一种数字集成电路布线后路径延时预测方法
1.本发明属于电子设计自动化领域,涉及一种数字集成电路布线后路径延时预测方法。
背景技术:
2.随着芯片设计和制造的复杂度越来越高,静态时序分析已经成为在数字集成电路各个设计阶段中验证芯片时序正确性、评估芯片能否在预期频率下正常工作的必要环节。数字集成电路物理设计中的各阶段都需要与静态时序分析频繁交互,根据时序分析结果来指导设计流程。随着工艺节点的不断进步,各设计阶段间时序不一致问题日渐严重。对于下游设计阶段,不准确的时序估计会使得时序不收敛,导致设计迭代,影响设计进度,同时需要耗费巨大的计算资源,造成设计成本的浪费,给设计流程带来极大的挑战。
3.时序分析和优化贯穿数字集成电路设计流程的各个阶段,其准确性和执行速度对于时序收敛尤为关键。尤其在物理设计后期,布线引入的寄生电容及必要的时序优化措施所导致的布线前后时序不一致问题,对物理设计早期精确高效的时序分析提出了挑战。工程中常采用的悲观时序估计策略会造成过度优化,浪费电路面积、功耗和设计时间。而基于数学模型的传统快速布线前时序估计方法主要关注线长或线延时,忽视了布线对单元延时和路径延时的影响。近年来,基于机器学习的布线前时序预测方法只停留于对布线后单级单元和网络的延时预测,忽略了路径中各级单元间的时序和物理相关性,并在累加获得路径延时预测值时,存在着误差累积和计算复杂度增加的弊端。
技术实现要素:
4.技术问题:本发明的目的是提出一种数字集成电路布线后路径延时预测方法,能够在布线前的布局阶段对布线后的路径延时进行准确预测,从而有效指导电路布线前设计与优化。
5.技术方案:一种数字集成电路布线后路径延时预测方法,所述布线后路径延时预测是指在数字集成电路后端设计流程中的布局阶段对布线后路径延时的预测;所述路径至少包含两级组合逻辑单元,且不包含时序逻辑单元;所述方法包括以下步骤:
6.s1:通过物理设计工具对逻辑综合后的电路网表进行物理设计,设计步骤包括布局规划、布局、时钟树综合、布线等;
7.s2:进行样本数据提取,通过静态时序分析工具对步骤s1中布局后和布线后的电路分别进行静态时序分析,从布局后电路的静态时序报表和版图信息中提取路径中各级单元的时序和物理信息,组成路径的特征序列,从布线后电路的静态时序分析报表中提取对应路径的延时值作为标签;
8.s3:将步骤s2中提取的样本数据进行预处理,对连续型特征序列中的每个连续型特征值进行离散化处理,对离散型特征序列中每个离散型特征值进行从离散文本到类别变量的映射,并进行特征序列填充以保证所有特征序列长度相同;
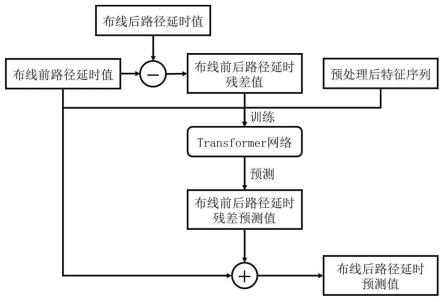
9.s4:搭建布线后路径延时预测模型,将步骤s3中预处理后的样本数据输入编码器网络,布线前路径延时值与编码器网络的输出数据进行合并,经过降维得到布线前后路径延时残差预测值。将布线前路径延时值与布线前后路径延时残差预测值相加,最终得到布线后路径延时预测值;
10.s5:对步骤s4中搭建的模型进行训练与验证,将步骤s3中预处理后的样本数据随机划分为训练集数据和测试集数据,使用训练集数据进行模型训练,使用测试集数据对模型预测精度和效率进行验证。
11.所述步骤s2中,对步骤s1中布局后电路进行静态时序分析,从静态时序分析报表和版图信息中分别提取路径中各级单元的时序和物理信息,构成路径的特征序列。单元的时序信息包括本级单元的输入转换时间、本级单元的输出转换时间、本级单元的单元延时、本级单元的输入信号极性、本级单元的输出信号极性;单元的物理信息包括本级单元的输入引脚电容、本级单元的总输出负载电容、本级单元的扇出数、本级单元的类型、本级单元的输出引脚与下一级单元的输入引脚的距离、本级单元的输入引脚与下一级单元的输入引脚的距离。
12.所述步骤s3具体包括以下步骤:
13.s31:通过分箱法对连续型特征序列中的每个连续型特征值进行离散化处理。连续型特征序列包括路径中每级单元的输入转换时间序列、每级单元的输出转换时间序列、每级单元的延时序列、每级单元的输入引脚电容序列、每级单元的总输出负载电容序列、每级单元的输出引脚与下一级单元的输入引脚的距离序列、每级单元的输入引脚与下一级单元的输入引脚的距离序列。分箱法通过观察特征的中位数、最大值、最小值以及特征值的物理意义来确定特征值需要保留的精度。若连续型特征序列中某个连续型特征值为x,分箱法处理后该连续型特征值为x’,m为该连续型特征值需要扩大的倍数,round()函数返回最靠近输入值的整数,则分箱法的计算公式为公式(1):
14.x
′
=round(m
