小视角远距离视频步态精准识别身份认证系统的制作方法
1.本技术涉及一种视频步态精准识别身份认证系统,特别涉及一种小视角远距离视频步态精准识别身份认证系统,属于安防图像身份识别技术领域。
背景技术:
2.传统的身份认证方法有以下两种:一种是基于已有知识(用户名、密码)的身份认证,另外一种是基于拥有物(门禁卡、身份证)的身份认证。总的来说,传统的身份认证方法存在较多缺陷,比如会出现容易丢失、被冒名顶替和篡改一系列问题。逐渐成熟的生物识别技术能解决传统身份认证方法存在的问题,生物识别技术是利用每个人所特有的生物特征进行人身份识别的。生物特征是不同个体所特有的生物信息,每个人的特征会有部分相似,但不可能完全相同,所以能利用生物特征去判定人的身份。现有的科学技术暂时还无法做到复制一个人的全部生物特征,dna、虹膜人类所特有的特征目前还是无法被复制。因此,基于生物识别的新技术得到了快速的成长与发展。
3.到现在为止,人脸识别、指纹识别技术,被普遍应用于各类身份认证的考勤系统中。但这些生物识别技术都有一个与生俱来的、不可避免的缺点,那就是无法做到远距离识别。步态识别技术解决了这个问题,步态识别的先天优势是在距离摄像头较远的情况下还能进行身份识别,即使是在视频或图像分辨率较低的情形下,也能利用获取到的轮廓或其他步态特征进行识别。与其它生物识别相比,步态识别具有以下优势:一是具有无侵犯性的优势,一方面不必与被采集人身体接触,能保护个人隐私,另一个方面是被采集人只需按照平时走路的方式和习惯行走;二是具有非感知性的优势,利用视频监控就能悄无声息地采集步态信息,而不需要告诉被采集人;三是具有远距离识别的优势,摄像头能远距离拍摄到行人步态,即使是在视频或图像模糊的情况下,也能获取到有效的步态信息;四是具有难于隐藏的优势,步态难以伪造,基本上不可能被隐藏。在正常情况下,平时走路的方式和习惯是多年行走积累下来的,一时半会难以改变,有意去隐瞒或是突然地改变行走方式,会使步态显得很不正常,很容易被识别出来。
4.当前许多安防监控摄像头是用来记录特定区域的人员出入情况,保障该区域的安全。而部分人员为了特定目的会选择远离或者绕开摄像头,造成摄像头经常捕捉到的是小视角超远距离人体步态视频,小视角远距离监控视频拍不到或拍不清人脸,也无法清楚的拍摄到步态,但相对而言步态经过处理后可能是相对最优的识别方法,但现有技术小视角超远距离等质量较差的监控视频中的行人步态识别依然存在较大难度,其准确率会大幅度下降。
5.综上,现有技术的生物特征身份识别系统仍然存在若干问题和缺陷,本技术需要解决的问题和关键技术难点包括:
6.(1)现有技术的人脸识别、指纹识别等生物识别技术都有一个与生俱来的、不可避免的缺点,那就是无法做到远距离识别,即使是用视频图像进行识别,一般也要求在距离摄像头较近的情况下,在视频或图像分辨率较高的情形下才能完成,而且现有技术很多身份
识别具有侵犯性,必须与被采集人身体接触,不能保护个人隐私,被采集人容易察觉,采集过程必须被感知,现有技术不能实现远距离的准确身份识别认证,在视频或图像模糊的情况下也无法进行身份识别;很多生物特征身份识别方法容易隐藏和伪造,生物特征身份识别准确度不高,存在很大的安全隐患。
7.(2)现有技术有一些视频步态识别身份认证系统,但这些系统对视频中人体步态图像的距离和角度都有一些要求,如果超出该要求范围,会造成步态识别准确率降低、身份认证失效等严重问题,而当前许多安防监控摄像头是用来记录特定区域的人员出入情况,保障该区域的安全的,部分人员为了特定目的会选择远离或者绕开固定摄像头,造成摄像头经常捕捉到的是小视角超远距离人体步态视频,小视角远距离监控视频拍不到或拍不清人脸,也无法清楚的拍摄到步态,是典型的低质量图像,但相对而言步态经过处理后可能是相对最优的身份识别方法,但现有技术小视角超远距离等质量较差的监控视频中的行人步态识别依然存在较大难度,其准确率会大幅度下降,当前亟需一种在小视角远距离等视频条件下,依然能够通过步态精准识别身份认证的系统。
8.(3)现有技术的视频步态识别身份认证系统对步态视频的视角和距离都有一定要求,虽然视频步态识别允许远距离识别,但对特别远的距离和角度识别率依然不高,这也导致了视频步态识别的运用受到了很大限制,现有技术缺少利用小视角远距离等质量较差的监控视频中的行人步态进行身份识别的方法,小视角远距离等质量较差的监控视频对前置处理阶段要求较高,但基于小视角远距离实时视频监控的场景,现有技术帧差法提取的轮廓可能不完整,光流法的时间复杂度高,计算量大,不适合于实时处理,而视频监控中摄像头通常是朝某个固定不变的,常用的背景建模方法中的中值法无法应对较复杂的背景,混合高斯模型实时性能不佳,且算法速度比较慢,效果不好,占用内存多,最终得到的前置处理效果不好,给后续的步态特征的提取以及步态的分类与识别带来较多困难。
9.(4)对于小视角远距离视频,现有技术在步态特征提取阶段缺少针对性的方法,缺少基于动态中编码形态和行进总势能的步态特征提取方法,无法基于动态中编码形态进行步态特征提取,缺少轮廓小视角采样和步态特征提取,无法基于行进总势能进行步态特征提取,无法基于动态中编码形态和行进总势能进行特征级融合,缺少把不同的特征向量矩阵进行组合,单一特征识别率较低,由于步态特征提取质量较差,导致步态识别精度抗干扰能力不高。在分类识别阶段,现有技术缺少采用基于加权特征融合的分类识别方法,无法基于不同特征的贡献度不同,对不同特征分别赋予不同的权值,由于缺少多种特征的互补融合,导致视频步态无法应对各种不同情况,特别是无法应对小视角超远距离视频的步态身份识别。
技术实现要素:
