多键数据查询方法及相关装置与流程
本技术涉及数据处理,特别涉及一种多键数据查询方法及相关装置。
背景技术:
1、多键数据是指具有多个键的数据,且一个键对应一个值。也即是,多键数据包括多个键值对。多键数据的查询是指查询某个多键数据是否存在于给定的目标数据集中,而且多键数据的查询在邮件系统、数据库、防火墙以及网络路由等领域都有广泛的应用。例如,邮件系统存储有垃圾邮箱集,当接收到某个邮件时,将该邮件对应的邮箱在多个维度的值组成一个多键数据,通过该多键数据查询该邮件对应的邮箱是否存在于垃圾邮箱集中,以此来实现垃圾邮箱的识别。其中,邮箱在多个维度的值包括该邮箱对应的域名、该邮箱对应的用户名以及该邮箱对应的主机名等。然而,目前基本都是通过单键布隆过滤器对单键数据进行查询,无法适用于多键数据的查询,因此,如何进行多键数据查询成为目前亟待解决的问题。
技术实现思路
1、本技术提供了一种多键数据查询方法及相关装置,可以解决相关技术无法进行多键数据查询的问题。所述技术方案如下:
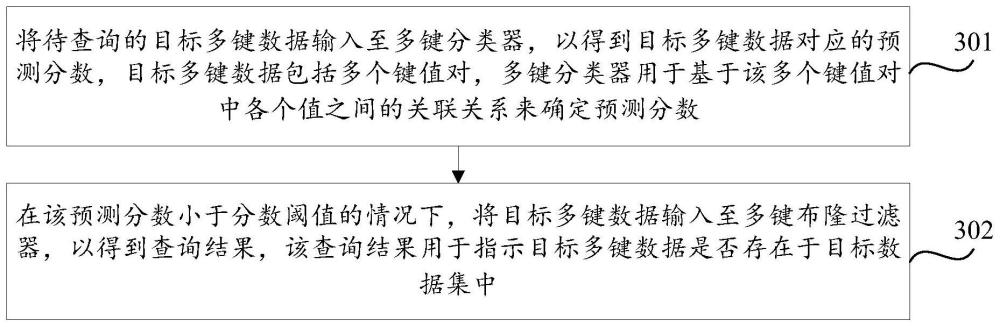
2、第一方面,提供了一种多键数据查询方法,在该方法中,将待查询的目标多键数据输入至多键分类器,以得到目标多键数据对应的预测分数,目标多键数据包括多个键值对,多键分类器用于基于该多个键值对中各个值之间的关联关系来确定预测分数。
3、可选地,按照下述步骤(1)-(3),将待查询的目标多键数据输入至多键分类器,以得到目标多键数据对应的预测分数。
4、(1)确定目标多键数据对应的矩阵表示,该矩阵表示包括该多个键值对中每个值对应的潜向量,该潜向量用于指示对应的值与该多个键值对中其他值之间的关联关系。
5、多键分类器包括多键数据映射层,多键数据映射层存储有键值对中的值与潜向量之间的对应关系。将目标多键数据输入至多键数据映射层,以得到多键数据映射层输出的该多个键值对中各个值对应的潜向量。然后,将该多个键值对中各个值对应的潜向量进行连接,以得到目标多键数据对应的矩阵表示。
6、可选地,通过多键数据映射层存储的值与潜向量之间的对应关系确定目标多键数据对应的矩阵表示之前,还需要基于训练样本数据集对待训练的深度因子分解机(deepfactorization machine,deepfm)进行训练,以得到键值对中的值与潜向量之间的对应关系,该训练样本数据集包括多个样本多键数据,以及每个样本多键数据包括的多个键值对中各个值对应的潜向量。
7、(2)按照多组参数矩阵,将该矩阵表示映射为多组自注意力相关矩阵,该多组自注意力相关矩阵与该多组参数矩阵一一对应。
8、多键分类器包括多组参数矩阵,每组参数矩阵包括多个参数矩阵。对于该多组参数矩阵中的任一组参数矩阵,将目标多键数据对应的矩阵表示与该组参数矩阵包括的多个参数矩阵分别相乘,以得到多个自注意力相关矩阵,将该多个自注意力相关矩阵作为一组自注意力相关矩阵。这样,对于该多组参数矩阵中的每一组参数矩阵,均能够按照上述方法将该矩阵表示进行映射,从而得到多组自注意力相关矩阵。
9、可选地,多键分类器还包括多层多头自注意力(multi-layer multi-head self-attention,mmsa)模型。mmsa模型具有上述多组参数矩阵,一组参数矩阵对应一头自注意力模型。
10、(3)基于该多组自注意力相关矩阵确定目标多键数据对应的预测分数。
11、基于上文描述,将该矩阵表示映射为多组自注意力相关矩阵之后,通过mmsa模型能够确定出每组自注意力相关矩阵对应的计算结果。
12、可选地,多键分类器还包括线性层和激活函数,将上述mmsa模型输出的计算结果输入至线性层,以得到线性层输出的一个二维特征向量。然后,将该二维特征向量输入至激活函数,以得到激活函数输出的目标多键数据对应的预测分数。
13、其中,激活函数为softmax函数。当然,在实际应用中,激活函数还可能为其他的函数,本技术实施例对此不做限定。
