脉冲神经网络硬件加速器及其在卷积运算中的优化方法
1.本技术涉及图像识别技术领域,具体涉及脉冲神经网络硬件加速器及其在卷积运算中的优化方法。
背景技术:
2.图像识别是机器对人或物体成功辨别的保证,目前大部分基于统计概率学的图像识别技术计算量大且不具有仿生意义,脉冲神经网络(spiking neural network,snn)是源于模拟生物神经元启发的新一代人工神经网络模型,具有丰富的时空动力学特征和多样的编码机制,其通过离散的动作电位或电脉冲的输入累积来实现激活从而完成信息传递。脉冲神经网络的神经元计算仅在收到脉冲信号时发生,且因为二进制脉冲的离散性,脉冲神经网络的输入均为0或1,减少了点积运算,因此,脉冲神经网络在图像识别领域具备高效的计算能力。
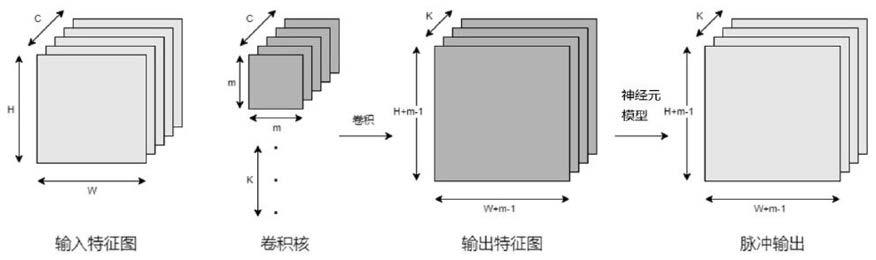
3.脉冲神经网络沿用神经网络的三大拓扑结构,即全连接层、循环层和卷积层,在利用脉冲神经网络硬件加速器识别图像的过程中,卷积运算是较为耗时的部分,所以加速卷积成为众多脉冲神经网络硬件加速器的共同目标。图1为现有技术提供的一种脉冲神经网络准确卷积运算的流程示意图,待识别图像通过脉冲编码转换成二进制脉冲序列后,将二进制脉冲序列作为输入特征图输入卷积层作卷积操作,其中最基本的运算是大小的输入特征图与大小的卷积核二维卷积的过程,卷积核作为滑动窗口在输入特征图上滑动,将卷积核内各权重和对应覆盖区域的脉冲序列值相乘并做累加运算,生成输出特征图中对应位置数据,再经过神经元模型得到对应的脉冲序列输出,将该脉冲序列输出作为下一卷积层的输入特征图继续正向传播。
4.为加速脉冲神经网络的卷积运算,现有技术提供了利用脉冲和修剪权重的稀疏性来消除尽可能多的计算周期的方法,其采用稀疏权重和脉冲的密集编码,以便从dram和片上缓冲区仅检索非零数值值,并采用了一种新颖的笛卡尔积数据流,该数据流利用了权重和脉冲重用,同时仅向乘法器提供非零权重和脉冲。
5.然而,上述现有技术在卷积运算时,只能实现前一层脉冲神经网络卷积层计算完成后,才能计算下一层脉冲神经网络卷积层,卷积运算效率有待进一步提高。
技术实现要素:
6.本技术提供一种脉冲神经网络硬件加速器及其在卷积运算中的优化方法,以实现更快的脉冲神经网络正向传播卷积运算。
7.本技术第一方面提供一种脉冲神经网络硬件加速器在卷积运算中的优化方法,所述脉冲神经网络硬件加速器包括至少两级依次连接的卷积层,所述两级依次连接的卷积层包括第一卷积层和第二卷积层,所述方法包括:步骤1,获取脉冲神经网络硬件加速器的预设参数,所述预设参数包括各级卷积层的卷积核、各卷积核对应的权重平均值和神经元模型;
步骤2,获取待识别图像,以及,根据所述待识别图像,得到所述待识别图像的第一输入特征图,其中,所述待识别图像的第一输入特征图为第一卷积层的输入特征图;步骤3,在第一卷积层上,使用第一卷积层上的卷积核,对所述待识别图像的第一输入特征图作准确卷积操作,得到所述待识别图像的第一准确输出特征图;步骤4,在步骤3的启动时刻,利用第一卷积层的权重平均值,对所述待识别图像的第一输入特征图作预估卷积操作,得到所述待识别图像的第一预估输出特征图,经过所述神经元模型后,得到所述待识别图像的第一预估脉冲输出;步骤5,在步骤4的完成时刻,在第二卷积层上,使用第二卷积层上的卷积核,对所述待识别图像的第一预估脉冲输出作准确卷积操作,得到所述待识别图像的第二预估输出特征图;步骤6,在步骤3的完成时刻,使所述待识别图像的第一准确输出特征图经过所述神经元模型后,得到所述待识别图像的第一准确脉冲输出,以及,基于所述待识别图像的第一准确脉冲输出和所述待识别图像的第一预估脉冲输出的差值,得到第一修正脉冲输出;步骤7,在步骤4的完成时刻,在第二卷积层上,使用第二卷积层的卷积核,对所述第一修正脉冲输出作准确卷积操作,得到第二修正输出特征图,以及,结合所述待识别图像的第二预估输出特征图和所述第二修正输出特征图,得到第二准确输出特征图,经过神经元模型后,确定第二准确脉冲输出。
