一种基于MAGRU的物流仓储需求量预测方法
一种基于magru的物流仓储需求量预测方法
技术领域
1.本发明专利涉及一种仓库商品需求量预测方法,在物流仓库管理领域具有极其重要的应用前景。
背景技术:
2.在物流行业内,仓库精益管理为产品制造、仓库运营提供了重要依据,大大节省了商业成本,而越来越受到业界重视。但不合理的商品储量会严重影响仓库管理效率,浪费运营商成本,降低用户体验,造成资源闲置浪费或货物囤积等现象。一些对保存时限有较高要求的商品,例如食品、药品等都需要较为准确的库存量预测,另一些定制化程度高的商品如一些特殊零件、芯片等需要按需定做,需要提供长时间序列预测。
3.为了解决上述问题,对商品需求量预测问题的研究尤为重要。需求预测以商品信息、历史需求信息作为基本信息,从中挖掘出潜在的需求规律,通过特定的算法找到其周期季节特性,从而提高仓库利用效率,降低仓库管理成本。
4.仓储需求量预测流程如下:(1)明确预测商品的基本信息,如商品类别、商品品牌、在各类销售平台的访问与收藏记录和商品的历史需求信息,例如每月、每周或每日的销售记录等其他信息;(2)通过一种商品的各类信息,包括历史需求数据和自身特征,找到适用于该商品未来需求量进行预测的算法;(3)将商品自身特征与历史需求量综合考虑,用基于统计学方法的对未来值进行预测。
5.目前在对物流需求预测问题的研究大多集中在传统时间序列方法上,关注历史需求数据是需求预测的重点,但仅关注历史需求量间的关系,而较少考虑影响商品的自身特征,这样会忽略掉影响需求量的外部特征,影响预测效果。也有学者使用机器学习方法预测商品需求量,但是对于一些定制化程度高的商品,例如机械零部件、芯片等需要对其提供较长序的预测,传统时间序列方法和机器学习方法都不能满足这一现实需求,在实际应用的能力有局限。本发明在模型捕获长序依赖方面进行了改进,能够捕获由历史需求数据组成序列中的关键序列,同时也考虑到商品自身特征对需求量的影响。在门控循环单元的基础上引入了注意力机制,并重复多次这一过程,极大的提高了预测的准确性。大量的实验证明,本发明对于长序列预测的准确性有较大提升,并且结构简单,适用于现实场景。
技术实现要素:
6.本发明克服了目前仓库商品需求量预测问题中存在的长序预测不准确,复杂预测方法实现代价过高,预测是对节假日、商品自身特征缺乏考虑等缺点,提出了一种基于ma(多层注意力,multi layer attention)-gru(gated recurrent unit,门控循环单元)的物流仓储需求预测方法,为物流仓库中商品的需求量提供可靠预测,节省物流商家运营成本,提升用户体验。
7.本发明主要包括五个部分:(1)确定方法的输入输出(2)对商品历史信息的时间进行节假日编码(3)构建多层注意力门控循环单元编码器(4)构建多层注意力门控循环单元
解码器(5)发明有效性验证。
8.下面分别介绍以上五部分的内容:
9.1、确定方法的输入输出。商品的各类信息包括商品的历史需求信息和商品自身信息,将这些信息作为我们的模型训练数据集。历史需求信息包括商品销售的日期以及销量,这样可以使我们更好的把握商品量与时间的关系,挖掘商品的季节性需求因素、节假日影响因素等。而商品的自身信息包括其品牌信息、品类信息等,这些外源条件的变化也会影响到需求量。商品各类信息组成的矩阵作为本方法的输入,其中包括日期、商品类型、销售平台商品被浏览次数、商品被收藏次数、商品品牌、成交金额、成交件数等属性。方法的输出为商品需求量的预测值,对未来商品需求量进行预测。
10.2、对商品历史信息的时间进行节假日编码。节假日及季节是商品需求预测的重要环节,有的商品其需求量不受节假日影响,而有的商品需求却与节假日密切相关,因此对商品进行节假日编码并加以分析是预测商品需求量的基础。将编码后的信息嵌入商品需求历史数据中,同样作为商品特征加以分析,对提高预测的准确率有重要的作用。
11.3、构建多层注意力门控循环单元编码器。门控循环单元捕获商品需求关系的线性依赖与非线性依赖时,注意力机制可以找到关键变化序列。基于此,本发明提出了将门控循环单元与自注意力相结合并堆叠多层的编码器,具体是指,将一个时间片内的数据作为编码器的输出,首先利用注意力机制求取时间片内各节点的注意力权重,将计算得到权重分配给时间片内各分量,并将各分量作为门控循环单元(以下用缩写gru表示)的输入,编码器输出的结果即为gru隐藏层所组成的向量。
12.4、构建多层注意力门控循环单元解码器。为了进一步提取编码器得到的向量的特征,捕获序列的线性与非线性关系,本发明在解码器阶段同样使用注意力层与gru实现。首先计算编码器输出向量的注意力权重,之后将权重与向量分量相乘并累加,得到的结果作为gru的输入,gru的隐藏层输出即为未来需求量预测结果。
