一种实体识别方法及系统、计算机可读存储介质及终端
1.本发明属于知识图谱构建技术领域,涉及面向生态环保类案件知识图谱的实体识别技术,具体涉及一种实体识别方法及系统、计算机可读存储介质及终端。
背景技术:
2.知识图谱通过信息处理技术将现实世界的概念、实体、事件以及它们之间的关系呈现为语义网络图,在其构建过程中涉及众多的技术,包括知识抽取、知识表示、知识推理等。虽然知识图谱在个性化推荐、智慧交通、智能政务等场景中被广泛应用,但是其发展过程中仍面临较多挑战,主要体现在计算效率低、数据稀疏两个方面。
3.当前的生态环保类案件知识图谱由于捕捉了案件实体之间的异构关联关系而具有巨大的发展潜力。在日常生活中,随着人们对环境的保护意识越来越强烈,污染环境等违法行为更多的被大众注意到。众多的生态环保类的法律案件需要被审判,但是由于法官等工作人数的有限,案件的数量居高不下,对工作人员造成很大的工作压力,为此构造一套生态环保类法律案件的智能审判系统是非常迫切的,以期达到将未经审判的生态环保类的法律案件输入智能审判系统,该智能审判系统可以输出该生态环保案件的审判结果以及对应的审判依据(法律条例)。
4.构造该智能审判系统需要需要构建关于生态环保类的法律案件的知识图谱,但是在生态环保类法律案件的文书中有大量与智能审判不相关的背景信息与知识,这些文本信息有其内在的语义逻辑,并不以智能审判为导向,需要进一步对文本信息的数值空间表示进行变换,以突出与智能审判等任务高度相关的要素信息,然后提取出与智能审判相关的文本信息。从分类的角度来看,文本信息的数值向量变换后的数据应呈现简单的(如:线性可分、同类数据局部聚集)分布状态。
5.知识图谱表征学习领域的谱聚类算法、卷积图神经网络、序列化神经网络等方法实现了知识图谱的向量化,即实现了非结构数据向结构数据的转变。但事实上知识图谱同时也面临着文书分析中数据来源较为复杂,有效信息提取识别率低、准确率低等问题。
6.现有技术缺陷:(1)以使用最广泛的核函数
‑‑‑
径向基核函数为例,其运算时函数中的两两数据点的距离度量可能并不合适。与距离度量学习被提出的原因类似,径向基函数的结果很容易受到特征的大小和特征之间相互作用的影响。因此,在进行核变换之前,需要对数据点的距离度量标准进行修正。
7.(2)标准的nystr
ö
m等核变换拟合方法是通过无监督进行学习的,其性能很大程度上依赖于内置核函数的参数设置。但是核函数的最优参数搜索相当耗时,这也在一定程度上削弱了nystr
ö
m等核变换方法的速度优势;(3)距离度量学习和核变换拟合一般来说是两个独立的学习过程,不能保证整体优化。两者都有各自的优化目标,不能保证整体优化。
技术实现要素:
8.为解决上述现有技术问题,本发明提供一种实体识别方法及系统、计算机可读存储介质及终端。
9.为了实现上述目的,本发明采用的技术方案是:提供一种实体识别方法,其特征在于,包括获取生态环保类法律案件的文书的文本信息,文本信息包括与案件审判有/无关的文本信息;配置为将文本信息与其对应的标签转换为数值向量,配置标签为与案件审判相关的类别;配置面向知识图谱的算法,配置为将已标注的数据集输入该算法进行训练,得到优化模型,数据集包括生态环保类法律案件的文书的文本信息及与其对应的标签;配置为将训练好的优化模型用于分类器中,使分类器对未审判的生态环保类法律案件的文书的文本信息进行分类,完成未审判的生态环保类法律案件的文书的文本信息的抽取。
10.优选的,nystr
ö
m映射单元;nystr
ö
m单元;分类单元;其中,nystr
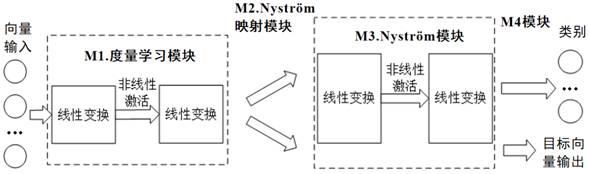
ö
m映射单元用于将输入数据映射到高维度/隐式的内积空间,配置为使数值向量为nystr
ö
m映射单元的输入数据;其中,nystr
ö
m单元用于核变换拟合与最优化核参数的自动学习,配置nystr
ö
m映射单元输出的数据为nystr