14、可选地,为了保证通过多键分类器得到的目标多键数据对应的预测分数更准确,在通过多键分类器确定目标多键数据对应的预测分数之前,还需要基于训练样本数据集对待训练的多键分类器进行训练。其中,该训练样本数据集包括多个样本多键数据,以及该多个样本多键数据对应的标签,该多个样本多键数据对应的标签用于指示样本多键数据为正例或者负例。示例地,将该多个样本多键数据依次输入至多键分类器,以得到多键分类器输出的多个概率,该多个概率与该多个样本多键数据一一对应,该概率用于指示样本多键数据被预测为正例的概率。基于该多个概率和该多个样本多键数据对应的标签,按照下述公式(6)来计算损失函数。然后,基于该损失函数通过反向传播的方法对多键分类器进行训练。
15、
16、其中,在上述公式(6)中,lossadaptive代表损失函数,n代表该多个样本多键数据的总数量,yi代表第i个样本多键数据对应的标签,pi代表第i个样本多键数据被预测为正例的概率,r代表一个超参数。
17、在该预测分数小于分数阈值的情况下,将目标多键数据输入至多键布隆过滤器,以得到查询结果,该查询结果用于指示目标多键数据是否存在于目标数据集中。
18、由于在利用多键布隆过滤器进行多键数据查询时,需要通过多键布隆过滤器包括的哈希函数族,确定目标多键数据包括的多个键值对中每个值对应的比特位。所以,在多键布隆过滤器包括的哈希函数族的数量不同的情况下,将目标多键数据输入至多键布隆过滤器,以得到查询结果的过程有所不同,因此接下来将分为以下三种情况分别进行介绍。
19、第一种情况,目标数据集具有m个键,多键布隆过滤器包括与该m个键一一对应的m个哈希函数族,每个哈希函数族包括多个不同且相互独立的哈希函数,m为大于等于1的整数。此时,通过该m个哈希函数族中与该多个键值对中每个键对应的哈希函数族,确定该多个键值对中每个值对应的比特位。如果目标位图中该多个键值对中每个值对应的比特位上的比特值均为1,则确定目标多键数据存在于目标数据集中。如果目标位图中该多个键值对中每个值对应的比特位上的比特值不均为1,则确定目标多键数据不存在于目标数据集中。其中,目标位图用于表征目标数据集中的各个数据。
20、目标数据集具有m个键,该m个键中的每个键对应一个哈希函数族,对于目标多键数据包括的多个键值对中的任一键值对,通过与该键值对中的键对应的哈希函数族,确定该键值对中的值对应的比特位。这样,对于目标多键数据包括的多个键值对中的每个键值对,均能够按照上述步骤确定出每个键值对中的值对应的比特位。
21、上述第一种情况中的多键布隆过滤器即为上文提及的标准多键布隆过滤器。
22、第二种情况,目标数据集具有m个键,该m个键被划分为n组,多键布隆过滤器包括与该n组键一一对应的n个哈希函数族,每个哈希函数族包括多个不同且相互独立的哈希函数,m和n均为大于1的整数,且n小于m。此时,通过该n个哈希函数族中与该多个键值对中每个键所在组对应的哈希函数族,确定该多个键值对中每个值对应的比特位。如果目标位图中该多个比特位上的比特值均为1,则确定目标多键数据存在于目标数据集中。如果目标位图中该多个比特位上的比特值不均为1,则确定目标多键数据不存在于目标数据集中。
23、确定目标数据集中该m个键中每个键对应的基数比,基数比是指相应键的不同值的数量与所有值的数量之间的比值。然后,按照其对应的基数比所处的基数比范围将该m个键划分为n组。该n组键中的每一组键对应一个哈希函数族,对于目标多键数据包括的多个键值对中的任一键值对,通过该键值对中的键所在组对应的哈希函数族,确定该键值对中的值对应的比特位。这样,对于目标多键数据包括的多个键值对中的每个键值对,均能够按照上述步骤确定出每个键值对中的值对应的比特位。
