基于FPGA卷积神经网络的人脸识别系统
基于fpga卷积神经网络的人脸识别系统
技术领域
1.本发明涉及卷积神经网络领域、fpga领域,尤其是涉及一种基于fpga卷积神经网络识别人脸的系统。
背景技术:
2.近年来,随着互联网技术的迅速发展,信息技术的不断提高,大数据时代的到来,因此带来的信息量爆发式增长,个人信息的安全隐患日益严重,如何准确地识别个人身份,保护信息安全成为了人们的视觉焦点;人脸识别在生物特征识别技术中具有方便快捷、无需接触、生物特征较多等特点,并且现已在手机解锁、乘客识别、网络支付等方面有着很高的实用价值。
3.边缘计算是一种让外围终端来进行数据处理运算的技术,可以不在云端指挥下实现独立工作,具有低延迟、高可用、高实时等优势,因此卷积神经网络这种重计算的算法越来越多被应用于边缘计算的环境当中,fpga也由于其高效率,低功耗等特性逐渐成为边缘计算的理想平台。
4.2013年邢健飞等以深度神经网络为框架,提出了一种新的搜索策略,误识别率较小并且实时性好;汪济民,陆建峰将卷积神经网络引入到人脸性别识别中,该网络的结构具有稀疏连接和权值共享的优点,卷积层和采样层交替进行,简化了模型的复杂度。
5.随着神经网络的迅速发展,神经网络加速器研究也逐步深入,使神经网络模型在嵌入式平台的完整实现成为可能,2017年,梁云等人xilinx zc706平台上采用winograd实现了resnet的130.4gop/s,使用fft实现了yolo的201.1gop/s,通过减少卷积所需的乘法次数来提高有效的dsp效率,提出了fpga上进一步加快运算速度的卷积神经网络快速算法; 2018年,施杰乔等人详细介绍了硬件实现cnn体系的基本结构,在de2-115开发板上实现了面部识别的cnn体系,识别率达到93%;李硕在zynq-7000芯片上实现了张量神经网络的人脸识别,虽然损失了识别率,但减少了参数数量,最终达到每张图片32ms的识别时间,识别率95%;2021年,王咏星等人介绍了“fpga+arm”架构的数字图像处理系统设计,提出了实时性高的图像的采集和处理实现。
6.quartus ii是最高级和复杂的,用于system-on-a-programable-chip(sopc)的设计环境,提供完善的timing closure和logiclocktm基于块的设计流程,是唯一一个包括以 timing closure和基于块的设计流为基本特征的programable logic device(pld)的软件,主要功能包括设计英特尔fpga、片上系统和cpld所需的一切,比如输入、合成、优化、验证和仿真等功能,quartusii设计软件改进了性能、提升了功能性、解决了潜在的设计延迟等。
技术实现要素:
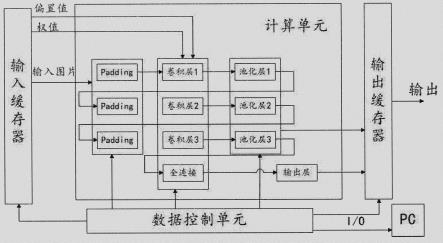
7.本发明涉及一种基于fpga卷积神经网络的人脸识别系统,目的是在fpga中实现基于卷积神经网络的人脸识别;系统包含数据存储模块、fpga卷积神经网络计算模块和数据
控制单元三部分。其中数据存储模块用于存储卷积神经网络在python预先训练好的权重和偏置参数以及待识别的图片数据;fpga卷积神经网络计算模块包含padding模块、卷积模块、池化模块、全连接模块、输出模块等,用于对待识别图片的人脸识别;数据控制单元用来控制各层之间和数据存储模块的数据传输;此完整系统对人脸识别算法和与其对应的的卷积运算加速电路进行设计,对每个模块用verilog语言进行rtl级描述,并进行仿真,综合,验证了算法硬件实现的可行性和正确性。
8.为实现上述目的,参数及待识别图片的输入基于pcie和pc实现,卷积神经网络计算单元的搭建和仿真基于quartus prime standard 18.0和modelsim实现,数据的识别结果输出基于pcie和pc实现。
9.发明的设计主体在fpga上,主要通过对硬件模块的设计,对实时输入的图像流进行正向预测运算,实现图像识别分类,输出识别结果。
10.卷积神经网络的的参数需要通过python辅助得到,网络结构在python上采用 tensorflow搭建,离线训练,共包含三个卷积层、三个池化层、一个全连接层和一个输出层;卷积模块提取图片特征,池化模块对特征降维,全连接模块将特征集合,输出层将特征整合分类输出结果。
