多方协作数据学习系统及学习模型训练方法
1.本发明涉及一种数据信息技术,特别涉及一种多方协作数据学习系统及学习模型训练方法。
背景技术:
2.人工智能的发展,依赖于大量信息数据,驱使深度学习在大型有标注数据集的数据支撑下取得了巨大的进步,获得的深度学习模型在生产实践中得到了广泛应用,如人脸识别系统、烟雾报警系统、智能车间、自动驾驶等。此外,深度学习在医疗领域、金融领域、工业领域、教育领域等等都有着巨大的发展前景。近年来,互联网发展成熟,物联网快速发展,各行各业每天都会产生大量的数据,如何利用好这些数据对深度学习模型进行训练成为一大现实挑战。
3.利用这些数据面临着以下的难题:第一,这些数据呈现出数据量大,价值密度低的特点,大多需要通过人工标注或其他代价巨大的方法进行标注。由于标注数据集的成本很高,这促使了众多研究人员研究寻找方法来减少标注代价,产生了主动学习等研究方向;第二,一个优秀的深度学习模型离不开大量的数据驱动,首先某领域内的单个企业收集的数据量可能无法达到对深度学习模型进行训练的需求,其次某些企业需要收集的数据不属于企业,这些数据可能属于个人或其他企业,因此想通过合作,采用传统的数据集中式方式,即多个企业或个人将这些数据上传到同一个高性能服务器中心进行深度学习模型训练,这样滋生出隐私保护、行业竞争、法律约束、知识产权保护、数据的存储和通讯等诸多问题。为解决这些问题,研究人员提出了联邦学习框架。
技术实现要素:
4.针对学习模型精度提高依赖大量高质量数据问题,提出了一种多方协作数据学习系统及学习模型训练方法,充分利用主动学习和联邦学习的优点,针对分类任务,在保护数据隐私的前提下,各个客户端的已标注数据信息进行联邦学习协作训练,利用联邦学习训练的得到的模型指导各个参与方进行主动学习,对信息性样本进行采样,接着进一步地进行联邦学习训练,最终尽可能地减少样本标注成本,并提高模型的精度和泛化性能。
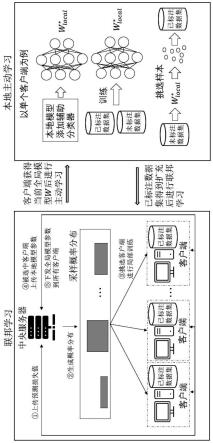
5.本发明的技术方案为:一种多方协作数据学习系统,包括布局全局模型的中央服务器和多方带本地分类模型的客户端,中央服务器下发模型参数,客户端利用本地标签数据进行推理和训练,推理和训练结果返回中央服务器,中央服务器接收多方客户端结果进行联邦学习训练全局模型;客户端根据获得训练后全局模型参数,对本地未标签的数据进行主动学习,扩充本地标签数据集,全局模型对多方客户扩充后的标签数据集再次进行联邦学习。
6.一种多方协作数据学习模型训练方法,具体包括如下步骤:
7.1)中央服务器初始随机生成全局模型参数w下发到所有客户端;
8.2)各个客户端接收中央服务器下发的全局模型参数w,并加载到本地模型,利用本
地模型对本地已标注数据集d
l
的所有样本执行一次模型推理,记录下本轮学习的预测损失值并上传到中央服务器;
9.3)中央服务器接收到所有客户端上传的一轮预测损失值集合v,对预测损失值集合v中所有元素进行线性数值映射,使其加和为1,并按照数值映射后的大小作为概率分布进行参加下一轮联邦学习客户端的挑选,挑选客户端的数量占客户端数量的一半;
10.4)被选中的客户端利用本地已标注数据集d
l
对本地模型进行训练,并将更新后的本地模型参数上传到中央服务器;
11.5)中央服务器接收被选中的客户端上传的本地模型参数利用模型聚合算法更新全局模型参数w并下发到所有客户端;
12.6)迭代训练,重复2)-5),直到满足一定的训练次数,完成联邦学习全局模型训练;
13.7)各个客户端接收中央服务器下发的全局模型训练后更新后参数w
*
,并加载到本地模型,进行主动学习,利用本地模型挑选出最具信息增益的未标注的样本,并请求专家对样本进行标注;
14.8)对补充后已标注数据集返回执行步骤6)再次进行全局模型训练,直到标注数据集无法扩充。
15.进一步,所述步骤2)中预测损失值的计算公式为:
[0016][0017]
其中v
it
表示第i个客户端第t轮联邦学习的预测损失值,t表示第t轮联邦学习训练,i表示第i个客户端,ni表示第i个客户端目前已标注数据集d
l
中拥有的样本数量,l(
·
)表示损失函数,xk、yk分别表示第k个样本和样本标签,w
