一种基于并行架构的空间大规模目标飞越的序列规划方法
1.本发明涉及一种基于并行架构的空间大规模目标飞越的序列规划方法,属于空间轨道设计与优化领域。
背景技术:
2.空间目标飞越序列规划是指对给定的一系列空间目标,从中挑选若干个或对全部目标进行飞越的顺序规划,在满足飞越条件的约束下优化整个飞越序列的总速度增量。该类任务的目标包括行星、小行星等自然天体,还包括探测器、空间碎片等人造天体,任务涉及小行星序列访问、空间碎片序列抓捕、对非合作目标实施动能拦截等。对于小规模目标数量的序列规划问题,现有技术可通过穷举法获取最优飞越序列;对于大规模目标序列规划问题,随着目标数量的增加,最优飞越序列的获取会愈加困难,计算复杂度会出现维度爆炸情况,贪心算法能有效降低计算负担,但容易使问题落入局部最优解;而集束搜索算法能提高获取问题结果的最优性,但会带来较大的计算负担;现有技术缺乏以较高的计算效率来获取较优飞越序列的算法。
技术实现要素:
3.针对空间大规模目标飞越的序列规划问题,本发明主要目的是提供一种基于并行架构的最优飞越序列获取方法,通过构建并行集束搜索算法,使大规模兰伯特问题求解并行化,有效提高序列规划中大规模兰伯特问题的求解效率;给定飞越任务所需的飞越目标数量及飞越时间窗口,利用并行集束搜索算法快速建立飞越子序列数据库,并通过在集束搜索算法中设置集束宽度,使数据库中子序列在足够宽的集束宽度下进行拼接,能有效避免飞越子序列拼接过程中提前落入局部最优解,提高整个序列获取的最优性;通过双层优化策略调整并优化拼接后的完整序列各目标间的转移时间,降低总速度增量,进一步提高整个序列的最优性;通过非线性规划算法sqp优化上述调整时间后序列的每个目标的飞越速度,进一步降低整个飞越过程的总速度增量,提高整个序列的最优性。因此,本发明基于并行架构实现空间大规模目标飞越的序列规划,具有规划效率高、飞越序列规划最优性高的优点。
4.本发明目的是通过下述技术方案实现的。
5.本发明公开的一种基于并行架构的空间大规模目标飞越的序列规划方法,构造并行集束搜索算法,将兰伯特问题求解并行化,所述集束搜索算法能针对大规模兰伯特问题不同的输入量,同步计算得到各自相应的结果,并根据并行兰伯特问题的求解结果进行目标与目标间所需速度增量计算;给定飞越任务所需的飞越目标数量及飞越时间窗口,依托并行集束搜索算法,在任务时间窗口的起始时刻确定航天器此时的状态,在给定子序列长度后,进行并行集束搜索得到目标访问的子序列,然后将子序列保存至数据库中;然后,提取现有数据库中每个子序列末端的状态及时刻,从此状态出发再次进行并行集束搜索,生成相应的子序列;将上述过程反复迭代,生成完整的子序列数据库;从数据库中提取子序
列,利用集束搜索算法,对子序列进行拼接,生成一条完整的飞越序列轨迹s1;为了进一步降低s1的速度增量,调整s1中目标与目标之间的转移时间,得到速度增量更低的序列轨迹s2;为进一步降低s2的总速度增量,建立非线性规划问题,以总速度增量作为优化目标,序列中每个目标的飞越速度作为待优化变量,以飞越时刻的相对速度限制作为约束条件,利用sqp优化上述非线性规划问题,得到速度增量更小的序列轨迹s3;所提出的方法具有快速求解的优点,并能有效保证大规模目标问题序列生成的最优性。
6.本发明公开的一种基于并行架构的空间大规模目标飞越的序列规划方法,包括如下步骤:
7.步骤一:针对空间大规模目标飞越序列规划存在的优化效率低、规划结果最优性难保证的难题,基于并行架构将兰伯特问题求解并行化,针对不同的输入量,同步计算得到各自相应的结果;得到兰伯特问题计算结果后,并行计算出不同输入量对应的速度增量,构建以速度增量为指标的并行集束搜索算法,该算法支持以更小的搜索步长来提高子序列获取的最优性,并提高空间大规模目标兰伯特问题的求解效率。
