一种多GPU数据传输方法、装置、设备及存储介质与流程
一种多gpu数据传输方法、装置、设备及存储介质
技术领域
1.本发明涉及计算机技术领域,尤其涉及一种多gpu数据传输方法、装置、设备及存储介质。
背景技术:
2.逐渐成熟的机器学习算法,如深度神经网络(dnn)、卷积神经网络(cnn)等,可以在许多实际应用中实现前所未有的性能并解决了许多领域的难题,例如语音识别,文本处理以及图像识别等。但是在单gpu(graphics processing unit,图形处理器或显示核心)上往往需要很长时间进行训练,效率过低一定程度上制约了其应用。减少训练时间最广泛使用的方法是执行数据并行训练。在数据并行训练中,每个gpu都具有模型参数的完整副本,并且gpu经常与参与训练的其他gpu交换参数,这导致了极大的通信成本,并且在通信缓慢时成为系统瓶颈。为了解决训练时的通信瓶颈,可以从硬件和软件两个方面解决。在硬件方面,我们采用更先进的gpu互联技术,如pcie、nvlink、nvswitch等。在nvlink中最高可以提供300gb/s的带宽。在软件方面,采用先进的现代通信库,例如nvidia的集体通信库(nccl),uber的horovod和百度的ring allreduce等。
3.在现有的通信方法中应用较多的是环形通信方法与double binary tree(双二叉树)方法。其中环形通信方法可以有效的采用pipeline(流水线)技术,使其具有良好的扩展性,在大数据量传输时应用较多。而double binary tree方法,往往在小数据量时使用。环形通信算法是gpu通信的常用方法,常在数据量较大时使用。请参照图1a所示,环形通信方法中每个gpu只接收自己左邻居的数据并将数据发送给右邻居,让数据在gpu形成的环内流动。
4.为了更加清楚解释环形通信方法,以all_gather通信方式为例,环形通信方法如图1b所示,后简称为ring_allgather方法。ring_allgather中我们将某部分数据均等的分为n块,然后指定左右邻居,然后执行n-1次发送接受操作,其中在第i次操作中gpu-j会将自己的第(j-i)%n块数据发送给右邻居,并接受左邻据的(j-i-1)%n块数据。在n-1次操作后,每个gpu会获得各个gpu的所有数据。以all_gather为例其算法复杂度为(p-1)α+((p-1)/p)nβ,其中p为gpu的数量,n为传输数据大小,α为传输延迟,β单位数据的传输时间。虽然环形通信算法可以有效的利用pipeline技术,在多gpu上有良好的扩展性,但是在某些服务器架构下会浪费其gpu传输带宽,且环形算法会带来较大的传输延迟,容易形成深度学习的计算瓶颈。
技术实现要素:
5.鉴于深度学习的大规模数据并行训练带来了越来越大的时间开销,这已经逐渐成为了神经网络大规模训练的瓶颈。为了提高通信效率,本发明提供了一种多gpu数据传输方法、一种多gpu数据传输装置、一种计算机设备及一种存储介质。
6.根据本发明的第一方面,提供了一种多gpu数据传输方法,所述方法包括:
7.对同一服务器挂载的多个gpu进行排序以生成gpu序列,其中,gpu总个数为偶数,每个gpu均持有大小相同内容不同的数据;
8.基于倍增算法确定本次执行数据拷贝的分组步长;
9.从所述gpu序列的头或尾开始,将间隔等于分组步长减一的两个gpu组成一组;
10.遍历所有分组以使属于同一组的两个gpu互相拷贝对方当前持有的数据;
11.响应于所有分组均完成数据拷贝,则返回执行所述基于倍增算法确定本次执行数据拷贝的分组步长的步骤。
12.在一些实施例中,所述服务器包括两个通过qpi协议通信的cpu,每个cpu通过pcie switch挂载四个gpu,同一pcie switch挂载的四个cpu分为两对,且每对gpu采用nvlink协议通信。
13.在一些实施例中,所述对同一服务器挂载的多个gpu进行排序以生成gpu序列的步骤包括:
14.获取服务器每个cpu所挂载的gpu,以及各个gpu之间的通信协议;