local
表示本地模型参数。
[0018]
进一步,所述步骤3)中线性数值映射的计算公式为:
[0019][0020]
其中newv
it
表示v
it
经过线性数值映射后的值,表示所有客户端预测损失值的加和,线性数值映射后的预测损失值作为离散概率分布进行客户端抽样,预测损失值越高,客户端被抽样的概率越大。
[0021]
进一步,所述步骤5)中模型聚合算法公式为:
[0022][0023]
其中h为当前被选中客户端的个数,表示被选中客户端中第i个客户端上传的本地模型参数。
[0024]
进一步,所述步骤7)本地模型主动学习方法如下:
[0025]
7.1)在全局模型训练中本地模型架构上,额外添加两个辅助分类器接到本地模型中主干网络后,与本地模型的主分类器并行,构成本地主动学习模型;
[0026]
7.2)利用已标注数据集d
l
和未标注数据集du对本地主动学习模型进行训练;
[0027]
7.3)以差异损失函数为目标函数来训练最大化辅助分类器之间的差异,获得更加
紧密的决策边界,从而在未标注的样本挑选出高信息性样本加入标签数据集。
[0028]
进一步,所述额外添加两个辅助分类器与主分类器网络架构一模一样,网络参数由主分类器的网络参数添加随机高斯噪声生成,添加的随机高斯噪声p~n(0,0.1),数据样本经过主干网络后得到的特征图分别进入主分类器和辅助分类器,分类器之间互不影响。
[0029]
进一步,所述步骤7.2)本地主动学习模型的训练方式如下:
[0030]
以θ表示主干网络和主分类器,以b表示主干网络,以θ1和θ2表示两个辅助分类器,以p表示样本经过θ输出的概率分布,以p1表示样本经过(b,θ1)输出的概率分布,以p2表示样本经过(b,θ2)输出的概率分布;
[0031]
a:利用已标注数据集对本地主动学习模型进行训练;
[0032]
a-1:计算样本经过θ、(b,θ1)、(b,θ2)推理产生的交叉熵损失l
ce
:
[0033]
交叉熵损失函数的计算公式为:
[0034][0035]
其中c为样本类别总数,c表示样本类别,1表示指示函数,pc(y|x)表示样本x属于c类的概率;
[0036]
a-2:对本地主动学习模型参数进行更新,其中η为学习率,为梯度:
[0037][0038][0039][0040]
b:利用未标注数据集对辅助分类器进行训练;
[0041]
b-1:计算样本经过(b,θ1)、(b,θ2)推理产生的差异损失l
dist
:
[0042]
l
dist
=d(p1,p2)+d(p1,p)+d(p2,p),
[0043][0044]
b-2:对辅助分类器参数进行更新:
[0045][0046][0047]
本发明的有益效果在于:本发明多方协作数据学习系统及学习模型训练方法,通过联邦学习将所有客户端的少量已标注数据集充分利用起来,用于指导单个客户端主动学习的样本采样;在联邦学习训练中,利用预测损失值作为概率分布对客户端进行抽样训练,可以加快模型收敛和降低通信量;在主动学习中,通过最大化辅助分类器之间的差异,可以获得更加紧密的决策边界,从而有效的挑选出高信息性样本;利用主动学习和联邦学习的优点,在保护数据隐私的前提下,能够充分利用各参与方的大量未标注数据进行模型的协同训练。
附图说明
[0048]
图1为本发明多方协作数据学习系统的架构示意图;
[0049]
图2为本发明多方协作数据学习模型训练方法的流程框图;
[0050]
图3为本发明多方协作数据学习系统中样本采样策略示意图。
具体实施方式
[0051]
下面结合附图和具体实施例对本发明进行详细说明。本实施例以本发明技术方案为前提进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
[0052]
如图1所示多方协作数据学习系统的架构示意图,本地客户端将全局模型参数载入到本地模型,利用本地标签数据进行本地模型推理,获取预测损失值发回中央服务器,用于中央服务器对参加下一轮联邦学习客户端的挑选;被选中的客户端利用本地已标注数据进行本地模型的训练后,将本地模型参数上传至中央服务器,中央服务器对选中客户端模型参数进行聚合得到更新后的全局模型,并将更新后的全局模型参数下发所有客户端,进行下一轮联邦学习,当全局模型收敛后结束联邦学习训练。客户端将训练后的全局模型参数载入到本地模型,利用本地模对本地未标注的数据进行主动学习,扩充本地已标注数据集,之后再进行联邦学习。
