多源日志的在线解析方法、系统、电子设备及存储介质
1.本发明涉及日志分析技术领域,具体涉及一种多源日志的在线解析方法、系统、电子设备及存储介质。
背景技术:
2.随着软件规模和复杂度的增加,软件产生的日志量也变得更加庞大。据统计,大型的云应用程序每小时产生大约10gb的日志,传统的人工方式对这些日志信息进行分析已不能满足需求,所以自动化的日志分析技术应运而生。
3.在日常运维过程中,使用非结构化日志进行异常检测和根因分析是一项极具挑战性的分析工作,而从海量日志数据中进行实时和有效的异常检测更具挑战性。日志中的内容通常可以分为常量部分和变量部分,常量部分是固定不变的文本内容,表示了一种日志事件模板,变量部分反映了系统运行时的信息,比如状态值和参数(ip地址、持续时间、文件路径等等)。日志解析的目的就是分离出日志事件信息和参数信息,将原始日志从非结构化日志转化为能让计算机容易识别和处理的结构化日志,解决非结构化日志数据难以分析的问题。它作为日志分析的首要环节,对后续的日志分析效果起到非常关键的作用。
4.目前,在日志解析研究领域中,有基于相似度的聚类方法、频繁项挖掘方法和启发式方法,现有的方法中主要是针对特定领域的日志表现较好,而且目前大部分的日志解析方法是只适用于离线的日志解析,不能满足在线日志解析的计算需求,其中支持日志在线解析的典型方法有drain和spell等,但从实验结果看,当遇到结构类似的日志事件模板时,都容易出现日志解析过拟合的问题,而这种结构类似的日志事件模板往往会在大型的软件系统中普遍存在。如以下是openstack的两条日志:
5.instance spawned successfully.
6.instance destroyed successfully.
7.上述两条日志在进行事件模板提取和求公共子序列时,往往会被误处理为相同事件模板(instance*successfully.),但其实它们是两类含义完全相反的日志事件。
8.又如openstack中nova组件中存在的类似结果相似的事件日志。
9.2022-04-21 18:14:29.104 19134 info nova.compute.manager[req-67a9597b-4d98-486d-a8dc-b2b3718357d5
‑‑‑‑‑
][instance:ac8ca295-9d99-4b5f-9a73-694c87af0f3c]vm started(lifecycle event)
[0010]
2022-04-21 18:14:29.172 19134 info nova.compute.manager[req-67a9597b-4d98-486d-a8dc-b2b3718357d5
‑‑‑‑‑
][instance:ac8ca295-9d99-4b5f-9a73-694c87af0f3c]vm paused(lifecycle event)
[0011]
2022-04-21 18:14:31.339 19134 info nova.compute.manager[req-67a9597b-4d98-486d-a8dc-b2b3718357d5
‑‑‑‑‑
][instance:ac8ca295-9d99-4b5f-9a73-694c87af0f3c]vm resumed(lifecycle event)
[0012]
在日志解析的过程中,日志事件中的关键词“started”、“paused”和“resumed”就
会很容易在日志解析过程中求公共子序列时会被标记为变量*,这会使几条不同语义特征的日志事件被错解析为一条事件vm《*》(lifecycle event)。
技术实现要素:
[0013]
本发明的主要目的在于克服现有技术的缺点与不足,提供一种多源日志的在线解析方法,通过日志树对日志进行快速的归类、查询和检索以及动词词性特征的分类,有效解决不同语义特征的日志事件被错误地归为一类事件的问题。
[0014]
为了达到上述目的,本发明采用以下技术方案:
[0015]
本发明一方面提供了一种多源日志的在线解析方法,包括下述步骤:
[0016]
对来源于分布式系统中多个不同应用组件的日志以日志流的方式进行收集;
[0017]
利用日志树对收集的日志进行归类和检索,并提取日志关键字段信息,所述日志关键字段信息包括:日志标识id、host、path、timestamp、level和日志内容message;
[0018]
对日志关键字段信息中的message字段进行预处理,通过正则表达式将message字段中的常用变量标记ip地址、数字变量和url地址字符替换成通配符*;