15.以每个cpu为单位执行以下步骤:将采用nvlink协议通信的两个gpu连续排列得到若干第一序列,拼接所述若干第一序列得到第二序列;
16.遍历所有cpu以得到每个cpu对应的第二序列,并对所有第二序列进行拼接以得到所述gpu序列。
17.在一些实施例中,所述基于倍增算法确定本次执行数据拷贝的分组步长的步骤包括:
18.获取任意一个gpu执行数据拷贝的完成次数;
19.基于公式l=2n计算分组步长,其中,l表示分组步长,n表示gpu执行数据拷贝的完成次数。
20.在一些实施例中,所述方法还包括:
21.响应于每个gpu均持有所有其他gpu的数据,则结束数据传输。
22.在一些实施例中,每个gpu持有的数据均为深度学习训练数据。
23.根据本发明的第二方面,提供了一种多gpu数据传输装置,所述装置包括:
24.排序模块,所述排序模块配置用于对同一服务器挂载的多个gpu进行排序以生成gpu序列,其中,gpu总个数为偶数,每个gpu均持有大小相同内容不同的数据;
25.确定模块,所述确定模块配置用于基于倍增算法确定本次执行数据拷贝的分组步长;
26.分组模块,所述分组模块配置用于从所述gpu序列的头或尾开始,将间隔等于分组步长减一的两个gpu组成一组;
27.数据拷贝模块,所述数据拷贝模块配置用于遍历所有分组以使属于同一组的两个gpu互相拷贝对方当前持有的数据;
28.返回模块,所述返回模块配置用于响应于所有分组均完成数据拷贝,则返回执行所述基于倍增算法确定本次执行数据拷贝的分组步长的步骤。
29.在一些实施例中,所述服务器包括两个通过qpi协议通信的cpu,每个cpu通过pcie switch挂载四个gpu,同一pcie switch挂载的四个cpu分为两对,且每对gpu采用nvlink协议通信。
30.在一些实施例中,所述排序模块进一步配置用于:
31.获取服务器每个cpu所挂载的gpu,以及各个gpu之间的通信协议;
32.以每个cpu为单位执行以下步骤:将采用nvlink协议通信的两个gpu连续排列得到若干第一序列,拼接所述若干第一序列得到第二序列;
33.遍历所有cpu以得到每个cpu对应的第二序列,并对所有第二序列进行拼接以得到所述gpu序列。
34.在一些实施例中,所述确定模块进一步配置用于:
35.获取任意一个gpu执行数据拷贝的完成次数;
36.基于公式l=2n计算分组步长,其中,l表示分组步长,n表示gpu执行数据拷贝的完成次数。
37.在一些实施例中,所述装置还包括配置用于执行以下步骤的模块:
38.响应于每个gpu均持有所有其他gpu的数据,则结束数据传输。
39.在一些实施例中,每个gpu持有的数据均为深度学习训练数据。
40.根据本发明的第三方面,还提供了一种计算机设备,该计算机设备包括:
41.至少一个处理器;以及
42.存储器,存储器存储有可在处理器上运行的计算机程序,处理器执行程序时执行前述的多gpu数据传输方法,所述方法包括:
43.对同一服务器挂载的多个gpu进行排序以生成gpu序列,其中,gpu总个数为偶数,每个gpu均持有大小相同内容不同的数据;
44.基于倍增算法确定本次执行数据拷贝的分组步长;
45.从所述gpu序列的头或尾开始,将间隔等于分组步长减一的两个gpu组成一组;
46.遍历所有分组以使属于同一组的两个gpu互相拷贝对方当前持有的数据;
47.响应于所有分组均完成数据拷贝,则返回执行所述基于倍增算法确定本次执行数据拷贝的分组步长的步骤。
48.根据本发明的第四方面,还提供了一种计算机可读存储介质,计算机可读存储介质存储有计算机程序,计算机程序被处理器执行时执行前述的多gpu数据传输方法,所述方法包括:
49.对同一服务器挂载的多个gpu进行排序以生成gpu序列,其中,gpu总个数为偶数,每个gpu均持有大小相同内容不同的数据;
50.基于倍增算法确定本次执行数据拷贝的分组步长;
51.从所述gpu序列的头或尾开始,将间隔等于分组步长减一的两个gpu组成一组;
52.遍历所有分组以使属于同一组的两个gpu互相拷贝对方当前持有的数据;