[0053]
如图2所示多方协作数据学习模型训练方法的流程框图,结合图2,对多方主动联邦学习系统实现和学习模型训练具体方法进一步进行阐述,具体包括如下步骤:
[0054]
s100、中央服务器初始随机生成全局模型参数w下发到所有客户端;
[0055]
s200、各个客户端接收中央服务器下发的全局模型参数w,并加载到本地模型,利用本地模型对本地已标注数据集d
l
的所有样本执行一次模型推理,记录下本轮联邦学习的预测损失值v
it
并上传到中央服务器;
[0056]
具体的,预测损失值v
it
的计算公式为:
[0057][0058]
其中t表示第t轮联邦学习训练,i表示第i个客户端,ni表示第i个客户端目前已标注数据集d
l
中拥有的样本数量,l(
·
)表示损失函数,xk、yk分别表示第k个样本和样本标签,w
local
表示本地模型参数。
[0059]
每个客户端本地都会保存有少量样本的已标注数据集d
l
和大量样本的未标注数据集du,预测损失值的计算公式的分母为已标注样本数量开平方的原因是:一方面向拥有较多已标注数据样本的客户端倾斜;另一方面降低可能因某客户端已标注数据集中样本数量少,且存在大量噪声数据的影响。
[0060]
s300、中央服务器接收到所有客户端上传的一轮预测损失值集合v,m表示客户端的数量,对预测损失值集合v中所有元素进行线性数值映射,使其加和为1,并按照数值映射后的大小作为概率分布进行参加下一轮联邦学习客户端的挑选,挑选客户端的数量占客户端数量的一半;
[0061]
具体的,线性数值映射的计算公式为:
[0062]
[0063]
其中newv
it
表示v
it
经过线性数值映射后的值,表示所有客户端预测损失值的加和。
[0064]
此步骤的有益之处,中央服务器将线性数值映射后的预测损失值作为离散概率分布进行客户端抽样,预测损失值越高,客户端被抽样的概率越大。首先损失预测值越高的客户端的本地已标注数据集对当前全局模型的训练帮助越大,可以加快全局模型的收敛,其次在每一轮联邦学习训练中由于不是所有的客户端都参加训练,所以可以降低通讯量。
[0065]
s400、被选中的客户端利用本地已标注数据集d
l
对本地模型进行训练,并将更新后的本地模型参数w
local
上传到中央服务器;
[0066]
s500、中央服务器接收被选中的客户端上传的本地模型参数利用模型聚合算法更新全局模型参数w并下发到所有客户端;
[0067]
具体的,聚合全局模型的算法公式为:
[0068][0069]
其中h为当前被选中客户端的个数,表示被选中客户端中第i个客户端上传的本地模型参数。
[0070]
s600、迭代训练,重复s200-s500,直到满足一定的训练次数,完成联邦学习全局模型训练;
[0071]
此步骤的有益之处,重复s200-s500可以充分利用各个客户端现有的已标注数据样本的信息,通过联邦学习训练获得全局模型比单个客户端利用少量已标注样本进行训练得到的本地模型具有更好的性能,利用全局模型指导各个客户端进行主动学习,可以更好地查询到对模型性能具有增益的样本。
[0072]
s700、各个客户端接收中央服务器下发的全局模型训练后更新后参数w
*
,并加载到本地模型,进行主动学习,利用本地模型挑选出一部分最具信息增益的未标注的样本,并请求专家对样本进行标注。如图3所示,s700中各个客户端进行主动学习包含如下步骤:
[0073]
s700-1、对本地模型架构进行修改,同主分类器classifier模块,额外添加两个辅助分类器classifier1、classifier2模块接到主干网络network backbone模块后,建立本地主动学习模型;
[0074]
s700-2、利用已标注数据集d
l
和未标注数据集du对本地主动学习模型进行训练;
[0075]
s700-3、利用本地主动学习模型从未标注数据集du中挑选出一部分最具信息增益的未标注的样本移动到已标注数据集d
