融合NSGA-Ⅲ和TOPSIS的数据驱动多目标优化方法
融合nsga
‑ⅲ
和topsis的数据驱动多目标优化方法
技术领域
1.本发明属于多目标优化技术领域,具体的为一种融合nsga
‑ⅲ
和topsis的数据驱动多目标优化方法。
背景技术:
2.多目标优化是指某个情景中在需要达到多个目标时,由于目标间存在内在冲突,一个目标的优化是以其他目标劣化为代价,因此很难出现唯一最优解,而只能在它们中间进行协调和折中处理,使各个子目标都尽可能地达到最优。多目标优化问题在工程应用等现实生活中非常普遍并且处于非常重要的地位,相较于单目标优化问题,多目标优化问题的求解难度更大,解决多目标优化问题具有非常重要的科研价值和实际意义。
3.根据国内外学者关于多目标优化问题的研究,目前解决多目标优化问题可分为两步。第一步是通过实验技术和理论方法建立参数和不同优化目标之间的数学关系。第二步是开发一种多目标优化算法或组合算法,用于解决参数的优化问题。
4.第一步中,实验技术主要采用试验设计(doe)的方法来构造统计曲线拟合函数,并将其作为预测模型来实现优化过程。doe的有效使用已被证明在筛选最有候选参数和确定优化的因果效应方面至关重要,从而提高产品的质量和可靠性。在实际制造操作中,使用精确的实验方法构建曲线拟合函数通常需要昂贵的实验加工数据采集,导致人工成本和材料成本增加。采用理论方法进行优化主要是基于物理-数学模型或有限元模拟。理论方法在实际应用前就可以得到合理的参数,能提高加工工艺性能和降低生产成本,但是该方法依赖于专家知识去构建多目标优化函数。
5.第二步中,“multi-objective parameter optimization of turbine impeller based on rbf neural network and nsga-ii genetic algorithm”(energy reports,2021,7(s7),ji yunguang,yang zhikuo,ran jingyu,li hongtao)内记载了一种基于径向基函数神经网络和nsga-ii的多目标优化方法,用于优化涡轮的扬程和效率。但是该方法针对扬程和效率这两个相互冲突的目标,需要额外的时间和人力资源用于筛选出最优的参数组合。“hybrid nsga-ii based decision-making in fuzzy multi-objective reliability optimization problem”(sn applied sciences,2019,1(11),hemant kumar,shiv prasad yadav)内记载了一种利用nsga-ii优化燃气轮机超速保护系统的系统可靠性、系统成本和系统重量的技术方案,利用模糊排序方法从pareto解集中得到最优折衷解。但是该方法依赖于专家知识去确定每一个目标的隶属度函数,不能快速应用于具有新目标的优化任务。公开号为cn114358409a的中国专利中公开了一种多目标优化结果的排序方法及相关装置,通过多次多目标优化将多目标优化结果的排序问题转换为单目标排序问题,降低了多目标优化排序问题的复杂度。但是该方法需要人为的去干预,优化步骤复杂且优化时间长。
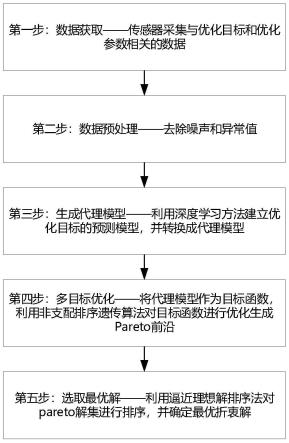
6.综上所述,现有的多目标优化方法存在以下缺陷:
7.(i)现有方法的优化时间长、成本高。试验设计方法针对新的优化目标需要进行新
的实验,并依赖于昂贵的实验数据采集,然后手动获得每个目标的曲线拟合函数,导致人工成本和材料成本增加。采用理论方法时物理预测模型和仿真模型的计算效率往往较低,导致迭代过程的时间成本较高,优化耗时几个小时到几天不等。
8.(ii)现有方法的依赖于专家知识,方法的适应性差。现有的方法依赖于专家知识去构建目标函数,但是针对多目标优化任务,由于专家知识仅在特定领域发挥作用,对于新的优化目标仅依赖于专家知识去开发不同目标的目标函数是很困难的。在实际的操作中存在各种类型的任务,不同任务的目标和相关的参数也不相同,由于专家知识的有限性,传统的方法不适用于解决不同领域的多优化问题。