[0019]
对经过预处理的日志message字段,利用首个单词对日志进行分组;
[0020]
对分组后的日志message字段内容进行动词词性特征提取,根据动词词性特征进行分类,将含有动词词性特征的日志归类为执行类日志,不含动词词性特征的日志,则归类为状态类日志;
[0021]
将同类动词词性特征的日志通过最长公共子序列lcs算法提取日志事件模板和更新日志模板。
[0022]
优选的,所述以日志流的方式进行收集,具体为:
[0023]
采用elasticstack开源的日志管理解决方案,通过filebeat轻量级组件收集服务器的日志,配置收集对应的目录文件。
[0024]
优选的,所述利用日志树对收集的日志进行归类和检索,并提取日志关键字段信息,具体为:
[0025]
通过日志树进行归类和检索,日志树第一层为主机节点,第二层为程序模块节点,第三层为日志关键字段信息,当新日志输入时,先匹配主机节点,接着匹配程序模块节点,如没匹配成功,则新增一个分支节点,然后提取日志关键字段;经过上述步骤,对来自不同应用组件的日志提取出统一格式的日志关键字段信息,该日志关键字段信息包括日志标识、日志来源信息以及日志字段信息,其中,所述日志标识为日志的唯一id号,所述日志来源信息包括:日志所在的主机名host以及日志的路径path;所述日志字段信息包括:日志的时序特征timestamp、日志的具体日志内容message以及日志的重要程度特征level,对于日志中不含有level字段的,则设为默认值default。
[0026]
优选的,所述利用首个单词对日志进行分组,具体为:
[0027]
在选择首单词时采用语料库的方法进行判断,当选择的首个单词是不在语料库范围的单词时,则选择第二个单词作为首单词标识,依次类推,当首单词是在语料库中的单词时则直接作为日志的首单词标识;在确定首单词后,如果原来已有该日志的首单词标识分组,则直接将日志的id加入该分组中,如果原来没有该日志的首单词标识分组,则自动创建一个首单词分组,并将日志的id加入到该分组中。
[0028]
优选的,所述对分组后的日志message字段内容进行动词词性特征提取,根据动词词性特征进行分类,将含有动词词性特征的日志归类为执行类日志,并根据具体的动词特征加以分组;而不含动词词性特征的日志,则归类为状态类日志,具体为:
[0029]
利用nltk词性标注工具包对日志进行词性标注,提取日志中的动词词性特征,将含有动词词性特征的归类为执行类日志,不含有动词词性特征的归类为状态类日志;利用日志的动词词性特征,对日志进行分类,如果原来已有该日志对应的动词词性特征分类,则加入该日志的id;如果原来没有该日志的动词词性特征分类,则自动创建一个动词词性特征分类,并将日志的id加入到该分类中;若输入的日志不含动词词性特征,则将输入日志归类为状态类日志。
[0030]
优选的,所述将同类动词词性特征的日志通过最长公共子序列lcs算法提取日志事件模板和更新日志模板,具体为:
[0031]
对相同动词词性特征组内的现有日志事件模板进行从长到短降序排列,新增的日志按照顺序与组内日志事件模板进行最长公共子序列计算,如果最长公共子序列长度大于现有日志模板长度一半以上,则匹配成功,直接将日志id加入到现有的日志模板组中,而当原有日志模板长度大于最长公共子序列长度时,还需要用现有的最长公共子序列来更新日志模板;如果最长公共子序列长度小于现有模板长度的一半时,则匹配失败,需新建一个独立日志模板,并将id加入到该模板中。
[0032]
本发明又一方面提供了一种多源日志的在线解析系统,应用于所述的多源日志的在线解析方法,包括:日志收集模块、关键字段提取模块、日志预处理模块、首单词分组模块、动词词性特征分类模块以及日志事件模板提取模块;
[0033]
所述日志收集模块,用于对来源于分布式系统中多个不同应用组件的日志以日志流的方式进行收集;
[0034]
所述关键字段提取模块,用于利用日志树对收集的日志进行归类和检索,并提取日志关键字段信息,所述日志关键字段信息包括:日志标识id、host、path、timestamp、level和日志内容message;
[0035]
所述日志预处理模块,用于对日志关键字段信息中的message字段进行预处理,通过正则表达式将message字段中的特殊标记替换成通配符;
[0036]
所述首单词分组模块,用于对经过预处理的日志message字段,利用首个单词对日志进行分组;
[0037]