ö
m单元的输入数据;其中,分类单元用于对nystr
ö
m单元的输出数据进行概率计算,分类单元输出带有类别信息的目标向量。
11.优选的,配置在nystr
ö
m映射单元前具有度量学习单元,度量学习单元用于提高面向知识图谱的算法的非线性拟合能力,配置为使数值向量为度量学习单元的输入数据,度量学习单元的输出配置为nystr
ö
m映射单元的输入数据。
12.优选的,度量学习单元具有全连接层和激活函数层;度量学习单元的输入数据通过多个全连接层和激活函数层进行变换。
13.优选的,配置度量学习单元的无约束目标损失函数为,(1)其中,表示参考数据点;其中,表示与距离最近的相同标签的数据点;其中,表示与距离最近的相异标签的数据点;其中,数据点配置为带有文本信息与类别信息的数值向量;其中,表示非线性变换函数。
14.优选的,配置在度量学习单元前具有局部敏感哈希方法,用于降低三元组数据的搜索时间;
其中,配置所述三元组数据为相同、相异标签最近邻数据对为。
15.优选的,一个核矩阵为,nystr
ö
m方法使用矩阵近似替代a,(2)其中,表示的广义伪逆矩阵,存在特征分解使矩阵中的每个元素分解为;(3)其中,径向基核函数;其中,为代表性的数据点;令,(4)则公式(3)可化简为,(5)其中,c为对核矩阵的行/列的一个抽样,t为转置。
16.优选的,nystr
ö
m映射单元中,核变换拟合中的配置为输入数据点与之间的核函数;其中,输入数据点为度量学习单元的输出数据。
17.优选的,nystr
ö
m单元可配置为具有全连接层和激活函数层;配置nystr
ö
m单元的非线性变换函数为,径向基核函数为,(6)其中,表示径向基函数的最优化参数,d为次幂,d为不小于1的整数。
18.优选的,分类单元配置为采用交叉熵损失函数,总体损失函数为,(7)其中,表示超参数;其中,表示分类交叉熵损失函数;其中,表示度量学习单元的损失函数。
19.提供一种实体识别的系统,其特征在于,包括,信息获取模块,用于获取生态环保类法律案件的文书的文本信息与其对应的标签信息,构建训练需要的数据集;模型训练模块,用于将已标注的生态环保类法律案件的文书的文本信息及与其对
应的标签的训练样本进行训练,得到优化模型;模型应用模块,包括分类器,将优化模型用于分类器中使分类器对未审判的生态环保类法律案件的文书的文本信息进行分类;实体提取模块,用于根据分类器识别文本信息的类别来提取实体。
20.提供一种计算机可读存储介质,其特征在于,用于存储指定计算机程序,所述指定计算机程序的执行实体抽取方法。
21.提供一种终端,其特征在于,包括:存储器;处理器;其中,所述存储器用于存储可执行程序代码;其中,所述处理器与所述存储器耦合;所述处理器调用所述存储器中存储的所述可执行程序代码,执行实体抽取方法。
22.本发明的有益效果体现在,提供一种实体识别方法及系统、计算机可读存储介质及终端。将生态环保类法律案件构建的与审判有关的关键信息提取出来,有助于对知识图谱的节点特征之间的复杂交互关系进行解耦,以更好地呈现由特征所反映的生态环保类案件的法律、法规审判和决策类应用问题,消除知识图谱节点特征的复杂分布模式,解决多准则、多目标的特征重要性评估问题;提出端到端的生态环保类案件大数据知识图谱自动化表征技术,即通过自动化的学习和训练,将知识图谱的结构分布特点与节点特征嵌入到数值型的向量空间,实现生态环保类案件知识图谱数据的非结构化向结构化表示的转变。
23.附图说明:图1-图8为本发明实施例,图1示出了集成度量学习与核变换拟合的神经网络结构与变换流程图;图2示出了将知识映射到向量空间示意图;图3示出了三元组的部分存储形式;图4示出了使用6种知识图谱的数据集;图5示出了6种知识图谱的数据集及其变换后的效果图图6示出了本算法与其它距离度量学习方法及非线性变换方法的运行时间对比 (秒);图7示出了本算法与其它距离度量学习方法对距离分类器的auc提升对比(%);图8示出了本算法与其它非线性变换方法的auc 对比 (%)。