8.基于图形处理器gpu强大的并行计算能力,首先将兰伯特问题的求解建立并行架构的核函数中,即将兰伯特问题建立在gpu的每一个线程上进行求解;每个线程都能针对不同的输入,求解对应的兰伯特问题,输出相应的结果,计算过程同步进行。针对每个线程中的兰伯特问题,其输入量包括转移时间tf、初始位置r0、终端期望位置ra,输出量包括初始位置所对需的速度终端期望位置所需的速度对于从一个目标出发,到另一个目标的单步飞越问题,起始位置所对应的速度为v0;因此,在起始位置应施加的速度增量矢量为该速度增量大小为记终端目标的速度为va,飞越任务最低的相对速度限制为δv
l
,则到达的速度增量矢量δvf由分段函数式(1)进行计算:
[0009][0010]
到达速度增量大小为δvf=||δvf||;因此,对于单步飞越问题,总的速度增量大小δv为:
[0011]
δv=δv0+δvfꢀꢀꢀꢀ
(2)
[0012]
基于上述建立的并行兰伯特问题,将其应用于子序列数据库生成的并行集束搜索算法,并行集束搜索算法通过求解不同输入条件下的并行兰伯特问题,得到转移轨迹的起始速度和末端速度,通过式(2)计算每个输入条件下的总速度增量,设置集束搜索宽度来筛选相应的子序列。
[0013]
所述并行集束搜索算法需要根据待求解兰伯特问题的数量给并行求解框架分配相应的网格数gs和块数bs;当有n个待求解的兰伯特问题时,bs和gs的关系由以下式子获得:
[0014][0015]
与贪心算法不同,所述的并行集束搜索算法能通过设置超参数bw来保留前bw个较优的结点,有效避免过早陷入局部最优解,同时也能减少搜索所占用的空间和时间,提高空
间大规模目标兰伯特问题的求解效率。
[0016]
步骤二:给定飞越任务所需的飞越目标数量及飞越时间窗口,对目标间的转移时间离散化,从时间窗口的起始时刻开始,基于并行集束搜索算法生成子序列,通过提取子序列终端状态和时刻,利用算法继续生成子序列,反复迭代直至出发时刻大于飞越时间窗口的末端值,基于并行集束搜索算法能快速建立飞越子序列数据库,离线生成数据库,并能够指导多个飞越序列的生成。
[0017]
所述子序列的要素包括目标编号、飞越时刻、飞越速度、从上一个目标到当前目标的速度增量大小。
[0018]
针对包含n
t
个可选目标的序列规划问题,给定任务的起始时刻,得到对应的位置及速度,航天器从此时刻出发,待选的目标有n
t
个,待选定目标完成飞越后,下一个的待选目标将是n
t-1个。因此,对于要求飞越n
flyby
个的飞越任务而言,当目标间的转移时间为固定值时,其备选的序列总数p为:
[0019][0020]
式中,指n
t
个可选目标中取出n
flyby
个元素进行排序。
[0021]
对于n
t
较小的小规模目标的飞越序列规划问题,能通过穷举方法得到最优的访问序列。但对于n
t
较大的问题,穷举方法的序列总数超出计算机可求解范围;并且,每个目标之间的转移时间也是待优化变量,无法事先获取。因此,当前步骤二将建立子序列数据库生成方法,能有效提高最优序列的生成效率。
[0022]
定义序列飞越的时间窗口为[t0,tf],其中t0为飞越任务的起始时刻,tf为飞越任务的终端时刻,即航天器需要在t
f-t0的时间内完成对n
flyby
个目标进行飞越;定义目标与目标之间的转移时间的最大值为间的转移时间的最大值为应小于t
f-t0,转移时间的最小值记为则目标间的转移时间对于目标间的转移,需给定离散间隔进行穷举遍历以获得最优解,记离散间隔为则转移时间
[0023]