9.(iii)现有方法不能准确获得最优方案。多目标优化求解是从基于物理预测模型的目标函数获得优化后的参数,然而物理建模过程中经常进行许多假设和简化,导致目标函数的精度较低,优化后的参数可能不满足约束条件。此外,在生成的pareto解集中只有少数几个解代表了优化目标之间的最优权衡,导致决策者很难根据目标函数从pareto解集中做出最优选择。
技术实现要素:
10.有鉴于此,本发明的目的在于提供一种融合nsga
‑ⅲ
和topsis的数据驱动多目标优化方法,能准确的得到不同的生产任务和生产要求对应的最优方案,解决生产过程中的多目标优化问题,以快速、准确地获得最优方案。
11.为达到上述目的,本发明提供如下技术方案:
12.一种融合nsga
‑ⅲ
和topsis的数据驱动多目标优化方法,包括如下步骤:
13.步骤1):历史数据采集:采集与优化目标和工艺参数相关的数据;
14.步骤2):数据预处理:对采集得到的历史数据进行预处理,剔除原始数据中的异常值;
15.步骤3):生成代理模型:利用深度学习方法,根据历史数据生成优化目标的预测模型,并将预测模型转换成代理模型;
16.步骤4):多目标优化:将代理模型作为目标函数,利用非支配排序遗传算法(nsga
‑ⅲ
)对目标函数进行优化,生成pareto前沿;
17.步骤5):选取最优解:利用逼近理想解排序法(topsis)对pareto解集进行排序,确定最优解。
18.进一步,所述步骤2)中,利用局部离群因子算法(lof)对历史数据进行预处理,方法如下:
19.在样本集d中,定义某样本点o与离其第k远的近邻点间的距离为点o的第k距离dk(o),并定义点o的第k距离邻域nk(o)为离点o的距离不超过dk(o)的所有样本点,即:
20.nk(o)={o'|o'∈d,d(o,o')≤dk(o)}
21.其中,d(o,o')为样本点o与o'间的距离;若d(o,o')<dk(o),则定义样本点o的可达距离d
reach
(o,o')为dk(o),否则为d(o,o'),即:
22.d
reach
(o,o')=max{d(o,o'),dk(o)}
23.其中,||nk(o)||为点o的第k距离邻域内包含的样本点个数;
24.定义点o的局部可达密度与其第k距离邻域nk(o)内所有点的局部可达密度之比的
平均值为局部离群因子lofk(o),即:
[0025][0026]
样本点o的局部可达密度相比其k近邻的局部可达密度越低,则lofk(o)值越大,说明点o是离群点的可能性也越大。
[0027]
进一步,所述步骤3)中,若历史数据为离散数据,则采用卷积神经网络(cnn)生成优化目标的预测模型;若历史数据为时序数据,则采用长短期记忆人工神经网络(lstm)生成优化目标的预测模型。
[0028]
进一步,所述步骤4)中,利用非支配排序遗传算法(nsga
‑ⅲ
)对目标函数进行优化的方法为:
[0029]
41)通过边界交叉构造权重的方法,基于优化目标数m和各维度目标划分数p,均匀生成h(m,p)个参考点:
[0030][0031]
42)将第t代种群p
t
通过交叉变异操作得到子代种群q
t
,每代种群规模为s,将父代种群和子代种群合并形成新种群r
t
;
[0032]
43)将合并种群r
t
中的个体进行快速非支配排序,得到若干非支配层f1,f2,f3,...,f
l
;
[0033]
44)将优先级较高的非支配层存入下一代种群p
t+1
,临界层为f
τ
,满足:
[0034]
且
[0035]
45)得到当前种群的所有个体在每一维目标上的最优值,构成当前种群在每一维目标上的原点。将步骤41)中生成的参考点与原点相连,连接线组成参考向量;计算当前p
t+1
中所有个体到参考向量的垂直距离,并与最近的参考向量相关联;
[0036]
46)根据距离最近原则,在f
τ
层中选择个个体加入种群p
t+1
,使种群规模为s,作为新一代父代种群,迭代次数gen加1;
[0037]
判断迭代次数gen是否达到设定阈值maxgen;若是,则输出当下种群,得到工艺参数优化解集;若否,则执行步骤42)。
[0038]
进一步,所述步骤5)中,利用逼近理想解排序法(topsis)确定最优解的方法为:
[0039]
51)建立初始判断矩阵
[0040]
