一种机关公文字体类别判别方法及系统与流程
1.本发明涉及语言识别领域,具体涉及一种机关公文字体类别判别方法及系统。
背景技术:
2.机关公文是国家党、政、军在行政管理中具有法定效力和规范体式的文书,公文质量高低是行政管理水平和工作作风,是机关业务考核的重要指标。机关公文质量的一个重要的指标就是公文字体是否符合国家标准规范,比如标题应为小标宋体,一级用黑体字、二级标题用楷体字、三级和四级标题用仿宋体字,版头、版记各要素也有各自字体规定。在机关业务考核时,面对纸质、扫描版或pdf版的机关公文字体是否符合规范,要靠人工经验判断,容易将相近样式的字体混淆,且当需要考评的公文量大时,就费时费力。
技术实现要素:
3.本发明实施例提供一种机关公文字体类别判别方法及系统,字体识别基于图像处理,能够识别各种类型的文件,速度和精准度更高。
4.为达上述目的,一方面,本发明实施例提供一种机关公文字体类别判别方法,包括:
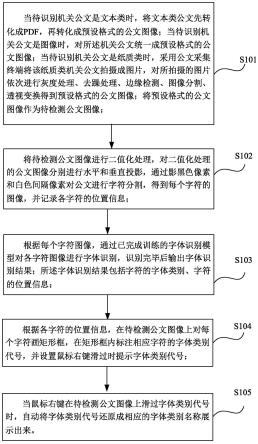
5.当待识别机关公文是文本类时,将文本类公文先转化成pdf,再转化成预设格式的公文图像;当待识别机关公文是图像时,对所述机关公文统一成预设格式的公文图像;当待识别机关公文是纸质类时,采用公文采集终端将该纸质类机关公文拍摄成图片,对所拍摄的图片依次进行灰度处理、去躁处理、边缘检测、图像分割、透视变换得到预设格式的公文图像;将预设格式的公文图像作为待检测公文图像;
6.将待检测公文图像进行二值化处理,对二值化处理的公文图像分别进行水平和垂直投影,通过影黑色像素和白色间隔像素对公文进行字符分割,得到每个字符的图像,并记录各字符的位置信息;
7.根据每个字符图像,通过已完成训练的字体识别模型对各字符图像进行字体识别,识别完毕后输出字体识别结果;所述字体识别结果包括字符的字体类别、字符的位置信息;
8.根据各字符的位置信息,在待检测公文图像上对每个字符画矩形框,在矩形框内标注相应字符的字体类别代号,并设置鼠标右键滑过时提示字体类别代号;
9.当鼠标右键在待检测公文图像上滑过字体类别代号时,自动将字体类别代号还原成相应的字体类别名称展示出来。
10.另一方面,本发明实施例提供一种机关公文字体类别判别系统,包括:
11.公文预处理单元,用于当待识别机关公文是文本类时,将文本类公文先转化成pdf,再转化成预设格式的公文图像;当待识别机关公文是图像时,对所述机关公文统一成预设格式的公文图像;当待识别机关公文是纸质类时,采用公文采集终端将该纸质类机关公文拍摄成图片,对所拍摄的图片依次进行灰度处理、去躁处理、边缘检测、图像分割、透视
变换得到预设格式的公文图像;将预设格式的公文图像作为待检测公文图像;
12.公文分割单元,用于将待检测公文图像进行二值化处理,对二值化处理的公文图像分别进行水平和垂直投影,通过影黑色像素和白色间隔像素对公文进行字符分割,得到每个字符的图像,并记录各字符的位置信息;
13.字符类别识别单元,用于根据每个字符图像,通过已完成训练的字体识别模型对各字符图像进行字体识别,识别完毕后输出字体识别结果;所述字体识别结果包括字符的字体类别、字符的位置信息;
14.字符类别标注单元,用于根据各字符的位置信息,在待检测公文图像上对每个字符画矩形框,在矩形框内标注相应字符的字体类别代号,并设置鼠标右键滑过时提示字体类别代号;
15.显示单元,用于当鼠标右键在待检测公文图像上滑过字体类别代号时,自动将字体类别代号还原成相应的字体类别名称展示出来。
16.上述技术方案具有如下有益效果:字体识别基于图像处理,能够识别各种类型的文件,速度和精准度更高。
附图说明
17.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
18.图1是本发明实施例的机关公文字体类别判别方法的流程图;
19.图2是本发明实施例的机关公文字体类别判别系统的结构图;
20.图3是本发明实施例的总体结构图;
21.图4本发明实施例的公文采集模块结构图;
22.图5本发明实施例的字体识别模型训练指标统计图;
23.图6本发明实施例的字体识别模型测试结果图;
24.图7本发明实施例的公文字体识别效果图。
具体实施方式
25.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
26.如图1所示,结合本发明的实施例,提供一种机关公文字体类别判别方法,包括:
27.s101:当待识别机关公文是文本类时,将文本类公文先转化成pdf,再转化成预设格式的公文图像;当待识别机关公文是图像时,对所述机关公文统一成预设格式的公文图像;当待识别机关公文是纸质类时,采用公文采集终端将该纸质类机关公文拍摄成图片,对所拍摄的图片依次进行灰度处理、去躁处理、边缘检测、图像分割、透视变换得到预设格式的公文图像;将预设格式的公文图像作为待检测公文图像;