10.本技术创造性的提出利用小视角远距离等质量较差的监控视频中的行人步态进行身份识别,设计完成基于步态的小视角远距离监控视频人员身份识别方法,从步态视频的前置处理、动态中编码形态和行进总势能的步态特征提取、步态的分类与识别三个方面进行改进,对各种小视角远距离视频的步态识别成功率都在97%以上,专门用于解决当前许多安防监控摄像头是用来记录特定区域的人员出入情况,保障该区域的安全,而部分人员为了特定目的会选择远离或者绕开摄像头,造成摄像头经常捕捉到的是小视角远距离人
体步态视频,小视角远距离监控视频拍不到或拍不清人脸,也无法清楚的拍摄到步态的问题,将步态经过处理后得到相对最优的识别方法,依然达到了很高的识别准确率,有益于发挥步态识别的优势。
11.为实现以上技术效果,本技术所采用的技术方案如下:
12.小视角远距离视频步态精准识别身份认证系统,从步态视频的前置处理、动态中编码形态和行进总势能融合的步态特征提取、步态的分类与识别三个方面进行改进;
13.(1)前置处理阶段:首先,根据实时视频监控摄像头朝某个固定不变,基于背景减除法,采用基于前景检测背景更新背景建模的方法将运动目标与背景分离,得到步态的二值化图像;其次,对获取的二值化步态图像进行腐蚀、膨胀、开闭运算的形态学处理,消除内部空洞和一些噪声;再次,对经过处理的二值化图像做连通区域分析,进一步消除图像中已有的噪声点;最后,采用双线性差值法进行步态轮廓二值化图像的归一化、采用canny边缘检测算法进行边缘轮廓检测和利用人体步态轮廓图像中人体宽度与高度比值的变化去进行步态周期检测,前置处理为后续的步态特征的提取以及步态的分类与识别阶段奠定基础;
14.(2)步态特征提取阶段,采用基于动态中编码形态和行进总势能的步态特征提取方法:首先基于动态中编码形态进行步态特征提取,分为轮廓小视角采样和步态特征提取两个部分,轮廓小视角采样采用角度采样方法,提取人体轮廓形态特征时,用动态中编码形态去表征人体形态轮廓;然后,基于行进总势能进行步态特征提取,基于提取到的行进总势能维度较高,对行进总势能进行数据降维处理;最后基于动态中编码形态和行进总势能进行特征级融合,把不同的特征向量矩阵进行组合,融合多种特征,对动态中编码形态和行进总势能两种特征进行归一化,利用两个步态序列间欧式距离度量相似度,得到基于动态中编码形态和行进总势能的特征级融合结果;
15.(3)分类识别阶段,采用基于加权特征融合的分类识别方法:基于不同特征的贡献度不同,在动态中编码形态与行进总势能两种特征融合的基础之上,分类器在计算隶属度时,对两种特征分别赋予不同权值,采用加权特征融合方法,动态中编码形态和行进总势能两种特征的权重比例是通过设置不同的值,在两者权重之和为1的情况下,计算各种权重组合下加权融合算法的识别率,多次论证取平均值,对比分析得到最终的权重比例,提升步态身份识别率。
16.优选地,基于动态中编码形态的步态特征提取:基于动态中编码形态的步态特征用一个中值编码形态去表示一组形态,包含有n个形态,同一个形态经过平移、旋转和尺度变化后,从视觉直观角度变成不同的形态,消除平移、旋转和尺度变化的影响,将n个形态对齐,同时将这n个形态由k个对应的点组合,然后再求得其中值编码形态,轮廓形态对齐通过图像归一化实现,在边缘轮廓线上采取到k个对应的点,去描述每个轮廓形态。
17.优选地,轮廓小视角采样:采用等角度采样的方法进行小视角采样,角度采样利用相同的角度间隔,对边缘轮廓线进行采样,假设总共要对轮廓线采k个点,那么采样的间隔角度为:
18.θ1=360
°
/k
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
式1
19.以某一点为起点,以θ1为角度间隔对边缘轮廓进行采点,逆时针旋转一周,当再次回到起点即完成采样;
20.将直角坐标系转换为极坐标系,将原来图像中的质心坐标(xc,yc)作为转换后的坐标原点,具体的变换式如式2所示:
[0021][0022][0023]
计算质心(xc,yc)按照:
[0024][0025]
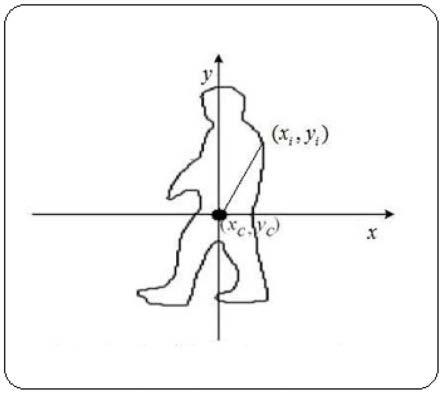
式4中,nb表示二值化图像的中全部像素点的数目,(xi,yi)表示边缘轮廓线上任意一点所对应的直角坐标;
[0026]
完成角度定点采样后,将极坐标转换为直角坐标,获取到动态中编码形态特征:
[0027]
x=r*cosθ,y=r*sinθ
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
式5
[0028]
采用式5转换获取直角系下的坐标。
[0029]
优选地,步态特征提取:
[0030]
二维平面内的形态z用它的k个边缘点所表示,所有边缘点到质心的向量组合而成一个向量,能用该向量表示的形态z为公因子向量,具体的表达式如式5所示:
[0031]
z=[z1,z2,..,zk]
t
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
式6
[0032]
式6中,zi=(x
i-xc)+j*(y
i-yc),(i=1,2,3,...,k),z1是指质心到边缘点i的向量,用一个复数表示,(xi,yi)表示的是二维坐标系中点的坐标点,(xc,yc)表示的是此形态的质心,基于人体二维轮廓形态,以质心(xc,yc)为坐标原点,边界上的点为(xi,yi);
[0033]
假如有两个二维形态z1与z2,它们的公因子向量经过若干次的平移变换或旋转变换以及尺度变换之后,z1与z2的公因子向量还是相同,那么判定z1与z2具有相同的形态,具体的变换如式7所示:
[0034][0035]
式7中,alk是对形态z2进行平移变换,β对形态z2进行旋转变换和尺度变换;采用一个变量来表示某个形态的中心,此变量为中心向量,设中心向量为u,u=[u1,u2,...uk]