53.响应于所有分组均完成数据拷贝,则返回执行所述基于倍增算法确定本次执行数据拷贝的分组步长的步骤。
54.上述一种多gpu数据传输方法,对现有多gpu的环形通信方式进行了改进,通过先对多个gpu进行排序,然后再基于倍增算法确定本次执行数据拷贝的分组步长,进而使用分组步长对gpu序列进行两两分组,属于同于组的gpu拷贝彼此持有的数据,与传统环形通信相比可以有效的降低通信延迟,避免了带宽的浪费,显著提升了数据传输效率。
55.此外,本发明还提供了一种多gpu数据传输装置、一种计算机设备和一种计算机可
读存储介质,同样能实现上述技术效果,这里不再赘述。
附图说明
56.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的实施例。
57.图1a为多gpu环形通信连接结构示意图;
58.图1b为应用图1a结构传递数据的示意图;
59.图2为本发明一个实施例提供的一种多gpu数据传输方法的流程示意图;
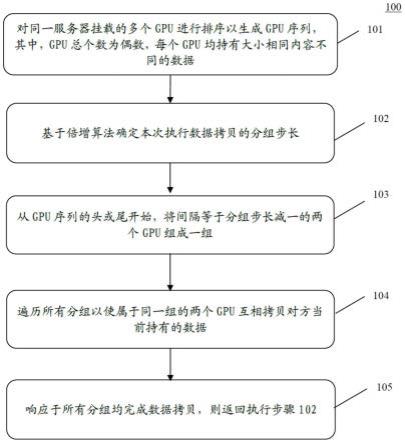
60.图3为本发明另一个实施例提供的采用倍增算法传递数据过程示意图;
61.图4为本发明又一个实施例提供的nf54xx系列服务器拓扑结构示意图;
62.图5为本发明另一个实施例提供的一种多gpu数据传输装置的结构示意图;
63.图6为本发明另一个实施例中计算机设备的内部结构图。
具体实施方式
64.为使本发明的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本发明实施例进一步详细说明。
65.需要说明的是,本发明实施例中所有使用“第一”和“第二”的表述均是为了区分两个相同名称非相同的实体或者非相同的参量,可见“第一”“第二”仅为了表述的方便,不应理解为对本发明实施例的限定,后续实施例对此不再一一说明。
66.在一个实施例中,请参照图2所示,本发明提供了一种多gpu数据传输方法100,具体来说所述方法包括以下步骤,
67.步骤101,对同一服务器挂载的多个gpu进行排序以生成gpu序列,其中,gpu总个数为偶数,每个gpu均持有大小相同内容不同的数据;
68.步骤102,基于倍增算法确定本次执行数据拷贝的分组步长;
69.步骤103,从所述gpu序列的头或尾开始,将间隔等于分组步长减一的两个gpu组成一组;
70.步骤104,遍历所有分组以使属于同一组的两个gpu互相拷贝对方当前持有的数据;
71.步骤105,响应于所有分组均完成数据拷贝,则返回执行所述基于倍增算法确定本次执行数据拷贝的分组步长的步骤。
72.上述一种多gpu数据传输方法,对现有多gpu的环形通信方式进行了改进,通过先对多个gpu进行排序,然后再基于倍增算法确定本次执行数据拷贝的分组步长,进而使用分组步长对gpu序列进行两两分组,属于同于组的gpu拷贝彼此持有的数据,与传统环形通信相比可以有效的降低通信延迟,避免了带宽的浪费,显著提升了数据传输效率。
73.在一些实施例中,请参照图3所示,所述服务器包括两个通过qpi(quick path interconnect)协议通信的cpu,每个cpu通过pcie switch挂载四个gpu,同一pcie switch挂载的四个cpu分为两对,且每对gpu采用nvlink协议通信。
74.其中,qpi是一种基于包传输的串行式高速点对点连接协议,采用差分信号与专门的时钟进行传输。在延迟方面,qpi与fsb几乎相同,却可以提升更高的访问带宽。一组qpi具有20条数据传输线,以及发送(tx)和接收方(rx)的时钟信号。nvlink是英伟达(nvidia)开发并推出的一种总线及其通信协议。nvlink采用点对点结构、串列传输,用于中央处理器(cpu)与图形处理器(gpu)之间的连接,也可用于多个图形处理器之间的相互连接。
75.在一些实施例中,前述步骤101,对同一服务器挂载的多个gpu进行排序以生成gpu序列具体包括以下步骤:
76.获取服务器每个cpu所挂载的gpu,以及各个gpu之间的通信协议;
77.以每个cpu为单位执行以下步骤:将采用nvlink协议通信的两个gpu连续排列得到若干第一序列,拼接所述若干第一序列得到第二序列;
78.遍历所有cpu以得到每个cpu对应的第二序列,并对所有第二序列进行拼接以得到所述gpu序列。
79.在一些实施例中,前述步骤102,基于倍增算法确定本次执行数据拷贝的分组步长具体包括以下步骤:
80.获取任意一个gpu执行数据拷贝的完成次数;
81.基于公式l=2n计算分组步长,其中,l表示分组步长,n表示gpu执行数据拷贝的完成次数。
82.在一些实施例中,所述方法还包括:
83.响应于每个gpu均持有所有其他gpu的数据,则结束数据传输。
84.在一些实施例中,每个gpu持有的数据均为深度学习训练数据。
85.在又一个实施例中,为了便于理解,下面将上述多gpu数据传输方法应用于图3所示的nf54xx系列服务器为例,如图4所示所述方法包括以下步骤:
86.步骤一,距离为1的gpu拷贝彼此数据。
87.步骤二,距离为2的gpu拷贝自己的数据以及在前一步中接收到的数据。
88.步骤三,距离为4的gpu拷贝它们自己的数据以及它们在前两步中接收到的数据。
89.经过步骤一至步骤三的传递该方法可以在lg(p)次内完成环形算法数据传递过程,该算法的算法复杂度为lg(pα)+((p-1)/p)nβ。而环形通信算法复杂度为(p-1)α+((p-1)/p)nβ。可以看出在核数较多时,倍增通信算法中有效的减少了通信延迟项。采用图3的结构gpu之间通过qoi、pcie和nvlink进行连接,其中qpi带宽为12.8gb/s,pcie带宽为16gb/s,nvlink带宽为250gb/s。在环形通信算法中,在8个gpu卡运行时gpu的环路为0-》1-》2-》3-》4-》5-》6-》7-》(0),在此环路中在gpu3和gpu4传输只能采用qpi进行传输,导致整个链路的传输效率理论最高仅为12.8gb/s。浪费了pcie和nvlink的高传输带宽。而在倍增通信算法中在步骤一中,数据传输采用的是nvlink传输(1/7数据),在步骤二中采用的pcie传输(2/7数据),在步骤三中采用的是qpi传输(4/7数据)。因此理论上倍增通信算法,在此架构上理论上最多可以获得18%以上的通信加速。
90.在又一个实施例中,请参照图5所示,本发明还提供了一种多gpu数据传输装置200,所述装置包括:
91.排序模块201,所述排序模块201配置用于对同一服务器挂载的多个gpu进行排序以生成gpu序列,其中,gpu总个数为偶数,每个gpu均持有大小相同内容不同的数据;
92.确定模块202,所述确定模块202配置用于基于倍增算法确定本次执行数据拷贝的分组步长;
93.分组模块203,所述分组模块203配置用于从所述gpu序列的头或尾开始,将间隔等于分组步长减一的两个gpu组成一组;
94.数据拷贝模块204,所述数据拷贝模块204配置用于遍历所有分组以使属于同一组的两个gpu互相拷贝对方当前持有的数据;
95.返回模块205,所述返回模块205配置用于响应于所有分组均完成数据拷贝,则返回执行所述基于倍增算法确定本次执行数据拷贝的分组步长的步骤。
96.上述一种多gpu数据传输装置,对现有多gpu的环形通信方式进行了改进,通过先对多个gpu进行排序,然后再基于倍增算法确定本次执行数据拷贝的分组步长,进而使用分组步长对gpu序列进行两两分组,属于同于组的gpu拷贝彼此持有的数据,与传统环形通信相比可以有效的降低通信延迟,避免了带宽的浪费,显著提升了数据传输效率。
97.在一些实施例中,所述服务器包括两个通过qpi协议通信的cpu,每个cpu通过pcie switch挂载四个gpu,同一pcie switch挂载的四个cpu分为两对,且每对gpu采用nvlink协议通信。
98.在一些实施例中,所述排序模块201进一步配置用于:
99.获取服务器每个cpu所挂载的gpu,以及各个gpu之间的通信协议;