28.s102:将待检测公文图像进行二值化处理,对二值化处理的公文图像分别进行水平和垂直投影,通过影黑色像素和白色间隔像素对公文进行字符分割,得到每个字符的图像,并记录各字符的位置信息;
29.s103:根据每个字符图像,通过已完成训练的字体识别模型对各字符图像进行字体识别,识别完毕后输出字体识别结果;所述字体识别结果包括字符的字体类别、字符的位置信息;
30.s104:根据各字符的位置信息,在待检测公文图像上对每个字符画矩形框,在矩形框内标注相应字符的字体类别代号,并设置鼠标右键滑过时提示字体类别代号;
31.s105:当鼠标右键在待检测公文图像上滑过字体类别代号时,自动将字体类别代号还原成相应的字体类别名称展示出来。
32.优选地,步骤101,当待识别机关公文是纸质类时,采用公文采集终端将该纸质类机关公文拍摄成图片,对所拍摄的图片依次进行灰度处理、去躁处理、边缘检测、图像分割、透视变换得到预设格式的公文图像;将预设格式的公文图像作为待检测公文图像,具体包括:
33.高清摄像头根据所收集到的图像采集指令自动拍摄待识别纸质类机关公文,输出该待识别纸质类机关公文的原始图像p;
34.创建原始公文图像p的副本p1,对p1进行灰度处理;在灰度处理完毕之后采用高斯模糊过滤掉噪声得到原始公文图像p的边缘图像e;具体为:
35.使用sobel过滤器确定p1边缘的梯度g(x,y)和方向θm;其中,g
x
为垂直边缘,是指梯度在x方向上的突变,gy为水平边缘,是指梯度在y方向上的突变;在梯度方向对梯度幅值进行非极大值抑制,针对p1的每个像素点i,在3*3区域内沿0
°
、45
°
、90
°
、135
°
四个类型的梯度方向,比较周围8个邻域值的大小,如果像素i为最大值,则保留该像素点,否则置0;结合双阈值算法检测和连接边缘,得到原始公文图像p的边缘图像e;
36.创建e的副本e1,获取e1中的边缘闭合轮廓集合,自边缘闭合轮廓集合中确定四边形边缘,将四边形边缘做为原始公文图像p的边缘;以及根据四边形边缘的位置信息自原始公文图像p中分割出目标公文图像;
37.通过4个顶点坐标将目标公文图像映射成标准公文的a4纸张大小比例的图像,通过透视变换将目标公文图像的每个文字校正成视觉上比例协调的样式,校正后形成预设格式的公文图像。
38.优选地,步骤102,将待检测公文图像进行二值化处理,对二值化处理的公文图像分别进行水平和垂直投影,通过影黑色像素和白色间隔像素对公文进行字符分割,得到每个字符的图像,具体包括:
39.将待检测公文图像进行二值化处理得到二值化公文图;将二值化公文图像在y轴上进行水平投影,获取每一行的二值图,对每一行的二值图在x轴上进行垂直投影,对投影得到的黑色像素和白色间隔像素来判断待检测公文图像内的每个字符的开始位置和结束位置、以及根据每个字符的开始位置和结束位置取得字符的位置坐标;
40.根据每个字符位置坐标在待检测公文图像内为各字符画出分割矩形框,通过矩形框对字符进行分割,得到每个字符的图像和位置,同时对每个字符图像以预设形式编号,记录各字符的编号和相应的字符位置信息。
41.优选地,步骤103,根据每个字符图像,通过已完成训练的字体识别模型对各字符图像进行字体识别,识别完毕后输出字体识别结果,具体包括:
42.将每个字符图像输入已完成训练的字体识别模型,通过骨干网络backbone的focus对每个字符图像切片分别得到4个同等大小的子图像;通过concat将各子图像的宽高整合,将输入图像的通道数量增加到64;利用conv卷积块对concat整合后的子图像采取卷积核为3、步长为2的卷积操作,输出第一特征图像;将第一特征图像经过3次bottleneckcsp模块及conv卷积块输出后,变成第二特征图像;通过ssp模块将第二特征图像以四种比例分别进行最大池化运算;通过concat连接层将池化结果进行整合,通过颈部neck和头部head的14层网络对整合的池化结果进行卷积和连结运算,输出每个字符的字体类别,识别完毕后输出字体识别结果;
43.步骤103,根据各字符的位置信息,在待检测公文图像上对每个字符画矩形框,在矩形框内标注相应字符的字体类别代号,并设置鼠标右键滑过时提示字体类别代号,具体包括:
44.使用python cv2包的rectangle()函数,根据每个字符的位置信息在待检测公文图像内各字符画出字体位置矩形框;使用matplotlib包调用plt.text(x,y,s)函数标在字符位置矩形框内标注字体类别代号,其中,x、y分别为字符位置矩形框中点的横坐标、纵坐标,s为该字符的字体类别代号,并设置在鼠标右键滑过该字符位置矩形框时根据字体类别代码显示字体类别代号。
45.优选地,s106,采用如下方法训练字体识别模型:
46.获取将机关公文所用的中文单个汉字、阿拉伯数字、标点符号、数学符号,分别按照机关公文所用的字体类别分别采用矩形框制作字体样本图片,所述字体样本图片背景色为纯白色,文字颜色为黑色,字体样式不加粗;每张字体样本图片包含一个汉字、数字或符号;其中,所用的字体类别包括至少如下之一:方正小标宋简体、仿宋、仿宋_gb2312、黑体、楷体、楷体_gb2312、宋体;
47.使用labelimg标注软件将每个字体样本图片内的字符类别采用字符类别代号标注,输出txt格式的label标注结果文件;每个label标注结果文件对应其同名的字体样本图片;将每个label标注结果文件和其同名的字体样本图片作为数据集,将数据集分为数训练集和验证集;其中,每个标注结果文件内的数据包括:cls,x,y,w,h,其中,cls为字体类别,x、y分别为矩形框中心点的横、纵坐标,w、h为矩形框的宽度值、高度值;
48.对字体识别模型的配置,将字体识别模型深度控制参数depth_multiple设置为0.33、宽度控制参数width_multiple设置为0.50;在8、18、32倍下采样下3个先验框大小分别设置为(10,13)、(16,30)、(33,23),(30,61)、(62,45)、(59,119),(116,90)、(156,198)、(373,326),权重文件设置为yolov5s.pt;在数据配置文件voc.yaml中设置类别数量为7,按照字体类别代号设置字体类别名称,配置字体识别模型的训练集和验证集的地址;
49.针对训练集,将机关公文图像分割成单字图像,将各单字图像调整成预设大小输入yolov5模型;所述yolov5模型包括骨干网络backbone、颈部neck和头部head;骨干网络backbone包括focus、concat、conv卷积块、ssp、bottleneckcsp;
50.通过focus对各单字图像切片分别得到4个同等大小的子图像;通过concat将子图像的宽高整合,将输入图像的通道数量增加到64;利用conv卷积块对concat整合后的子图
像采取卷积核为3、步长为2的卷积操作,输出第一特征图像;将第一特征图像经过3次bottleneckcsp模块及conv卷积块输出后,变成第二特征图像;通过ssp模块将第二特征图像以四种比例分别进行最大池化运算;通过concat连接层将池化结果进行整合,通过颈部neck和头部head的14层网络对整合的池化结果进行卷积和连结运算,输出单字边框和字体类别;
51.并采用验证集进行验证,得到已训练完成的字体识别模型。
52.如图2所示,结合本发明的实施例,提供一种机关公文字体类别判别系统,包括:
53.公文预处理单元21,用于当待识别机关公文是文本类时,将文本类公文先转化成pdf,再转化成预设格式的公文图像;当待识别机关公文是图像时,对所述机关公文统一成预设格式的公文图像;当待识别机关公文是纸质类时,采用公文采集终端将该纸质类机关公文拍摄成图片,对所拍摄的图片依次进行灰度处理、去躁处理、边缘检测、图像分割、透视变换得到预设格式的公文图像;将预设格式的公文图像作为待检测公文图像;
54.公文分割单元22,用于将待检测公文图像进行二值化处理,对二值化处理的公文图像分别进行水平和垂直投影,通过影黑色像素和白色间隔像素对公文进行字符分割,得到每个字符的图像,并记录各字符的位置信息;
55.字符类别识别单元23,用于根据每个字符图像,通过已完成训练的字体识别模型对各字符图像进行字体识别,识别完毕后输出字体识别结果;所述字体识别结果包括字符的字体类别、字符的位置信息;
56.字符类别标注单元24,用于根据各字符的位置信息,在待检测公文图像上对每个字符画矩形框,在矩形框内标注相应字符的字体类别代号,并设置鼠标右键滑过时提示字体类别代号;
57.显示单元25,用于当鼠标右键在待检测公文图像上滑过字体类别代号时,自动将字体类别代号还原成相应的字体类别名称展示出来。
58.优选地,所述公文预处理单元21包括纸质类机关公文预处理子单元211,所述纸质类机关公文预处理子单元211,具体用于:
59.高清摄像头根据所收集到的图像采集指令自动拍摄待识别纸质类机关公文,输出该待识别纸质类机关公文的原始图像p;
60.创建原始公文图像p的副本p1,对p1进行灰度处理;在灰度处理完毕之后采用高斯模糊过滤掉噪声得到原始公文图像p的边缘图像e;具体为:
61.使用sobel过滤器确定p1边缘的梯度g(x,y)和方向θm;其中,g
x
为垂直边缘,是指梯度在x方向上的突变,gy为水平边缘,是指梯度在y方向上的突变;在梯度方向对梯度幅值进行非极大值抑制,针对p1的每个像素点i,在3*3区域内沿0
°
、45
°
、90
°
、135
°
四个类型的梯度方向,比较周围8个邻域值的大小,如果像素i为最大值,则保留该像素点,否则置0;结合双阈值算法检测和连接边缘,得到原始公文图像p的边缘图像e;