所述动词词性特征分类模块,用于对日志的message字段内容进行动词词性特征提取,根据动词词性特征进行分类,将含有动词词性特征的日志归类为执行类日志,不含动词词性特征的日志,则归类为状态类日志;
[0038]
所述日志事件模板提取模块,用于将同类动词词性特征的日志通过最长公共子序列lcs算法提取日志事件模板和更新日志模板。
[0039]
本发明又一方面提供了一种电子设备,其特征在于,所述电子设备包括:
[0040]
至少一个处理器;以及,
[0041]
与所述至少一个处理器通信连接的存储器,其中,
[0042]
所述存储器存储有可被所述至少一个处理器执行的计算机程序指令,所述计算机程序指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行所述的一种多源
日志的在线解析方法。
[0043]
本发明再一方面提供了一种计算机可读存储介质,存储有程序,所述程序被处理器执行时,实现所述的多源日志的在线解析方法。
[0044]
本发明与现有技术相比,具有如下优点和有益效果:
[0045]
本发明结合分布式软件系统日志的特点,设计了支持多源日志在线解析的数据结构和通用方法,通过对日志的动词词性特征区分出执行类日志和状态类日志,并结合日志的多源信息,能为后续的日志分析中构建工作流图和根因分析提供重要的数据基础,有效解决了结构相同而语义不同的日志在模板提取过程中被误处理为同一日志事件的过拟合问题。
附图说明
[0046]
为了更清楚地说明本技术实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本技术的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0047]
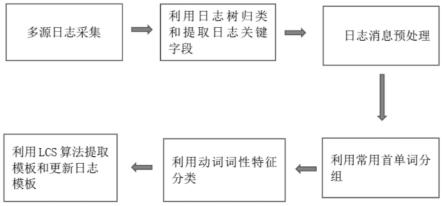
图1为本发明实施例一种多源日志的在线解析方法流程图。
[0048]
图2为本发明实施例一种多源日志的在线解析方法查找树示意图。
[0049]
图3为本发明实施例一种多源日志的在线解析系统的构成示意图。
[0050]
图4为本发明实施例电子设备的结构图。
具体实施方式
[0051]
为了使本技术领域的人员更好地理解本技术方案,下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述。显然,所描述的实施例仅仅是本技术一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
[0052]
在本技术中提及“实施例”意味着,结合实施例描述的特定特征、结构或特性可以包含在本技术的至少一个实施例中。在说明书中的各个位置出现该短语并不一定均是指相同的实施例,也不是与其它实施例互斥的独立的或备选的实施例。本领域技术人员显式地和隐式地理解的是,本技术所描述的实施例可以与其它实施例相结合。
[0053]
如图1所示、如图2所示,本实施例一种多源日志的在线解析方法,包括下述步骤:
[0054]
s1、对来源于分布式系统中多个不同应用组件的日志以日志流的方式进行收集。
[0055]
进一步的,所述以日志流的方式进行收集,具体为:
[0056]
采用elasticstack开源的日志管理解决方案,通过filebeat轻量级组件收集服务器的日志,配置收集对应的目录文件。
[0057]
更进一步的,输入为日志流来源于control01控制主机的/var/log/nova/nova-api.log控制服务日志和compute3计算节点主机的/var/log/nova/nova-compute.log计算服务日志。
[0058]
[1]control01/var/log/nova/nova-api.log 2022-04-27 18:33:47.956 1343 info nova.api.openstack.compute.server_external_events
[0059]
[req-288b9b4f-cda5-4e29-a3a1-ede2f4073674 ba82731d70654e39bc5e832454a6fd06 d4d0d97635944209a9093fcd443531d7-default default]creating event network-changed:830ec68b-e073-4932-bcec-94c12afe1377 for instance b9000564-fe1a-409b-b8cc-1e88b294cd1d on compute1.