8.可选的,在步骤4中,所述利用第一卷积层的权重平均值,对所述待识别图像的第一输入特征图作预估卷积操作,得到所述待识别图像的第一预估输出特征图,包括:采用第一卷积层的卷积核大小和步长;利用第一卷积层的卷积核对应的权重平均值,乘以覆盖区域脉冲序列的和,得到对应位置的预估输出。
9.可选的,所述在第一卷积层上,使用第一卷积层上的卷积核,对所述待识别图像的第一输入特征图作准确卷积操作,得到所述待识别图像的第一准确输出特征图,包括:筛选所述待识别图像的第一输入特征图中的非零数值;将所述第一输入特征图中的非零数值逐个映射到对应的输出位置,得到所述待识别图像的第一准确输出特征图;其中,所述将所述第一输入特征图中的非零数值逐个映射到对应的输出位置的映射方法包括:将第一卷积层上的卷积核旋转180度后,得到旋转后的卷积核;如果第一输入特征图中的第x行第y列的数据为1,则在输出特征图中对应的区域累加旋转后的卷积核,其中,为第一卷积层上的卷积核大小,对应的区域在列方向为第x-m+1列到x列,在行方向为y-m+1行到y行;遍历每个所述非零数值,得到所述待识别图像的第一准确输出特征图。
10.可选的,所述在第二卷积层上,使用第二卷积层上的卷积核,对所述待识别图像的第一预估脉冲输出作准确卷积操作,得到所述待识别图像的第二预估输出特征图,包括:筛选所述待识别图像的第一预估脉冲输出中的非零数值;将所述第一预估脉冲输出中的非零数值逐个映射到对应的输出位置,得到所述待识别图像的第二预估输出特征图;
其中,将所述第一预估脉冲输出中的非零数值逐个映射到对应的输出位置的映射方法包括:将第二卷积层上的卷积核旋转180度后,得到旋转后的卷积核;如果第一预估脉冲输出中的第x行第y列的数据为1,则在输出特征图中对应的区域累加旋转后的卷积核,其中,为第一卷积层上的卷积核大小,对应的区域在列方向为第x-m+1列到x列,在行方向为y-m+1行到y行;遍历第一预估脉冲输出中的每个非零数值,得到所述待识别图像的第二预估输出特征图。
11.可选的,所述在第二卷积层上,使用第二卷积层的卷积核,对所述第一修正脉冲输出作准确卷积操作,得到第二修正输出特征图,包括:筛选所述第一修正脉冲输出中的非零数值;将所述第一修正脉冲输出中的非零数值逐个映射到对应的输出位置,得到第二修正输出特征图;其中,所述将所述第一修正脉冲输出中的非零数值逐个映射到对应的输出位置的映射方法包括:将第二卷积层上的卷积核旋转180度后,得到旋转后的卷积核;如果第一修正脉冲输出中的第x行第y列的数据为1,则在输出特征图中对应的区域累加旋转后的卷积核,其中,为第一卷积层上的卷积核大小,对应的区域在列方向为第x-m+1列到x列,在行方向为y-m+1行到y行;遍历每个所述第一修正脉冲输出中的非零数值,得到第二修正输出特征图。
12.可选的,所述脉冲神经网络硬件加速器还包括第三卷积层,所述第三卷积层位于所述第二卷积层的下一级,所述方法还包括:在步骤4的完成时刻,利用第二卷积层的权重平均值,对所述待识别图像的第一预估脉冲输出作预估卷积操作,得到所述待识别图像的第二预估输出特征图,经过所述神经元模型后,得到所述待识别图像的第二预估脉冲输出,以及,在第三卷积层上,使用第三卷积层的卷积核,对所述待识别图像的第二预估脉冲输出作准确卷积操作,得到所述待识别图像的第三预估输出特征图;在步骤7的完成时刻,基于所述待识别图像的第二准确脉冲输出和所述待识别图像的第二预估脉冲输出的差值,得到第二修正脉冲输出;在第三卷积层上,使用第三卷积层的卷积核,对所述第二修正脉冲输出作准确卷积操作,得到第三修正输出特征图,以及,结合所述待识别图像的第三预估输出特征图和所述第三修正输出特征图,得到第三准确输出特征图,经过神经元模型后,确定第三准确脉冲输出。