62.创建e的副本e1,获取e1中的边缘闭合轮廓集合,自边缘闭合轮廓集合中确定四边形边缘,将四边形边缘做为原始公文图像p的边缘;以及根据四边形边缘的位置信息自原始公文图像p中分割出目标公文图像;
63.通过4个顶点坐标将目标公文图像映射成标准公文的a4纸张大小比例的图像,通过透视变换将目标公文图像的每个文字校正成视觉上比例协调的样式,校正后形成预设格
式的公文图像。
64.优选地,所述公文分割单元22,具体用于:
65.将待检测公文图像进行二值化处理得到二值化公文图;将二值化公文图像在y轴上进行水平投影,获取每一行的二值图,对每一行的二值图在x轴上进行垂直投影,对投影得到的黑色像素和白色间隔像素来判断待检测公文图像内的每个字符的开始位置和结束位置、以及根据每个字符的开始位置和结束位置取得字符的位置坐标;
66.根据每个字符位置坐标在待检测公文图像内为各字符画出分割矩形框,通过矩形框对字符进行分割,得到每个字符的图像和位置,同时对每个字符图像以预设形式编号,记录各字符的编号和相应的字符位置信息。
67.优选地,所述字符类别识别单元23,具体用于:
68.将每个字符图像输入已完成训练的字体识别模型,通过骨干网络backbone的focus对每个字符图像切片分别得到4个同等大小的子图像;通过concat将各子图像的宽高整合,将输入图像的通道数量增加到64;利用conv卷积块对concat整合后的子图像采取卷积核为3、步长为2的卷积操作,输出第一特征图像;将第一特征图像经过3次bottleneckcsp模块及conv卷积块输出后,变成第二特征图像;通过ssp模块将第二特征图像以四种比例分别进行最大池化运算;通过concat连接层将池化结果进行整合,通过颈部neck和头部head的14层网络对整合的池化结果进行卷积和连结运算,输出每个字符的字体类别,识别完毕后输出字体识别结果;
69.所述字符类别标注单元24,具体用于:
70.使用python cv2包的rectangle()函数,根据每个字符的位置信息在待检测公文图像内各字符画出字体位置矩形框;使用matplotlib包调用plt.text(x,y,s)函数标在字符位置矩形框内标注字体类别代号,其中,x、y分别为字符位置矩形框中点的横坐标、纵坐标,s为该字符的字体类别代号,并设置在鼠标右键滑过该字符位置矩形框时根据字体类别代码显示字体类别代号。
71.优选地,还包括字体识别模型训练单元26,所述字体识别模型训练单元26,包括:
72.获取将机关公文所用的中文单个汉字、阿拉伯数字、标点符号、数学符号,分别按照机关公文所用的字体类别分别采用矩形框制作字体样本图片,所述字体样本图片背景色为纯白色,文字颜色为黑色,字体样式不加粗;每张字体样本图片包含一个汉字、数字或符号;其中,所用的字体类别包括至少如下之一:方正小标宋简体、仿宋、仿宋_gb2312、黑体、楷体、楷体_gb2312、宋体;
73.使用labelimg标注软件将每个字体样本图片内的字符类别采用字符类别代号标注,输出txt格式的label标注结果文件;每个label标注结果文件对应其同名的字体样本图片;将每个label标注结果文件和其同名的字体样本图片作为数据集,将数据集分为数训练集和验证集;其中,每个标注结果文件内的数据包括:cls,x,y,w,h,其中,cls为字体类别,x、y分别为矩形框中心点的横、纵坐标,w、h为矩形框的宽度值、高度值;
74.对字体识别模型的配置,将字体识别模型深度控制参数depth_multiple设置为0.33、宽度控制参数width_multiple设置为0.50;在8、18、32倍下采样下3个先验框大小分别设置为(10,13)、(16,30)、(33,23),(30,61)、(62,45)、(59,119),(116,90)、(156,198)、(373,326),权重文件设置为yolov5s.pt;在数据配置文件voc.yaml中设置类别数量为7,按
照字体类别代号设置字体类别名称,配置字体识别模型的训练集和验证集的地址;
75.针对训练集,将机关公文图像分割成单字图像,将各单字图像调整成预设大小输入yolov5模型;所述yolov5模型包括骨干网络backbone、颈部neck和头部head;骨干网络backbone包括focus、concat、conv卷积块、ssp、bottleneckcsp;
76.通过focus对各单字图像切片分别得到4个同等大小的子图像;通过concat将子图像的宽高整合,将输入图像的通道数量增加到64;利用conv卷积块对concat整合后的子图像采取卷积核为3、步长为2的卷积操作,输出第一特征图像;将第一特征图像经过3次bottleneckcsp模块及conv卷积块输出后,变成第二特征图像;通过ssp模块将第二特征图像以四种比例分别进行最大池化运算;通过concat连接层将池化结果进行整合,通过颈部neck和头部head的14层网络对整合的池化结果进行卷积和连结运算,输出单字边框和字体类别;
