双向自回归无监督预训练微调式排污异常监控方法及应用
1.本发明涉及排污异常监控领域,具体而言,涉及双向自回归无监督预训练微调式排污异常监控方法及应用。
背景技术:
2.排污企业是固定污染源,其污染排放是我国环境污染的主要来源之一。对固定污染源的监管是我国污染防治的重中之重。但目前仍然存在企业偷排、恶意篡改监测设备参数、破坏在线监测设备设施、设备运维不规范、不及时导致的监测数据异常或无效的情况,给环境造成污染,对监管提出更高要求。目前国内外对于水质排放的检测在硬件方面已十分完备,各类水质传感器、漂浮式水质监测站以及水质监测终端机等等的开发与研究,保证了对水质排放相关指标数据,精准高效地大量搜集。然而,在对污染物数据的处理方面,还有较大的空白,未能利用数据,对企业合法排污,进行较为合理高效的判断。
3.传统用的时序特征提取方法主要分为两大部分:(1)基于统计学的判断,如3-signma原则、置信度原理等。这些方法对序列的所有维度的数据进行综合评估,依靠统计量,将离群点做实时的更新和判断。(2)基于普通机器学习,人工构造特征,这需要研究人员对于数据含义有清晰的认识和理解,才能进行合适的特征工程来确保模型的稳健性。因此,更多的情况下,难以达到较好的效果。对多维时间序列特征的学习与提取是异常点检测任务的必要前提。
技术实现要素:
4.针对以上传统方法的不足和多维时间序列的特点,本文利用改进的深度学习网络对多维时间序列进行特征提取,融合了泛化能力强的网络来充分提取多维时间序列中更加抽象的语义特征,在构建复杂模型的同时还将参数进行优化,使得模型能够有更快的推理速度和更高的精度。
5.本发明提供了一种双向自回归无监督预训练微调式排污异常监控方法,包括以下步骤:
6.s1:采集数据
7.多通道采集和传输模块周期性地采集污染源排放口的以下数据:压力、流速、温度、密度;得到原始多维时间序列样本,传输到数据处理模块;
8.s2:对原始多维时间序列样本进行预处理;
9.使用基于掩码mask的方法,对数据处理模块得到的数据进行去噪和插值操作;
10.s3:对预处理后的多维时间序列样本进行重采样;
11.将某段时间序列进行伸缩变换,再以滑动窗口的模式进行重采样,以设定的时间间隔提取原样本,提取设定尺度的多维时间序列特征;
12.s4:构建包括数据重采样增强、编码器、解码器三个部分的模型并进行预训练;
13.s5:对预训练后的模型进行小样本微调和序列点分类。
14.在经过预训练之后,模型已经学习到了多维时间序列设层次、多尺度的特征,这是一种通用的特征,蕴含了整个多维时间序列局部与局部、整体与局部之间的内在联系,将该预训练模型作为下游任务的基线baseline,对下游异常检测任务进行微调fine-tuning,将输入的序列作为原序列,模型输出的序列记为重建序列,故可利用预训练模型对原序列进行编码和解码,可以重建出不含噪点信息,但具备原序列高维特征的重建序列,利用原序列和重建后得到的多维时间序列进行对比,计算每个对应点的动态时间规整指标作为异常指标,而后通过聚类的方法将异常和正常情况分类;
15.首先随机在由一长串多维时间序列构成的数据集中抽取10%的连续序列作为样本,重复 s4中的训练过程,在下游任务中做小样本的微调fine tuning;
16.小样本微调的具体步骤如下:输入为预处理后的原始多维时间序列x
′
in
∈ r
batch_size
×
input_window
×
in_dim
,其中batch_size为训练批次大小,input_window表示序列长度,即预处理过程中的滑动窗口宽度,in_dim表示样本的维度;
17.经过编码器和解码器重建序列得到求得每个时间点的loss,通过k-means聚类方法对序列点进行分类,具体步骤如下:
18.(1)首先设置参数k,k的含义为将数据聚合成几类,这里取k=2;
19.(2)从数据当中,随机的选择两个点,成为聚类初始中心点;
20.(3)计算所有其他点到这两个点的距离,然后找出离每个数据点最近的中心点,将该点划分到这个中心点所代表的的簇当中去;那么所有点都会被划分到两个簇当中去;
21.(4)重新计算两个簇的质心,作为下一次聚类的中心点;
22.(5)重复上面的(3)-(4)步的过程,重新进行聚类,不断迭代重复这个过程;
23.(6)当重新聚类后,所有样本点归属类别都没有发生变化的时候停止;