设评价方案数量为m,所有评价方案构成方案集a={a1,a2,
…
,am};每个评价方案有n个评价指标,单一评价方案评判集ai={x
i1
,x
i2
,
…
,x
in
},评判指标x
ij
为第i个评价方案的第j个评价指标值,i∈[1,m],j∈[1,n];构建相应的初始判断矩阵为:
[0041][0042]
52)建立标准化决策矩阵
[0043]
将负向指标以倒数方式完成正向化,使所有指标具有同趋势性;将原始数据进行归一化处理以消除量纲:
[0044][0045]
最终得到标准化决策矩阵z=(z
ij
)m×n;
[0046]
53)构建加权评价矩阵
[0047]
对评价方案的n维评价指标分配权重,构建的评价指标权重矩阵对标准化决策矩阵进行加权得到加权评价矩阵z’:
[0048][0049]
其中,z'表示加权评价矩阵;w表示评价指标的权重矩阵;wj表示第j个评价指标的权重;
[0050]
54)确定理想解
[0051]
正理想解z
+
是由加权评价矩阵z’中每列最优值组成:
[0052][0053]
其中,表示加权评价矩阵z’中第j列的最优值;
[0054]
负理想解z-是由加权评价矩阵z’中每列最劣值组成:
[0055][0056]
其中,表示加权评价矩阵z’中第j列的最劣值;
[0057]
55)计算距离尺度与优劣排序
[0058]
(1)计算距离尺度,确定评价方案与正、负理想解的欧式距离:
[0059][0060][0061]
其中,d
i+
表示第i个评价方案到正理想解的欧式距离;d
i-表示第i个评价方案到正理想解的欧式距离;z’ij
表示加权评价矩阵中的第i个方案得到的第j个指标的值;
[0062]
(2)计算评价方案与正理想解的接近度:
[0063][0064]
其中,ci表示第i个方案与正理想解的接近度;
[0065]
根据ci高低进行优劣排序,ci值越接近1表明评价方案越优。
[0066]
本发明的有益效果在于:
[0067]
本发明融合nsga
‑ⅲ
和topsis的数据驱动多目标优化方法具有以下优点:
[0068]
1)基于深度学习的代理模型构建方法可以自适应的构建优化参数和优化目标之间的复杂函数关系。与传统的方法相比,本方法不需要构建新的模型或实验也不依赖于专家知识,减少了优化时间和成本。
[0069]
2)使用历史数据搭建目标函数,与传统的方法相比,深度学习建立代理模型,采用自动化、集成的方式,人为干扰最小,不需要理解生产过程中的物理规律或化学规律,避免了非最优隐藏节点问题,保证了模型精度的稳定。
[0070]
3)可提高从pareto非劣解集中寻找最优方案的搜索性能,与传统的方法相比,可以根据预先设置的目标数量和目标间的权重,自适应的获得符合生产过程要求的最优方案。
[0071]
4)可以针对不同的生产任务和生产要求,对目标的个数和不同目标的权重进行动态调整,解决传统方法不能快速适应不同任务的优化问题。
附图说明
[0072]
为了使本发明的目的、技术方案和有益效果更加清楚,本发明提供如下附图进行说明:
[0073]
图1为本发明融合nsga
‑ⅲ
和topsis的数据驱动多目标优化方法的流程图;
[0074]
图2为cnn模型的结构图;
[0075]
图3为lstm模型的结构图;
[0076]
图4为利用非支配排序遗传算法(nsga
‑ⅲ
)对目标函数进行优化的流程图。
具体实施方式
[0077]
下面结合附图和具体实施例对本发明作进一步说明,以使本领域的技术人员可以更好的理解本发明并能予以实施,但所举实施例不作为对本发明的限定。
[0078]
如图1所示,本实施例融合nsga
‑ⅲ
和topsis的数据驱动多目标优化方法,包括如下步骤。
[0079]
步骤1):历史数据采集:采集与优化目标和工艺参数相关的数据。
[0080]
根据优化的目标和优化的参数,利用传感器和实验设备采集相关的历史数据。对于在生产过程中不能从设备中直接获取的状态信息,可以在需要采集信息的部位安装相应的传感器,通过数据采集系统获取历史数据。
[0081]
步骤2):数据预处理:对采集得到的历史数据进行预处理,剔除原始数据中的异常值。
[0082]
本实施例利用局部离群因子算法(lof)对历史数据进行预处理,提高原始数据的准确性,方法如下:
[0083]
在样本集d中,定义某样本点o与离其第k远的近邻点间的距离为点o的第k距离dk(o),并定义点o的第k距离邻域nk(o)为离点o的距离不超过dk(o)的所有样本点,即:
[0084]
nk(o)={o'|o'∈d,d(o,o')≤dk(o)}
[0085]
其中,d(o,o')为样本点o与o'间的距离;若d(o,o')<dk(o),则定义样本点o的可
达距离d
reach
(o,o')为dk(o),否则为d(o,o'),即:
[0086]dreach
(o,o')=max{d(o,o'),dk(o)}
[0087]
其中,||nk(o)||为点o的第k距离邻域内包含的样本点个数;
[0088]
为了避免样本分布形状对离群点选取的影响,lof算法采用局部可达密度来表征样本点o的密度。定义点o的局部可达密度lrdk(o)为:
[0089][0090]
其中,||nk(o)||为点o的第k距离邻域内包含的样本点个数。
[0091]
定义点o的局部可达密度与其第k距离邻域nk(o)内所有点的局部可达密度之比的平均值为局部离群因子lofk(o),即:
[0092][0093]
样本点o的局部可达密度相比其k近邻的局部可达密度越低,则lofk(o)值越大,说明点o是离群点的可能性也越大。
[0094]
步骤3):生成代理模型:利用深度学习方法,根据历史数据生成优化目标的预测模型,并将预测模型转换成代理模型。
[0095]
本实施例中,代理模型是指利用各种预测模型所开发的目标函数。通常,代理模型是一个快速运行的逼近函数,可用于全局或局部逼近昂贵的函数值。由于复杂的工作条件阻碍了物理模型的构建来描述加工过程,使其优化极其困难。深度学习是机器学习中最重要的分支领域,由于具有从原始数据中提取特征的能力,能够自动建立输入参数和输出目标之间的关系,利用深度学习开发的预测模型可以在较少人为干预的情况下运行,所有模型参数,包括特征和回归模块,都可以联合训练。具体的,若历史数据为离散数据,则采用卷积神经网络(cnn)生成优化目标的预测模型;若历史数据为时序数据,则采用长短期记忆人工神经网络(lstm)生成优化目标的预测模型。
[0096]
cnn具有一般的一维结构,如图2所示。在一维cnn建模过程中,考虑了五个不同的层:输入层、卷积层、池化层、全连接层和输出层。采集到的数据,包括工艺参数和输出目标,送到输入层进行处理,再送到卷积层进行卷积运算。
[0097]
在卷积层之后,池化层的作用是减少特征映射级别,同时保留之前输入中隐藏的信息。通常,多个池操作是必要的。在本实施例中,采用最大池化,可以表示为:
[0098]
f(x)=max(0)
[0099]
在实施例的池化操作为:
[0100][0101]
其中,x为池化层的输入,f(x)为池化层的输出。在卷积和池化操作后,后续为全连接层,以池化层输出的1d向量作为输入。全连接层由许多神经元组成,这些神经元与前一层中的所有节点聚集在一起。在输出层,激活函数通常用于完成回归或分类。由于预测问题是一项回归任务,因此采用线性激活函数。
[0102]
lstm作为特殊rnn,在循环网络的基础上添加记忆细胞(cell)单元,用于保存长期状态,并增加遗忘门、输入门和输出门共同控制信息的遗忘和记忆,使之更擅长处理时间序
列数据。
[0103]
如图3,lstm的单元结构x
t
和h
t
分别为t时刻的输入和输出,h
t-1
为上一时刻lstm单元的输出,c
t-1
为上一时刻记忆细胞单元的输出,c
t
为t时刻记忆细胞单元的输出。lstm各单元计算公式如下。
[0104]
遗忘门决定上一时刻有多少信息保留或遗忘在记忆细胞c
t
,即:
[0105]ft
=σ(w
fhht-1
+w
fx
x
t
+bf)
[0106]
输入门决定当前时刻有多少信息保留在记忆细胞c
t
,即:
[0107]it
=σ(w
itht-1
+w
ix
x
t
+bi)
[0108]
当前时刻的候选记忆细胞单元c
t’,即:
[0109]ct
'=tanh(w
chht-1
+w
cx
x
t
+bc)
[0110]
记忆细胞由f
t
点乘上一时刻记忆细胞单元c
t-1
的值与i
t
点乘当前时刻临时储存单元c