t
,其
中两个中心向量u1、u2之间的距离,用d(u1,,u2)表示。
[0036]
优选地,计算一组步态图像序列的中值编码形态,具体方法如下:假设一个步态视频序列有n帧,这个序列有n个不同的形态,然后,令来表示这n个形态中的中值编码形态,采用最小化式10所示的函数,获取此n个形态集合的中值编码形态:
[0037][0038]
按照式11计算矩阵,求出
[0039][0040]
平面形态中值编码形态与该矩阵su的最优支配向量正好对应,su矩阵的最大特征值所对应的特征向量即为所求的中值编码形态;
[0041]
给出同一个人的步态序列的动态中编码形态图像,然后给出不同的行人在0度视角下的动态中编码形态图像。
[0042]
优选地,基于行进总势能的步态特征提取:行进总势能是对一个步态序列的所有二值化图像b(x,y)先求和而后取的中值编码值,直观上表现为形态轮廓以及它们的变化,行进总势能g(x,y)的计算式如式12所示:
[0043][0044]
式12中,n为步态周期所包含的帧数,b
t
(x,y)表示t时刻坐标为(x,y)的点所对应的灰度值,得到的行进总势能维度较高,计算量较大,需要进行数据降维处理;
[0045]
假设一幅m
×
n的图像a,它的投影矩阵为x∈rn×d,设y为图像a在x上的投影,大小为m
×
d,即:
[0046]
y=ax
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
式13
[0047]
式13中,x为投影矩阵,a是原始图像,y是通过x矩阵投影后投影特征向量,投影轴x的优劣决定矩阵y的好坏,降维时用准则函数j(x)去判断投影轴x的好坏,j(x)的表达式如式14所示:
[0048]
j(x)=tr{sy}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
式14
[0049]
式14中,训练样本集合中y的协方差矩阵用sy来表示,协方差矩阵sy的迹用tr{sy}来表示。
[0050]
优选地,假如有m幅图像ak,大小都为m
×
n,通过这m幅图像计算协方差矩阵,中值编码图像矩阵记为表达式如式17所示:
[0051][0052]
那么协方差矩阵g估算为:
[0053][0054]
式15转化为:
[0055]
tr{sy}=tr{x
t
cx}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
式19
[0056]
由式19与式15联合,得到式20:
[0057]
j(x)=tr{sy}=tr{x
t
gx}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
式20
[0058]
其中,x为归一化正交列向量,x只有一列,选取若干个最佳投影轴,采用协方差g中前d个最大特征值所对应的特征向量,然后将它们组合成最佳投影轴x,即为:
[0059]
x=(x1,x2,...,xd)=arg max[j(x)]
[0060]
且有x
it
xj=0,i≠j,i,j=1,2,...,d
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
式21
[0061]
假设有行进总势能a,令:
[0062]
yk=axk,k=1,2,...,d
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
式22
[0063]
由式22得到一组投影后的结果y1,y2,...,yk,为a的主势能向量,降维后选择d个主势能向量构成的m
×
d的矩阵即为行进总势能a的特征矩阵。
[0064]
优选地,基于动态中编码形态和行进总势能的特征级融合:将原始的数据经过一系列的前置处理,把不同的特征向量矩阵进行组合,融合多种特征来提高识别率,动态中编码形态和行进总势能两种特征得到的特征矩阵的尺寸大小不一,先对其进行归一化;
[0065]
动态中编码形态表示的是一组视频序列中轮廓形态的中值编码,用矩阵u来表示,u的大小与采样点数目k相关,假设k=m,m为归一化后图像的宽度,u的大小为m
×
1,设行进总势能图像的大小为m
×
n,对行进总势能降维,降维后得到的特征矩阵大小为m
×
d,降维后的矩阵为am×d;
[0066]
设归一化后动态中编码形态的特征向量为设归一化后动态中编码形态的特征向量为的表达式如式23所示:
[0067][0068]
设归一化行进总势能降维后的特征矩阵为bm×d,b的表达式如式24所示:
[0069][0070]
设两种特征融合后的特征矩阵为b=(b1,b2,...,ba),融合后的矩阵f转化为
[0071]
设融合后的两个不同步态序列的特征矩阵分别为fi与fj,利用两个步态序列间欧式距离度量相似度,fi与fj间的距离d(fi,fj)为:
[0072][0073]
得到基于动态中编码形态和行进总势能的特征级融合结果。
[0074]
优选地,基于加权特征融合的分类识别:
[0075]
首先,用一个矩阵f来表示某个训练样本,如式26所示:
[0076][0077]
式26中,m表示的是两种特征融合后的维度,q表示的是训练集中的样本总数,假设总的类别数为c,其中第c类的样本数为lc(c=1,2,...,c),得到:
[0078][0079]
设测试样本的组合特征为{fi,i=1,2,...,m},得到测试样本与训练集中每个样本的特征差距离矩阵df:
[0080][0081]
式28中,df
iq
=|f
i-f
iq
|,i=1,2,...m,q=1,2,...,q,df