24.最后可以得到两类样本,样本数量少的一类即为异常;
25.实际情况中,企业为了排放不超标,私自进行上传数据的修改:当接受到的排放数据指标在某个时间段有上升趋势,但是在过程中的某个时间点之后突然快速下降,产生了“尖刺状”的数据变化情况,并且这一现象在近段时间内未曾出现过,那么有理由推测,监测对象可能在发现排污指标呈上升趋势且将要超标时,对检测设备进行了外部干涉,或者在上传的数据有篡改行为发生,并将相应的时间点标记为异常数据,对该公司及与其共用排污口的公司进行异常标记,最后通过聚类的方法找出所有的异常点。
26.s6:利用步骤s5得到的模型进行排污异常监控。
27.作为优选,所述步骤s1中,所述多通道采集和传输模块采集数据的步骤包括:初始化、读取一次串口中断数据、数据打包发送,
28.所述初始化步骤包括:对esp8266芯片运行环境进行初始化配置;
29.所述读取一次串口中断数据的步骤,具体包括以下步骤:设置临时储存串口中断数据的数据类型为32位机的unsigned int型,数据长度即为16bits,串口中断实时更新数据,并在固定时间中断中进行二次滤波;
30.所述数据打包发送的具体步骤为:通过esp8266芯片将读取的十六位数据打断,分成前八位与后八位,以0x03、~0x03为数据针头,~0x03、0x03为数据针尾,将以上数据打包,最后以字符形式,使用esp8266芯片以无线热点方式,通过网络传输到数据处理模块。
31.作为优选,所述步骤s2中,所述基于掩码mask的方法具体为:取来一段完整的时间
序列作为样本,随机遮盖掉其中的10%,利用卡尔曼滤波算法对其进行还原。
32.作为优选,所述步骤s4具体包括以下子步骤:
33.s4.1:使用噪声函数破坏序列:
34.使用tokenmasking、tokendeletion、textlnfilling、sentencepermutation、documentrotation五种噪声函数中的任一种或多种组合,破坏s3步骤得到的时间序列;
35.s4.2:构建编码器网络骨架部分:
36.选用自注意力层和mlp网络作为骨干网络,迭代12次构成编码器;
37.将多维时间序列进行标准化,消除量纲的影响,
38.使用位置编码pe,为多维时间序列加入位置信息
39.pos指不同的时间点位置,2i和2i+1分别对应某个时间点的不同维度指标,奇数维度利
[0040][0041][0042]
用sin正弦编码,偶数维度利用cos余弦编码,d
model
指数据的总维度,这里是防止10000的指数过大而溢出;
[0043]
利用三个线性层生成q,k,v三个矩阵,并且使用q去访问每一个k,经过缩放和softmax,先转化为以e为底的指数,而后做归一化处理:
[0044][0045]
归一化处理后作为v的权重,从而计算attention值用于后续的mlp层和解码器进行序列重建:
[0046][0047]
引入多头机制以适应更高维度的时间序列信息:
[0048]
multihead(q,k,v)=[head1,...,headh]w0[0049][0050]
其中h为注意力头数量,使用多头注意力时必须确保输入维度的大小必须能被注意力头数量整除,将输入维度分成h组,每组特征具有自己的注意力体系;
[0051]
s4.3:构建解码器部分:
[0052]
由多头自注意力层和mlp层作为网络骨架,经过一次堆叠后,利用交叉多头注意力聚合操作cross attention与编码器最后一层的隐藏状态结果进行注意力聚合计算,而后进行多次自注意力层mlp层的堆叠;
[0053]
取编码器中自注意力机制得到的k,v与解码器中训练得到的q进行聚合计算,并采用 layer normalization方法在每层mlp后加上标准化层,其中h是一层中隐层节点的数量,l 是mlp的层数,我们可以计算layer normalization的归一化统计量μ
l
和σ
l
:
[0054][0055]
其中a
l
为输入的多维时间序列,统计量μ
l
和σ
l
的计算,与样本数量没有关系,而只取决于隐层节点的数量,
[0056]
只要隐层节点的数量足够多,就能保证layer normalization的归一化统计量足够具有代表性,经过l层mlp后输出的数据为i表示维度,记作in_dim,通过μ