13.5、方法有效性验证。通过在公开的仓库货物需求量数据集上的实验证明,对比其他前沿的研究,本发明对不同长度时间的预测任务,及不同的商品,本发明都能提供更高的预测准确率。
14.本发明为实现上述目的所采取的详细实施步骤如下:
15.步骤1:先确定模型的输入输出,选择合适的训练数据集。模型需要输入仓库运营中采集到的商品需求时序数据。单条数据可表示为表示其中d表示日期,a为商品的各类属性,q是当日商品的需求量。从数据集中采集m个样本大小的数据集{x
(1)
,...,x
(m)
}作为模型的训练样本。
16.步骤2:根据商品需求量的时间信息进行日期嵌入。将每一条商品的日期数据d编码为年、月、周内星期、是否节日4条属性,将4条属性嵌入原始商品数据中,替换原来的日期数据。可以将日期嵌入后的数据定义为这样可以将数据的时间特征加以提取,有效捕获影响需求的日期因素。
17.步骤3:数据集预处理。数据集的组成对本方法的训练过程存在影响,因此,对数据集预处理也是本发明的必要步骤之一。将原始数据集中的异常数据、极端数据删除,并用后续的数据填补,此外还对数据进行归一化,本发明采用最大最小归一化,将数据控制在一定
范围内。
18.步骤4:基于训练数据集,按时间步划分序列并计算序列中各分量注意力权重;首先,根据步骤4.1按照设定的时间步划分数据集,其次根据步骤4.2计算注意力权重。通过对输入序列权重的提取,可以找到影响需求的关键序列,从而给与关键序列更多的注意力,提升预测的准确性。
19.构建编码器的具体步骤如下:
20.步骤4.1:根据时间步划分输入序列。训练数据集可以表示为{x1,x2,...,x
t
},将一个时间步下的序列输入注意力层,计算各分量权重。
21.步骤4.2:根据步骤4.1的一个时间步序列,计算序列中各分量注意力权重。计算注意力的公式为:
[0022][0023]
将权重压缩在[0,1]且各分量权重和为1,计算公式如下:
[0024][0025]
对序列分配权重,使每个分量体现不同的重要性。我们将这一时间片下的向量记录为
[0026][0027]
步骤4.3:根据步骤4.2输出的向量作为gru的输入,通过gru提取这一段时间片序列的特征。首先初始化gru网络隐藏层状态h,其次将x
′
t
作为每个gru单元的输出。通过公式
[0028]rt
=σ(x
twxz
+h
t-1whz
+bz)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0029]zt
=σ(x
twxz
+h
t-1whz
+bz)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
[0030][0031][0032]
对隐藏层h
t
的更新后,记录每一个隐藏层的输出,这些隐藏层输出通过一层全连接神经网络后输出即为编码器的输出。
[0033]
步骤5:构建解码器。将编码器输出的向量进一步特征提取,从而对未来的商品需求量提供更准确的预测。
[0034]
步骤5.1:计算基于编码器输出的各隐藏层状态h在解码器中再一次计算隐藏层状态的注意力。注意力计算公式如下:
[0035][0036]
将初始化解码器状态d,s之后计算编码器输出序列的注意力权重,并通过softmax层使序列中各分量权重和为1。
[0037][0038]
再将权重与序列中的分量相乘求和,得到的结果为驱动向量。
[0039][0040]
步骤5.2:通过gru输出计算预测需求量。一个时间片内最终可以得到一个驱动向量c,训练过程中将c与此时间片后续的真实需求值相拼接,共同作为gru一个单元的输入,从第一个时间片,到训练集划分的最后一个时间片,组成的序列中,每个分量为一个gru的输入,最终输出未来需求量。
[0041]
步骤5.3:输出预测需求量。解码器输出的结果是门控循环单元输出的隐藏层序列,直接作为预测结果表达能力有限,基于此,本发明在解码器之后添加两个全连接层,以实现维度变换,提高模型表达能力的目的。公式中v,w都是需要不断迭代训练的参数。
[0042][0043]
表示预测结果,预测结果可以定义为一个向量,其大小与预测任务长度一致。预测未来τ天的需求量则向量大小为τ。
[0044][0045]