具体实施方式
24.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
25.请参阅图1-图8所示,本发明提供的具体实施例如下:实施例1:一种实体识别方法,其特征在于,包括
获取生态环保类法律案件的文书的文本信息,文本信息包括与案件审判有/无关的文本信息;配置为将文本信息与其对应的标签转换为数值向量,配置标签为与案件审判相关的类别;配置面向知识图谱的算法,配置为将已标注的数据集输入该算法进行训练,得到优化模型,数据集包括生态环保类法律案件的文书的文本信息及与其对应的标签;配置为将训练好的优化模型用于分类器中,使分类器对未审判的生态环保类法律案件的文书的文本信息进行分类,完成未审判的生态环保类法律案件的文书的文本信息的抽取。
26.知识图谱本质上是结构化的语义知识库,用符号的形式描述现实世界中的概念及其相互关系。其基本组成单位是“实体-关系-属性”三元组,以及实体及其相关属性,实体间通过关系相互连接,构成网状的知识结构,三元组可以更好地描述出实体与实体之间的关系,能够更加多样化地对知识图谱进行搜索。在构造生态环保类法律案件的知识图谱时,训练数据主要来源法院案件文书,将生态环保类法律案件的与智能审判相关的重点信息区分出来,重点信息是通过分析真实审判案件中法官的审判标准及审判关注信息得到的,从而提取出模拟法官审判所需要的重点信息,也就是实体识别。实体提取的准确与否对知识图谱的构建有非常大的影响,在生态环保类法律案件中,如果提取的实体不是审判需要的重点信息,不仅其构建的知识图谱偏离事实,而且还会给使用知识图谱搜索的人一种误解。为此,准确提取出实体是非常有价值的。
27.在本实施例中,提出一种实体识别方法,获取生态环保类法律案件的文书的文本信息,文本信息包括与案件审判有/无关的文本信息;然后配置为将文本信息与其对应的标签转换为数值向量,配置标签为与案件审判相关的类别;配置面向知识图谱的算法,配置为将已标注的数据集输入该算法进行训练,得到优化模型,数据集包括生态环保类法律案件的文书的文本信息及与其对应的标签;配置为将训练好的优化模型用于分类器中,使分类器对未审判的生态环保类法律案件的文书的文本信息进行分类,完成未审判的生态环保类法律案件的文书的文本信息的抽取。本发明的提取实体的方法可以将生态环保类法律案件的文书中与智能审判高度相关的信息提取出来,而滤掉与智能审判无关的文本信息,为构建生态环保类案件的知识图谱提供更接近审判的实体,为整个智能审判系统打好基础。
28.实施例2:面向知识图谱的算法包括,nystr
ö
m映射单元;nystr
ö
m单元;分类单元;其中,nystr
ö
m映射单元用于将输入数据映射到高维度/隐式的内积空间,配置为使数值向量为nystr
ö
m映射单元的输入数据;其中,nystr
ö
m单元用于核变换拟合与最优化核参数的自动学习,配置nystr
ö
m映射单元输出的数据为nystr
ö
m单元的输入数据;其中,分类单元用于对nystr
ö
m单元的输出数据进行概率计算,分类单元输出带有类别信息的目标向量。
29.配置在nystr
ö
m映射单元前具有度量学习单元,度量学习单元用于提高面向知识图谱的算法的非线性拟合能力,配置为使数值向量为度量学习单元的输入数据,度量学习单元的输出配置为nystr
ö
m映射单元的输入数据。
30.nystr
ö
m方法可以把对n阶矩阵的特征分解问题,转化为对l阶矩阵的特征分解问题,大大降低了计算复杂度。但是标准的nystr
ö
m等核变换拟合性能很大程度上依赖于内置核函数的参数设置,但核函数的最优参数搜索相当耗费时间,这在一定程度上削弱了nystr
ö
m等核变换方法的速度优势。