l
和σ
l
可以得到归一化后的值其中∈取1e-5
,防止除0;
[0057]
以自回归的方式对被破坏的时间序列进行复原重建;复原重建程度通过动态时间规整指标来评估;
[0058]
所述动态时间规整指标的计算方式为:把两个时间序列进行对齐后,求算出一个差异矩阵,目标是在矩阵中找到一条从(0,0)到(n,n)的路径,使得该路径上的元素的累加欧拉距离最小,该最小路径为wraping path,即为动态时间规整指标,用于表示两个时间序列的相似度:
[0059]
构造一个n
×
n的矩阵,矩阵的(i
th
,j
th
)元素是点qi和cj之间的欧几里德距离d(qi,cj); wraping path定义了时序q和c之间的映射,记作p,是一组连续的矩阵元素,p的第th个元素定义为p
t
=d(qi,cj)
t
,其中p=p1,p2,...,p
t
,n≤t≤2n-1,本质上是通过一个动态规划的方法来求得的:
[0060]dij
=d(xi,yj)
[0061]
d(i,j)=d
ij
+min{d(i-1,j),d(i,j-1),d(i-1,j-1)}
[0062]
其中,d(i-1,j)表示x
i-1与yj匹配时的子序列距离,d(i,j-1)表示xi与y
j-1匹配时的子序列距离,d(i-1,j-1)表示x
i-1与y
j-1匹配时的子序列距离;
[0063]
在多变量时间序列中,xi和yj都是in_dim维的向量,而且xi中的元素是时刻i下变量的值, yj中的元素是时刻j下变量的值,d(xi,yj)即是i时刻的xi和j时刻的yj对齐时的距离;向量xi和 yj之间的距离计算方式d(xi,yj)可以通过欧氏距离或者马氏距离来计算;
[0064]
欧氏距离:
[0065][0066]
对于一个均值为μ=(μ1,μ2,μ3,...,μ
p
)
t
,协方差矩阵为s的多变量x=(x1,x2,x3,...,x
p
)
t
,马氏距离为:
[0067][0068]
其与欧氏距离不同的是它考虑到各种特性之间的联系,并且是尺度无关的(scale
‑ꢀ
invariant),即独立于测量尺度。
[0069]
s44:预训练过程为:
[0070]
对采集到的数据进行重采样,作为原序列,而后对原序列进行序列破坏,而后将其传入模型做前向推理forward,经过编码器和解码器处理,得到一个新序列,记该序列为原序列的重建序列;
[0071]
利用动态时间规整指标来衡量原序列与其重建序列之间的相似度,记作dtw,构造损失函数:
[0072][0073]
计算得到重建前后损失后,进行反向传播,更新模型参数,使得损失越来越小直至收敛到损失不再下降,在此过程中模型逐渐学习多维时间序列中的特征,做到自动提取特征的功能,此为预训练过程,最终得到一个具有序列提取能力的预训练模型,供之后下游任务的使用。
[0074]
本发明还提供了一种双向自回归无监督预训练微调式排污异常监控方法在可视化大屏管理平台上的应用,所述可视化大屏管理平台的硬件部分包括:多通道采集和传输模块、数据处理模块,所述多通道采集和传输模块包括:压力传感器、流速计、温度计以及密度检测计,上述传感器设置于待监控的污染源排放口,数据处理模块的前端,基于react框架开发,使用 axios与后端进行交互获取分析后的排污数据,并引入datav和antv进行排污异常数据可视化;数据处理模块的后端,基于golang开发,包括gin和gorm框架;数据处理模块的编码,通过编写dockerfile,生成docker镜像,进行多平台迁移运行;所述可视化大屏管理平台包括“政府”、“企业”、“个人”三个视角。
附图说明
[0075]
为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体实施方式或现有技术描述中所需要使用的附图作简单介绍,后文将参照附图以示例性而非限制性的方式详细描述本发明的一些具体实施例。本领域技术人员应该理解,这些附图未必是按比例绘制的。附图中:
[0076]
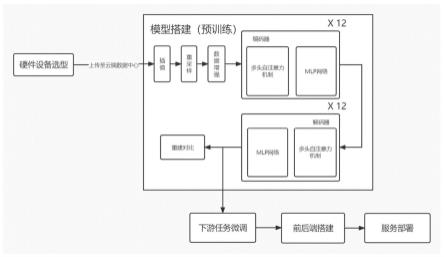
图1为本发明的功能流程图;
[0077]
图2为用户上传的指定格式的表格。
具体实施方式
[0078]
