Web数据收集中的高级响应处理的制作方法
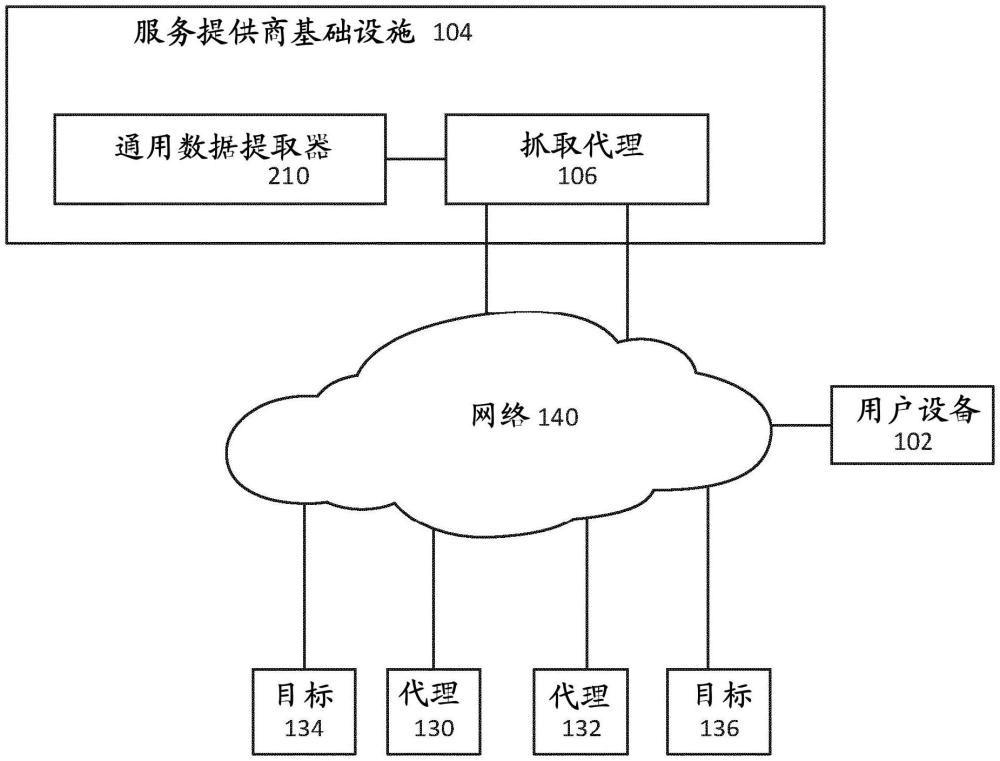
本文详述的方法和系统涉及在数据收集服务的上下文中处理响应数据,其中该处理采用由经训练的机器学习分类模型辅助的解析工具集。
背景技术:
1、web抓取(也称为屏幕抓取、数据挖掘、web收集)在其最一般意义上是从互联网自动采集数据。从技术上讲,它是通过除人类使用web浏览器或与应用编程接口(api)交互的程序以外的任何方式从互联网采集数据的做法。web抓取通常是通过执行程序来完成,该程序查询web服务器并自动请求数据,然后解析数据以提取所请求的信息。
2、web抓取器——为web抓取编写的程序——与其它访问信息的方式(如web浏览器)相比具有显著优势。web浏览器被设计为以人类可读的方式呈现信息,而web抓取器则擅长快速收集和处理大量数据。与通过监视器一次打开一个页面(如web浏览器所做那样)不同,web抓取器能够一次收集、处理、聚合和呈现数千甚至数百万页面的大型数据库。
3、有时,网站允许另一种自动化方式经由api将其结构化数据从一个程序传输到另一个程序。通常,程序将经由超文本传输协议(http)向api请求某种类型的数据,并且api会以结构化形式从网站返回此数据。它用作传输数据的中介。但是,使用api不被视为web抓取,因为api是由网站(或第三方)提供的,并且它消除了对web抓取器的需要。
4、api可以将格式良好的数据从一个程序传输到另一个程序,并且使用它的过程比构建web抓取器来获取相同数据更容易。但是,api并不总是可用于所需的数据。此外,api经常使用容量和速率限制并限制数据的类型和格式。因此,用户会对不存在api或api以任何方式限制的数据使用web抓取。
5、通常,web抓取包括以下步骤:从网站检索超文本标记语言(html)数据;针对期望的目标信息解析数据;保存期望的目标信息;如果需要,那么在另一个页面上重复该过程。web抓取器是被设计为大规模执行所有这些步骤的程序。相关程序——web爬虫(也称为web蜘蛛)——是执行第一个任务的程序或自动化脚本,即它以自动化的方式导航web以检索所访问网站的原始html数据(该过程也称为建立索引)。
6、抓取活动可以由多种类型的抓取应用执行,这些应用一般可以被分类为例如浏览器、无头浏览器、命令行工具、编程语言库等。
7、浏览器——在计算设备内执行的应用,通常在最终用户会话的上下文中,其功能足以接受用户的请求、将其传递给目标web服务器、处理来自web服务器的响应,以及将结果呈现给用户。浏览器被认为是例如能够执行和解释javascript代码的启用用户侧脚本编写的工具。
8、无头浏览器——没有图形用户界面(gui)的web浏览器。无头浏览器在类似于流行的web浏览器的环境中提供对网页的自动化控制,但经由命令行接口或使用网络通信执行。它们对于测试网页特别有用,因为它们能够像浏览器一样渲染和理解html,包括样式元素,诸如页面布局、颜色、字体选择以及javascript和ajax的执行,这些在使用其它测试方法时通常不可用。可以识别两个主要用例:
9、脚本化网页测试——目的是识别错误,而与用户活动非常相似是必要的。
10、web抓取——必须与用户活动相似才能避免阻止,即请求应该具有有机web浏览请求的所有属性。
11、无头浏览器被认为是例如能够执行和解释javascript代码的启用用户侧脚本编写的工具。