定义航天器起始时刻t0对应的位置及速度矢量记为r0,v0,首先利用步骤一中的并行集束搜索算法进行计算,输入量包括转移时间tf、在t0+tf时刻n
t
个目标对应的位置、速度,则应求解的兰伯特问题总数t
idx
为:
[0024][0025]
每个线程单独完成其中一个兰伯特问题的求解,求解过程同步进行,待完成兰伯特求解后,各线程还需利用式(2)计算对应的速度增量,待完成速度增量求解后,将计算结果传回cpu中,然后将t
idx
组兰伯特问题所对应的速度增量按照从小带大进行排序,提取前bw个速度增量以及对应的目标及转移时间;提取完成后,从上述bw目标出发,进行并行集束搜索,而此时对应待求解的兰伯特问题总数t
idx
为:
[0026]
[0027]
按照上述每个线程先求解兰伯特问题再获取速度增量的步骤,待求解完成后,将t
idx
组速度增量进行从小带大排序,提取前bw个子序列,由此不断迭代,直至完成bw个长度为l的子序列,将其保存在数据库中。为了降低后续子序列生成的计算量,当完成子序列搜索后,将每个子序列的速度增量求和,设定相应的最大速度增量限制,剔除超出该限制的子序列。
[0028]
由于序列总长度n
flyby
大于子序列长度l,仅生成bw个长度为l的子序列不能满足任务指标。从现有数据库中提取每个子序列末端的目标、对应的到达速度,以及时刻;完成提取后,进行并行集束搜索,直至再次生成长度为l的子序列;因此,不断将上述过程进行迭代,直至出发时刻大于tf,完成子序列数据库的快速建立。基于并行集束搜索算法能快速建立飞越子序列数据库,离线生成数据库,并能指导多个飞越序列的生成。
[0029]
步骤三:通过在集束搜索算法中通过设置集束宽度,使步骤二构建的数据库中子序列在足够宽的集束宽度下进行拼接,有效避免飞越序列拼接过程中提前落入局部最优解,提高整个序列获取的最优性,待拼接完成后,挑选得到序列总速度增量最小的序列s1。
[0030]
飞越任务所需飞越的目标数目为n
flyby
,每个子序列的长度为l;因此,要实现对n
flyby
个目标进行飞越,则需要对ni个子序列进行拼接,其中ni为:
[0031][0032]
定义对子序列拼接的集束搜索宽度为b
w2
,首先从起始时刻开始搜索,将起始时刻对应的所有子序列从数据库中取出,计算每个子序列的总速度增量,根据总速度增量进行从小到达排序,选取前b
w2
个子序列;提取b
w2
个子序列的末端目标以及对应时刻,从数据库中提取该时刻对应的目标子序列,将此子序列与前者拼接,得到长度为2l-1的子序列,对得到的所有子序列进行总速度增量计算,然后对其进行从小到大排序,选取前b
w2
个子序列;根据上述方法不断迭代,完成对ni次子序列的拼接,挑选速度增量最小的完整序列s1。此步骤通过在集束搜索算法中设置集束宽度,使子序列在足够宽的集束宽度下进行拼接,有效避免序列拼接过程中提前落入局部最优解,提高整个序列获取的最优性。
[0033]
步骤四:通过构建双层优化策略,对步骤三得到的完整序列s1中每个目标与目标之间的转移时间进行调整及优化,以降低完整序列的总速度增量,进一步提高整个序列的最优性,得到总速度增量更低的飞越序列s2。
[0034]
通过双层优化策略,对步骤三得到的完整序列s1中每个目标与目标之间的转移时间进行调整,实现方法如下:内层优化:给定序列中任意两个相邻目标,固定序列中前者目标的飞越时刻,通过改变后者飞越时刻,重新计算整个序列所需的总速度增量;需要说明的是,改变后者的飞越时刻,会对前后两处的转移时间造成影响;外层优化:从航天器起始时刻开始,按顺序执行两两目标之间的内层优化,直至序列中最后一个目标;当完成整个序列的一轮外层优化后,记录当前序列所需的总速度增量。通过不断迭代上述外层优化与内层优化策略,当相邻两次外层优化的总速度增量值相差为0时,结束此优化步骤,得到总速度增量更低的飞越序列s2。