31.在本实施例中,将距离度量学习和核变换拟合统一为一个优化框架通过端到端的学习方式。针对知识图谱结构化后数值向量,设计并实现了一种新的整合度量学习与核变换拟合的神经网络结构,以缓解数据中的复杂分布问题。本发明的算法提高了模型的综合分类性能高,具体效果为:有效平衡了分类准确率、非平衡数据上的单侧分类精度,以及在不同参数下分类的鲁棒性。算法提升auc值,使得分类性能更好,实体识别与实体关系识别的准确性能越好,进而提高知识图谱的构建质量。构建的知识图谱可以更好地提炼生态环保类案件的文本中的碎片化信息、去除噪音(与审判无关的信息)、以及捕捉信息之间的复杂关联关系,建立非结构化文本信息与数理化数据挖掘模型与算法之间的桥梁,以使人工智能技术可以更方便地理解人类语言中的高阶语义信息,并支持知识图谱的下游数据挖掘任务,如智能法律案件审判中的潜在影响因素分析、案情推理、智能专家系统等。
32.实施例3:度量学习单元具有全连接层和激活函数层;度量学习单元的输入数据通过多个全连接层和激活函数层进行变换。
33.原始度量学习的基本思想是:在一定的约束条件下,学习一个线性距离度量矩阵,对原空间进行线性变换,以使相同“标签”的向量对之间的距离最小化,或者使不同“标签”类别的向量对之间的距离最大化。距离度量学习可以解决知识图谱向量空间的标签类别感知问题,但传统的度量学习面临如下局限:(1)多数数学优化模型仅能求解单次线性变换的最优化问题;(2)多数基于数学优化的度量学习为半定规划问题,时间复杂度高且难以求解;(3)相同/相异标签最近邻数据点对(三元组,triplet)搜索时间复杂度高。
34.在本实施例中,本发明将传统的度量学习封装为一种多层神经网络的非线性结构,如图1中m1模块所示:通过多层全连接神经网络层和非线性激活单元,使用多层神经网络各层之间的连接表示线性变换矩阵p,激活函数的主要作用是加入非线性因素,解决线性模型的表达、分类能力不足的问题。常见的激活函数包括:sigmoid、tanh、relu、leaky-relu、maxout等,本发明采用relu激活函数作为实施方式之一。本技术的度量学习模块比传统的“线性变换度量学习”具备更强的复杂非线性模式拟合能力,解决了上文提到的局限(1)“多数数学优化模型仅能求解单次线性变换的最优化问题”。
35.实施例4:配置度量学习单元的无约束目标损失函数为,(1)其中,表示参考数据点;其中,表示与距离最近的相同标签的数据点;
其中,表示与距离最近的相异标签的数据点;其中,数据点配置为带有文本信息与类别信息的数值向量;其中,表示非线性变换函数。
36.在本实施例中,在优化目标损失函数的构建方面,本发明提出无约束目标损失函数,通过计算“同标签最近邻数据点之间总距离”与“异标签最近邻数据点之间总距离”的比值,避免了减法函数容易导致的空间坍缩问题,并且通过pytorch神经网络框架实现梯度链的自动跟踪与计算,解决了上文提到的局限(2)“多数基于数学优化的度量学习为半定规划问题,时间复杂度高且难以求解”。
37.传统的表示学习方法只关注表示学习模型的准确性,而忽略了对于训练时间代价的优化,产生了巨大的时间代价。传统的度量学习的三元组搜索时间复杂度较高,由于用于构建三元组搜索是在单次输入的“小批量(mini-batch)”评论向量数据中进行的,搜索时间复杂度从降低为,其中n为总体样本数,m为“小批量”中的样本数,搜索时间复杂度大大降低。通过本发明所提出的度量学习神经网络模块结构与无约束的目标优化问题,可以使相同“标签”的数据在向量空间中的距离更近,相异“标签”的数据在向量空间中的距离更远,最终实现了知识图谱数据向量空间的标签类别感知效果。
38.实施例5:配置在度量学习单元前具有局部敏感哈希方法,用于降低三元组数据的搜索时间;其中,配置所述三元组数据为相同、相异标签最近邻数据对为。