l
。
[0076]
具体的,在步骤s700的子步骤s700-1中,额外添加两个辅助分类器classifier1、classifier2模块与主分类器classifier模块网络架构一模一样,网络参数由主分类器的网络参数添加随机高斯噪声生成。添加的随机高斯噪声p~n(0,0.1),数据样本经过主干网络network backbone模块后得到的特征图feature map会分别进入主分类器和辅助分类器,分类器之间互不影响。
[0077]
具体的,在步骤s700的子步骤s700-2中,以θ表示主干网络模块和主分类器模块,以b表示主干网络,以θ1和θ2表示两个辅助分类器模块,以p表示样本经过θ输出的概率分布,
以p1表示样本经过(b,θ1)输出的概率分布,以p2表示样本经过(b,θ2)输出的概率分布,本地主动学习模型的训练方式如下:1、利用已标注数据集对本地主动学习模型进行训练;
[0078]
(1)计算样本经过θ、(b,θ1)、(b,θ2)推理产生的交叉熵损失l
ce
:交叉熵损失函数的计算公式为:
[0079][0080]
其中c为样本类别总数,c表示样本类别,1表示指示函数,pc(y|x)表示样本x属于c类的概率。
[0081]
(2)对本地主动学习模型参数进行更新,其中η为学习率,为梯度:
[0082][0083][0084][0085]
2、利用未标注数据集对辅助分类器进行训练;
[0086]
(1)计算样本经过(b,θ1)、(b,θ2)推理产生的差异损失l
dist
:
[0087]
差异损失函数的计算公式为:
[0088]
l
dist
=d(p1,p2)+d(p1,p)+d(p2,p),
[0089][0090]
(2)对辅助分类器参数进行更新:
[0091][0092][0093]
辅助分类器同主分类器在模型架构上一模一样,其不同点在于:
[0094]
(1)参数不同,辅助分类器的参数由主分类器的参数添加随机高斯噪声得到,所以三个分类器的参数都不一样;
[0095]
(2)本发明可以简述为三个阶段,初始联邦学习阶段-本地主动学习阶段-本地已标注数据集扩充后的联邦学习阶段,主分类器的参数是初始联邦学习训练得到的,在本地主动学习阶段中,对本地模添加两个辅助分类器后,还需要对本地模型进行训练,其中,主分类器的参数仅在利用已标注数据集进行训练的时候进行更新,
[0096][0097]
然而,两个辅助分类器的参数不仅在利用已标注数据集进行训练的时候进行更新:
[0098][0099][0100]
还会在利用未标注数据集进行训练的时候更新:
[0101][0102][0103]
辅助分类器在利用未标注数据集进行参数更新,其目的是以差异损失函数为目标
函数来训练最大化辅助分类器之间的差异,获得更加紧密的决策边界,从而挑选出高信息性样本加入标签数据集。
[0104]
具体的,在步骤s700的子步骤s700-3中,根据f(x)的数值大小降序排序,依次从未标注数据集du中挑选出一部分最具信息增益的未标注的样本移动到已标注数据集d
l
,f(x)的计算公式为:
[0105]
f(x)=d(p1(x),p2(x))。
[0106]
此步骤的有益之处,在本地模型上增加两个辅助分类器,由于其架构同主分类器一样,因此实现简单,以差异损失函数为目标函数来训练最大化辅助分类器之间的差异,可以获得更加紧密的决策边界,从而有效的挑选出高信息性样本。
[0107]
s800、对补充后已标注数据集返回执行步骤s600再次进行全局模型训练,直到标注数据集无法扩充。
[0108]
此步骤的有益之处,经过s700后各个客户端的已标注数据集得到进一步的扩充,此时接着进行联邦学习训练可以得到性能更好的模型。
[0109]
在本实施方式中,如图2所示,基于上述方法实现的一种主动联邦学习模型训练系统,包括中央服务器以及若干个参与方设备,且所述参与方设备保存有大量的未标注数据集,此外每个参与方都会有相关的领域专家能够对数据样本进行高质量的标注工作。
[0110]
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1