·
x)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
15.s32:通过分词器法对离散型特征序列中每个离散型特征值进行从离散文本到类别变量的映射。离散型特征序列包括路径中每级单元的输入信号极性序列、每级单元的输出信号极性序列、每级单元的扇出数序列、每级单元的类型序列。分词器法首先训练映射词典,然后根据词典得到映射后的类别变量序列。
16.s33:进行特征序列填充,使得特征序列长度相同。设定训练集数据特征序列最大长度为max_len,则在长度小于max_len的特征序列末尾填充“0”,使得该特征序列长度为max_len。对于测试集数据中长度大于max_len的特征序列,将其长度大于max_len的序列部分截断,使得该特征序列长度为max_len。
17.所述步骤s4中,所述编码器网络为transformer网络,其包括输入嵌入与位置编码、多头自注意力机制、全连接前馈网络、相加与标准化。所述步骤s4具体包括以下步骤:
18.s41:在输入嵌入过程中,对于每个输入序列特征都有一个专门的可训练嵌入层,将输入序列中的每个元素都转化为一个维度为dimk的向量。即将维度为(samples,max_len)的输入特征序列转换为维度为(samples,max_len,dimk)的张量,其中samples是样本数量,max_len是路径最大级数,dimk是第k个特征序列在嵌入层中指定的词向量维度,k=1,2,
…
,n,n是输入特征序列个数。在位置编码过程中,采用公式(2)和公式(3)所示的三角
函数,来帮助网络理解路径中各级单元的特征在序列中的位置关系。其中pos表示某特征值在序列中的位置,pos=1,2,
…
,max_len,m为该特征值的位置编码序列的维度索引,m=0,1,
…
,dimk/2-1,其中偶数维度处(2m)采取正弦函数(sin)编码,奇数维度处(2m+1)采取余弦函数(cos)编码,位置编码后输出张量的维度也为(samples,max_len,dimk)。即在特征序列pos处的特征值的位置编码序列在2m处的编码值为pe
(pos,2m)
,在2m+1处的编码值为pe
(pos,2m+1)
。对于每个特征序列,都将位置编码的输出张量与输入嵌入后的输出张量相加,得到n个维度为(samples,max_len,dimk)的新张量。
[0019][0020][0021]
s42:将步骤s41中n个新张量进行合并,得到一个维度为(samples,max_len,dim)的张量,作为多头自注意力机制的输入x,其中dim=dim1+dim2+
…
+dimn,n是输入特征序列个数。x的第j个行向量为路径中第j级单元在时序和物理信息上的综合特征表达,j=1,2,
…
,max_len。通过三个可训练的矩阵w
iq
、w
ik
、w
iv
,i=1,2,
…
,h,对x分别进行h次线性变换,得到h组词向量维度均为dk=dim/h的矩阵qi、ki、vi,h是自注意力机制的头数,q、k、v分别表示查询(query),地址(key),值(value)。对h组qi、ki、vi并行执行注意力函数,基于点积的注意力机制的计算公式为公式(4)。首先计算qi与ki转置的点积并除以系数d
k1/2
,随后通过柔性最大值传输函数(softmax)运算得到权重矩阵c,最后将权重矩阵c点乘vi得到维度为dk的矩阵zi,即为注意力机制的计算结果attention(qi,ki,vi)。权重矩阵c第a行、第b列的元素可以认为是路径中第a级单元和第b级单元的时序和物理相关性,a=1,2,
…
,max_len;b=1,2,
…
,max_len,矩阵zi行向量的个数与输入x相同,因此zi行向量也有与x类似的单元时序和物理含义。
[0022][0023]
合并h头注意力机制的计算结果headi,i=1,2,
…
,h,并通过一个可训练矩阵wo进行一次线性变换,得到多头自注意力机制的输出multihead(x)。多头自注意力机制的计算公式为公式(5),其中x为多头自注意力机制的输入,w
iq
、w
ik
、w
iv
、wo为可训练的矩阵,i=1,2,
…
,h。
[0024][0025]
s43:将步骤s42中多头自注意力机制的输入x和输出multihead(x)相加,并进行标准化,来避免梯度消失和梯度爆炸,多头自注意力机制标准化层的输出可表示为(6),layernorm()为标准化层的输出函数。
[0026]