[0035]
步骤五:以每个目标的飞越速度作为待优化变量,序列的总速度增量作为优化目标,以飞越的相对速度条件作为约束条件,建立优化问题模型,通过非线性规划算法sqp,优化步骤四得到的序列s2中每个目标的飞越速度,进一步降低整个飞越过程的总速度增量,
提高整个序列的最优性,得到速度增量更小的飞越序列s3。
[0036]
在建立子序列数据库的过程中,速度增量的计算是通过比较兰伯特问题的到达速度与目标当前速度的相对速度大小是否满足飞越约束,如式(1);若兰伯特问题的到达速度与目标当前速度满足飞越条件,则不施加速度增量;若兰伯特问题到达速度与目标当前速度不满足飞越条件,则施加速度增量以调整飞越速度。通过式(1)计算末端速度增量,子序列数据库的建立具有较高的优化效率,但式(1)方法只考虑当前目标间飞越的最优性,缺乏考虑对后续飞越序列的影响,使得序列的总速度增量过大。
[0037]
本步骤以每个目标的飞越速度vi作为待优化变量,序列的总速度增量作为优化目标,以飞越的相对速度条件作为约束条件,建立优化问题模型,通过sqp优化算法优化序列s2中每个小行星处的飞越速度,获得总速度增量更小飞越序列s3。目标函数为:
[0038][0039]
约束条件为:
[0040][0041]
其中,为第i个目标的速度,vi为航天器飞越第i个目标的飞越速度,表示第i-1个目标到第i个目标经过兰伯特转移得到的到达速度,表示第i个目标到第i+1个目标经过兰伯特转移得到的出发速度,其中i=1,2,...,n
flyby
。
[0042]
通过非线性规划算法sqp对式(8)和(9)进行求解,能优化步骤四得到的序列s2中每个目标的飞越速度,进一步降低整个飞越过程的总速度增量,提高整个序列的最优性,得到速度增量更小的飞越序列s3,即基于并行架构实现空间大规模目标飞越的序列规划,并经优化得到速度更小的飞越序列。
[0043]
还包括步骤六:根据步骤五得到的优化后的速度增量更小的飞越序列s3,对航天器在对应时刻下施加相应速度增量,在给定的飞越窗口和飞越时刻的速度约束下,实现高精度低能耗的航天器飞越任务。
[0044]
有益效果:
[0045]
1、本发明公开的一种基于并行架构的空间大规模目标飞越的序列规划方法,通过构建并行集束搜索算法,有效提高大规模兰伯特问题的求解效率,快速建立飞越子序列数据库,在集束搜索算法中通过设置集束宽度,使数据库中子序列在足够宽的集束宽度下进行拼接,能有效避免飞越序列搜索过程中提前落入局部最优解,提高整个序列获取的最优性。
[0046]
2、本发明公开的一种基于并行架构的空间大规模目标飞越的序列规划方法,通过双层优化策略调整拼接后的完整序列各目标间转移时间,首先对序列中两相邻目标执行内层优化,调整目标间的转移时间以减小速度增量,再通过外层优化不断执行内层优化,迭代直至两次外层优化的总速度增量值相差为0时,得到速度增量更小的完整序列。双层优化策略通过优化目标间的转移时间以降低总速度增量,进一步提高整个序列的最优性。
[0047]
3、本发明公开的一种基于并行架构的空间大规模目标飞越的序列规划方法,以每个目标的飞越速度作为待优化变量,序列的总速度增量作为优化目标,以飞越的相对速度条件作为约束条件,建立优化问题模型,通过非线性规划算法sqp优化调整时间后序列的每
个目标的飞越速度,进一步降低整个飞越过程的总速度增量,提高整个序列的最优性。
[0048]