为了使本技术的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本技术进行进一步详细说明。应当理解,此处描述的具体实施例仅用以解释本技术,并不用于限定本技术。
[0079]
双向自回归无监督预训练微调式排污异常监控方法的流程图如图1所示,本发明具体实施步骤如下:
[0080]
s1.1:硬件设备的选型。
[0081]
选取压力传感器、流速计、温度计以及密度检测计等数据传感器,采集排放口附近的数据,以此作为检测污染的指标。主控与蓝牙传输模块选取esp8266实现主控与无线传输功能。其在较小尺寸封装中集成了业界领先的tensilica l106超低功耗32位微型mcu,带有16位精简模式,主频支持80mhz和160mhz,支持rtos,集成wi-fi mac/b/rf/pa/lna,板载天线。该模块支持标准的ieee802.11b/g/n协议,完整的tcp/ip协议栈。
[0082]
s1.2:数据采集程序主要由初始化、读取一次串口中断数据、数据打包发送等模块组成。
[0083]
初始化主要是对mcu运行环境进行初始化配置。设置临时储存串口中断数据的数据类型为32位机的unsigned int型,数据长度即为16bits,串口中断实时更新数据,并在固定时间中断中进行二次滤波。mcu将读取的十六位数据打断,分成前八位与后八位,以0x03、~0x03为数据针头,~0x03、0x03为数据针尾,将以上数据打包,最后以字符形式发送。数据上传部分通过esp8266模块以热点形式与电脑连接实现无线数据传输,进而将数据传入网络,并上传至云端的数据中心。
[0084]
s2:对原始多维时间序列样本进行预处理;
[0085]
使用一种基于掩码mask的方法,选取一种插值算法,对数据处理模块得到的数据进行去噪和插值操作;
[0086]
取来一段完整的时间序列作为样本,随机遮盖掉其中的10%,利用线性插值、二次插值、移动平均、指数平均等不同的插值算法对其进行还原,若还原后与原序列差异较小,则说明该插值方案比较对该序列的特征适应性较优。最后选取卡尔曼滤波作为插值算法。
[0087]
s3:对预处理后的多维时间序列样本进行重采样;
[0088]
将某段时间序列进行伸缩变换,再以滑动窗口的模式进行重采样,以不同的时间间隔提取原样本,提取不同尺度的多维时间序列特征。
[0089]
确定一个长度固定的滑动窗口,然后将它以一定的步长,从序列的开始不断向右移动,每次移动后覆盖的序列区域就是一个小样本,这样就实现了把原始长时间序列划分成多个子序列,作为新的数据集用于模型的训练,预设滑动窗口大小为input_window,输入样本序列总长度为seq_len,多维时间序列维度为in_dim,故输入的样本是一个二维张量x
in
∈ r
seq_len
×
in_dim
,经过多尺度拉伸变换和滑动窗口重采样得到样本为三维张量x
′
in
∈ r
batc_size
×
input_window
×
in_dim
。
[0090]
s4:构建包括数据重采样增强、编码器、解码器三个部分的模型并进行预训练;
[0091]
s4.1:使用噪声函数破坏序列。
[0092]
利用token masking、token deletion、text infilling、sentence permutation、documentrotation五种噪声函数方法来破坏预训练时输入的时间序列,破坏s3步骤得到的时间序列。加大预训练阶段序列重建任务的难度,从而使得模型能够更好地学习和提取多维时间序列中的特征。
[0093]
s4.2:构建编码器网络骨架部分。
[0094]
选用自注意力层和mlp网络作为骨干网络,迭代12次构成编码器。先将多维时间序列进
[0095][0096][0097]
行标准化,从而消除量纲的影响,再使用位置编码(position encoding),为多维时间序列加入位置信息,防止后续注意力机制中的并行导致位置信息缺失。
[0098]
pos指不同的时间点位置,2i和2i+1分别对应某个时间点的不同维度指标,奇数维度利用sin 正弦编码,偶数维度利用cos余弦编码,d
model
指数据的总维度,这里是防止10000的指数过大而溢出。而后利用三个线性层生成q(query),k(key),v(value)三个矩阵,并且使用q去访问每一个k,经过缩放和softmax(先转化为以e为底的指数,而后做归一化:) 后作为v的权重,从而计算attention值用于后续的mlp层和解码器进行序列重建:
[0099][0100]
再引入多头机制以适应更高维度的时间序列信息:
[0101]
multihead(q,k,v)=[head1,...,headh]w0[0102][0103]
其中h为注意力头数量,使用多头注意力时必须确保输入维度的大小必须能被注意力头数量整除,将输入维度分成h组,每组特征具有自己的注意力体系。
[0104]
s4.3:构建解码器部分。
[0105]
同样由多头自注意力层和mlp层作为网络骨架,经过一次堆叠后,利用交叉多头注意力聚合操作(cross attention)与编码器最后一层的隐藏状态结果进行注意力聚合计算,而后进行多次自注意力层mlp层的堆叠。取编码器中自注意力机制得到的k(key),v(value)与解码器中训练得到的q(query)进行聚合计算,并在每次mlp后加上标准化层,采用的是 layer normalization,设h是一层中隐层节点的数量,l是mlp的层数,我们可以计算 layer normalization的归一化统计量μ
l
和σ
l
:
[0106][0107]
上面统计量的计算是和样本数量没有关系的,它的数量只取决于隐层节点的数量,所以只要隐层节点的数量足够多,我们就能保证ln的归一化统计量足够具有代表性,经过l层mlp 后输出的数据为i表示维度,记作in_dim,通过μ
l
和σ
l
可以得到归一化后的值其中∈取 1e-5
防止除0。最后以自回归的方式对被破坏的时间序列进行复原重建。复原重建程度通过动态时间规整指标来评估。即把两个时间序列进行对齐后,求算出一个差异矩阵,目标是在矩阵中找到一条从(0,0)到(n,n)的路径,使得该路径上的元素的累加欧拉距离最小,这样的一条路径被称为wraping path,即为动态时间规整指标,用于表示两个时
间序列的相似度:
[0108]
先构造一个n
×
n的矩阵,矩阵的(i
th
,j
th
)元素是点qi和cj之间的欧几里德距离d(qi,cj)。wraping path定义了时序q和c之间的映射,记作p。是一组连续的矩阵元素,p的第th个元素定义为p
t
=d(qi,cj)
t
,其中p=p1,p2,...,p
t
,n≤t≤2n-1,本质上是通过一个动态规划的方法来求得的:
[0109]dij
=d(xi,yj)
[0110]
d(i,j)=d
ij
+min{d(i-1,j),d(i,j-1),d(i-1,j-1)}
[0111]
其中,d(i-1,j)表示x
i-1与yj匹配时的子序列距离,d(i,j-1)表示xi与y
j-1匹配时的子序列距离,d(i-1,j-1)表示x
i-1与y
j-1匹配时的子序列距离。在多变量时间序列中, xi和yj都是in_dim维的向量,而且xi中的元素是时刻i下变量的值,yj中的元素是时刻j下变量的值,d(xi,yj)即是i时刻的xi和j时刻的yj对齐时的距离。向量xi和yj之间的距离计算方式 d(xi,yj)通过欧氏距离来计算。
[0112]
欧氏距离:
[0113][0114]
s4.4:预训练过程
[0115]
对采集到的数据进行重采样,作为原序列,而后对原序列进行序列破坏,而后将其传入模型做前向推理(forward),经过编码器和解码器处理,得到一个新序列,记该序列为原序列的重建序列。
[0116]
再利用动态时间规整指标来衡量原序列与其重建序列之间的相似度,记作dtw,构造损失函数:
[0117][0118]
计算得到重建前后损失后,进行反向传播,更新模型参数,使得损失越来越小直至收敛到损失不再下降,在此过程中模型逐渐学习多维时间序列中的特征,做到自动提取特征的功能,此为预训练过程,最终得到一个具有序列提取能力的预训练模型,供之后下游任务的使用。
[0119]
s5:对预训练后的模型进行小样本微调和序列点分类。
[0120]
利用少量的样本,重复训练过程,在下游任务中做小样本的微调(fine tuning)。
[0121]
数据集为一长串多维时间序列,首先随机在数据集中抽取10%的连续序列作为样本,重复训练过程,在下游任务中做小样本的微调(finetuning):输入为预处理后的多维时间序列x
′
in
∈ r