13.可选的,所述神经元模型为lif模型。
14.本技术第二方面提供一种脉冲神经网络硬件加速器,包括:存储单元,用于存储各级卷积层的卷积核以及每个卷积核的权重平均值,其中各级卷积层包括至少两级依次连接的卷积层,所述两级依次连接的卷积层包括第一卷积层和第二卷积层;准确卷积计算单元,用于获取存储单元中各级卷积层的卷积核,以及,根据各级卷
积层的卷积核,作对应卷积层的卷积计算;预估卷积计算单元,用于在卷积操作时,利用加法逻辑电路求得覆盖区域的脉冲序列和,以及,获取存储单元中对应卷积核的权重平均值,利用乘法器求得权重平均值与脉冲序列和的乘积,得到卷积对应位置的预估输出;神经元模型单元,用于根据神经元膜电位和输出特征图,得到对应的脉冲输出;控制器,用于控制卷积运算的时序;其中,所述控制器被进一步配置为:第一层准确卷积:控制所述准确卷积计算单元,使用第一卷积层上的卷积核,对第一卷积层的输入特征图作准确卷积操作,得到第一准确输出特征图;第一层预估卷积和预估输出:在所述第一层准确卷积的启动时刻,控制所述预估卷积计算单元,使用第一卷积层的权重平均值,对第一卷积层的输入特征图作预估卷积操作,得到第一预估输出特征图,经过所述神经元模型单元后,得到第一预估脉冲输出;第二层不准确卷积:在所述第一层预估卷积和预估输出的完成时刻,控制所述准确卷积计算单元,使用第二卷积层上的卷积核,对第一预估脉冲输出作准确卷积操作,得到第二预估输出特征图;第一层修正输出:在所述第一层准确卷积的完成时刻,使第一准确输出特征图经过所述神经元模型单元后,得到第一准确脉冲输出,以及,基于所述第一准确脉冲输出和所述第一预估脉冲输出的差值,得到第一修正脉冲输出;第二层修正准确卷积:在所述第二层不准确卷积的完成时刻,控制所述准确卷积计算单元,使用第二卷积层上的卷积核,对所述第一修正脉冲输出作准确卷积操作,得到第二修正输出特征图;第二层准确输出:在所述第二层修正准确卷积的完成时刻,结合第二预估输出特征图和第二修正输出特征图,得到第二准确输出特征图,经过神经元模型后,确定第二准确脉冲输出。
15.由以上技术方案可知,本技术提供一种脉冲神经网络硬件加速器及其在卷积运算中的优化方法,该方法在第一卷积层作准确卷积操作的启动时刻,对待识别图像的第一输入特征图作预估卷积操作,经过神经元模型后,得到待识别图像的第一预估脉冲输出,在第二卷积层上,对第一预估脉冲输出作准确卷积操作,得到待识别图像的第二预估输出特征图,再通过第二修正输出特征图得到第二准确输出特征图,经过神经元模型后,确定第二准确脉冲输出,即第二卷积层的准确脉冲输出。在前一层卷积运算未完成时即可开始下一层的卷积运算,利用时间的重叠,加快脉冲神经网络的正向传播卷积计算,不会占用额外的硬件资源。此外,采用本技术提供的准确卷积运算方法,由于修正特征图中的非零数量很少,因此修正卷积不会耗费很多时间,通过误差修正的方法使得增加的工作量大大少于节约的时间。
附图说明
16.图1为现有技术提供的一种脉冲神经网络准确卷积运算的流程示意图;图2为本技术实施例提供的双层卷积运算时序图;图3为本技术实施例提供的一种准确卷积运算的流程示意图;
图4为本技术实施例提供的常规准确卷积流程示意图;图5为本技术实施例提供的修正脉冲输出的矩阵减法示意图;图6为本技术实施例提供的三层卷积层运算时序图。
具体实施方式
17.参见图2,为本技术实施例提供的双层卷积运算时序图。