t’的值相加更新,即:
[0111]ct
=f
t
⊙ct-1
+i
t
⊙ct
'
[0112]
输出门决定当前记忆细胞c
t
有多少输出到当前隐藏层输出值h
t
,即:
[0113]ot
=σ(w
ohht-1
+w
ox
x
t
+bo)
[0114]
将记忆细胞c
t
经过tanh函数处理后与输出门o
t
相乘,得到最终输出:
[0115]ht
=o
t
⊙
tanh(c
t
)
[0116]
其中,w
fh
、w
ih
、w
oh
分别为遗忘门、输入门、输出门与上一时刻隐藏层h
t-1
的权重矩阵;w
fx
、w
ix
、w
ox
分别为遗忘门、输入门、输出门与输入向量x
t
的权重矩阵;bf、bi、bc、bo分别为遗忘门、输入门、记忆细胞、输出门的偏执项;σ代表sigmoid非线性函数;tanh为双曲正切函数;
⊙
表示向量间点乘。
[0117]
步骤4):多目标优化:将代理模型作为目标函数,利用非支配排序遗传算法(nsga
‑ⅲ
)对目标函数进行优化,生成pareto前沿。
[0118]
本实施例使用nsga-iii来对工艺参数进行多目标优化,开发的基于深度学习的数据驱动代理模型作为目标函数。本实施例可以避免计算复杂的数学建模和昂贵的实验。当要构建一个新的种群st,利用基于pareto支配的非支配排序将原始种群分为若干不同的非支配层(f1,f2
…
)。从f1开始逐次将各非支配层的解加入到st中。这种分布干扰了最优方案的选择,直到达到形成下一代所需的非支配解的数量。如果要插入的最后一个非支配层fl包含的个体多于需要的,那么必须在fl内根据参考线进行选择。基准线从fl的中心开始并通过基准点。与基准线垂直距离最小的解决方案被优先选择。利用下列公式计算得到工艺参数的帕累托(pareto)前沿。
[0119]
具体的,如图4所示,本实施例利用非支配排序遗传算法(nsga
‑ⅲ
)对目标函数进行优化的方法如下。
[0120]
41)通过边界交叉构造权重的方法,基于优化目标数m和各维度目标划分数p,均匀生成h(m,p)个参考点:
[0121][0122]
42)将第t代种群p
t
通过交叉变异操作得到子代种群q
t
,每代种群规模为s,将父代种群和子代种群合并形成新种群r
t
;
[0123]
43)将合并种群r
t
中的个体进行快速非支配排序,得到若干非支配层f1,f2,f3,...,f
l
;
[0124]
44)将优先级较高的非支配层存入下一代种群p
t+1
,临界层为f
τ
,满足:
[0125]
且
[0126]
45)得到当前种群的所有个体在每一维目标上的最优值,构成当前种群在每一维目标上的原点。将步骤41)中生成的参考点与原点相连,连接线组成参考向量;计算当前p
t+1
中所有个体到参考向量的垂直距离,并与最近的参考向量相关联;
[0127]
46)根据距离最近原则,在f
τ
层中选择个个体加入种群p
t+1
,使种群规模为s,作为新一代父代种群,迭代次数gen加1;
[0128]
判断迭代次数gen是否达到设定阈值maxgen;若是,则输出当下种群,得到工艺参数优化解集;若否,则执行步骤42)。
[0129]
步骤5):选取最优解:利用逼近理想解排序法(topsis)对pareto解集进行排序,确定最优解。
[0130]
nsga-iii产生的优化结果信息量较大,同时可供决策者选择的解决方案数目多。从nsga-iii算法得到的pareto解中选取的代表解可以看作是一个多目标优化问题。为了实现这一目标,利用理想解相似度排序技术对最优有效解进行排序。提出的理想相似度排序方法的基本机制是计算在n维空间中定义的正理想解(pis)和负理想解(nis)的每个备选方案之间的距离,其中n为决策问题中准则的数量。最佳的方案与pis之间的矢量距离最小,与nis之间的矢量距离最大。
[0131]
具体的,本实施例利用逼近理想解排序法(topsis)确定最优解的方法如下。
[0132]
51)建立初始判断矩阵
[0133]
设评价方案数量为m,所有评价方案构成方案集a={a1,a2,
…
,am};每个评价方案有n个评价指标,单一评价方案评判集ai={x
i1
,x
i2
,
…
,x
in
},评判指标x
ij