11.待识别图片来自于pc端,将原图片调整图片尺寸大小调整为64
×
64大小并对其提取像素值,提取像素值后通过pcie将提取的像素值从pc端上传送到fpga。
12.硬件运算模块的设计大体上包含四部分,分别是卷积模块、池化模块、全连接模块、输出模块。在流水线设计前提下,对每个模块独自编写计算步骤,包含了对输入的具体操作,其中卷积模块将卷积操作和relu操作合并,方便顶层模块的调用,节省运算时间。
13.卷积模块和池化模块滑窗部分参考linebuffer结构采用移位寄存器实现,卷积中采用三个抽头,池化中采用两个抽头,特征图数据经过流动进入移位寄存器参与运算。
14.控制单元控制数据在每层的输入输出、各层之间和数据存储模块的数据传输。
15.本发明中模型参数在python中训练时采用32位浮点数类型,硬件实现中,模型参数、输入输出数据和中间结果均量化为16bit定点数参与运算。
16.由于在本次设计中采用流水线设计,涉及大量的卷积计算,每张并行的图片需要9个乘法器支持,中间运算结果也较多,故需对各层并行度进行分配,在设计好时序的情况下,本层可以同时对多张特征图采用统一卷积核运算,结果直接送入加法器中,省去过久的缓存时间。
附图说明
17.图1为cnn卷积神经网络硬件电路图。
18.图2为cnn体系图。
19.图3为卷积结构图。
20.图4为池化结构图。
21.图5为全连接结构图。
22.图6为输出层结构图。
23.图7为padding效果图。
24.图8为卷积层仿真图。
25.图9为池化层仿真图。
26.图10为输出层仿真图。
27.图11为总体仿真结果图。
28.图12为识别平台的搭建。
具体实施方式
29.下面结合附图和具体实施例对本发明进行详细说明。本实施例以本发明技术方案为前提进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
30.本发明前期准备分为两项,首先是在python中采用tensorflow框架搭建卷积神经网络,本实例中,使用lfw人脸数据库中13991张人脸图片以及自行采集的真人10000张照片作为数据集进行训练,直接将训练好的模型参数各层分开,导出存入各层bram中;其次将待识别图片预处理为rgb类型的三张大小为64
×
64的图片,每个像素点除以255做归一化处理,导出存入bram中。
31.参考图2的卷积神经网络结构图,步骤如下:1)输入预处理的64
×
64
×
3的图片进入卷积层1,用大小3
×
3,步长为1的卷积核处理,输出64
×
64
×
32的特征图,后接relu,再用2
×
2,步长为2的最大池化处理,得到32
×
32
×
32的特征图;2)上层输出接卷积层2,用大小3
×
3,步长为1的卷积核处理,输出32
×
32
×
64的特征图,后接relu,再用2
×
2,步长为2的最大池化处理,得到16
×
16
×
64的特征图;3)上层输出接卷积层3,用大小3
ꢀ×
3,步长为1的卷积核处理,输出16
×
16
×
64的特征图,后接relu,再用2
×
2,步长为2 的最大池化处理,得到8
×8×
64的特征图;4)上层输出接全连接层,输出1
×1×
512;5) 上层输出接输出层,输出两位数据,再经比较得出所属位代表结果。
32.参考图1,卷积神经网络硬件中中设计包含三个卷积模块、三个池化模块、一个全连接模块、一个输出模块;将前期准备的待识别图片及参数输入后即可对输入的图像流进行正向预测运算,实现图像识别分类,输出识别结果;其中各个运算模块设计如下:
33.卷积层:采用多张特征图同时与第n组卷积核卷积,所有特征图卷积完成后更换下一组卷积核的计算顺序,以此类推,最终相加即可以得到卷积结果,比一张特征图先与多个卷积核卷积,再更换特征图的方式更简便快捷。其中一张特征图的卷积模块参考图3,特征图数据经过流动进入移位寄存器,每次时钟上升沿到来,滑窗内的9个特征图数据就更新一次,更新数据传入乘法器与内存中所存权值相乘,最后在加法器中依次相加再加上偏置数据得到卷积结果,三行数据计算完成后,输入处传入下三行数据继续计算,直到整张图片输入完毕。