18.本技术实施例提供一种脉冲神经网络硬件加速器在卷积运算中的优化方法,该脉冲神经网络硬件加速器包括至少两级依次连接的卷积层,该两级依次连接的卷积层包括第一卷积层和位于第一卷积层下一级的第二卷积层,本技术实施例的优化方法在第一卷积层的卷积运算没完成时,先预估计算第二卷积层的卷积运算,以节省时间,需要说明的是,术语“第一”、“第二”仅用于描述目的。本技术实施例的优化方法包括步骤s1至步骤s7。
19.s1、获取脉冲神经网络硬件加速器的预设参数。
20.该预设参数包括已训练完成的各级卷积层的卷积核、各卷积核对应的权重平均值和神经元模型。需要说明的是,本技术实施例从二维卷积的角度阐述卷积运算优化方法的过程,本领域技术人员可以适应性地从二维卷积的运算过程得到三维卷积的运算过程。需要说明的是,各卷积核对应的权重平均值是指二维卷积核内各个权重的平均值,例如,对于卷积核,其对应的权重平均值为卷积核内9个权重值的平均值。
21.进一步的,本技术实施例的神经元模型采用lif(leaky-integrate-and-fire models)模型。lif模型是一个经典的用于模拟神经元活动模式的模型,在本技术实施例中,输入脉冲会以不同的权重作用在神经元膜电位上,使其增加或者减少,当膜电位升高至阈值后,神经元会产生脉冲输出,同时膜电位回落至某个预设的电位。在每个时间周期,由于离子交换作用,神经元膜电位都会在一定程度上降低。
22.s2、获取待识别图像,以及,根据所述待识别图像,得到所述待识别图像的第一输入特征图。
23.本技术实施例的卷积运算优化方法可以选择性地应用在两层相连的卷积层中,例如,某脉冲神经网络有5层连续相连的卷积层,分别为第一层、第二层、第三层、第四层和第五层,则可以将5层卷积层拆分成若干个两层卷积层的连接,比如第一层第二层、第四层第五层均应用本技术实施例的卷积运算优化方法。
24.在获取待识别图像后,得到所述待识别图像的第一输入特征图,需要说明的是,所述待识别图像的第一输入特征图为第一卷积层的输入特征图,第一卷积层和第二卷积层为应用本技术实施例优化方法的双卷积层。
25.例如,在第一层第二层应用本技术实施例的卷积运算优化方法时,第一层即为第一卷积层,第二层即为第二卷积层,将待识别图像通过脉冲编码得到脉冲序列,将该脉冲序列作为第一卷积层的输入特征图。
26.又例如,在第四层第五层应用本技术实施例的卷积运算优化方法时,第四层即为第一卷积层,第五层即为第二卷积层,将待识别图像通过脉冲编码得到脉冲序列,将该脉冲序列通过常规正向传播,经过第一层、第二层和第三层卷积后的脉冲序列作为第一卷积层的输入特征图。
27.脉冲编码包括时序编码和频率编码,频率编码即神经元的脉冲产生频率与输入刺
激强度成正比,时序编码即用神经元首次脉冲的发放时间来表示刺激强度。本技术实施例不具体限定脉冲编码的方式。
28.s3、在第一卷积层上,使用第一卷积层上的卷积核,对所述待识别图像的第一输入特征图作准确卷积操作,得到所述待识别图像的第一准确输出特征图。
29.参见图2中第一卷积层(c1)的计算准确卷积,此步骤为第一卷积层上常规的准确卷积运算,得到第一卷积层上准确输出特征图,即所述待识别图像的第一准确输出特征图。
30.参见图3,图3为本技术实施例提供的一种准确卷积运算的流程示意图,在一部分优选实施例中,可以采用本技术实施例提供的准确卷积运算方法,以下将结合图3对其说明。
31.脉冲神经网络卷积层的输入特征图是一系列由0和1组成的脉冲序列,也是人脑中沿着轴突传递的神经冲动的数字化表示。本技术实施例将输入特征图中每个非零数值映射到输出特征图中,映射方法具体为:其中,输入特征图的行列均从0开始,x代表特征图中的行,y代表特征图中的列,m代表卷积核的大小,如果在输入特征图中第x行y列的数据为1,则在输出特征图中,x-m+1列到x列,y-m+1行到y行,这m