100.以每个cpu为单位执行以下步骤:将采用nvlink协议通信的两个gpu连续排列得到若干第一序列,拼接所述若干第一序列得到第二序列;
101.遍历所有cpu以得到每个cpu对应的第二序列,并对所有第二序列进行拼接以得到所述gpu序列。
102.在一些实施例中,所述确定模块202进一步配置用于:
103.获取任意一个gpu执行数据拷贝的完成次数;
104.基于公式l=2n计算分组步长,其中,l表示分组步长,n表示gpu执行数据拷贝的完成次数。
105.在一些实施例中,所述装置还包括用于执行以下步骤的模块:
106.响应于每个gpu均持有所有其他gpu的数据,则结束数据传输。
107.在一些实施例中,每个gpu持有的数据均为深度学习训练数据。
108.需要说明的是,关于多gpu数据传输装置的具体限定可以参见上文中对多gpu数据传输方法的限定,在此不再赘述。上述多gpu数据传输装置中的各个模块可全部或部分通过软件、硬件及其组合来实现。上述各模块可以硬件形式内嵌于或独立于计算机设备中的处理器中,也可以以软件形式存储于计算机设备中的存储器中,以便于处理器调用执行以上各个模块对应的操作。
109.根据本发明的另一方面,提供了一种计算机设备,该计算机设备可以是服务器,其内部结构图请参照图6所示。该计算机设备包括通过系统总线连接的处理器、存储器、网络接口和数据库。其中,该计算机设备的处理器用于提供计算和控制能力。该计算机设备的存储器包括非易失性存储介质、内存储器。该非易失性存储介质存储有操作系统、计算机程序和数据库。该内存储器为非易失性存储介质中的操作系统和计算机程序的运行提供环境。该计算机设备的数据库用于存储数据。该计算机设备的网络接口用于与外部的终端通过网
络连接通信。该计算机程序被处理器执行时实现以上所述的多gpu数据传输方法,具体来说,所述方法包括以下步骤:
110.对同一服务器挂载的多个gpu进行排序以生成gpu序列,其中,gpu总个数为偶数,每个gpu均持有大小相同内容不同的数据;
111.基于倍增算法确定本次执行数据拷贝的分组步长;
112.从所述gpu序列的头或尾开始,将间隔等于分组步长减一的两个gpu组成一组;
113.遍历所有分组以使属于同一组的两个gpu互相拷贝对方当前持有的数据;
114.响应于所有分组均完成数据拷贝,则返回执行所述基于倍增算法确定本次执行数据拷贝的分组步长的步骤。
115.上述一种计算机设备,对现有多gpu的环形通信方式进行了改进,通过先对多个gpu进行排序,然后再基于倍增算法确定本次执行数据拷贝的分组步长,进而使用分组步长对gpu序列进行两两分组,属于同于组的gpu拷贝彼此持有的数据,与传统环形通信相比可以有效的降低通信延迟,避免了带宽的浪费,显著提升了数据传输效率。
116.在一些实施例中,所述服务器包括两个通过qpi协议通信的cpu,每个cpu通过pcie switch挂载四个gpu,同一pcie switch挂载的四个cpu分为两对,且每对gpu采用nvlink协议通信。
117.在一些实施例中,所述对同一服务器挂载的多个gpu进行排序以生成gpu序列的步骤包括:
118.获取服务器每个cpu所挂载的gpu,以及各个gpu之间的通信协议;
119.以每个cpu为单位执行以下步骤:将采用nvlink协议通信的两个gpu连续排列得到若干第一序列,拼接所述若干第一序列得到第二序列;
120.遍历所有cpu以得到每个cpu对应的第二序列,并对所有第二序列进行拼接以得到所述gpu序列。
121.在一些实施例中,所述基于倍增算法确定本次执行数据拷贝的分组步长的步骤包括:
122.获取任意一个gpu执行数据拷贝的完成次数;
123.基于公式l=2n计算分组步长,其中,l表示分组步长,n表示gpu执行数据拷贝的完成次数。
124.在一些实施例中,所述方法还包括:
125.响应于每个gpu均持有所有其他gpu的数据,则结束数据传输。
126.在一些实施例中,每个gpu持有的数据均为深度学习训练数据。