77.并采用验证集进行验证,得到已训练完成的字体识别模型。
78.下面结合具体的应用实例对本发明实施例上述技术方案进行详细说明,实施过程中没有介绍到的技术细节,可以参考前文的相关描述。
79.一种基于图像处理技术的机关公文字体判别方法及装置,涉及自然语言处理和计算机器视觉领域,主要用于党、政、军等机关公文质量考核评价。
80.本发明针对机关公文质量考核评价时,人工判定、逐字核对各要素字体是否正确费时费力,相近样式的字体易混淆,使用机器解析读取字体,又面临纸质类,扫描、pdf等主体图像类公文无法判别的情况,能够快速高效判定机关公文字体,为辅助机关公文质量考核评价提供一种高效解决方案。其中,机关公文:是指国家行政机关公文格式,符合中华人民共和国国家标准gb-t 9704-2012规定。
81.本发明根据每种字体细节图像特征的特点,基于图像的深度学习目标检测方法进行字体判别,分为公文采集终端、中心处理系统、显示判读终端3部分,如图3所示。
82.1.公文采集终端
83.由图像采集模块、文档导入接口、识别转换模块3部分组成,结构如图4所示。
84.(1)图像采集模块:设置高清摄像头1个,分辨率:不低于1080p(1920*1080),视频压缩方式:motion-jpeg,信号系统:pal或ntsc,帧频率:大于25fps,接口:usb3.0高速接口,免驱驱动;图像采集模块收到图像采集指令后,自动拍摄纸质类公文,输出1920*1080原始图像。
85.(2)文档导入接口:配置usb数据接口,对于doc、docx、wps等电子文档类公文和bmp、jpg、png、titf等扫描、翻拍的图像类公文,实现数据直接导入。
86.(3)识别转换模块:接收到图像采集模块拍摄的原始公文图像p后,创建p副本p1,而后对p1进行灰度处理,来去掉图像色彩,对灰度处理计算方法如公式(1):
[0087][0088]
其中,f(x,y)为灰度处理后的图像,r(x,y)、g(x,y)、b(x,y)表示该处的r、g、b值。
[0089]
而后对图像p1进行高斯模糊过滤掉噪声以便更精确地边缘图像e。具体为:使用sobel过滤器确定图像p1边缘的梯度g(x,y)和方向θm,定义如公式(2)(3)。其中,g
x
为垂直边缘,是指梯度在x方向上的突变,gy为水平边缘,是指梯度在y方向上的突变。
[0090][0091][0092]
而后在梯度方向对梯度幅值进行非极大值抑制,对原始公文图像p1每个像素点i,对在3*3区域内,沿0
°
,45
°
,90
°
,135
°
四个类型的梯度方向,比较周围8个邻域值的大小,如果像素i为最大值,则保留该像素点,否则置0,这样进行非极大值抑制,最后使用双阈值算法检测和连接边缘,得到原始公文图像p的边缘图像e。
[0093]
创建e的副本e1,从e1中找到边缘闭合轮廓集合,从轮廓集合中找出四边形边缘,确定为原始公文图像p的边缘,再通过四边形边缘位置信息,从原始公文图像p中分割出目标公文图像。
[0094]
将目标公文图像,通过4个顶点坐标,映射成标准公文的a4纸张大小比例图像,分辨率为1120*790,而后进行透视变换,透视变换方法如公式(4)。
[0095][0096]
其中,公式右侧3*3矩阵为映射矩阵,从opencv库中获取,x,y是透视变换前目标公文图像的坐标。透视变换后的图像定义如公式(5)。
[0097][0098]
将透视变换的图像f
t
(x,y)另存为jpeg格式,作为纸质公文的待检测图像。在拍摄纸质公文图像时,由于角度不正,导致图像变形,透视变换的目的是使变形图像重新矫正成a4大小的图像。
[0099]
识别转换模块接收到从文档导入接口,导入的doc、docx、wps等文档类的公文先转化成pdf,再转化成分辨率为1120*790的jpeg格式图像待下步处理;其中,对bmp、jpg、png、titf等扫描、翻拍的图像类公文,也统一转化成分辨率为1120*790的jpeg格式图像待下步处理。
[0100]
2.中心处理系统
[0101]
(1)字体识别模型构建。字体识别模型依托yolov5模型构建。yolov5模型是在yolov3模型基础上改进而来的,基于pytorch框架,更易于在实际中配置使用,且训练速度更快,精准度更高,对象识别速度达140fps。字体识别模型由骨干网络backbone、颈部neck和头部head三部分组成。
[0102]
