一种基于多任务学习的蒙汉非自回归机器翻译方法
1.本发明属于机器翻译技术领域,特别涉及一种基于多任务学习的蒙汉非自回归机器翻译方法。
背景技术:
2.近年来,随着不同区域沟通的需要,机器翻译得到了长远的发展,蒙古语等低资源语言的机器翻译也越来越受到重视。由于蒙古语与汉语的翻译中,平行语料匮乏及语义特征提取困难等原因,导致翻译过程仍存在很多不足,包括训练时间过长、翻译不准确、语义信息表达不足以及词向量表征不准确等。
3.神经机器翻译(nmt)作为最先进的机器翻译方式,近年来有两种不同的序列解码策略。第一种是自回归翻译(at)模型,模型按照从左到右的方向逐个生成输出序列,但是其解码速度慢。第二种是非自回归翻译(nat)模型,采用并行解码算法同时产生输出序列,但其翻译质量往往低于自回归翻译模型。尽管at和nat编码器属于相同的顺序学习任务,但它们捕获的是源句子的不同语言属性。
4.目前,针对非自回归的机器翻译提出一系列的方法进行改进,引入隐变量、迭代翻译知识蒸馏等技术,但这些方法在蒙汉翻译方面未取得较好的效果。
技术实现要素:
5.为了克服上述现有技术的缺点,本发明的目的在于提供一种基于多任务学习的蒙汉非自回归机器翻译方法,采用多任务学习,通过编码器共享将自回归翻译模型的知识转移到非自回归翻译模型,将自回归翻译模型作为提高非自回归翻译模型性能的辅助任务;从而希望在保证翻译速率提高的前提下,还能提高蒙汉翻译质量。
6.为了实现上述目的,本发明采用的技术方案是:
7.一种基于多任务学习的蒙汉非自回归机器翻译方法,包括如下步骤:
8.步骤1,对蒙汉平行语料进行预处理;
9.步骤2,将预处理得到的蒙汉平行语料数据集划分为训练集,验证集和测试集三部分;
10.步骤3,搭建共享编码器的自回归翻译模型和非自回归翻译模型,并由共享编码器、自回归翻译模型解码器和非自回归翻译模型解码器构成一个多任务学习框架;
11.步骤4,在所述多任务学习框架下,基于所述训练集训练所述非自回归翻译模型,从而将自回归翻译模型的知识转移到非自回归翻译模型;
12.步骤5,利用步骤4得到的非自回归翻译模型执行蒙汉翻译。
13.在一个实施例中,所述步骤1,对于汉语,先进行分词处理,然后再使用bpe进行切分;对于蒙古语,直接使用bpe切分。
14.在一个实施例中,所述步骤3,自回归翻译模型解码器的输入是上一步解码出的结果,每一步解码生成都依赖于上一步解码的结果,当解码到eos标志时,序列的生成过程自
动停止,得到最终的解码序列;非自回归翻译模型解码器为并行输出。
15.在一个实施例中,所述多任务学习框架在迭代步长t时的损失函数定义为自回归翻译模型与非自回归翻译模型损失的加权和:
[0016][0017]
其中,l
at
和l
nat
分别为自回归翻译模型与非自回归翻译模型的损失;θ
enc
、分别为共享编码器、自回归翻译模型解码器和非自回归翻译模型解码器的参数;在迭代步长t时,λ
t
为调节自回归翻译模型和非自回归翻译模型之间平衡的参数:
[0018][0019]
其中t为训练的总步骤,l
at
的权值在训练过程中从1.0线性退火到0.0,而l
nat
的权值从0.0增加到1.0;
[0020]
在进行模型训练时,将蒙古语句子x输入至编码器,将汉语句子y分别输入至自回归翻译模型解码器和非自回归翻译模型解码器,在训练过程中只使用非自回归翻译模型解码器生成的汉语译文,其中所述汉语句子y为数据集中与蒙古语句子x对应的汉语翻译。
[0021]
与现有技术相比,本发明的有益效果是:
[0022]
非自回归翻译模型和自回归翻译模型的编码器可以捕捉源句子的不同属性,具体来说,以往的非自回归翻译模型虽然大大提高了解码速度但是降低了翻译质量。因此本发明采用多任务学习的方法来进行蒙汉翻译,通过编码器共享将自回归机器翻译模型知识转移到非自回归机器翻译模型中,将自回归机器翻译模型作为一种辅助任务来提高非自回归翻译模型的性能。
附图说明
[0023]
图1为自回归与非自回归翻译模型区别。
[0024]
图2为多任务学习框架。
具体实施方式
[0025]
下面结合附图和实施例详细说明本发明的实施方式。
[0026]
本发明为一种基于多任务学习的蒙汉非自回归机器翻译方法,包括如下步骤:
[0027]
步骤1,对蒙汉平行语料进行预处理。
[0028]
对于汉语,由于其不像蒙古语和英语一样单词之间存在空格,因此先进行一个分词处理,本实施例采用的是现下流行的jieba中文分词技术,然后再使用bpe进行切分。而对于蒙古语,则直接使用bpe切分。进行词切分这一过程可以在一定程度上缓解低频词的影响。
[0029]
步骤2,将预处理得到的蒙汉平行语料数据集划分为训练集,验证集和测试集三部分。
[0030]
其中,训练集用来训练翻译模型,其质量的好坏决定了模型的表现。验证集使模型在训练中能实时了解翻译性能如何。测试集用于在模型训练结束后,来测试最终模型的翻
译效果。
[0031]
三部分的比例可依据惯例或者其它参考因素人为设定,例如,训练集,验证集和测试集的比例可以为8:1:1。
[0032]