batch_size
×
input_window
×
in_dim
,经过编码器和解码器重建序列得到,经过编码器和解码器重建序列得到计算动态时间规整指标,用于表示两个时间序列的相似度,再计算
[0122]
最后对loss进行k-means聚类得到异常点:
[0123]
(1)首先设置参数k,k的含义为将数据聚合成几类(这里取k=2);
[0124]
(2)从数据当中,随机的选择两个点,成为聚类初始中心点;
[0125]
(3)计算所有其他点到这两个点的距离,然后找出离每个数据点最近的中心点,将该点划分到这个中心点所代表的的簇当中去。那么所有点都会被划分到两个簇当中去;
[0126]
(4)重新计算两个簇的质心,作为下一次聚类的中心点;
[0127]
(5)重复上面的3-4步的过程,重新进行聚类,不断迭代重复这个过程;
[0128]
(6)当重新聚类后,所有样本点归属类别都没有发生变化的时候停止;
[0129]
最后可以得到两类样本,样本数量少的一类即为异常。
[0130]
实际情况中,企业为了排放不超标,私自进行上传数据的修改:当接受到的排放数据指标在某个时间段有上升趋势,但是在过程中的某个时间点之后突然快速下降,产生了“尖刺状”的数据变化情况,并且这一现象在近段时间内未曾出现过,那么有理由推测,监测对象可能在发现排污指标呈上升趋势且将要超标时,对检测设备进行了外部干涉,或者在上传的数据有篡改行为发生,并将相应的时间点标记为异常数据,对该公司及与其共用排污口的公司进行异常标记,最后通过聚类的方法找出所有的异常点。
[0131]
s6:利用步骤s5得到的模型进行排污异常监控。
[0132]
进一步的,将模型集成在可视化大屏管理平台中,搭建前后端,形成“政府”、“企业”、“个人”三个视角的管理体系。
[0133]
前端方面基于react框架开发,使用axios与后端进行交互获取分析后的公司排污数据,并引入datav和antv进行公司排污异常数据可视化,直观展示公司的排污异常状态。后端使用golang进行后端开发,主要使用轻量化的gin和gorm框架,gin框架相比于原生http,具有更好的性能和更多的拓展功能。使用gorm框架编写持久化层对mysql进行高效地数据读写和管理。系统设计方面,将用户分为政府管理员、公司人员、游客三级,不同的级别具有不同权限,例如管理员(政府相关管理人员)可以修改公司的异常状态,公司可以进行异常申诉,游客可以进行举报等。gin框架与python的flask相结合,gin负责处理路由,flask负责数据处理以及模型运行,利用numpy、pandas等数据处理库,以及用pytorch框架编写的模型,处理得到相关指标和数据,返回给前端进行可视化展示,两种编程语言优势互补,有机结合,充分发挥了他们在不同领域的功能优势。
[0134]
通过编写dockerfile将本地项目及各种依赖进行打包,生成docker镜像,上传至仓库后,在服务器端进行镜像拉取并创建容器进行应用服务的部署。docker可以在很多平台上运行,可以很轻易的将在一个平台上运行的应用,迁移到另一个平台上,而不用担心运行环境的变化导致应用无法正常运行的情况,我们应用docker技术将应用服务部署在了阿里云服务器上,虽然用到的依赖较多较杂,但在docker容器技术的支持下轻松完成。
[0135]
本发明能对标准数据集(即硬件采集后上传的数据集)某段时间某个端口的排污时序数据进行重建,比较重建前后差异,并进行聚类得到异常。
[0136]
用户也可以上传指定格式的表格,可以帮助用户自主分析多维时间序列异常:
[0137]
用户上传的表格如图2所示,用户预先选择两端时间,就可以对多维时间序列进行异常分析,返回异常时间点、两段时间的单维度异常对比情况(如异常点数量增幅等),还有两段时间的多维度异常对比情况(即考虑所有污染物的综合情况,统计异常信息输出)。
[0138]
以上所述,仅为本发明部分具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本领域的人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在
本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1