×
m大小区域累加上卷积核旋转180
°
后的值。例如,图3中输入特征图的第0列第4行为1,则在输出特征图对应的第-2列至第0列和第2行至第4行的3
×
3区域累加旋转后的卷积核,依次遍历输入特征图的非零数值,对应的依次在输出特征图对应的区域完成累加后得到实际的输出特征图。本技术实施例提供的准确卷积运算方法只需要遍历输入特征图中的非零数值,计算的时间复杂度与输入特征图中的非零数值个数成正相关,而脉冲序列通常是稀疏矩阵的形式,也就是说这些矩阵中大部分元素都为0,只有少数有意义的部分为1,因此采用该方法可以提高准确卷积的计算效率。
32.在部分优选实施例中,所述在第一卷积层上,使用第一卷积层上的卷积核,对所述待识别图像的第一输入特征图作准确卷积操作,得到所述待识别图像的第一准确输出特征图,包括筛选所述待识别图像的第一输入特征图中的非零数值;将所述第一输入特征图中的非零数值逐个映射到对应的输出位置,得到所述待识别图像的第一准确输出特征图;其中,所述将所述第一输入特征图中的非零数值逐个映射到对应的输出位置的映射方法包括:将第一卷积层上的卷积核旋转180度后,得到旋转后的卷积核;如果第一输入特征图中的第x行第y列的数据为1,则在输出特征图中对应的区域累加旋转后的卷积核,其中,为第一卷积层上的卷积核大小,对应的区域在列方向为第x-m+1列到x列,在行方向为y-m+1行到y行;遍历每个所述非零数值,得到所述待识别图像的第一准确输出特征图。
33.s4,在s3的启动时刻,利用第一卷积层的权重平均值,对所述待识别图像的第一输入特征图作预估卷积操作,得到所述待识别图像的第一预估输出特征图,经过所述神经元模型后,得到所述待识别图像的第一预估脉冲输出。
34.参见图2中n1的预估卷积和预估输出,本技术实施例在第一卷积层(c1)的计算准确卷积启动时刻,开始第一卷积层的预估卷积,该预估卷积具体采用第一卷积层的卷积核大小和步长,利用第一卷积层的卷积核对应的权重平均值,乘以覆盖区域脉冲序列的和,得到对应位置的预估输出。
35.参见图4,为本技术实施例提供的常规准确卷积流程示意图,卷积核在输入特征图上滑动,常规准确卷积将卷积核中每一位权重与对应覆盖区域的数据乘积再求和,作为对应位置的输出,即1.1+2.5+1.2+0=4.8。本技术实施例的预估卷积利用卷积核对应的权重平均值,乘以覆盖区域数据的和,得到对应位置的预估输出,即(1.1+0.4+2.5+2.8+0.1+0.4+1.2+0+1.4)
÷9×
(1+1+1+1)=4.4。
36.由于脉冲神经网络硬件加速器中卷积核的参数是预先训练好不会改变的,因此,卷积核的权重平均值可以预先算得,输入特征图的数据只可能是0或者1,则使用简单的逻辑电路可以进行预估卷积。
37.将所述待识别图像的第一预估输出特征图经过所述神经元模型后,得到所述待识别图像的第一预估脉冲输出,本技术实施例采用lif模型,由于很多神经元的膜电位都处于较低的状态,很难在一个时钟周期内输出峰值,因此预估输出的精确度有一定的保障。
38.s5、在s4的完成时刻,在第二卷积层上,使用第二卷积层上的卷积核,对所述待识别图像的第一预估脉冲输出作准确卷积操作,得到所述待识别图像的第二预估输出特征图。
39.参见图2中第二卷积层(c2)的不准确卷积计算,在s4步骤完成预估输出时,此时第一卷积层上的准确卷积运算还未完成,即可根据所述待识别图像的第一预估脉冲输出,在第二卷积层上,使用第二卷积层上的卷积核对其准确卷积操作,得到所述待识别图像的第二预估输出特征图。