iq
表示测试样本中第i维的特征与训练样本q中第i维的特征差的距离;当特征差值越大,距离就越大,该维特征的相似度就越小;特征差值越小,距离就越小,该维特征的相似度大,这时引入一个模糊分布函数消除误判,当特征差距离较小时,下降缓慢,当特征差距离较大时,相似度迅速下降,采用同一维的特征差的距离作为自变量,利用降岭形分布函数计算同一维度的特征间的相似度,具体如式29所示:
[0082][0083]
式中,x表示的是特征间的距离,a1、a2为参数;
[0084]
然后利用式29,得到测试样本中的第i个特征属于样本q隶属度为μ
iq
,具体表达式如
[0085]
式30所示:
[0086][0087]
其中:
[0088][0089][0090]
利用式30求得测试样本中每个特征对训练集中样本的隶属度,然后能得到一个隶属度矩阵μ。
[0091]
优选地,在计算隶属度时,对两种特征分别赋予不同的权值,如式36所示:
[0092][0093]
式36中ωi表示的是第i种特征的权重,后面的分类判别还是利用式35即可,只需设定动态中编码形态和行进总势能的权重,设动态中编码形态的权重为ω1,行进总势能的权重为ω2,其中ω1+ω2=1,通过实验分析论证,当ω1=0.6,ω2=0.4时,加权融合后的效果最佳。
[0094]
与现有技术相比,本技术的创新点和优势在于:
[0095]
(1)本技术创造性的提出利用小视角远距离等质量较差的监控视频中的行人步态进行身份识别,设计完成基于步态的小视角远距离监控视频人员身份识别方法,从步态视频的前置处理、动态中编码形态和行进总势能的步态特征提取、步态的分类与识别三个方面进行改进,对各种小视角远距离视频的步态识别成功率都在97%以上,专门用于解决当前许多安防监控摄像头是用来记录特定区域的人员出入情况,保障该区域的安全,而部分人员为了特定目的会选择远离或者绕开摄像头,造成摄像头经常捕捉到的是小视角远距离人体步态视频,小视角远距离监控视频拍不到或拍不清人脸,也无法清楚的拍摄到步态的问题,将步态经过处理后得到相对最优的识别方法,依然达到了很高的识别准确率,有益于发挥步态识别的优势。
[0096]
(2)本技术提出的小视角远距离视频步态精准识别身份认证系统,在前置处理阶段,基于小视角远距离实时视频监控的场景,摄像头通常是朝某个固定不变的,基于背景减除法,改进得到前景检测背景更新算法进行运动目标检测时,前景检测背景更新算法速度比较快,效果好,占用内存少,将运动目标与背景分离,得到步态的二值化图像;对获取的二值化步态图像进行形态学处理,消除内部空洞和一些噪声;对经过处理的二值化图像做连通区域分析,进一步消除图像中已有的噪声点;采用双线性差值的方法进行步态轮廓二值化图像的归一化、采用canny边缘检测算法进行边缘轮廓检测和利用人体步态轮廓图像中人体宽度与高度比值的变化去进行步态周期检测,得到了不错的前置处理效果,为后续的步态特征的提取以及步态的分类与识别阶段奠定基础,有助于发挥步态识别无侵犯性的优势,一方面不必与被采集人身体接触,能保护个人隐私,另一个方面是被采集人只需按照平时走路的方式和习惯行走;同时具有非感知性的优势,不需要告诉被采集人;进一步发挥了远距离识别的优势,即使是在视频或图像模糊的情况下,也能获取到有效的步态信息;另外具有难于隐藏的优势,步态难以伪造,相比其他身份识别方法优势非常明显。
[0097]
(3)本技术在步态特征提取阶段,创造性的提出基于动态中编码形态和行进总势能的步态特征提取方法,基于动态中编码形态进行步态特征提取,轮廓小视角采样采用角度采样方法,提取人体轮廓形态特征时,用动态中编码形态去表征人体形态轮廓;基于行进总势能进行步态特征提取,由于提取到的行进总势能维度较高,对行进总势能进行数据降维处理;单一的特征识别率都没有融合的效果好,把不同的特征向量矩阵进行组合,融合多种特征提高识别率,对动态中编码形态和行进总势能两种特征进行归一化,利用两个步态序列间欧式距离度量相似度,得到基于动态中编码形态和行进总势能的特征级融合结果,加权特征融合后,比单一的特征的中值编码识别率至少提升了18%,当人的行走方向与摄
像头的夹角为30到90度时,识别率最高,而夹角小于30度等实际复杂多变的环境中,识别率依然保持较高水平,相比其他步态识别方法优势明显。
[0098]
(4)本技术在在分类识别阶段,创造性的提出基于加权特征融合的分类识别方法,基于不同特征的贡献度不同,在动态中编码形态与行进总势能两种特征融合的基础之上,分类器在计算隶属度时,对两种特征分别赋予不同的权值,提出了加权特征融合的方法,动态中编码形态和行进总势能两种特征的权重比例是通过设置不同的值,计算各种权重组合下加权融合算法的识别率,多次论证取平均值,对比分析得到最终的权重比例,提升步态身份识别率。实验证明,动态中编码形态中值编码识别率为78.02%,行进总势能特征的中值编码识别率为79.52%,而融合后的中值编码识别率为93.69%,加权融合后的中值编码识别率为97.63%。单一的特征识别率都没有融合的效果好,加权特征融合后,比单一的特征的中值编码识别率至少提升了18%,特别是对于小视角远距离视频,本技术的步态识别方法都达到了相当高的精准和可靠性,鲁棒性好,能够应对各种不同的复杂场景。
附图说明
[0099]
图1是视频步态识别的前置处理整体流程图。
[0100]
图2是步态特征提取的边缘轮廓形状示意图。
[0101]
图3是运动目标的动态中编码形态示意图。
[0102]
图4是行进总势能a降维后得到的特征矩阵示意图。
[0103]
图5是方案一中的视频经过前置处理后的结果示意图。
[0104]
图6是采样点数与正确识别率的关系示意图。
[0105]