骨干网络backbone包括focus、conv卷积块、ssp、bottleneckcsp等模块,模型识别公文字体时,首先将分辨率为1120*790的公文图像,分割成单字图像,再把每个单字图像调整成640*640大小输入模型。模型通过focus进行单字图像切片,将单字图像调整成4个大小为320*320的子图像,再通过concat将子图像的宽高整合,把输入图像的通道数量增加到64。对concat整合的图像,利用conv卷积块采取卷积核为3,步长为2的卷积操作,输出结果为160*160*128的特征图像,而后特征图像经过3次bottleneckcsp模块及conv卷积块输出后,变成20*20*1024的图像。ssp模块再对20*20图像,分1*1、5*5、9*9、13*13四组进行最大
池化运算,以提高模型精准度,最后用concat连接层将池化结果整合到一起,由颈部neck和头部head的14层网络进行卷积和连结运算,输出单字边框和字体类别。
[0103]
模型损失计算的主要衡量指标—矩形框损失,用ciou计算,定义如公式(6)。
[0104][0105]
在公式(6)中,ρ2(b,b
gt
)是预测和真实两个矩形框中点之间的几何距离,c是涵盖预测和真实框最小外框减去预测、真实框的并集,iou是预测和真实框的交并比,v是预测和真实框长宽的切合程度,定义如公式(7)。
[0106][0107]
α是调节参数,定义如公式(8)。
[0108][0109]
(2)字体识别模型训练。模型构建完成后,开始制作训练集,对模型进行训练。
[0110]
step1.数据集制作。将公文拟制常用的中文单个汉字、阿拉伯数字、标点符号、数学符号等全部收集起来,分别按照机关公文常用到的方正小标宋简体、仿宋、仿宋_gb2312、黑体、楷体、楷体_gb2312、宋体7类字体,分别制作字体正方形样本图片,分辨率不低于32*32,每张字体样本图片只包含一个汉字、数字或符号,背景色为纯白色,文字颜色为黑色,字体样式不加粗。
[0111]
step2.样本标注。使用labelimg标注软件,对每个字体样本图片进行标注,输出格式为yolo格式,方正小标宋简体、仿宋、仿宋_gb2312、黑体、楷体、楷体_gb2312、宋体7类字体类别代号分别记为:"xiaobiaosong","fangsong","fangsong_gb","heiti","kaiti","kaiti_gb","songti",标注完成后输出txt格式的label文件,每个txt格式的标注结果文件,对应1个同名的样本图片。标注结果文件数据存储格式为:cls,x,y,w,h,其中,cls为目标类别,x、y为标注框中心点的横、纵坐标,w、h为标注框的宽、高值。
[0112]
step3.模型配置。模型类型选择为低复杂度的yolov5s,模型深度控制参数depth_multiple设置为0.33,模型宽度控制参数width_multiple设置为0.50。在8、18、32倍下采样下3个先验框大小分别设置为(10,13)、(16,30)、(33,23),(30,61)、(62,45)、(59,119),(116,90)、(156,198)、(373,326),权重文件设置为yolov5s.pt。在数据配置文件voc.yaml中设置类别数量为7,按照字体类别代号设置类别名称,配置模型的数据集和验证集文件地址。
[0113]
step4.模型训练。模型配置完成后,将数据样本输入模型中进行训练。考虑到数据集规模总体较少,将样本图片和标注结果均按照8:2划分成训练集和验证集,每个文件以文件名对应关联,将样本图片和样本标注结果分别存储在images、labels文件夹中。在images、labels文件夹下均新建1个train文件夹和1个val文件夹,分别存放各自验证集和训练集。
[0114]
启动模型训练,待模型训练完成后,开始公文字体识别。
[0115]
(3)公文单字分割。在公文字体识别前,需将公文分割成单个文字图像。分割首先对待识别公文图像进行二值化处理,而后对待识别公文图像(二值化图像)在y轴上进行水
平投影,获取每一行的二值图,然后对每一行的二值图在x轴上的进行垂直投影,最后通过投影黑色像素和白色间隔像素数量的统计,判断出每个字符的开始和结束的位置,进而取得单个字符的位置坐标,画出矩形框,进行字符分割,并记录该字符的编号和位置信息。
[0116]
(4)字体判别。将分割后的单个文字图像输入模型,获取字体识别结果和位置信息。
[0117]
3.显示判读终端
[0118]
根据字体识别结果和单个字符的位置信息,通过python cv2包的rectangle()函数在待识别图像上对每个字符画框(字体位置矩形框),并标记识别的字体类别代号,设置右键字体名称辅助提示,当鼠标右键滑过字体标记信息时,自动将字体类别代号还原成“方正小标宋简体、仿宋、仿宋_gb2312、黑体、楷体、楷体_gb2312、宋体”的原始字体名称,便于公文考评人员判读。
[0119]
本发明所取得的有益效果如下:
[0120]