40.其中,在部分优选实施例中,使用第二卷积层上的卷积核对其准确卷积操作,包括筛选所述待识别图像的第一预估脉冲输出中的非零数值;将所述第一预估脉冲输出中的非零数值逐个映射到对应的输出位置,得到所述待识别图像的第二预估输出特征图;其中,将所述第一预估脉冲输出中的非零数值逐个映射到对应的输出位置的映射方法包括:将第二卷积层上的卷积核旋转180度后,得到旋转后的卷积核;如果第一预估脉冲输出中的第x行第y列的数据为1,则在输出特征图中对应的区域累加旋转后的卷积核,其中,为第一卷积层上的卷积核大小,对应的区域在列方向为第x-m+1列到x列,在行方向为y-m+1行到y行;遍历第一预估脉冲输出中的每个非零数值,得到所述待识别图像的第二预估输出特征图。
41.s6,在s3的完成时刻,使所述待识别图像的第一准确输出特征图经过所述神经元模型后,得到所述待识别图像的第一准确脉冲输出,以及,基于所述待识别图像的第一准确脉冲输出和所述待识别图像的第一预估脉冲输出的差值,得到第一修正脉冲输出。
42.参见图2中n1的修正输出,在第一卷积层的准确卷积计算完成后,经过神经元模型,得到所述待识别图像的第一准确脉冲输出,用所述待识别图像的第一准确脉冲输出减去所述待识别图像的第一预估脉冲输出,得到第一修正脉冲输出,示例性得,图5为本技术实施例提供的修正脉冲输出的矩阵减法示意图。
43.s7,在s4的完成时刻,在第二卷积层上,使用第二卷积层的卷积核,对所述第一修正脉冲输出作准确卷积操作,得到第二修正输出特征图,以及,结合所述待识别图像的第二预估输出特征图和所述第二修正输出特征图,得到第二准确输出特征图,经过神经元模型后,确定第二准确脉冲输出。
44.参见图2中第二卷积层(c2)的修正准确卷积,在第二层的不准确卷积计算完成时,
利用第二卷积层的卷积核,对所述第一修正脉冲输出作准确卷积操作,得到第二修正输出特征图。
45.在部分优选实施例中,对所述第一修正脉冲输出作准确卷积操作包括:筛选所述第一修正脉冲输出中的非零数值;将所述第一修正脉冲输出中的非零数值逐个映射到对应的输出位置,得到第二修正输出特征图;其中,所述将所述第一修正脉冲输出中的非零数值逐个映射到对应的输出位置的映射方法包括:将第二卷积层上的卷积核旋转180度后,得到旋转后的卷积核;如果第一修正脉冲输出中的第x行第y列的数据为1,则在输出特征图中对应的区域累加旋转后的卷积核,其中,为第二卷积层上的卷积核大小,对应的区域在列方向为第x-m+1列到x列,在行方向为y-m+1行到y行;遍历每个所述第一修正脉冲输出中的非零数值,得到第二修正输出特征图。
46.由于所述第一修正脉冲输出中的非零数量很少,因此计算修正的准确卷积并不会耗费太多的时间,通过误差修正的方式使得增加的工作量大大少于节约的时间。
47.参见图2中n2的准确输出,将所述待识别图像的第二预估输出特征图和所述第二修正输出特征图相加,得到第二准确输出特征图,经过神经元模型后,确定第二准确脉冲输出。
48.参见图6,在部分优选实施例中,所述脉冲神经网络硬件加速器还包括第三卷积层,所述第三卷积层位于所述第二卷积层的下一级,所述方法还包括:s8、在s4的完成时刻,利用第二卷积层的权重平均值,对所述待识别图像的第一预估脉冲输出作预估卷积操作,得到所述待识别图像的第二预估输出特征图,经过所述神经元模型后,得到所述待识别图像的第二预估脉冲输出,以及,在第三卷积层上,使用第三卷积层的卷积核,对所述待识别图像的第二预估脉冲输出作准确卷积操作,得到所述待识别图像的第三预估输出特征图。
49.s9、在s7的完成时刻,基于所述待识别图像的第二准确脉冲输出和所述待识别图像的第二预估脉冲输出的差值,得到第二修正脉冲输出。