本发明提出了一种基于magru的物流仓储需求预测方法,该方法利用深度学习技术,结合注意力机制,并使用编码器-解码器结构,在编码器和解码器阶段重复注意力的过程,提高了对长序依赖关系的捕获能力,充分考虑了各类外部特征和时间特征对商品需求量的影响,提高模型准确率。除此之外,模型最小化仓库运营成本。通过大量的实验证明,无论是对长时序预测任务的准确率,还是对不同分布规律商品预测的泛化性,本发明相对于先前研究都有一个较大的提升,能够应用于中小型物流企业中。
附图说明
[0046]
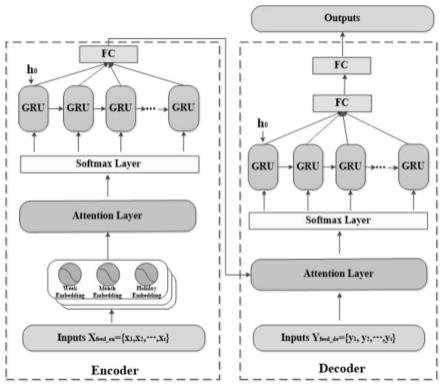
图1是本发明中多层注意力循环门控单元模型图
[0047]
图2是本发明中编码器阶段注意力计算过程
[0048]
图3是本发明中解码器阶段预测计算过程
[0049]
图4是本发明中某商品具体需求量和变化趋势图
[0050]
图5是本发明中对某商品预测效果折线图
[0051]
图6是本发明与循环神经网络关于预测准确率对比图
[0052]
图7是本发明与极端梯度增强算法关于预测准确率对比图
[0053]
图8是本发明与双阶段注意的循环神经网络关于预测准确率对比图
[0054]
图9是本发明与删除发明中部分组件对预测准确率对比图
具体实施方式
[0055]
下面结合附图和实施例对本发明进一步说明。
[0056]
本发明针对仓库货品需求量预测准确性不足进行预测建模。提出基于ma-gru的物流仓储商品需求量预测方法,该方法适用于仓库管理中采集到的任意商品时序数据。本发明在jupyter notebook环境中通过python语言构建模型来实现,下面结合实例对本发明的实现进行详细说明。
[0057]
图1是本发明网络模型架构图,图中的共有2层注意力机制,2层gru网络,数据
其中d是表示日期的数字字符串,q是商品每日需求量,而a是影响商品需求量的客户端商品被访问次数、商品被收藏次数、商品页流量和商品价格等特征。首先进行时间特征提取,并作为特征嵌入原始数据中将数据组织成y表示年份、m表示月份、w表示周几、h表示是否节假日。其次通过一个注意力机制,为输入的序列每日分配一个权重,再次将已近具有不同权重的x组成一个向量,向量的每个分量作为gru网络各单元的输入,之后将gru网络的隐藏层输出再次通过一层注意力,获取其权重,将这些权重与gru的隐层乘积累加,得到驱动向量,最后将驱动向量与训练数据集中的序列真实需求量相结合,再通过一个gru网络层得出预测需求量。
[0058]
本发明重点关注在已经构建的ma-gru网络上对仓库商品未来需求量进行预测场景,给定合适的数据集,通过注意力机制和神经网络构建网络模型,进行网络参数化,之后通过训练和优化参数,从而在所设定的恰当的训练次数内,在实现网络性能最优的基础上,最小化网络的损失值和指标值。
[0059]
ma-gru的框架如图1所示,本发明采用某商品真实日需求量数据,具体实施如下:
[0060]
步骤1:先确定模型的输入输出,选择合适的训练数据集。模型需要输入仓库运营中采集到的商品需求时序数据。单条数据可表示为表示其中d表示日期,a表示商品属性,q则为商品需求量从训练集中采集m个样本大小的数据集{x
(1)
,...,x
(m)
}作为模型的训练样本。
[0061]
之后转入步骤2。
[0062]
步骤2:根据商品需求量的时间信息进行日期嵌入。将每一条商品的日期数据d编码为年、月、周内星期、是否节日4条属性,将4条属性嵌入原始商品数据中,替换原来的日期数据。可以将日期嵌入后的数据定义为这样可以将数据的时间特征加以提取,有效捕获影响需求的日期因素。之后转入步骤3。
[0063]
步骤3:数据集预处理。首先对输入的训练数据集进行归一化处理,归一化方法使用最大最小归一化,将训练数据线性转换到[0,1]的范围,归一化公式为:
[0064][0065]
其中x
max
表示训练数据集中的最大值,x
min
表示训练数据集的最小值。将归一化后的数据集作为最终的训练数据集。之后转入步骤4。
[0066]
步骤4:基于步骤3所得到训练数据集,按时间步划分序列并计算序列中各分量注意力权重;首先,根据步骤4.1按照设定的时间步划分数据集,其次根据步骤4.2计算注意力权重,之后根据步骤4.3计算隐藏层。之后转入步骤5;
[0067]
构建编码器的具体步骤如下:
[0068]
步骤4.1:根据时间步划分输入序列。训练数据集可以表示为{x
(1)
,...,x
(m)
},共有m条每日需求数据,时间步可以根据现实需求调整,本发明以7天历史需求量为例,则一个时间片内数据为{x1,x2,...,x7}将一个时间步下的序列输入注意力层,计算各分量权重。
[0069]
步骤4.2:根据步骤4.1的一个时间步序列,计算序列中各分量注意力权重。计算注意力的公式为:
[0070]
[0071]
之后通过softmax将权重压缩在[0,1]且各分量权重和为1,计算公式如下:
[0072][0073]
对序列分配权重,使每个分量体现不同的重要性。我们将这一时间片下的向量记录为
[0074]
步骤4.3:根据步骤4.2输出的向量作为gru的输入,通过gru提取这一段时间片序列的特征。首先初始化gru网络隐藏层状态h,其次将x
′
t
作为每个gru单元的输出。通过公式
[0075]rt
=σ(x
twxz
+h
t-1whz
+bz)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(16)
[0076]zt
=σ(x
twxz
+h
t-1whz
+bz)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(17)
[0077][0078][0079]
对隐藏层h
t
的更新后,记录每一个隐藏层的输出,这些隐藏层输出通过一层全连接神经网络后输出即为编码器的输出。
[0080]
之后转入步骤5;
[0081]
步骤5:构建解码器。将编码器输出的向量进一步特征提取,从而对未来的商品需求量提供更准确的预测。
[0082]
步骤5.1:计算基于编码器输出的各隐藏层状态h在解码器中再一次计算隐藏层状态的注意力。注意力计算公式如下:
[0083][0084]
首先要将初始化解码器状态d,s之后计算编码器输出序列的注意力权重,并通过softmax层使序列中各分量权重和为1,
[0085][0086]
再将权重与序列中的分量相乘求和,得到的结果为驱动向量。之后进入步骤5.2
[0087][0088]
步骤5.2:通过gru输出计算预测需求量。一个时间片内最终可以得到一个驱动向量c,训练过程中将c与此时间片后续的真实需求值相拼接,共同作为gru一个单元的输入,从第一个时间片,到训练集划分的最后一个时间片,组成的序列中,每个分量为一个gru的输入,最终输出未来需求量。之后进入步骤5.3
[0089]
步骤5.3:输出预测需求量。为了增强本发明的模型表达能力,我们基于5.2的输出在后续增加两个全连接层,通过全连接层后输出预测目标。
[0090][0091]
输出的结果是一个向量,根据预测任务不同向量长度不同,例如预测后续1天该商品的需求量,则y为长度为1的向量,预测未来t天的需求量可以表示为
[0092][0093]
本发明对于t值较大时的预测任务,仍能给出较为准确的预测。
[0094]
根据本方法训练获得预测数据集,将预测数据集与测试数据集进行比较,计算预测数据的mae和rmse指标值经过对比实验得到最终的生成数据,计算生成数据的指标公式如下:
[0095][0096][0097]
其中,yi即为真实测试数据集需求量,即为预测的未来需求量,n为测试数据集的大小。
[0098]
在同一训练数据集下,通过mae、rmse这两项指标说明本发明的性能,对比其他已有的方法对本发明性能进行评价。利用折线图来展现结果如图所示。
[0099]
图5是本发明中对某商品预测效果折线图。从图中可以看出,本发明能较好拟合商品未来需求量的变化趋势,对未来需求量能给出较准确的预测。
[0100]
图6是本发明与循环神经网络关于预测准确率对比图。循环神经网络作为一种时间序列模型,广泛应用于各类预测问题,图6的横轴表示预测时间,纵轴表示某商品的需求量,从图示中可以看出我们的方法更贴近真实需求量曲线,且对长序列的预测也同样能给出较准确的预测。
[0101]
图7是本发明与极端梯度增强(xgboost)算法关于预测准确率对比图。xgboost作为一种统计学方法,对未来需求量的预测准确性有限,仅能对给出需求量的总统变化规律,对波动趋势预测性能较差。
[0102]
图8是本发明与双阶段注意的循环神经网络(da-rnn)关于预测准确率对比图。da-rn想较于本发明,对长序预测的性能有限,且对未来每日的需求量与真实需求量的差异要大于本发明。本发明的实验结果经验证比较,mae、rmse比da-rnn模型减小了13.47%,和14.90%。
[0103]
图9是本发明与删除发明中部分组件对预测准确率对比图。由于本发明由各个组件构成,因此,对各个组件的必要性进行了评估,通过省略编码器和解码器步骤中计算注意力权重的模块,进行比对mae的值,本发明能够提供更高的准确性。本发明的各个步骤均不可省略。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1