39.在本实施例中,如图2所示,将知识映射到低维向量空间中参与计算。如图3所示包含部分三元组的存储形式,使用实体来表示自然界的物体或者抽象的概念,使用关系来建模实体之间的交互,其基本的存储形式是(头实体h,关系r,尾实体t)的三元组。本方案的三元组数据为相同、相异标签最近邻数据对,应用“局部敏感哈希(local sensitive hashing,lsh)”等技术,三元组搜索时间降低为,其中g为哈希桶数,进一步降低三元组搜索时间。
40.如图4所示,6个测试数据集来自于不同的法庭的生态环保类案件的数据,其中,d1-d2为6个数据集的名称,d1为“大熊猫法庭”生态环保类案件的数据集,d2为来源于中国政法大学研究院的生态环保类案件的数据集,d3来自于南京的通达海法院系统的生态环保类案件的数据集,d4为上海市的部分生态环保类案件的数据集,d5为武汉市的部分生态环保类案件的数据集,d6为重庆的部分生态环保类案件的数据集。其中,实例数为各个数据集中环保案件中的与案件审判有/无关的文本信息的数值向量的个数,每个数据集的文本信息向量化后,属性数为文本信息被压缩到的对应维度,例如,d1数据集对应的属性数为78,即例如d1数据集的文本信息向量化后被压缩到78维。
41.类针对这6个数据集,本算法与传统模型的运行时间对比如图6所示,其中“\”表示该算法在64g内存的服务器上仍内存崩溃,相较于lmnn(distance metric learning for large margin nearest neighbor classification,大幅度近邻分类的距离度量学习)及
dmlmj(distance metric learning through maximization of the jeffrey divergence,通过jeffrey散度最大化的距离度量学习)这两种涉及半定规划的模型来说,本发明提出的nystr
ö
mnet模型由于不涉及过于复杂的数学优化问题,本算法nystr
ö
mnet1、nystr
ö
mnet2、nystr
ö
mnet3运行时间约是传统模型lmnn及dmlmj运行时间的1/240倍-1/30倍,在速度上有大幅提升。本算法nystr
ö
mnet1、nystr
ö
mnet2、nystr
ö
mnet3运行时间是tripletnet运行时间的1/12倍-2/5倍,而相对于tripletnet这种涉及triplet三元组搜索的模型来说,nystromnet模型也有部分性能上的优势。解决上文提到的局限(3)“相同/相异标签最近邻数据点对搜索时间复杂度高”。
42.实施例6:一个核矩阵为,nystr
ö
m方法使用矩阵近似替代a,(2)其中,表示的广义伪逆矩阵,存在特征分解使矩阵中的每个元素分解为;(3)其中,径向基核函数;其中,为代表性的数据点;令,(4)则公式(3)可化简为,(5)其中,c为对核矩阵的行/列的一个抽样,t为转置。
43.nystr
ö
m映射单元中,核变换拟合中的配置为输入数据点与之间的核函数;其中,输入数据点为度量学习单元的输出数据。
44.nystr
ö
m单元可配置为具有全连接层和激活函数层;配置nystr
ö
m单元的非线性变换函数为,径向基核函数为,(6)其中,表示径向基函数的最优化参数,d为次幂,d为不小于1的整数。
45.由于知识图谱的多源数据与异质性等特点,会导致向量空间的数据分布模式也非常复杂,如果在该种数据中直接应用快速的分类、聚类等数据挖掘方法,对于生态环保类案件的文书,不能很好地识别其中的模式,较大的概率会出现将a识别成b的现象。
46.核变换(核技巧)通过将原数据点映射到更高维度(或无限维度)的、隐式的内积空间,可以使数据分布更加简单。核变换涉及到了核矩阵的计算,即需要将所有的“两两数据点对”应用于核函数,形成一个n
×
n的矩阵,例如传统的谱聚类使用核矩阵模拟邻接矩阵、支持向量机(svm)将该矩阵应用于优化目标的对偶问题求解。核矩阵的计算时间复杂度为,在大规模数据集上其计算规模相当庞大。因此,大量的研究使用nystr
ö
m等方法近似拟合核矩阵和核变换问题。但nystr