本发明字体识别基于图像处理技术进行,克服传统文本处理技术判读字体时无法处理纸质类的扫描、照片、pdf等图像类公文的局限;用机器自动判别代替人工逐字核对,避免了相近和易混淆字体的错判误判,速度和精准度更高,提升了机关公文质量考核的效率。本发明效果不限于公文字体识别,也可帮助用户在图文设计、多媒体制作时,通过字体效果图像识别字体类别,进而为精准查找字体,进行高效创作打下基础。
[0121]
本实施例以常用公文涉及的方正小标宋简体、仿宋、仿宋_gb2312、黑体、楷体、楷体_gb2312、宋体7类字体为例。实验环境:windows 10操作环境,python3.9.7编程语言,anaconda3包管理器和环境管理器,cpu:intel(r)core(tm)i7-10875h,显卡:nvidia geforce rtx 2070,内存:32g。
[0122]
1.首先对纸质类公文,公文采集终端通过拍摄、边缘检测、图像分割、透视变换等操作,转换成jpeg格式图像待下步处理;对doc、docx、wps等电子文档类公文,先转化成pdf,再转化成jpeg图像格式待下步处理;对bmp、jpg、png、titf等扫描、翻拍的图像格式公文,统一转化成jpeg图像格式待下步处理。
[0123]
2.对字体识别模型训练数据集进行构建,收集公文常用的字符7889个,存放在1个docx文档中,然后将该文档复制7份,分别以7个字体名称命名,文档中所有字符字体设置为文档名称对应的字体。将这7个docx文档页面大小均设置成宽5cm、高5cm、白色背景、页边距均为0.5cm,字体大小为100、黑色、不加粗,使每个页面刚好只有1个字。
[0124]
3.使用python语言win32com模块的client包下函数,打开字符集文档,使用exportasfixedformat()函数将doc文档转化为pdf格式文档,再使用fitz模块打开pdf文档,获取文档的每个页面图像导出,图像名称为“字体名称+页码”,格式为jpeg,分辨率大小为189*189。
[0125]
鉴于字符样本数量较多,为提升样本训练速度,且使样本文字接近真实文字大小,将189*189大小的页面图像等比压缩成30*30大小。标注时考虑到人工标注费时费力,且标注目标单一、大小固定,遂采取程序自动生成样本方法,参照labelimg标注软件的输出xml格式,将《folder》《filename》《path》《source》《size》等属性标签按照样本图片属性信息写入,样本图片中的字符左上、右上坐标分别按照(5,5)(25,25)设置,批量生成xml标注格式的标注文件,再批量转换成yolo格式的标注结果文件。
[0126]
4.将7类55223个字体样本图片、7类55223个yolo格式的标注结果文件,分别存放在同一目录下,每个目录下按照43563个文件组成训练集,11660个文件组成验证集,样本图片名和标注结果文件名一一对应。配置完模型后,将样本和标注结果文件输入模型,训练参数为batch-size:16,workers:0,epochs:50,训练结果如图5。
[0127]
表1模型训练指标统计表
[0128][0129]
通过50轮的迭代训练,模型准确率为96.7%,召回率为96.2%,map_0.5为98.9%,详细见表1,train/box_loss为训练集框损失,train/obj_loss为训练集置信度损失,train/cls_loss为训练集类别损失,val/box_loss为验证集框损失、val/obj_loss为验证集置信度损失、val/cls_loss为验证集类别损失,模型取得了不错的指标效果。使用训练好的模型测试一组16个字包括个13楷体、3个方正小标宋的字体测试图片,结果如图6所示,模型准确地预测出字体类别,并给出了相应字体类别的置信度值。
[0130]
5.将1份测试公文图像进行二值化,而后进行水平和垂直投影,再进行字符分割,分割后的字符以“c(序号)”的形式进行编号,并记录每个字符的位置坐标(x1,y1,x2,y2),将字符图像输入训练好的模型进行字体识别,模型输出结果,如图7所示,左侧为测试公文图像分割后的单个字符图像,右侧为模型识别字体后的结果,其中,红色为识别的方正小标宋字体、浅黄色为识别的楷体字体、粉色为识别的仿宋_gb2312字体。
[0131]
6.对识别的字体位置及类别信息,使用python cv2包的rectangle()函数,在公文图像上画出字体位置矩形框,并使用matplotlib包,调用plt.text(x,y,s)函数标注出字体类别信息,其中x,y分别为标注框的中点横、纵坐标,s为该字体的类别信息,并将标注后的结果公文在终端显示设备显示,辅助机关公文考评人员快速进行公文质量考核。
[0132]
应该明白,公开的过程中的步骤的特定顺序或层次是示例性方法的实例。基于设计偏好,应该理解,过程中的步骤的特定顺序或层次可以在不脱离本公开的保护范围的情况下得到重新安排。所附的方法权利要求以示例性的顺序给出了各种步骤的要素,并且不是要限于所述的特定顺序或层次。