4、本发明公开的一种基于并行架构的空间大规模目标飞越的序列规划方法,给定所需的飞越目标数量及飞越时间窗口,在实现上述有益效果1、2、3的基础上,基于并行架构实现空间大规模目标飞越的序列规划,根据优化后飞越序列,对航天器在对应时刻下施加相应速度增量,在给定的飞越窗口和飞越时刻的速度约束下,实现高精度低能耗执行预定航天器飞越任务。本发明具有规划效率高、飞越序列规划最优性高的优点,
附图说明
[0049]
图1是实施例中飞越候选目标的分布情况。
[0050]
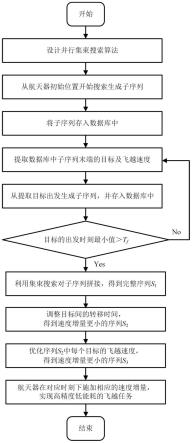
图2是本发明公开的一种基于并行架构的空间大规模目标飞越的序列规划方法流程图。
[0051]
图3是并行兰伯特算法的计算效率与普通串行计算效率对比。
[0052]
图4是经过兰伯特转移后,末端速度与目标速度的两种情况。
[0053]
图5是经过子序列拼接后得到的完整飞越序列轨迹。
[0054]
图6是对飞越速度优化变量定义示意图。
具体实施方式
[0055]
为了更好的说明本发明的目的和优点,下面结合附图和实例对发明内容做进一步说明。
[0056]
实施例1:
[0057]
本实施例公开对小行星飞越任务的最优速度增量飞越序列获取,针对任务提供的大规模候选目标问题,生成一个使序列总速度增量最优的飞越序列,同时满足飞越的相对速度约束、飞越时间窗口约束。
[0058]
本实施例的候选目标是从第11届国际空间轨道设计竞赛方提供的质量前10000个小行星中进行选取,其中10000个待选小行星的分布情况如图1所示;任务目的是在给定时间窗口下,以最小的速度增量从中选取33个小行星进行飞越,飞越时间窗口为16年,任务起始时间为96030mjd,飞越的相对速度约束为2km/s,任务目标是使序列的总速度增量最小。
[0059]
如图2所示,本实施例公开的大规模小行星飞越的序列规划方法实施步骤流程图,具体步骤所用方法如下:
[0060]
步骤一:将兰伯特问题求解并行化,利用cuda和gpu并行计算平台,在每个线程上建立兰伯特问题的求解,即每个线程都能针对不同的输入,然后求解对应的兰伯特问题,输出相应的结果,计算过程同步进行。针对每个线程中的兰伯特问题,其输入量包括转移时间tf、初始位置r0、终端期望位置ra,输出量包括初始位置所对应的速度终端期望位置对应的速度如图3所示,将建立后的并行兰伯特问题求解效率与串行算法对比,两种算法的计算都在个人计算机上进行,配置为:intel core i9-10900x 3.70ghz cpu,32gb ram,nvidia geforce rtx 2080ti gpu。从图3中可看出,针对大规模兰伯特问题的求解,并行效率远高于串行效率;如:对50
×
106个兰伯特问题进行求解,并行兰伯特算法耗时约1.5s,而直接将兰伯特问题建立在cpu上求解将会耗时250s。
[0061]
在兰伯特问题求解后,需要计算目标间转移的总速度增量,其中包括在起始位置应施加的速度增量和飞越时刻的速度增量,起始位置施加速度增量为其大小为到达的速度增量的两种情况如图4所示,通过将δv
l
=2给式(1)赋值,式(1)具体化为式(10),到达速度增量矢量将可由下式分段函数进行计算:
[0062][0063]
完成上述速度增量计算后,将并行计算框架中的计算结果传回cpu中,设置超参数bw=2000,仅保留前2000个较优的结点以减少搜索所占用的空间和时间,提高求解效率。
[0064]
步骤二:基于上述并行集束搜索算法,建立小行星飞越子序列数据库,其中子序列数据库包括从地球出发到小行星的子序列,小行星到小行星转移的子序列。
[0065]