50.s10、在第三卷积层上,使用第三卷积层的卷积核,对所述第二修正脉冲输出作准确卷积操作,得到第三修正输出特征图,以及,结合所述待识别图像的第三预估输出特征图和所述第三修正输出特征图,得到第三准确输出特征图,经过神经元模型后,确定第三准确脉冲输出。
51.三层卷积层相连也能够使用本技术实施例的优化方法,但是由于第三卷积层的输入特征图是第一卷积层和第二卷积层经过两次估算得到,在准确性上有所欠缺,可能导致修正准确卷积的时间更长。但其利用更多的时间重叠,在时间效率方面有较大提升。
52.本技术实施例还提供了一种脉冲神经网络硬件加速器,包括存储单元、准确卷积计算单元、预估卷积计算单元、神经元模型单元和控制器。
53.存储单元,用于存储各级卷积层的卷积核以及每个卷积核的权重平均值,其中各级卷积层包括至少两级依次连接的卷积层,所述两级依次连接的卷积层包括第一卷积层和第二卷积层。
54.准确卷积计算单元,用于获取存储单元中各级卷积层的卷积核,以及,根据各级卷积层的卷积核,作对应卷积层的卷积计算。
55.预估卷积计算单元,用于在卷积操作时,利用加法逻辑电路求得覆盖区域的脉冲
序列和,以及,获取存储单元中对应卷积核的权重平均值,利用乘法器求得权重平均值与脉冲序列和的乘积,得到卷积对应位置的预估输出。
56.神经元模型单元,用于根据神经元膜电位和输出特征图,得到对应的脉冲输出。
57.控制器,用于控制卷积运算的时序。
58.其中,所述控制器被进一步配置为:第一层准确卷积:控制所述准确卷积计算单元,使用第一卷积层上的卷积核,对第一卷积层的输入特征图作准确卷积操作,得到第一准确输出特征图;第一层预估卷积和预估输出:在所述第一层准确卷积的启动时刻,控制所述预估卷积计算单元,使用第一卷积层的权重平均值,对第一卷积层的输入特征图作预估卷积操作,得到第一预估输出特征图,经过所述神经元模型单元后,得到第一预估脉冲输出;第二层不准确卷积:在所述第一层预估卷积和预估输出的完成时刻,控制所述准确卷积计算单元,使用第二卷积层上的卷积核,对第一预估脉冲输出作准确卷积操作,得到第二预估输出特征图;第一层修正输出:在所述第一层准确卷积的完成时刻,使第一准确输出特征图经过所述神经元模型单元后,得到第一准确脉冲输出,以及,基于所述第一准确脉冲输出和所述第一预估脉冲输出的差值,得到第一修正脉冲输出;第二层修正准确卷积:在所述第二层不准确卷积的完成时刻,控制所述准确卷积计算单元,使用第二卷积层上的卷积核,对所述第一修正脉冲输出作准确卷积操作,得到第二修正输出特征图;第二层准确输出:在所述第二层修正准确卷积的完成时刻,结合第二预估输出特征图和第二修正输出特征图,得到第二准确输出特征图,经过神经元模型后,确定第二准确脉冲输出。
59.本技术实施例提供一种脉冲神经网络硬件加速器及其在卷积运算中的优化方法,该方法在第一卷积层作准确卷积操作的启动时刻,对待识别图像的第一输入特征图作预估卷积操作,经过神经元模型后,得到待识别图像的第一预估脉冲输出,在第二卷积层上,对第一预估脉冲输出作准确卷积操作,得到待识别图像的第二预估输出特征图,再通过第二修正输出特征图得到第二准确输出特征图,经过神经元模型后,确定第二准确脉冲输出,即第二卷积层的准确脉冲输出。
60.由以上技术方案可知,本技术实施例在前一层卷积运算未完成时即可开始下一层的卷积运算,利用时间的重叠,加快脉冲神经网络的正向传播卷积计算,不会占用额外的硬件资源。此外,在部分优选实施例中,采用本技术提供的准确卷积运算方法,由于修正特征图中的非零数量很少,因此修正卷积不会耗费很多时间,通过误差修正的方法使得增加的工作量大大少于节约的时间。
61.以上所述的本技术实施方式并不构成对本技术保护范围的限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1