ö
m方法仍面临两个难题:(1)非线性变换中的矩阵是通过抽样数据直接计算出的,易受样本数据影响,无法保证针对特定问题的最优化;(2)基核函数难以选取,函数中的最优参数难以确定。
47.在本实施例中,本发明设计一种基于核变换拟合的神经网络模块,降低评论空间的分布复杂性。如图1中的m2.nystr
ö
m映射模块所示:核变换拟合中的为神经网络输入数据点与“代表性数据点”之间的核函数应用,可以用神经网络连接结构表示。由于核变换拟合中的是一个方阵,可以用一层或者多层的全连接的神经网络表示,即图1中的m3模块。表示为神经网络结构后,nystr
ö
m方法中的方阵不再由抽样数据点直接计算,而是由神经网络结构来学习得出,这将大大提高nystr
ö
m方法的拟合精度,并解决了上述的难题(1)“非线性变换中的矩阵是通过抽样数据直接计算出的,易受样本数据影响,无法保证针对特定问题的最优化”,与传统的直接使用抽样数据点的nystr
ö
m方法的对比如图8所示,本算法具有nystr
ö
mnet1、nystr
ö
mnet2、nystr
ö
mnet3可实行的3中算法,其中nystr
ö
mnet1算法采用随机抽样技术对数据集抽取代表性数据点,nystr
ö
mnet2算法采用聚类抽样技术对数据集抽取代表性数据点,nystr
ö
mnet3采用迭代式抽样技术,具体为先抽样,训练一轮将数值向量变换到新的空间里,对训练之后的数值向量进行再抽样,再训练一轮,再对训练之后的数值向量进行抽样,以重复训练抽样的抽样方式进行抽样。
48.nystr
ö
mnet1、nystr
ö
mnet2、nystr
ö
mnet的auc(area under curve,衡量分类器综合性能的指标)比直接使用抽样数据计算的原始nystrom方法的auc有大幅度提升,最大增加了43个百分点,由于数据的差异与分类器的性能不同,对于本发明使用的6种知识图谱数据集,auc有平均提升17个百分点。auc越高就说明这个模型的综合分类性能高,使得分类性能更好,实体识别与实体关系识别的准确性能越好,进而提高知识图谱的构建质量。并能够更好的支持知识图谱的下游数据挖掘任务,如智能法律案件审判中的潜在影响因素分析、案情推理、智能专家系统等。
49.在本实施例中,径向基函数的最优参数可以自动融入m3模块的学习,核函数参数的学习变成一个自动的最优化过程,这避免了以往应用核变换时的最优参数网格搜索过程。因此,难题(2)“基核函数难以选取,函数中的最优参数难以确定”中的问题得以解决,如图7、图8所示,相对于lmnn(distance metric learning for large margin nearest neighbor classification)及dmlmj(distance metric learning through maximization of the jeffrey divergence)等传统的涉及半定规划的线性方法,本研究所提出方法(m1.距离度量学习模块)由于可以进行非线性变换,对模式有更好的拟合性,因此对1-nn、rbfclassifier等基于距离的分类器的auc(area under curve,衡量分类器综合性能的指标)指标有大幅提升作用;而相对用使用triplet三元组搜索的dml network模型,本研究的
模型由于无需非精确triplet搜索带来的精度损失,auc指标也有了更好的提升。auc是一个数据挖掘领域的分类性能指标,auc越高就说明这个模型的综合分类性能越高,具体效果为:可以有效平衡了分类准确率、非平衡数据上的单侧分类精度。
50.实施例6:分类单元配置为采用交叉熵损失函数,总体损失函数为,(7)其中,表示超参数;其中,表示分类交叉熵损失函数;其中,表示度量学习单元的损失函数。