[0133]
在上述的详细描述中,各种特征一起组合在单个的实施方案中,以简化本公开。不应该将这种公开方法解释为反映了这样的意图,即,所要求保护的主题的实施方案需要比清楚地在每个权利要求中所陈述的特征更多的特征。相反,如所附的权利要求书所反映的那样,本发明处于比所公开的单个实施方案的全部特征少的状态。因此,所附的权利要求书特此清楚地被并入详细描述中,其中每项权利要求独自作为本发明单独的优选实施方案。
[0134]
为使本领域内的任何技术人员能够实现或者使用本发明,上面对所公开实施例进行了描述。对于本领域技术人员来说;这些实施例的各种修改方式都是显而易见的,并且本文定义的一般原理也可以在不脱离本公开的精神和保护范围的基础上适用于其它实施例。因此,本公开并不限于本文给出的实施例,而是与本技术公开的原理和新颖性特征的最广范围相一致。
[0135]
上文的描述包括一个或多个实施例的举例。当然,为了描述上述实施例而描述部件或方法的所有可能的结合是不可能的,但是本领域普通技术人员应该认识到,各个实施例可以做进一步的组合和排列。因此,本文中描述的实施例旨在涵盖落入所附权利要求书的保护范围内的所有这样的改变、修改和变型。此外,就说明书或权利要求书中使用的术语“包含”,该词的涵盖方式类似于术语“包括”,就如同“包括,”在权利要求中用作衔接词所解释的那样。此外,使用在权利要求书的说明书中的任何一个术语“或者”是要表示“非排它性的或者”。
[0136]
本领域技术人员还可以了解到本发明实施例列出的各种说明性逻辑块(illustrative logical block),单元,和步骤可以通过电子硬件、电脑软件,或两者的结合进行实现。为清楚展示硬件和软件的可替换性(interchangeability),上述的各种说明性部件(illustrative components),单元和步骤已经通用地描述了它们的功能。这样的功能是通过硬件还是软件来实现取决于特定的应用和整个系统的设计要求。本领域技术人员可以对于每种特定的应用,可以使用各种方法实现所述的功能,但这种实现不应被理解为超出本发明实施例保护的范围。
[0137]
本发明实施例中所描述的各种说明性的逻辑块,或单元都可以通过通用处理器,数字信号处理器,专用集成电路(asic),现场可编程门阵列或其它可编程逻辑装置,离散门或晶体管逻辑,离散硬件部件,或上述任何组合的设计来实现或操作所描述的功能。通用处理器可以为微处理器,可选地,该通用处理器也可以为任何传统的处理器、控制器、微控制器或状态机。处理器也可以通过计算装置的组合来实现,例如数字信号处理器和微处理器,多个微处理器,一个或多个微处理器联合一个数字信号处理器核,或任何其它类似的配置来实现。
[0138]
本发明实施例中所描述的方法或算法的步骤可以直接嵌入硬件、处理器执行的软件模块、或者这两者的结合。软件模块可以存储于ram存储器、闪存、rom存储器、eprom存储器、eeprom存储器、寄存器、硬盘、可移动磁盘、cd-rom或本领域中其它任意形式的存储媒介中。示例性地,存储媒介可以与处理器连接,以使得处理器可以从存储媒介中读取信息,并可以向存储媒介存写信息。可选地,存储媒介还可以集成到处理器中。处理器和存储媒介可以设置于asic中,asic可以设置于用户终端中。可选地,处理器和存储媒介也可以设置于用户终端中的不同的部件中。
[0139]
在一个或多个示例性的设计中,本发明实施例所描述的上述功能可以在硬件、软件、固件或这三者的任意组合来实现。如果在软件中实现,这些功能可以存储与电脑可读的媒介上,或以一个或多个指令或代码形式传输于电脑可读的媒介上。电脑可读媒介包括电脑存储媒介和便于使得让电脑程序从一个地方转移到其它地方的通信媒介。存储媒介可以是任何通用或特殊电脑可以接入访问的可用媒体。例如,这样的电脑可读媒体可以包括但不限于ram、rom、eeprom、cd-rom或其它光盘存储、磁盘存储或其它磁性存储装置,或其它任何可以用于承载或存储以指令或数据结构和其它可被通用或特殊电脑、或通用或特殊处理器读取形式的程序代码的媒介。此外,任何连接都可以被适当地定义为电脑可读媒介,例如,如果软件是从一个网站站点、服务器或其它远程资源通过一个同轴电缆、光纤电缆、双绞线、数字用户线(dsl)或以例如红外、无线和微波等无线方式传输的也被包含在所定义的电脑可读媒介中。所述的碟片(disk)和磁盘(disc)包括压缩磁盘、镭射盘、光盘、dvd、软盘
和蓝光光盘,磁盘通常以磁性复制数据,而碟片通常以激光进行光学复制数据。上述的组合也可以包含在电脑可读媒介中。
[0140]
以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1