为第i个评价方案的第j个评价指标值,i∈[1,m],j∈[1,n];构建相应的初始判断矩阵为:
[0134][0135]
52)建立标准化决策矩阵
[0136]
评价指标可分为正向指标与负向指标,以最小化为目的的目标通常被认为是负向指标,而以最大化为目的的目标通常被认为是正向指标。将负向指标以倒数方式完成正向化,使所有指标具有同趋势性;将原始数据进行归一化处理以消除量纲:
[0137][0138]
最终得到标准化决策矩阵z=(z
ij
)m×n;
[0139]
53)构建加权评价矩阵
[0140]
对评价方案的n维评价指标分配权重,构建的评价指标权重矩阵对标准化决策矩阵进行加权得到加权评价矩阵z`:
[0141][0142]
其中,z'表示加权评价矩阵;w表示评价指标的权重矩阵;wj表示第j个评价指标的权重;
[0143]
54)确定理想解
[0144]
正理想解z
+
是由加权评价矩阵z`中每列最优值组成:
[0145][0146]
其中,表示加权评价矩阵z`中第j列的最优值;
[0147]
负理想解z-是由加权评价矩阵z`中每列最劣值组成:
[0148][0149]
其中,表示加权评价矩阵z`中第j列的最劣值;
[0150]
55)计算距离尺度与优劣排序
[0151]
(1)计算距离尺度,确定评价方案与正、负理想解的欧式距离:
[0152][0153][0154]
其中,d
i+
表示第i个评价方案到正理想解的欧式距离;d
i-表示第i个评价方案到正理想解的欧式距离;z’ij
表示加权评价矩阵中的第i个方案得到的第j个指标的值;
[0155]
(2)计算评价方案与正理想解的接近度:
[0156][0157]
其中,ci表示第i个方案与正理想解的接近度;
[0158]
根据ci高低进行优劣排序,ci值越接近1表明评价方案越优。
[0159]
下面结合具体实例对本实施例融合nsga
‑ⅲ
和topsis的数据驱动多目标优化方法进行进一步说明。
[0160]
1、铣削加工实验环境
[0161]
为了证明本实施例融合nsga
‑ⅲ
和topsis的数据驱动多目标优化方法的可行性,本实施例以铣削加工实验为例,实验所用主要设备如表1所示。
[0162]
表1.实验主要设备
[0163][0164]
实验在vcml850数控铣床上进行,数控系统为siemens 828d,数据处理多目标优化求解采用一台带有4个nvidia geforce rtx 2080ti显卡的windows系统计算机。本实施例采用kistler 9139aa切削力计测量切削过程中的切削力,利用hioki pw3337功率仪采集加工过程中的能耗数据,利用rtec mft-5000测量工件已加工表面的表面粗糙度。
[0165]
本实施例中采用的刀具直径为8mm,齿数为4。为了进一步验证多目标优化方法对切削参数优化的有效性,在固定刀具轨迹上进行了优化实验。为了说明在不同优化目标上的有效性和适应性,本实施例进行了两个案例研究。在第一种情况下,有四个相互冲突的目标:生产率(mrr)、表面粗糙度、最大切削力和能耗。在第二种情况下,有三个相互冲突的目标:生产率、最大切削力和能耗,以表面粗糙度(ra)为约束条件。相应的公式如下:
[0166][0167]
0<a
p
≤4
[0168]
0<ae≤10
[0169]
0.16≤f*n≤0.5
[0170]
30≤vc≤100
[0171]
ra≤0.5μm
[0172]
其中,a
p
为切削深度,ae为切削宽度,f为进给速度,n为刀具的齿数,vc为切削速度。
[0173]
在本实施例中,由于切削参数和目标具有离散性,所以采用了卷积神经网络(cnn)开发最大切削力、表面粗糙度和能耗的预测模型。数据采集系统采集的整个数据集分为三个部分,用于训练、验证和测试的比例分别为70%、15%和15%。利用平均绝对误差(mae)、均方根误差(rmse)和预测精度(pa)对预测模型的性能进行评价。计算公式如下:
[0174][0175]
[0176][0177]
在本实施例中,nsga
‑ⅲ