首先从航天器起始时刻t0对应的位置及速度r0,v0出发,建立从地球出发到小行星的子序列,子序列长度为2。本实施例中,航天器从地球出发,出发时刻为t0=96030mjd,根据开普勒公式可得出航天器出发时刻的位置及速度;利用步骤1中的并行集束搜索算法进行计算,输入量包括转移时间tf,其中转移时间最大值天,最小值天,离散间隔天,还包括在t0+tf时刻10000个目标对应的位置、速度,则应求解的兰伯特问题总数为:
[0066][0067]
因此,完成该兰伯特计算后,计算各自的速度增量,并给定速度增量幅值3.0km/s,提取前bw=2000个子序列,将满足此约束的子序列存到数据库中。在完成地球到小行星子序列计算后,下一步将计算小行星到小行星的子序列;在本实施例中,小行星到小行星的序列长度设为3,子序列速度增量约束幅值为1.1km/s,转移时间最大值天,最小值天,离散间隔天。
[0068]
提取数据库中地球到小行星子序列的末端目标及对应的飞越速度,从此目标和对应的飞越速度出发,利用2次并行集束搜索算法,生成长度为3的子序列,子序列包含的要素包括:目标编号、飞越时刻、飞越速度、以及从上一个目标到当前目标的速度增量;子序列的保存方式如下表所示:
[0069]
表1长度为3的子序列保存方式
[0070][0071]
完成子序列搜索后,计算该子序列的总速度增量,若小于约束幅值1.1km/s,则保存到数据库中。通过此步骤反复迭代,最终建成子序列数据库。
[0072]
步骤三:将子序列数据库中的子序列进行拼接,利用集束搜索算法选择速度增量最优的飞越序列。
[0073]
飞越任务所需飞越的目标数目为n
flyby
=33,其中,地球到小行星序列长度为2,而小行星之间的序列长度为3;而子序列的初始目标和速度是对应已有子序列的末端目标和速度,因此,经过一次序列拼接后,序列长度增加2;要实现对33个目标进行飞越,则需要对17个子序列进行拼接。对子序列拼接的集束搜索宽度设为b
w2
=30000,首先从起始时刻开始搜索,将起始时刻对应的所有子序列从数据库中取出,计算每个子序列的总速度增量,根据总速度增量进行从小到大排序,选取前b
w2
个子序列;根据序列拼接后总速度增量的大小进行筛选、不断迭代,完成对子序列的拼接,最后挑选一条速度增量最小的完整序列s1,s1对应的三维轨迹如图5所示。
[0074]
步骤四:对步骤三得到的完整序列s1中每个目标与目标之间的转移时间进行调整,其中s1中33个小行星的飞越时刻以及小行星间的速度增量如表2所示。构造一种序列目标转移时间调整的双层优化策略,优化目标间的转移时间以降低总速度增量,得到新的飞越序列s2,其中s2的飞越时刻与表2中s3相同。
[0075]
表2序列s1和s3记录表
[0076][0077]
步骤五:通过sqp优化算法优化序列s2中每个小行星处的飞越速度,获得新的飞越
序列s3。各目标的飞越速度、兰伯特转移速度、目标速度的变量定义如图6所示。根据式(8)和式(9)构建的优化问题,利用非线性规划算法进行优化,进一步降低总速度增量;优化后目标与目标之间的速度增量如表2中飞越序列s3所示。该步骤不改变飞越时刻,通过优化飞越速度以降低序列总速度增量。
[0078]
在上述面向大规模目标飞越的序列规划方法下,针对大规模可选目标情况,子序列数据库的建立能有效提高序列获取的最优性,同时依托于并行集束搜索算法,子序列数据库能快速生成;通过集束搜索算法,将数据库中子序列进行拼接,得到完整的飞越序列轨迹;最后通过调整飞越时刻以及优化飞越速度,进一步降低总速度增量。
[0079]
以上所述的具体描述,对发明的目的、技术方案和有益效果进行进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施例而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1