图7是ω1的取值与识别率的变化具体结果示意图。
[0106]
图8是方案二中的视频经过前置处理后的结果示意图。
具体实施方式
[0107]
下面结合附图,对本技术提供的小视角远距离视频步态精准识别身份认证系统的技术方案进行进一步的描述,使本领域的技术人员能够更好的理解本技术并能够予以实施。
[0108]
当前许多安防监控摄像头是用来记录特定区域的人员出入情况,保障该区域的安全。而部分人员为了特定目的会选择远离或者绕开摄像头,造成摄像头经常捕捉到的是小视角远距离人体步态视频,小视角远距离监控视频拍不到或拍不清人脸,也无法清楚的拍摄到步态,但相对而言步态经过处理后可能是相对最优的识别方法,本技术创造性的提出利用小视角远距离等质量较差的监控视频中的行人步态进行身份识别,设计完成基于步态的小视角远距离监控视频人员身份识别方法,从步态视频的前置处理、动态中编码形态和行进总势能的步态特征提取、步态的分类与识别三个方面进行改进。
[0109]
(1)在前置处理阶段,基于小视角远距离实时视频监控的场景,帧差法提取的轮廓可能不完整,光流法的时间复杂度高,计算量大,不适合于实时处理,而视频监控中摄像头通常是朝某个固定不变的,采用背景减除法比较适合,而常用的背景建模方法中的中值法无法应对较复杂的背景,混合高斯模型实时性能不佳,而采用前景检测背景更新算法进行运动目标检测时,前景检测背景更新算法速度比较快,效果好,占用内存少。所以,采用基于
前景检测背景更新背景建模的方法将运动目标与背景分离,得到步态的二值化图像;其次,对获取的二值化步态图像进行腐蚀、膨胀、开闭运算的形态学处理,消除内部空洞和一些噪声;再次,对经过处理的二值化图像做连通区域分析,进一步消除图像中已有的噪声点;最后,采用双线性差值的方法进行步态轮廓二值化图像的归一化、采用canny边缘检测算法进行边缘轮廓检测和利用人体步态轮廓图像中人体宽度与高度比值的变化去进行步态周期检测,得到了不错的前置处理效果,为后续的步态特征的提取以及步态的分类与识别阶段奠定基础。
[0110]
(2)在步态特征提取阶段,采用基于动态中编码形态和行进总势能的步态特征提取方法:首先基于动态中编码形态进行步态特征提取,分为轮廓小视角采样和步态特征提取两个部分,轮廓小视角采样采用角度采样方法,提取人体轮廓形态特征时,用动态中编码形态去表征人体形态轮廓;然后基于行进总势能进行步态特征提取,基于提取到的行进总势能维度较高,对行进总势能进行数据降维处理;最后基于动态中编码形态和行进总势能进行特征级融合,把不同的特征向量矩阵进行组合,融合多种特征提高识别率,对动态中编码形态和行进总势能两种特征进行归一化,利用两个步态序列间欧式距离度量相似度,得到基于动态中编码形态和行进总势能的特征级融合结果。
[0111]
(3)在分类识别阶段,采用基于加权特征融合的分类识别方法:基于不同特征的贡献度不同,在动态中编码形态与行进总势能两种特征融合的基础之上,分类器在计算隶属度时,对两种特征分别赋予不同的权值,提出加权特征融合的方法,动态中编码形态和行进总势能两种特征的权重比例是通过设置不同的值,在两者权重之和为1的情况下,计算各种权重组合下加权融合算法的识别率,多次论证取平均值,对比分析得到最终的权重比例,提升步态身份识别率。
[0112]
一、小视角远距离步态视频前置处理
[0113]
视频步态识别的前置处理整体流程如图1所示。前置处理阶段依次进行检测运动目标、形态学处理、连通区域分析、步态图像归一化、边缘检测和步态周期检测,得到步态轮廓二值化图像序列,获取到完整、清晰的步态轮廓序列。如果前置处理阶段对步态视频或图像处理后的效果不好,没能得到完整、清晰的步态轮廓二值化图像,那么在步态特征提取阶段提取到的特征就不全,进而会影响后期的步态分类与识别。
[0114]
首先,针对小视角远距离实时视频,帧差法提取的轮廓可能不完整,光流法的时间复杂度高,计算量大,不适合实时处理,而视频监控中摄像头通常是朝某个固定不变的,采用背景减除法较合适,而背景建模方法中的中值法无法应对较复杂的背景,混合高斯模型实时性能不佳,而采用前景检测背景更新算法进行运动目标检测时,速度比较快、效果好,占用内存少。所以,采用基于前景检测背景更新背景建模的方法将运动目标与背景分离,然后得到步态轮廓二值化图像;其次,对得到的二值化步态图像进行一系列的形态学处理,消除内部空洞和一些噪声;再次,对二值化图像进行连通区域分析,进一步消除图像中已有的噪声点;采用双线性差值的方法进行步态轮廓二值化图像的归一化,采用canny边缘检测算法进行边缘轮廓检测,最后利用步态轮廓图像的人体宽度与高度比值的变化曲线去度量步态周期,进而得到前置处理结果,为后续的步态步态特征提取以及步态分类与识别阶段奠定坚实的基础。
[0115]
二、基于动态中编码形态和行进总势能的步态特征提取
[0116]
对监控视频中的图像序列进行前置处理操作之后,就能获取比较有效和清晰的人体步态轮廓二值化图像,经过前置处理,然后根据得到的二值化图像序列进行步态特征提取,首先提取人体轮廓的形态特征,考虑到轮廓形态描述能力有限,然后再提取行进总势能特征,发现行进总势能特征的损失了轮廓信息,将轮廓形态特征与行进总势能特征进行融合,弥补单一特征的不足,提高识别率,接下来采用基于动态中编码形态和行进总势能特征的特征级融合,最后基于加权特征融合进行分类识别。
[0117]
(一)基于动态中编码形态的步态特征提取
[0118]
监控视频中行人的运动轮廓始终变动,采用轮廓形态作为步态特征,将多帧图像的步态轮廓信息一次性表现出来,采用计算统计方法来表征,本技术提出一种对人体轮廓步态特征提取对平移变换、旋转变换以及尺度变换都具有一定鲁棒性的解析计量方法,改善小视角远距离步态识别对视角敏感的问题,本技术采用动态中编码形态作为步态特征进行步态识别。