24、在采用上述方法进行多键数据查询时,按照目标数据集的每个键对应的基数比,将该目标数据集的多个键划分到不同的基数比范围,位于不同基数比范围内的键对应不同数量的哈希函数。由于键对应的基数比越大,表明目标数据集中该键对应的不同值越多,即目标数据集中各个多键数据在该键下的值重复的可能性越小。所以,对于目标多键数据来说,目标多键数据位于目标数据集中的可能性比较小,通过少量的哈希函数就能够确定目标多键数据每个键值对中的值对应的比特位。由于键对应的基数比越小,表明目标数据集中该键对应的不同值越少,即目标数据集中各个多键数据在该键下的值重复的可能性越大。所以,对于目标多键数据来说,目标多键数据位于目标数据集中的可能性比较大,需要通过大量的哈希函数确定目标多键数据每个键值对中的值对应的比特位。这样,对于不同的键能够按照不同数量的哈希函数,确定相应键的值对应的比特位,并不是按照相同数量的哈希函数,确定相应键的值对应的比特位,从而能够进一步提高多键数据的查询准确率。
25、上述第二种情况中的多键布隆过滤器即为上文提及的基于区间优化的多键布隆过滤器。
26、第三种情况,目标数据集具有m个键,多键布隆过滤器包括一个哈希函数族,该哈希函数族包括多个不同且相互独立的哈希函数,m为大于等于1的整数。此时,在该多个键值对中的键与该m个键相同的情况下,将该多个键值对进行拼接,以得到一个字符串。通过该哈希函数族确定该字符串所对应的比特位。如果目标位图中该多个比特位上的比特值均为1,则确定目标多键数据存在于目标数据集中。如果目标位图中该多个比特位上的比特值不均为1,则确定目标多键数据不存在于目标数据集中。
27、在采用上述方法进行多键数据查询时,将目标多键数据包括的多个键值对进行拼接,以得到一个字符串,进而基于该字符串判断目标多键数据是否存在于目标数据集中,并不是基于目标多键数据包括的多个键值对判断目标多键数据是否存在于目标数据集中。这样,能够避免由于目标数据集包括的键值对的数量较多,而导致误判目标多键数据存在于目标数据集中的情况,从而能够进一步提高多键数据的查询准确率。
28、上述第三种情况中的多键布隆过滤器即为上文提及的基于拼接优化的多键布隆过滤器。
29、第二方面,提供了一种多键数据查询装置,所述多键数据查询装置具有实现上述第一方面中多键数据查询方法行为的功能。所述多键数据查询装置包括至少一个模块,该至少一个模块用于实现上述第一方面所提供的多键数据查询方法。
30、第三方面,提供了一种电子设备,所述电子设备包括处理器和存储器,所述存储器用于存储执行上述第一方面所提供的多键数据查询方法的计算机程序。所述处理器被配置为用于执行所述存储器中存储的计算机程序,以实现上述第一方面所述的多键数据查询方法。
31、可选地,所述电子设备还可以包括通信总线,该通信总线用于该处理器与存储器之间建立连接。
32、第四方面,提供了一种计算机可读存储介质,所述存储介质内存储有指令,当所述指令在计算机上运行时,使得计算机执行上述第一方面所述的多键数据查询方法的步骤。
33、第五方面,提供了一种包含指令的计算机程序产品,当所述指令在计算机上运行时,使得计算机执行上述第一方面所述的多键数据查询方法的步骤。或者说,提供了一种计算机程序,当所述计算机程序在计算机上运行时,使得计算机执行上述第一方面所述的多键数据查询方法的步骤。
34、上述第二方面、第三方面、第四方面和第五方面所获得的技术效果与第一方面中对应的技术手段获得的技术效果近似,在这里不再赘述。
35、本技术实施例提供的技术方案至少可以带来以下有益效果:
36、对于待查询的目标多键数据来说,先通过多键分类器进行粗判断,在多键分类器确定目标多键数据对应的预测分数小于分数阈值的情况下,再通过多键布隆过滤器进行细判断。这样,能够提高多键数据的查询准确率。而且,由于多键分类器是基于目标多键数据包括的多个键值对中各个值之间的关联关系,确定目标多键数据对应的预测分数。所以,多键分类器输出的预测分数更准确,从而能够提高多键数据查询的准确度。
- 还没有人留言评论。精彩留言会获得点赞!