layernorm(x+multihead(x))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0027]
s44:将步骤s43中多头自注意力机制标准化后的输出接入全连接前馈神经网络,其相邻两层的神经元间为全连接。首先对输入进行一次线性变换,然后经过线性整流激活函数max(0,s),s为线性整流激活函数的输入,最后再经过一次线性变换。t是全连接前馈神
经网络的输入,w1、b1和w2、b2分别是两次线性变换的参数,则全连接前馈神经网络的输出计算公式为公式(7):
[0028]
ffn(t)=max(0,tw1+b1)w2+b2ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
[0029]
s45:将步骤s44中全连接前馈神经网络的输入t和输出ffn(t)相加,并进行标准化,来避免梯度消失和梯度爆炸,连接前馈神经网络标准化层的输出可表示为(8),layernorm()为标准化层的输出函数。
[0030]
layernorm(t+fnn(t))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)
[0031]
s46:将步骤s45中全连接前馈神经网络标准化层的输出接入池化(pooling)层,将三维数据展平为二维数据,并接入全连接(dense)层进行非线性变换,通过丢弃函数(dropout)随机丢弃部分信息,以防止过拟合。随后与经过非线性变换和信息随机丢弃后的布线前路径延时值特征进行数据合并,并将合并后的数据非线性变换至一维,得到布线前后路径延时残差预测值。最后将布线前路径延时值与布线前后路径延时残差预测值相加,得到最终布线后路径延时预测值。
[0032]
有益效果:本发明公开了一种数字集成电路布线后路径延时预测方法。利用transformer网络的自注意力机制捕获路径中各级单元的时序和物理相关性,从而对路径延时进行直接预测。并利用残差预测结构对布线后路径延时预测值进行校准,从而提高了预测精度。与传统静态时序分析流程相比,本发明可以在布线前准确且高效地预测布线后路径延时,从而有效指导电路布线前设计与优化,对于加速数字集成电路设计流程具有重要意义。
附图说明
[0033]
图1为本发明数字集成电路布线后路径延时预测框架示意图;
[0034]
图2为本发明数字集成电路布线后路径延时残差预测结构示意图;
[0035]
图3为transformer网络结构示意图;
[0036]
图4为多头自注意力机制计算过程示意图。
具体实施方式
[0037]
下面结合具体实施方式对本发明的技术方案作进一步的介绍。
[0038]
一种数字集成电路布线后路径延时预测方法,所述布线后路径延时预测是指在数字集成电路后端设计流程中的布局阶段对布线后路径延时的预测;所述路径至少包含两级组合逻辑单元,且不包含时序逻辑单元;所述方法包括以下步骤:
[0039]
s1:通过物理设计工具对逻辑综合后的电路网表进行物理设计,设计步骤包括布局规划、布局、时钟树综合、布线等。例如在smic 40nm工艺、tt工艺角、1.1v电压、25℃温度下,通过ic complier对逻辑综合后的9个iscas和opencores的基准电路进行物理设计;
[0040]
s2:进行样本数据提取,通过静态时序分析工具对步骤s1中布局后和布线后的电路分别进行静态时序分析,从布局后电路的静态时序报表和版图信息中提取路径中各级单元的时序和物理信息,组成路径的特征序列,从布线后电路的静态时序分析报表中提取对应路径的延时值作为标签。例如在smic 40nm工艺、tt工艺角、1.1v电压、25℃温度下,设定时钟周期为5ns,通过primetime对布局后和布线后的9个iscas和opencores的基准电路进
行静态时序分析;
[0041]
s3:将步骤s2中提取的样本数据进行预处理,通过分箱法对连续型特征序列中的每个连续型特征值进行离散化处理,通过分词器法对离散型特征序列中每个离散型特征值进行从离散文本到类别变量的映射,并进行特征序列填充以保证所有特征序列长度相同。例如通过python编写的开源人工神经网络库keras完成分箱法、分词器法和序列填充;
[0042]
s4:搭建布线后路径延时预测模型,将步骤s3中预处理后的样本数据输入transformer网络,布线前路径延时值与transformer网络的输出数据进行合并,经过降维得到布线前后路径延时残差预测值。将布线前路径延时值与布线前后路径延时残差预测值相加,最终得到布线后路径延时预测值。例如通过python编写的开源人工神经网络库keras和机器学习库scikit-learn实现布线后路径延时预测模型搭建;