51.在本实施例中,针对神经网络的训练阶段的输出层,本研究使用单层线性连接并应用softmax和交叉熵损失函数,即图1中的m4模块,拟使用的标签类别通常为节点本身的领域知识类别,总体损失函数为包括分类交叉熵损失函数与度量学习模块的损失函数,可以根据不同的目的、数据库调整损失函数的权重。由于该神经网络的输出层是单层线性全连接层,单层线性连接只适用于线性可分的分类问题,因此,神经网络在增量式的训练过程中为了最优化数据分类这个总体目标,将迫使“m1.度量学习模块”与“m3.nystr
ö
m模块”不断地进行最优参数调整,最终使知识图谱数据在“m3.nystr
ö
m模块”输出时呈现出一种线性可分的简单分布结构,大大有利于后续的聚类、分类等任务。
52.以6种数据集为例,使用的知识图谱数据集如图4所示,原数据集及变换后的效果图如图5所示,由于高维度的分类效果不能可视化,为此本发明将高维的分类效果降低到可视化的二维平面上,图中的数据点包括深灰色的数据点与浅灰色的数据点表示2种标签类别数据点,例如,放射性污染物与动植物资源,其中,第一列图像表示对应6种原数据集压缩到二维空间的效果图,第二列图像表示对应原数据集经过度量学习模块变换后压缩到二维空间的的效果图,第三列图像表示对应原数据集先后经过度量学习模块、nystr
ö
m模块变换后压缩到二维空间的的效果图。从图5中可以看出,从第一列图像可以看出原数据集中不同标签类别的数据互相缠绕在一起,难以分离;经过dml模块变换之后,同类别的数据开始向局部聚集,但总体上仍线性不可分;经过nystr
ö
m模块变换之后,数据在总体上已经基本线性可分。
53.一种实体识别的系统,其特征在于,包括,信息获取模块,用于获取生态环保类法律案件的文书的文本信息与其对应的标签信息,构建训练需要的数据集;模型训练模块,用于将已标注的生态环保类法律案件的文书的文本信息及与其对应的标签的训练样本进行训练,得到优化模型;模型应用模块,包括分类器,将优化模型用于分类器中使分类器对未审判的生态环保类法律案件的文书的文本信息进行分类;实体提取模块,用于根据分类器识别文本信息的类别来提取实体。
54.一种计算机可读存储介质,其特征在于,用于存储指定计算机程序,所述指定计算机程序的执行可实现体抽取方法。
55.一种终端,其特征在于,包括:
存储器;处理器;其中,所述存储器用于存储可执行程序代码;其中,所述处理器与所述存储器耦合;所述处理器调用所述存储器中存储的所述可执行程序代码,执行实体抽取方法。
56.在本发明的实施例的描述中,需要理解的是,术语“上”、“下”、“前”、“后”、“左”、“右”、“坚直”、“水平”、“中心”、“顶”、“底”、“顶部”、“底部”、“内”、“外”、“内侧”、“外侧”等指示的方位或位置关系。
57.在本发明的实施例的描述中,需要说明的是,除非另有明确的规定和限定,术语“安装”、“相连”、“连接”、“组装”应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通。对于本领域的普通技术人员而言,可以具体情况理解上述术语在本发明中的具体含义。
58.在本发明的实施例的描述中,具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
59.在本发明的实施例的描述中,需要理解的是,
“‑”
和“~”表示的是两个数值之同的范围,并且该范围包括端点。例如:“a-b”表示大于或等于a,且小于或等于b的范围。“a~b'' 表示大于或等于a,且小于或等于b的范围。
60.在本发明的实施例的描述中,本文中术语“和/或”,仅仅是一种描述关联对象的关联关系,表示可以存在三种关系,例如,a和/或b,可以表示:单独存在a,同时存在a和b,单独存在b这三种情况。另外,本文中字符“/”,一般表示前后关联对象是一种“或”的关系。
61.尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1