12、命令行工具——允许通过例如curl的命令行终端生成和提交web请求的无gui应用。这种类别中的一些工具可能具有其上包裹的gui,但图形元素不会覆盖显示http请求的结果。命令行工具的功能有限,因为它们无法执行和解释javascript代码。
13、编程语言库——行为实现的集合,根据语言编写,具有调用行为的明确定义的接口。例如,当要调用特定的http方法来执行抓取请求时,抓取应用可以使用包含该方法的库来进行系统调用,而不是在程序代码内一遍又一遍地实现这些系统调用。此外,提供行为以供多个独立程序重用,其中程序经由语言机制调用库提供的行为。因此,库的价值在于行为的重用。当程序调用库时,它获得在该库内部实现的行为,而无需自己实现该行为。库鼓励以模块化方式共享代码,并简化代码的分发。编程语言库的功能有限,因为它们无法执行和解释javascript代码,除非存在库作为包装器的能够执行用户端脚本的另一种工具。
14、先前的基本代理类型的组合在不同程度上实现http协议方法和客户端侧脚本编写。
15、上面列出的抓取应用类型在它们拥有的技术能力方面有所不同,通常是由于应用的开发目的不同。在向目标web服务器发送初始请求时,所有列出的类型的抓取应用都会传递提交和处理web请求所必需的参数。例如,http参数-报头、cookie、声明它们支持并打算在其中进行通信的http协议的版本,以及在发起http请求底层的传输控制协议(tcp)会话时公开的tcp参数(例如,tcp窗口大小和其它参数)。如上所述,浏览器和无头浏览器可以处理在web服务器的响应内获得的javascript文件,例如,在请求时通过javascript提交配置设置,而命令行实用程序无法做到这一点。
16、在处理web服务器的响应时,所有列出类型的抓取应用都能够获得、解释、渲染或以其它方式处理和呈现http元数据和主html文档,而一些列出的抓取应用不具备处理从web目标的响应中获得的附加文件的功能,例如,在客户端侧执行脚本化代码。因此,web收获工具的实际分类是基于它们执行和解释javascript代码的能力。
17、整个数据收集过程的进一步公开可以集中在概述标准web服务器请求的结构上。
18、从web服务器获取的响应一般包括以下部分:
19、-http元数据,包含http报头、cookie和http响应代码;
20、-主html文档;
21、-处理和渲染网页的最终版本所需的附加文件:图像、级联样式表(css)文件和javascript(js)脚本。
22、简单html文件包含用基线html代码格式化的数据,而mhtml文件是包含完整响应数据的文本文件:主文档(html)、.css文件——关于每个元素的样式的信息、图像、包含要被执行以渲染最终网页的未编译的脚本代码的javascript文件。
23、文档对象模型(dom)是用于html和xml文档的编程接口。它表示页面,使得程序可以改变文档结构、样式和内容。dom是网页的面向对象表示,确保编程语言可以连接到页面并对其中的元素进行操作。大多数现代浏览器中都实现了w3c dom和whatwg dom标准。为了进一步扩展,所有可用于操纵和创建网页的特性、方法和事件都被组织成对象,例如整个文档、标题、文档中的表格、表格标题、表格单元格中的文本等。
24、现代dom是使用多个协同工作的api构建的。核心dom定义了从根本上描述文档及文档内对象的对象。核心dom根据需要由其它api进行扩展,其他api向dom添加新特征和能力。例如,html dom api对核心dom添加了用于表示html文档的支持。