[0060]
[2]control01/var/log/nova/nova-api.log 2022-04-27 18:34:44.264 1317infonova.api.openstack.compute.server_external_events
[0061]
[req-ae103bb1-d263-4fd5-b425-ce546d38f655 ba82731d70654e39bc5e832454a6fd06 d4d0d97635944209a9093fcd443531d7-default default]creating event network-vif-plugged:830ec68b-e073-4932-bcec-94c12afe1377 for instance 9069c8d7-cfd7-4440-88b4-0e1577cddd76 on compute3.
[0062]
[3]compute3/var/log/nova/nova-compute.log 2022-04-27 18:34:44.315 19134 info nova.virt.libvirt.driver[-][instance:9069c8d7-cfd7-4440-88b4-0e1577cddd76]instance spawned successfully.
[0063]
[4]compute3/var/log/nova/nova-compute.log 2022-04-27 19:02:40.632 19134 info nova.virt.libvirt.driver[-][instance:9069c8d7-cfd7-4440-88b4-0e1577cddd76]instance destroyed successfully.
[0064]
s2、利用日志树对收集的日志进行归类和检索,并提取日志关键字段信息,所述日志关键字段信息包括:日志标识id、host、path、timestamp、level和日志内容message;
[0065]
进一步的,日志树第一层为主机节点,第二层为程序模块节点,第三层为日志关键字段信息,当新日志输入时,先匹配主机节点,接着匹配程序模块节点,如没匹配成功,则新增一个分支节点,然后提取日志关键字段;经过上述步骤,对来自不同应用组件的日志提取出统一格式的日志关键字段信息,该日志关键字段信息包括日志标识、日志来源信息以及日志字段信息,其中,所述日志标识为日志的唯一id号,所述日志来源信息包括:日志所在的主机名host以及日志的路径path;所述日志字段信息包括:日志的时序特征timestamp、日志的具体日志内容message以及日志的重要程度特征level,对于日志中不含有level字段的,则设为默认值default。
[0066]
更进一步的,对来自不同组件的日志提取出统一格式的字段信息,如下表所示。
[0067]
[0068][0069]
s3、对日志关键字段信息中的message字段进行预处理,通过正则表达式将message字段中的常用变量标记ip地址、数字变量和url地址字符替换成通配符*。
[0070]
[1]creating event network-changed:*for instance*on compute1
[0071]
[2]creating event network-vif-plugged:*for instance*on compute3
[0072]
[3]instance spawned successfully.
[0073]
[4]instance destroyed successfully.