34.参考图4,池化层中,每两行特征图数据进入滑窗,在比较器模块中包含三个小比较器,滑窗内数据通过比较得到最大值输出,该两行计算完成后输入处传入下两行数据,以此类推得到整张图片结果,以达到最大池化效果。
35.参考图5,全连接层中每个神经元都与前一层相连,仍通过卷积操作得到结果,用512 个8
×8×
64的卷积核对64张8
×
8特征图进行卷积,每张特征图与对应卷积核相乘,64张乘积结果对应位置求和,最后加上偏置值就可以得到一个全连接层的输出,这样更换卷积核循环512次,即可得到全连接模块的512个输出。
36.输出层每一个特征节点里握着一定的权重来决定输入是属于那个分类,最终全部特征的权重共同决定了输入所属分类的权重或概率;参考图6,输出层就是来算得所属分类概率,将全连接模块得到的512个数据通过计算得到2个数值,根据数值大小判断是否是本人人脸;操作过程如图所示,两个含512个数据的权值缓存器与全连接层数据并行依次相乘相加,再加上偏置值,最后得到两个结果,传入比较器中得到最终结果。
37.另外,通常进行卷积操作时,会导致特征图缩小(n-1)行(n-1)列数据,n为卷积核大小。如卷积核为3
×
3时,特征图会缩小两行两列。为保证卷积操作前后特征图尺寸保持一致,需在卷积之前采用padding操作为特征图在外围补0,效果如图7所示;硬件上该模块的输入包含时钟,复位和输入数据,输出包含bram读写标志位和输出数据,通过状态机来实现,将输入数据分为第一行,中间行和最后行三个状态,第一行和最后一行全部补位0,中间行在数据前后各添一位0。
38.fpga最大的优点是可以并行处理数据,实现这一点的关键是使用fpga的bram来缓存和处理数据。因此,为了充分发挥fpga并行流水线处理的优势,算法运用并行流水线式是有必要的;为保障资源的高利用率,在卷积层1中对3张图片并行计算;卷积层2中对32张图片并行计算;卷积层3中对64张图片并行计算;全连接层对两个通道的8*8图片并行计算;输出层同时对两行矩阵依次对应相乘。
39.为说明fpga对人脸识别功能的实现情况,对其做仿真验证,通过自行编写testbench 文件模拟时钟输入激活仿真,同时将图片数据预存在bram进行运算。
40.卷积层仿真参考图8,其中左侧两框表示移位寄存器采到的卷积核,右侧两框表示该行末尾舍掉的卷积核,舍掉的卷积核不参与运算,从参数data1_row(第一行卷积核的合并数据)和data2_row(第二行卷积核的合并数据)和data3_row(第三行卷积核的合并数据)看出,错误的卷积核没有被运送到卷积核参数中,并且输出norm_result正常运行,完成了卷积功能。
41.池化层仿真参考图9,图9中变量out_da1和out_da2表示最后要进行比较的两个数,输出out_data会在下一个时钟将两数中较大的一方输出,可看出能够完成最大池化操作。
42.输出层仿真参考图10,in_data1是输入图片特征的第一条通道数据,in_data2是输入图片特征的第二条通道数据;weight是输出层权重,bia1是通道一的偏置,bia2是通道二的偏置;outflag是输出标志位,由00变为01时表示所有计算已经完成,可以输出最终结果;out_data是最终结果,可以看出在运算完成后,标志位发生变化的下一个时钟, out_data正确输出最终结果。
43.总体仿真结果参考图11,在outflag为高位时,在21ms附近计算完成,输出最终结果out_data。
44.参考图12,本发明基于卷积神经网络在fpga上实现,目标器件为straltix iv系列ep4sgx230kf40c2芯片;将420张测试图片依次输入,完成运算后最终得到正确图像数量;最后正确识别图片413张,误识别7张,识别率为98.3%,总计算时间为8.8s。
45.以上包含了本发明优选实施例的说明,这是为了详细说明本发明的技术特征,并不是想要将发明内容限制在实施例所描述的具体形式中,依据本发明内容主旨进行的其他修改和变型也受本专利保护。本发明内容的主旨是由权利要求书所界定,而非由实施例的
具体描述所界定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1