算法的突变概率和交叉概率分别设为1/55和1。此外,代数和种群大小都设置为100。在第一种情况下,能耗、最大切削力和表面粗糙度被认为是负向指标,因为目的是使其最小化。生产率(即mrr)被认为是一个正向指标,因为优化目的是使其最大化。本案例在第一种情况中假设所有目标的权重相等,即为(0.25,0.25,0.25,0.25)。在第二种情况下,将能耗和最大切削力作为负指标,将生产率(即mrr)作为正指标。为了说明本实施例提出的方法在不同权重上的有效性,在第二种情况下,所有目标的权重被分为四组。第一组、第二组、第三组、第四组的权重分别设为(0.2,0.2,0.6)、(0.3,0.3,0.4)、(0.5,0.4,0.1)、(0.6,0.2,0.2)。
[0178]
2、实验结果分析
[0179]
由表2可以看出,通过基于深度学习的数据驱动代理模型得到的目标函数具有较高的精度和共性,能满足多目标优化对模型精度的要求,可以大大提高优化结果的可靠性。
[0180]
表2预测性能的统计结果
[0181][0182]
在第一种情况下利用nsga
‑ⅲ
和topsis对工艺参数进行多目标优化和求解,结果如表3。
[0183]
表3第一种情况多目标优化及排序结果
[0184]
[0185]
[0186][0187]
由表3可知,75号方案效果最好,得分为0.611,工艺参数分别为97.85、11.15
×
10-2
、9.98、3.99,生成的目标值分别为13.94、966.13、1151
×
10-3
、0.97,这些值满足加工过程的约束条件。结果最差的是26号方案,工艺参数分别为95.30、5.19
×
10-2
、1.63、3.89,对应的目标值分别为40.27、432.30、83.18
×
10-3
、0.52,得到的topsis得分为0.373。
[0188]
表4第二种情况多目标优化及排序结果
[0189][0190]
由表4可知,不同分组的工艺参数和相应的目标变化较大,这主要是由于赋予不同
的权值的造成的。这表明,最佳工艺参数确实随着需求的不同而改变。而且往往很难找到一个合适的解决方案,满足当前的工作要求。但是利用本实施例可以很容易地找出最满足现有工作要求的工艺参数的组合。
[0191]
第一种情况下优化过程的计算时间汇总如表5所示。在第一种情况下,需要优化四个相互冲突的目标,用于在优化上的时间比第二种情况要长。因此,本实施例用第一种情况的时间来说明本方法的效率。优化总时间为160.4s,模型训练总时间为914.2s,优化总时间为1074.6s,这比传统方法用的时间更短,进一步说明了本实施例方法能解决传统方法优化时间长的问题。
[0192]
表5第一种情况下优化过程的计算时间
[0193][0194]
优化过程已在两个案例中成功实施,这证明了本实施例所提出的方法在优化过程中对不同目标的有效性。为了进一步说明这种差异,我们对两种情况下的最佳优化结果进行了比较。对于第二种情况,由于分配给不同目标的权重不同,得到了4个最佳优化结果。通过对比可以发现,第一种情况下的切削力比第一组和第二组在第二种情况下要小,而其他目标则相反。可以发现,虽然得到了最佳的参数组合,但不同的优化目标在不同场合下的响应值差异很大,这进一步说明最佳优化结果往往依赖于不同的工作要求。综上所述,本实施例提出的方法在不同权重和优化目标下的有效性和可行性,证明了提出的方法可以适用于不同的工况,同时操作人员可以很容易地根据他们的实际加工要求调整不同目标的权重,这有助于从复杂的加工参数空间中设计和找到最佳的近似加工参数组合。
[0195]
总的来说,本实施例所提出的方法的主要优势在于通过使用我们提出的方法,可以在不需要额外的成本或理解物理规律的情况下,轻松地构建高精度和通用的目标函数,更具有成本效益和工业实践。本实施例所提出的优化方法是端到端结构,目标函数的构造、优化计算和pareto集求解均采用自动化、集成化的方式,人为干扰最小。与传统的优化方法相比,我们提出的方法具有快速的优化速度,只需几分钟就可以完成优化过程。
[0196]
以上所述实施例仅是为充分说明本发明而所举的较佳的实施例,本发明的保护范围不限于此。本技术领域的技术人员在本发明基础上所作的等同替代或变换,均在本发明的保护范围之内。本发明的保护范围以权利要求书为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1