[0119]
基于动态中编码形态的步态特征用一个中值编码形态去表示一组形态,包含有n个形态,同一个形态经过平移、旋转和尺度变化后,从视觉直观角度变成不同的形态,消除平移、旋转和尺度变化的影响,将n个形态对齐,同时将这n个形态由k个对应的点组合,然后再求得其中值编码形态,轮廓形态对齐通过图像归一化实现,在边缘轮廓线上采取到k个对应的点,去描述每个轮廓形态。
[0120]
1.轮廓小视角采样
[0121]
采用等角度采样的方法进行小视角采样,角度采样利用相同的角度间隔,对边缘轮廓线进行采样,假设总共要对轮廓线采k个点,那么采样的间隔角度为:
[0122]
θ1=360
°
/k
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
式1
[0123]
以某一点为起点,以θ1为角度间隔对边缘轮廓进行采点,逆时针旋转一周,当再次回到起点即完成采样;
[0124]
将直角坐标系转换为极坐标系,将原来图像中的质心坐标(xc,yc)作为转换后的坐标原点,具体的变换式如式2所示:
[0125][0126][0127]
计算质心(xc,yc)按照:
[0128][0129]
式4中,nb表示二值化图像的中全部像素点的数目,(xi,yi)表示边缘轮廓线上任意一点所对应的直角坐标;
[0130]
完成角度定点采样后,将极坐标转换为直角坐标,获取到动态中编码形态特征:
[0131]
x=r*cosθ,y=r*sinθ
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
式5
[0132]
采用式5转换获取直角系下的坐标。
[0133]
2.步态特征提取
[0134]
二维平面内的形态z用它的k个边缘点所表示,所有边缘点到质心的向量组合而成一个向量,能用该向量表示的形态z为公因子向量,具体的表达式如式5所示:
[0135]
z=[z1,z2,..,zk]
t
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
式6
[0136]
式6中,zi=(x
i-xc)+j*(y
i-yc),(i=1,2,3,...,k),z1是指质心到边缘点i的向量,用一个复数表示,(xi,yi)表示的是二维坐标系中点的坐标点,(xc,yc)表示的是此形态的质心,基于人体二维轮廓形态,以质心(xc,yc)为坐标原点,边界上的点为(xi,yi),如图2所示;
[0137]
假如有两个二维形态z1与z2,它们的公因子向量经过若干次的平移变换或旋转变换以及尺度变换之后,z1与z2的公因子向量还是相同,那么判定z1与z2具有相同的形态,具体的变换如式7所示:
[0138][0139]
式7中,alk是对形态z2进行平移变换,β对形态z2进行旋转变换和尺度变换;采用一个变量来表示某个形态的中心,此变量为中心向量,设中心向量为u,u=[u1,u2,...uk]
t
,其中两个中心向量u1、u2之间的距离,用d(u1,,u2)表示,具体的表达式如式8所示:
[0140][0141]
式8中的上标*表示复数共辄转置,且0≤d(u1,u2)≤1,平面形态距离经过平移、旋转以及尺度变换后,不影响两个形态间的相似度比较;
[0142]
然后将d(u1,,u2)最小化,表达式如式9所示:
[0143][0144]
计算一组步态图像序列的中值编码形态,具体方法如下:假设一个步态视频序列有n帧,这个序列有n个不同的形态,然后,令来表示这n个形态中的中值编码形态,然后能最小化公
[0145]
式10所示的函数,获取此n个形态集合的中值编码形态:
[0146][0147]
按照式11计算矩阵,求出
[0148][0149]
平面形态中值编码形态与该矩阵su的最优支配向量正好对应,su矩阵的最大特征值所对应的特征向量即为所求的中值编码形态;
[0150]
给出同一个人的步态序列的动态中编码形态图像,如图3(a)所示,然后给出不同的行人在0度视角下的动态中编码形态图像,如图3(b)所示;
[0151]
同一运动目标的步态序列的动态中编码形态一致,而不同运动目标在同一视角下动态中编码形态相差较大,但当两个人形态轮廓很相似的时候,采用动态中编码形态作为特征判断时,就会误判为同一个人,导致识别率降低;另外,提取的边缘轮廓线容易受到噪声干扰,同时采用动态中编码形态特征时,必须保证轮廓是完整的。因此,单一的动态中编码形态作为步态特征存在不足,为弥补动态中编码形态特征的这种不足,融入一种对单帧图像噪音不敏感和完整性没有要求的特征,这种特征被称之为行进总势能。
[0152]
(二)基于行进总势能的步态特征提取
[0153]
行进总势能是对一个步态序列的所有二值化图像b(x,y)先求和而后取的中值编码值,直观上表现为形态轮廓以及它们的变化,行进总势能g(x,y)的计算式如式12所示:
[0154][0155]
式12中,n为步态周期所包含的帧数,b
t
(x,y)表示t时刻坐标为(x,y)的点所对应的灰度值,得到的行进总势能维度较高,计算量较大,需要进行数据降维处理;
[0156]
假设一幅m
×
n的图像a,它的投影矩阵为x∈rn×d,设y为图像a在x上的投影,大小为m
×
d,即
[0157]
y=ax
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
式13
[0158]
式13中,x为投影矩阵,a是原始图像,y是通过x矩阵投影后投影特征向量,投影轴x的优劣决定矩阵y的好坏,影响最终的识别效果,降维时用准则函数j(x)去判断投影轴x的好坏,j(x)的表达式如式14所示:
[0159]
j(x)=tr{sy}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
式14
[0160]
式14中,训练样本集合中y的协方差矩阵用sy来表示,协方差矩阵sy的迹用tr{sy}来表示;
[0161]
当式14中表达式取得最大值时,表示获取一个投影轴x,让投影后所得的特征向量的总体离散度矩阵的值最大;
[0162]
矩阵sy的迹的表达式如式15所示:
[0163]
tr{sy}=tr{e[(y-ey)(y-ey)
t
]}
[0164]
=tr{e[ax-e(ax)][ax-e(ax)]
t
}
[0165]
=tr{x
t
e[(a-ea)
t
(a-ea)]x}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
式15
[0166]
然后定义图像的协方差矩阵为:
[0167]
g=e[(a-ea)
t
(a-ea)]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
式16
[0168]
其中,矩阵g是非负正定的,大小为n
×
n;
[0169]
假如有m幅图像ak,大小都为m
×
n,通过这m幅图像计算协方差矩阵,中值编码图像矩阵记为表达式如式17所示:
[0170][0171]
那么协方差矩阵g估算为:
[0172][0173]
式15转化为:
[0174]
tr{sy}=tr{x
t
gx}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
式19
[0175]
由式19与式15联合,得到式20:
[0176]
j(x)=tr{sy}=tr{x
t
gx}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
式20
[0177]
其中,x为归一化正交列向量,x只有一列,选取若干个最佳投影轴,采用协方差g中前d个最大特征值所对应的特征向量,然后将它们组合成最佳投影轴x,即为:
[0178]
x=(x1,x2,...,xd)=arg max[j(x)]
[0179]
且有x
it
xj=0,i≠j,i,j=1,2,...,d
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
式2l
[0180]
假设有行进总势能a,令:
[0181]
yk=axk,k=1,2,...,d
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
式22
[0182]
由式22得到一组投影后的结果y1,y2,...,yk,为a的主势能向量,降维后选择d个主势能向量构成的m
×
d的矩阵即为行进总势能a的特征矩阵,行进总势能a降维后得到的特征矩阵如图4所示。
[0183]
(三)基于动态中编码形态和行进总势能的特征级融合
[0184]
步态动态中编码形态表征的是轮廓形态在一个步态周期内的中值编码形态,体现的是步态周期中的整体轮廓形态。当两个人的形态相似时,会出现误判。同时,轮廓边缘线容易受到环境中的噪声的干扰。而行进总势能是对整个步态周期的所有二值化图像取的中值编码值,但行进总势能体现是一种累积的局部变化。行进总势能中亮度比较高的点,说明该点出现的频率较高,行进总势能能弥补轮廓形态只能表现整体形态的不足。行进总势能本来就损失了一部分轮廓信息,再进行降维,损失更多的轮廓信息,动态中编码形态能弥补行进总势能损失的轮廓信息。本技术将动态中编码形态和行进总势能特征融合,弥补单一特征的不足。
[0185]
将原始的数据经过一系列的前置处理,把不同的特征向量矩阵进行组合,融合多种特征来提高识别率,动态中编码形态和行进总势能两种特征得到的特征矩阵的尺寸大小不一,先对其进行归一化;
[0186]
动态中编码形态表示的是一组视频序列中轮廓形态的中值编码,用矩阵u来表示,u的大小与采样点数目k相关,假设k=m,m为归一化后图像的宽度,u的大小为m
×
1,设行进总势能图像的大小为m
×
n,对行进总势能降维,降维后得到的特征矩阵大小为m
×
d,降维后的矩阵为am×d;
[0187]
设归一化后动态中编码形态的特征向量为化后动态中编码形态的特征向量为的表达式如式23所示:
[0188][0189]
设归一化行进总势能降维后的特征矩阵为bm×d,b的表达式如式24所示:
[0190][0191]
设两种特征融合后的特征矩阵为b=(b1,b2,...,ba),融合后的矩阵f转化为
[0192]
设融合后的两个不同步态序列的特征矩阵分别为fi与fj,利用两个步态序列间欧式距离度量相似度,fi与fj间的距离d(fi,fj)为:
[0193][0194]
得到基于动态中编码形态和行进总势能的特征级融合结果。
[0195]
三、基于加权特征融合的分类识别
[0196]
本技术将两种特征融合,以此弥补单一特征识别率不高的问题。但动态中编码形态和行进总势能两种特征的特征类型不同,将两种特征直接进行融合,识别率提升的幅度有限,因此基于动态中编码形态和行进总势能特征的特征级融合方法进行改进。
[0197]
首先,用一个矩阵f来表示某个训练样本,如式26所示:
[0198][0199]
式26中,m表示的是两种特征融合后的维度,q表示的是训练集中的样本总数,假设总的类别数为c,其中第c类的样本数为lc(c=1,2,...,c),得到:
[0200][0201]
设测试样本的组合特征为{fi,i=1,2,...,m},得到测试样本与训练集中每个样本的特征差距离矩阵df:
[0202][0203]
式28中,df