25、xpath是处理网页的基本元素,它有可能跨dom的层次结构进行导航。xpath语言基于xml文档的树表示,并提供在树中导航、按各种准则选择节点的能力。在流行的使用中(虽然不在官方规范中),xpath表达式常常被简称为“xpath”,其中它包含使用html dom结构的网页上的任何元素的位置,该位置以用于使用xml路径表达式在网页查找任何元素的语法或语言定义。
26、由于手动处理大量数据很少有效或甚至不可行,因此在使数据分析自动化的操作中已涉及支持方法。此类方法之一是机器学习。
27、机器学习可以被广泛地定义为使用聚合数据来提高性能或做出准确预测的计算方法。这里,聚合数据是指机器学习算法可用的过去信息,其通常采用被收集并使其可用于分析的电子数据的形式。
技术实现思路
1、当处理特定数据点集合的请求或请求流时面临的主要缺点是处理所收集的数据的不相关或冗余部分。作为示例,从电子商务网站及其产品页面收集数据的公司通常会遇到多个基于标准解析器的问题,其中最主要的是——各个网站遵守独特的定制布局。通过开发定制的解析和数据收集工具来缓解这种情况,以这种方式处理大量站点在很大程度上依赖于解析代码的不断开发和维护,例如,用于定价和产品情报信息的解析代码。而且,目标网页的布局可以频繁改变,要求附加的精力来进行数据提取和选择调整。web服务器向客户呈现同一web页面的多个版本(版本基于请求来源的国家或浏览器语言设置)可能加剧这个问题。这再次迫使数据收集公司使其已经构建的解析器适应不同的本地化产品页面布局。
2、为每个单独的电子商务网站构建解析器是非常耗时和耗资源的。每个潜在的目标网站都有独特的html结构,并且要求独特的规则来提取相关元素,诸如价格、标题或描述之类。如之前提到的,解析器必须不断维护和更新,因为网站可以在任何时候改变布局和html结构,其中以前的解析器规则将变得过时。启用机器学习的用于数据提取和解析的平台可以自动适应此类改变并且被训练以解析相关元素,而无需针对每个客户制定规则集并且不受网站布局改变的影响。
3、为了成功地收集公共数据并以最小化错误和不一致的方式处理数据收集结果并使结果与原始数据收集要求一致,抓取应用需要采用适应挑战的方法。确保内容得到适当处理、分类和呈现的一种示例性方法是基于机器学习分类器模型的高级web页面数据变换和分类,该机器学习分类器模型被用于解析和检查从目标平台接收到的响应、根据所请求的数据模型对收集的数据进行分类,并将正确标记的数据反馈回抓取平台。用于分类的输入可以通过以下方式获得:提取响应的http部分,将提取的html数据抓取到包含请求方所期望的确切信息的文本块,同时剥离不相关的信息,以及相应地归一化和格式化数据。但是,在一些实施例中,响应的非html部分可以是分类输入的部分,例如,指派给web页面内的对象的样式元素。
4、分类输出可以馈送到最终响应数据聚合中并呈现给请求方。除了其它好处之外,这些方法可以增加如下可能性:在抓取平台处正确标记和分类按请求定制的内容以进一步呈现给请求客户。
5、一方面,这里详述的实施例公开了通过处理从收集的html页面提取的文本元素、解析数据、识别所解析的元素的适当分类、相应地指派分类并将分类的数据反馈回抓取平台来来检查由内容提供商返回的内容的方法和系统,其中响应处理基于经训练的机器学习分类模型。
- 还没有人留言评论。精彩留言会获得点赞!