[0043]
s5:对步骤s4中搭建的模型进行训练与验证,将步骤s3中预处理后的样本数据随机划分为训练集数据和测试集数据,使用训练集数据进行模型训练,使用测试集数据对模型预测精度和效率进行验证。例如将9个iscas和opencores的基准电路中6个电路所提取的所有路径中随机选取80%的路径作为训练集数据进行模型训练,剩下20%的路径用于验证模型在已知电路上的预测性能,并将剩下3个电路所提取的所有路径用于验证模型在未知电路上的预测性能。训练时设置优化器为adam,学习率为0.001,训练批次个数为1080,损失函数为均方根误差(rmse)。
[0044]
所述步骤s2中,对步骤s1中布局后电路进行静态时序分析,从静态时序分析报表和版图信息中分别提取路径中各级单元的时序和物理信息,构成路径的特征序列。单元的时序信息包括本级单元的输入转换时间、本级单元的输出转换时间、本级单元的单元延时、本级单元的输入信号极性、本级单元的输出信号极性;单元的物理信息包括本级单元的输入引脚电容、本级单元的总输出负载电容、本级单元的扇出数、本级单元的类型、本级单元的输出引脚与下一级单元的输入引脚的距离、本级单元的输入引脚与下一级单元的输入引脚的距离。
[0045]
所述步骤s3具体包括以下步骤:
[0046]
s31:通过分箱法对连续型特征序列中的每个连续型特征值进行离散化处理。连续型特征序列包括路径中每级单元的输入转换时间序列、每级单元的输出转换时间序列、每级单元的延时序列、每级单元的输入引脚电容序列、每级单元的总输出负载电容序列、每级单元的输出引脚与下一级单元的输入引脚的距离序列、每级单元的输入引脚与下一级单元的输入引脚的距离序列。分箱法通过观察特征的中位数、最大值、最小值以及特征值的物理意义来确定特征值需要保留的精度。若连续型特征序列中某个连续型特征值为x,分箱法处理后该连续型特征值为x’,m为该连续型特征值需要扩大的倍数,round()函数返回最靠近输入值的整数,则分箱法的计算公式为公式(1):
[0047]
x
′
=round(m
·
x)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0048]
s32:通过分词器法对离散型特征序列中每个离散型特征值进行从离散文本到类别变量的映射。离散型特征序列包括路径中每级单元的输入信号极性序列、每级单元的输出信号极性序列、每级单元的扇出数序列、每级单元的类型序列。分词器法首先训练映射词典,然后根据词典得到映射后的类别变量序列。例如分词器法通过python编写的开源人工神经网络库keras的tokenizer完成,首先使用fit_on_texts训练映射词典,然后使用
texts_to_sequences得到映射后的序列特征。
[0049]
s33:进行特征序列填充,使得特征序列长度相同。设定训练集数据特征序列最大长度为max_len,则在长度小于max_len的特征序列末尾填充“0”,使得该特征序列长度为max_len。对于测试集数据中长度大于max_len的特征序列,将其长度大于max_len的序列部分截断,使得该特征序列长度为max_len。例如特征序列填充通过python编写的开源人工神经网络库keras的pad_sequences完成。
[0050]
所述步骤s4中,使用了transformer网络,其包括输入嵌入与位置编码、多头自注意力机制、全连接前馈网络、相加与标准化。所述步骤s4具体包括以下步骤:
[0051]
s41:在输入嵌入过程中,对于每个输入序列特征都有一个专门的可训练嵌入层,将输入序列中的每个元素都转化为一个维度为dimk的向量。即将维度为(samples,max_len)的输入特征序列转换为维度为(samples,max_len,dimk)的张量,其中samples是样本数量,max_len是路径最大级数,dimk是第k个特征序列在嵌入层中指定的词向量维度,k=1,2,
…
,n,n是输入特征序列个数。在位置编码过程中,采用公式(2)和公式(3)所示的三角函数,来帮助网络理解路径中各级单元的特征在序列中的位置关系。其中pos表示某特征值在序列中的位置,pos=1,2,
…
,max_len,m为该特征值的位置编码序列的维度索引,m=0,1,
…
,dimk/2-1,其中偶数维度处(2m)采取正弦函数(sin)编码,奇数维度处(2m+1)采取余弦函数(cos)编码,位置编码后输出张量的维度也为(samples,max_len,dimk)。即在特征序列pos处的特征值的位置编码序列在2m处的编码值为pe
