0.292。对于音频模态教师网络,需要对第一个卷积修改输入通道数为1,不使用预训练模型进行训练,最终得到最好的音频教师网络准确度为0.485。
70.步骤3:多模态融合学生网络。resnet-18特征学习部分包含一个基础卷积头、四层基础块basicblock以及最后的全连接层。如图4所示,使用最后全连接层的输出特征用于知识蒸馏,对最后两层basicbloc块的输出特征使用mmtm模块进行中期融合。具体流程:首先将两种模态的特征通过全局池化压缩再拼接,然后分别通过各自的全连接层得到各自模态的激励向量,最后将激励向量与原始模态特征相乘,公式为
[0071][0072]
其中表示对两种模态模型的第l层特征,表示全局平均池化,表示视觉模态的全连接层,表示中期融合后的视觉特征。对中期融合得到的特征继续通过basicbloc块,并输出第二次mmtm融合得到的输出。晚期融合采用如图5所示的压缩激励(se)模块进行模型输出特征的融合。
[0073]
步骤4:模型训练。对于每个输入,使用教师网络计算得到输出预测,使用学生网络得到输出预测、中期融合输出,使用晚期融合来融合两个模态学生网络的中期融合输出得到最后的多模态联合预测。总损失为2个学生网络输出预测的分类损失、多模态联合预测的分类损失和两个模态学生网络与教师网络之间输出预测的kl散度知识蒸馏损失。模型总共训练50个epoch。
[0074]
(2)测试阶段:
[0075]
步骤1:移去知识蒸馏模块。对于测试阶段,仅考虑学生网络多模态融合的预测结果和分类损失。
[0076]
步骤2:可视化。测试的结果如附图6所示,使用全部训练样本训练视觉设为50epoch,采用准确度作为衡量标准,针对多分类问题,计算在所有预测值上的平均正确率。准确度越高,就代表模型的分类正确率越高,模型效果越好。由图6可以看到,使用本方法后,学生网络的准确度得到了提高,并且多模态融合准确度远超教师网络。同时使用本方法得到的多模态融合准确度是目前vggsound数据集上使用resnet-18网络的各种方法里性能最好的。
[0077]
以上所述是本实验优选实施方式,尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解,其依然可以对前述各实施例所记载的技术方案进行
修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1