127.根据本发明的又一方面,提供了一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现以上所述的多gpu数据传输方法,具体来说,包括执行以下步骤:
128.对同一服务器挂载的多个gpu进行排序以生成gpu序列,其中,gpu总个数为偶数,每个gpu均持有大小相同内容不同的数据;
129.基于倍增算法确定本次执行数据拷贝的分组步长;
130.从所述gpu序列的头或尾开始,将间隔等于分组步长减一的两个gpu组成一组;
131.遍历所有分组以使属于同一组的两个gpu互相拷贝对方当前持有的数据;
132.响应于所有分组均完成数据拷贝,则返回执行所述基于倍增算法确定本次执行数据拷贝的分组步长的步骤。
133.上述一种存储介质,对现有多gpu的环形通信方式进行了改进,通过先对多个gpu进行排序,然后再基于倍增算法确定本次执行数据拷贝的分组步长,进而使用分组步长对gpu序列进行两两分组,属于同于组的gpu拷贝彼此持有的数据,与传统环形通信相比可以有效的降低通信延迟,避免了带宽的浪费,显著提升了数据传输效率。
134.在一些实施例中,所述服务器包括两个通过qpi协议通信的cpu,每个cpu通过pcie switch挂载四个gpu,同一pcie switch挂载的四个cpu分为两对,且每对gpu采用nvlink协议通信。
135.在一些实施例中,所述对同一服务器挂载的多个gpu进行排序以生成gpu序列的步骤包括:
136.获取服务器每个cpu所挂载的gpu,以及各个gpu之间的通信协议;
137.以每个cpu为单位执行以下步骤:将采用nvlink协议通信的两个gpu连续排列得到若干第一序列,拼接所述若干第一序列得到第二序列;
138.遍历所有cpu以得到每个cpu对应的第二序列,并对所有第二序列进行拼接以得到所述gpu序列。
139.在一些实施例中,所述基于倍增算法确定本次执行数据拷贝的分组步长的步骤包括:
140.获取任意一个gpu执行数据拷贝的完成次数;
141.基于公式l=2n计算分组步长,其中,l表示分组步长,n表示gpu执行数据拷贝的完成次数。
142.在一些实施例中,所述方法还包括:
143.响应于每个gpu均持有所有其他gpu的数据,则结束数据传输。
144.在一些实施例中,每个gpu持有的数据均为深度学习训练数据。
145.本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的计算机程序可存储于一非易失性计算机可读取存储介质中,该计算机程序在执行时,可包括如上述各方法的实施例的流程。其中,本技术所提供的各实施例中所使用的对存储器、存储、数据库或其它介质的任何引用,均可包括非易失性和/或易失性存储器。非易失性存储器可包括只读存储器(rom)、可编程rom(prom)、电可编程rom(eprom)、电可擦除可编程rom(eeprom)或闪存。易失性存储器可包括随机存取存储器(ram)或者外部高速缓冲存储器。作为说明而非局限,ram以多种形式可得,诸如静态ram(sram)、动态ram(dram)、同步dram(sdram)、双数据率sdram(ddrsdram)、增强型sdram(esdram)、同步链路(synchlink)dram(sldram)、存储器总线(rambus)直接ram(rdram)、直接存储器总线动态ram(drdram)、以及存储器总线动态ram(rdram)等。
146.以上实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
147.以上所述实施例仅表达了本技术的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来
说,在不脱离本技术构思的前提下,还可以做出若干变形和改进,这些都属于本技术的保护范围。因此,本技术专利的保护范围应以所附权利要求为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1