iq
=|f
i-f
iq
|,i=1,2,...m,q=1,2,...,q,df
iq
表示测试样本中第i维的特征与训练样本q中第i维的特征差的距离;当特征差值越大,距离就越大,该维特征的相似度就越小;特征差值越小,距离就越小,该维特征的相似度大,这时引入一个模糊分布函
数消除误判,当特征差距离较小时,下降缓慢,当特征差距离较大时,相似度迅速下降,采用同一维的特征差的距离作为自变量,利用降岭形分布函数计算同一维度的特征间的相似度,具体如式29所示:
[0204][0205]
式中,x表示的是特征间的距离,a1、a2为参数;
[0206]
然后利用式29,得到测试样本中的第i个特征属于样本q隶属度为μ
iq
,具体表达式如式30所示:
[0207][0208]
其中:
[0209][0210][0211]
利用式30求得测试样本中每个特征对训练集中样本的隶属度,然后能得到一个隶属度矩阵μ,如式33所示:
[0212][0213]
然后利用式34,计算出测试样本与训练样本q的每个特征间的隶属度μq:
[0214][0215]
以μq的最大值作为最终分类标准,如式35所示:
[0216][0217]
计算隶属度的式34,没有考虑不同特征的贡献度不同,取的是算术平均值,对于动态中编码形态和行进总势能两种特征,在同一角度下的识别率不同,融合后两种特征,对融合后识别率的贡献度不同,动态中编码形态是对整体轮廓的中值编码,考虑的是整体形态,行进总势能是实心轮廓图的中值编码,反映的是局部变化。因此,直接融合得到联合特征矢量没有考虑特征的贡献度问题。
[0218]
考虑到这个问题,在计算隶属度时,对两种特征分别赋予不同的权值,如式36所示:
[0219][0220]
式36中ωi表示的是第i种特征的权重,后面的分类判别还是利用式35即
可,只需设定动态中编码形态和行进总势能的权重,设动态中编码形态的权重为ω1,行进总势能的权重为ω2,其中ω1+ω2=1,通过实验分析论证,当ω1=0.6,ω2=0.4时,加权融合后的效果最佳。
[0221]
四、实验结果与分析
[0222]
方案一中的视频经过前置处理后的结果如图5所示。然后对轮廓进行角度采样,提取得到的动态中编码形态特征,再提取行进总势能特征,对其降维。
[0223]
然后,针对轮廓小视角采样点取不同的值,采用nn分类器进行分类,得到的采样点数k与识别率的关系如图6所示。
[0224]
由图6可知,采样点数从5开始,随着采样点数目的增加,识别率逐渐提高,采样点数为85左右时,识别率达到最大,后续不再增长。但是考虑到动态中编码形态与行进总势能的要进行融合,以及尽可能完整的表述人体轮廓形态,故后续实验进行轮廓小视角采样时,采样点数为90。
[0225]
在确定k的取值基础之上,再考虑动态中编码形态的权重ω1,和行进总势能的权重ω2的取值,对加权特征融合后正确识别率的影响,由于ω1+ω2=1,ω1的取值与识别率的变化具体结果如图7所示。
[0226]
由图7可知,正确识别率随着ω1的取值变化先增大,后减小,当ω1=0.6,ω2=0.4时,加权融合后的效果最佳,后续实验权重取值为ω1=0.6,ω2=0.4。
[0227]
给出方案一在不同角度下不同特征的识别率,动态中编码形态的识别率一般比行进总势能要低,有时动态中编码形态也会比行进总势能稍微高一些,但融合后的特征比单一的特征识别率都要高。方案一中动态中编码形态中值编码识别率为78.02%,行进总势能特征的中值编码识别率为79.52%,而特征融合后的中值编码识别率为93.69%,采用加权特征融合后中值编码识别率为97.63%。
[0228]
方案二中视频经过前置处理后的结果如图8所示。然后对轮廓进行角度采样,提取得到的动态中编码形态特征,再提取行进总势能特征,对其进行降维。
[0229]
给出方案二中不同视角下不同特征对应的识别率,行进总势能的识别率一般比动态中编码形态高,特征融合后的识别率要比单一特征的识别率高。动态中编码形态考虑了整体的轮廓信息,而行进总势能是一个步态周期内所有序列的中值编码值,它既包含了动态特征,也包含了静态特征,所以行进总势能特征的识别率一般是高于动态中编码形态特征的。而两种步态特征的融合,弥补了单一的步态特征识别率不太高的问题,而且,融合后的识别率比单一特征的识别率高。
[0230]
方案一表示的是casic datasetb数据库中小视角远距离视频行走情况下的累积匹配率,rank=1时表示ccr,当rank=7时,累积匹配率达到了100%,方案二表示的是实际场景的小视角远距离步态数据库中正常行走情况下的累积匹配率,当rank=7时,累积匹配率为90%,之后一直保持不变。casicdatasetb数据库拍摄于室内环境,干扰较少,而实际场景的数据库拍摄于室外,背景比室内环境复杂,干扰(如光照、阴影)较多。
[0231]
方案一中动态中编码形态中值编码识别率为78.02%,行进总势能特征的中值编码识别率为79.52%,而融合后的中值编码识别率为93.69%,加权融合后的中值编码识别率为97.63%。方案二中动态中编码形态的中值编码识别率为69.25%,行进总势能特征的中值编码识别率为71.48%,而融合后的中值编码识别率为84.99%,加权融合后的中值编
码识别率为97.16%。从实验结果中能看出:不论是在方案一还是方案二,单一的特征识别率都没有融合的效果好。加权特征融合后,比单一的特征的中值编码识别率至少提升了18%。当人的行走方向与摄像头的夹角为90度时,识别率一般是最高的,而本技术在小视角远距离等实际复杂多变的环境中,识别率依然保持较高水平。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1