[0074]
s4、对经过预处理的日志message字段,利用首个单词对日志进行分组。
[0075]
进一步的,在选择首单词时采用语料库的方法进行判断,当选择的首个单词不在语料库中时,则选择第二个单词作为首单词标识,依次类推,当首单词是在语料库中的单词时则直接作为日志的首单词标识;在确定首单词后,如果原来已有该日志的首单词标识分组,则直接将日志的id加入该分组中,如果原来没有该日志的首单词标识分组,则自动创建一个首单词分组,并将日志的id加入到该分组中。
[0076]
creating:{1,2}
[0077]
instance:{3,4}
[0078]
s5、对分组后的日志message字段内容进行动词词性特征提取,根据动词词性特征进行分类,将含有动词词性特征的日志归类为执行类日志,并根据具体的动词特征加以分组,而不含动词词性特征的日志,则归类为状态类日志。
[0079]
进一步的,利用nltk词性标注工具包对日志进行词性标注,提取日志中的动词词性特征,将含有动词词性特征的归类为执行类日志,不含有动词词性特征的归类为状态类
日志;利用日志的动词词性特征,对日志进行分类,如果原来已有该日志对应的动词词性特征分类,则加入该日志的id;如果原来没有该日志的动词词性特征分类,则自动创建一个动词词性特征分类,并将日志的id加入到该分类中;若输入的日志不含动词词性特征,则将输入日志归类为状态类日志分类。
[0080]
('creating','vbg'):{1,2}
[0081]
('spawned','vbd'):{3}
[0082]
('destroyed','vbd'):{4}
[0083]
s6、将相同动词词性特征的日志通过最长公共子序列lcs算法提取日志事件模板和更新日志模板。
[0084]
进一步的,对相同动词词性特征组内的现有日志事件模板进行从长到短降序排列,新增的日志按照顺序与组内日志事件模板进行最长公共子序列计算,如果最长公共子序列长度大于现有日志模板长度一半以上,则匹配成功,直接将日志id加入到现有的日志模板组中,而当原有日志模板长度大于最长公共子序列长度时,还需要用现有的最长公共子序列来更新日志模板;如果最长公共子序列长度小于现有模板长度的一半时,则匹配失败,需新建一个独立日志模板,并将id加入到该模板中。
[0085]
creating event*for instance*on*{1,2}
[0086]
instance spawned successfully.{3}
[0087]
instance destroyed successfully.{4}
[0088]
基于与上述实施例中的一种多源日志的在线解析方法相同的思想,本发明还提供了一种多源日志的在线解析系统,该系统可用于执行上述一种多源日志的在线解析方法。为了便于说明,一种多源日志的在线解析系统实施例的结构示意图中,仅仅示出了与本发明实施例相关的部分,本领域技术人员可以理解,图示结构并不构成对装置的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置。
[0089]
如图3所示,本发明另一实施例中,提供了一种多源日志的在线解析系统100,该系统包括日志收集模块101、关键字段提取模块102、日志预处理模块103、首单词分组模块104、动词词性特征分类模块105以及日志事件模板提取模块106;
[0090]
所述日志收集模块101,用于对来源于分布式系统中多个不同应用组件的日志以日志流的方式进行收集;
[0091]
所述关键字段提取模块102,用于利用日志树对收集的日志进行归类和检索,并提取日志关键字段信息,所述日志关键字段信息包括:日志标识id、host、path、timestamp、level和日志内容message;;
[0092]
所述日志预处理模块103,用于对日志关键字段信息中的message字段进行预处理,通过正则表达式将message字段中的特殊标记替换成通配符;
[0093]
所述首单词分组模块104,对经过预处理的日志message字段,利用首个单词对日志进行分组;
[0094]
所述动词词性特征分类模块105,用于对日志的message字段内容进行动词词性特征提取,根据动词词性特征进行分类,将含有动词词性特征的日志归类为执行类日志,不含动词词性特征的日志,则归类为状态类日志;
[0095]
所述日志事件模板提取模块106,用于将同类动词词性特征的日志通过最长公共
子序列lcs算法提取日志事件模板和更新日志模板。
[0096]
需要说明的是,本发明的一种多源日志的在线解析系统与本发明的一种多源日志的在线解析方法一一对应,在上述一种多源日志的在线解析方法的实施例阐述的技术特征及其有益效果均适用于一种多源日志的在线解析系统的实施例中,具体内容可参见本发明方法实施例中的叙述,此处不再赘述,特此声明。
[0097]
此外,上述实施例的一种多源日志的在线解析系统的实施方式中,各程序模块的逻辑划分仅是举例说明,实际应用中可以根据需要,例如出于相应硬件的配置要求或者软件的实现的便利考虑,将上述功能分配由不同的程序模块完成,即将所述一种多源日志的在线解析系统的内部结构划分成不同的程序模块,以完成以上描述的全部或者部分功能。