步骤3,搭建共享编码器的自回归翻译模型和非自回归翻译模型,并由共享编码器、自回归翻译模型解码器和非自回归翻译模型解码器构成一个多任务学习框架。
[0033]
本发明自回归翻译模型和非自回归翻译模型使用相同的编码器。参考图1,《bos》表示句子开始符,自回归翻译模型解码器的输入是上一步解码出的结果,每一步解码生成都依赖于上一步解码的结果,当解码到句子结束符《eos》时,序列的生成过程便自动停止,得到最终的解码序列。而非自回归翻译模型没有这样的依赖特性,实现了解码器的并行输出,提高了翻译的速度。
[0034]
步骤4,在多任务学习框架下,基于训练集训练非自回归翻译模型,从而将自回归翻译模型的知识转移到非自回归翻译模型。
[0035]
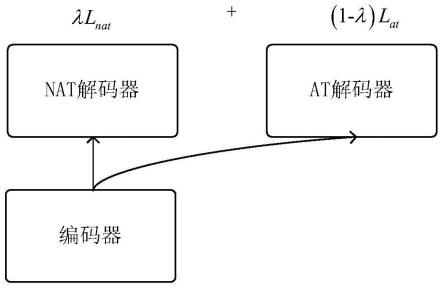
本发明利用一个附加的自回归翻译任务作为辅助任务,该任务的编码器参数与非自回归翻译任务共享,而解码器参数是互斥的。鉴于标准编码器结构下的自回归翻译模型和非自回归翻译模型,本发明将采用硬参数共享方法来共享它们的编码器参数。如图2所示为本发明所采用的多任务学习框架,框架由三部分组成:共享编码器、自回归翻译模型解码器和非自回归翻译模型解码器。
[0036]
自回归翻译模型在翻译目标语句时,模型从左到右逐字翻译。具体来说,给定蒙古语句子对于可能输出的汉语句子按照如下的方式生成:
[0037][0038]
其中,t在此处表示当前的迭代步长,y
<t
表示当前已经生成的目标单词,θ
enc
、分别为共享编码器、自回归翻译模型解码器的参数。
[0039]
是输出的汉语句子的最后一个词。ty是输出的汉语句子中总词数。y
t
是第t个输出的汉语词。是蒙古语句子的最后一个词。t
x
是蒙古语语句子中总词数。
[0040]
对输出分布进行自回归分解,可以直接进行最大似然训练,并在迭代步长t时应用自回归翻译模型的交叉熵损失:
[0041][0042]
非自回归翻译模型在翻译目标语句时,去除生成目标语句时单词之间的依赖关系之后,生成的过程可以用如下方式表示:
[0043][0044]
z是非自回归翻译模型的解码器的输入。
[0045]
自回归翻译模型与非自回归翻译模型的编码器完全相同,而在解码器,训练时,自
回归翻译模型的输入是蒙古语句子x所对应的译文,非自回归翻译模的输入是上式中的z:
[0046]
z=f(x;θ
enc
)
[0047]
f()表示生成力预测模块所做的运算。
[0048]
通过复制源语句x来得到z,比如将句子“hello,world.”翻译成中文,如果输出译文是“你好,世界。”hello翻译成中文是两个字,那么生成力值为2;world翻译成中文也是两个字,那么生成力值为2。所以在这里x为“hello,world.”,z可以简单的理解为“hello hello,world world”。
[0049]
非自回归翻译模型的并行输出是通过将编码器的每个输入单词作为解码器的一个输入复制零次或多次,每个输入被复制的次数称为输入单词的“生成力”。每个单词的生成力值由其对应翻译成目标译文后的单词长度决定,而结果输出长度由所有单词生成力值的总和决定。引入了生成力预测模块来预测x中的每个单词在复制过程中会被复制多少次。最大似然损失函数即非自回归翻译模型的损失如下:
[0050][0051]
本发明所使用的多任务学习框架中自回归与非自回归翻译模型的编码器参数共享,在迭代步长t时的框架整体损失函数定义为自回归翻译模型与非自回归翻译模型损失的加权和:
[0052][0053]
其中,l
at
和l
nat
分别为自回归翻译模型与非自回归翻译模型的损失;θ
enc
、分别为共享编码器、自回归翻译模型解码器和非自回归翻译模型解码器的参数;在迭代步长t时,λ
t
为调节自回归翻译模型和非自回归翻译模型之间平衡的参数:
[0054][0055]
其中t为训练的总步骤;由于l
at
仅起辅助作用,并不直接影响非自回归翻译模型,因此直接在训练过程接近尾声时降低at损失的重要性。在该方案下,l
at
的权值在训练过程中从1.0线性退火到0.0,而l
nat
的权值从0.0增加到1.0。
[0056]
在进行模型训练时,将蒙古语句子x输入至编码器,将汉语句子y分别输入至自回归翻译模型解码器和非自回归翻译模型解码器,在训练过程中只使用非自回归翻译模型解码器生成的汉语译文,其中汉语句子y为数据集中与蒙古语句子x对应的汉语翻译。
[0057]
步骤5,利用步骤4得到的非自回归翻译模型执行蒙汉翻译。
[0058]
在本发明的一个实施例中,以翻译为例,将源语言句子切分成对应的将译文“今天是晴天”切分成
“‑
,今天,是,晴天”。将依次分别输入到自回归和非自回归翻译模型,在自回归翻译模型中依次生成译文“今天天晴”,在非自回归翻译模型中并行生成译文“今天是晴天”。在翻译过程中,两个模型的编码器参数共享,最后以非自回归翻译模型所产生的译文“今天是晴天”为最终输出。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1