(pos,2m)
,在2m+1处的编码值为pe
(pos,2m+1)
。对于每个特征序列,都将位置编码的输出张量与输入嵌入后的输出张量相加,得到n个维度为(samples,max_len,dimk)的新张量。例如路径最大级数max_len=21,设置嵌入层中指定的词向量维度dim=16。
[0052][0053][0054]
s42:将步骤s41中n个新张量进行合并,得到一个维度为(samples,max_len,dim)的张量,作为多头自注意力机制的输入x,其中dim=dim1+dim2+
…
+dimn,n是输入特征序列个数。x的第j个行向量为路径中第j级单元在时序和物理信息上的综合特征表达,j=1,2,
…
,max_len。通过三个可训练的矩阵w
iq
、w
ik
、w
iv
,i=1,2,
…
,h,对x分别进行h次线性变换,得到h组词向量维度均为dk=dim/h的矩阵qi、ki、vi,h是自注意力机制的头数,q、k、v分别表示查询(query),地址(key),值(value)。对h组qi、ki、vi并行执行注意力函数,基于点积的注意力机制的计算公式为公式(4)。首先计算qi与ki转置的点积并除以系数d
k1/2
,随后通过柔性最大值传输函数(softmax)运算得到权重矩阵c,最后将权重矩阵c点乘vi得到维度为dk的矩阵zi,即为注意力机制的计算结果attention(qi,ki,vi)。权重矩阵c第a行、第b列的元素可以认为是路径中第a级单元和第b级单元的时序和物理相关性,a=1,2,
…
,max_len;b=1,2,
…
,max_len,矩阵zi行向量的个数与输入x相同,因此zi行向量也有与x类似的单元时序和物理含义。例如设置头数h=2,则经过线性变换后每个词向量的维度dk=8。
[0055]
[0056]
合并h头注意力机制的计算结果headi,i=1,2,
…
,h,并通过一个可训练矩阵wo进行一次线性变换,得到多头自注意力机制的输出multihead(x)。多头自注意力机制的计算公式为公式(5),其中x为多头自注意力机制的输入,w
iq
、w
ik
、w
iv
、wo为可训练的矩阵,i=1,2,
…
,h。
[0057][0058]
s43:将步骤s42中多头自注意力机制的输入x和输出multihead(x)相加,并进行标准化,来避免梯度消失和梯度爆炸,多头自注意力机制标准化层的输出可表示为(6),layernorm()为标准化层的输出函数。
[0059]
layernorm(x+multihead(x))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0060]
s44:将步骤s43中多头自注意力机制标准化后的输出接入全连接前馈神经网络,其相邻两层的神经元间为全连接。首先对输入进行一次线性变换,然后经过线性整流激活函数max(0,s),s为线性整流激活函数的输入,最后再经过一次线性变换。t是全连接前馈神经网络的输入,w1、b1和w2、b2分别是两次线性变换的参数,则全连接前馈神经网络的输出计算公式为公式(7):
[0061]
ffn(t)=max(0,tw1+b1)w2+b2ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
[0062]
s45:将步骤s44中全连接前馈神经网络的输入t和输出ffn(t)相加,并进行标准化,来避免梯度消失和梯度爆炸,连接前馈神经网络标准化层的输出可表示为(8),layernorm()为标准化层的输出函数。
[0063]
layernorm(t+fnn(t))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)
[0064]
s46:将步骤s45中全连接前馈神经网络标准化层的输出接入池化(pooling)层,将三维数据展平为二维数据,并接入全连接(dense)层进行非线性变换,通过丢弃函数(dropout)随机丢弃部分信息,以防止过拟合。随后与经过非线性变换和信息随机丢弃后的布线前路径延时值特征进行数据合并,并将合并后的数据非线性变换至一维,得到布线前后路径延时残差预测值。最后将布线前路径延时值与布线前后路径延时残差预测值相加,得到最终布线后路径延时预测值。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1