[0098]
如图4所示,本发明又一实施例中提供了一种多源日志的在线解析电子设备,所述电子设备200可以包括第一处理器201、第一存储器202和总线,还可以包括存储在所述第一存储器202中并可在所述第一处理器201上运行的计算机程序,如多源日志的在线解析程序203。
[0099]
其中,所述第一存储器202至少包括一种类型的可读存储介质,所述可读存储介质包括闪存、移动硬盘、多媒体卡、卡型存储器(例如:sd或dx存储器等)、磁性存储器、磁盘、光盘等。所述第一存储器202在一些实施例中可以是电子设备200的内部存储单元,例如该电子设备200的移动硬盘。所述第一存储器202在另一些实施例中也可以是电子设备200的外部存储设备,例如电子设备200上配备的插接式移动硬盘、智能存储卡(smart media card,smc)、安全数字(securedigital,sd)卡、闪存卡(flash card)等。进一步地,所述第一存储器202还可以既包括电子设备200的内部存储单元也包括外部存储设备。所述第一存储器202不仅可以用于存储安装于电子设备200的应用软件及各类数据,例如多源日志的在线解析程序203的代码等,还可以用于暂时地存储已经输出或者将要输出的数据。
[0100]
所述第一处理器201在一些实施例中可以由集成电路组成,例如可以由单个封装的集成电路所组成,也可以是由多个相同功能或不同功能封装的集成电路所组成,包括一个或者多个中央处理器(central processing unit,cpu)、微处理器、数字处理芯片、图形处理器及各种控制芯片的组合等。所述第一处理器201是所述电子设备的控制核心(control unit),利用各种接口和线路连接整个电子设备的各个部件,通过运行或执行存储在所述第一存储器202内的程序或者模块,以及调用存储在所述第一存储器202内的数据,以执行电子设备200的各种功能和处理数据。
[0101]
图4仅示出了具有部件的电子设备,本领域技术人员可以理解的是,图4示出的结构并不构成对所述电子设备200的限定,可以包括比图示更少或者更多的部件,或者组合某些部件,或者不同的部件布置。
[0102]
所述电子设备200中的所述第一存储器202存储的多源日志的在线解析程序203是多个指令的组合,在所述第一处理器201中运行时,可以实现:
[0103]
对来源于分布式系统中多个不同应用组件的日志以日志流的方式进行收集;
[0104]
利用日志树对收集的日志进行归类和检索,并提取日志关键字段信息,所述日志关键字段信息包括:日志标识id、host、path、timestamp、level和日志内容message;;
[0105]
对日志关键字段信息中的message字段进行预处理,通过正则表达式将message字段中的特殊标记替换成通配符;
[0106]
对经过预处理的日志message字段,利用首个单词对日志进行分组;
[0107]
对分组后的日志message字段内容进行动词词性特征提取,根据动词词性特征进行分类,将含有动词词性特征的日志归类为执行类日志,不含动词词性特征的日志,则归类为状态类日志;
[0108]
将同类动词词性特征的日志通过最长公共子序列lcs算法提取日志事件模板和更新日志模板。
[0109]
进一步地,所述电子设备200集成的模块/单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个非易失性计算机可读取存储介质中。所述计算机可读介质可以包括:能够携带所述计算机程序代码的任何实体或装置、记录介质、u盘、移动硬盘、磁碟、光盘、计算机存储器、只读存储器(rom,read-only memory)。
[0110]
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于一非易失性计算机可读取存储介质中,该程序在执行时,可包括如上述各方法的实施例的流程。其中,本技术所提供的各实施例中所使用的对存储器、存储、数据库或其它介质的任何引用,均可包括非易失性和/或易失性存储器。非易失性存储器可包括只读存储器(rom)、可编程rom(prom)、电可编程rom(eprom)、电可擦除可编程rom(eeprom)或闪存。易失性存储器可包括随机存取存储器(ram)或者外部高速缓冲存储器。作为说明而非局限,ram以多种形式可得,诸如静态ram(sram)、动态ram(dram)、同步dram(sdram)、双数据率sdram(ddrsdram)、增强型sdram(esdram)、同步链路(synchlink)dram(sldram)、存储器总线(rambus)直接ram(rdram)、直接存储器总线动态ram(drdram)、以及存储器总线动态ram(rdram)等。
[0111]
以上实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
[0112]
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1