医疗数据的联邦学习系统、方法、存储介质及程序产品与流程
本发明的实施方式涉及医疗数据的联邦学习系统、方法、存储介质及程序产品。
背景技术:
1、联邦学习(federated learning)也称为“联合学习”、“分散式学习”等,是机器学习的方法之一,是一种带有隐私保护、安全加密技术的分布式机器学习方法。在联邦学习中,分散在各站点(site)的数据在不向其他站点泄露的前提下协作进行ai模型的训练(training)。
2、在医疗健康领域,各站点可以根据各自的任务需求,从中心服务器(centerserver)下载要进行机器学习的模型,在数据不出站点的情况下,完成该模型的本地训练,并将该模型对于本地数据的性能表现上传至中心服务器。这里的站点例如是医院、诊所、研究机构等具有医疗数据的机构,这里的模型例如包括在医用图像处理过程中使用的“肺分割模型”、“肝分割模型”、“肺结节检测模型”等,这些模型用于对医疗数据进行识别、分割、检测、分类等预先规定的处理。而且,模型可以分为存储于中心服务器的全局模型(globalmodel)以及存储于各站点的本地模型(local model)两种。全局模型有时也称为“共通模型”、“联邦模型”等。
3、此外,各站点也可以发起针对某个全局模型的联邦学习的请求,通过综合其他站点的数据共同训练该全局模型,能够提高该全局模型的泛化能力。另一方面,在联邦学习中,由于各站点的自身数据集的规模、样本多样化和标注(annotation)质量的水平等因素不同,各站点对全局模型产生的贡献也不同,在联邦学习中各站点所占的权重也不同。因此,在联邦学习中,准确地评估各站点的权重也是提高该全局模型的泛化能力的重要因素。
4、但是,在参与联邦学习的各站点数据无法直接共享的情况下,难以准确地评估各站点的权重。在现有技术中,作为确定联邦学习中的各站点的权重的方法,已知有平均加权法、联邦机会计算(focus,federated opportunistic computing for ubiquitoussystems)法等。平均加权法是将各站点的权重设为均等的方法,该方法中没有对各站点的权重进行评估。联邦机会计算法是将本地模型在服务器基准数据集上的性能和全局模型在本地数据集上的性能之间的交叉熵作为权重。
5、在通过上述联邦机会计算法来计算各站点的权重时,计算结果比较依赖存储于中心服务器侧的基准数据集的分布,但不能够充分考虑到本地模型对于本地数据的训练结果这一因素对于全局模型的贡献。在该中心服务器侧的基准数据集分布没能包含某个站点的本地数据集分布的情况下,或者在基准数据集和站点数据集之间的差异较大的情况下,该联邦机会计算法可能会得出该站点侧的数据集质量的可信度较差的错误结论,并错误地降低该站点的权重。这样的情况不利于提高全局模型的泛化能力。
6、例如,假设中心服务器侧的基准数据集中仅包含了常见病例的数据,而站点1中的本地数据集中不仅包含了常见病例的数据,还包含了一些罕见病例(例如肝病的罕见病例、肺病的罕见病例等)的数据的情况。该情况下,当中心服务器和站点1分别针对肝分割模型进行联邦学习时,本地模型在服务器基准数据集上的性能与全局模型在本地数据集上的性能之间差异较大,可能会导致本地模型在服务器基准数据集上的性能和全局模型在本地数据集上的性能之间的交叉熵小,因此会得出站点1的数据集质量的可信度较差的错误结论。此时,尽管站点1的数据集包含了有利于全局模型泛化的罕见病例的数据且数据质量的可信度高,但现有的联邦机会计算法却不能够正确地评估该站点1对全局模型的贡献。
技术实现思路
1、鉴于现有技术中存在的问题,本发明提供一种能够更加准确地调整联邦学习中的各站点的权重的医疗数据的联邦学习系统、方法、存储介质及程序产品。
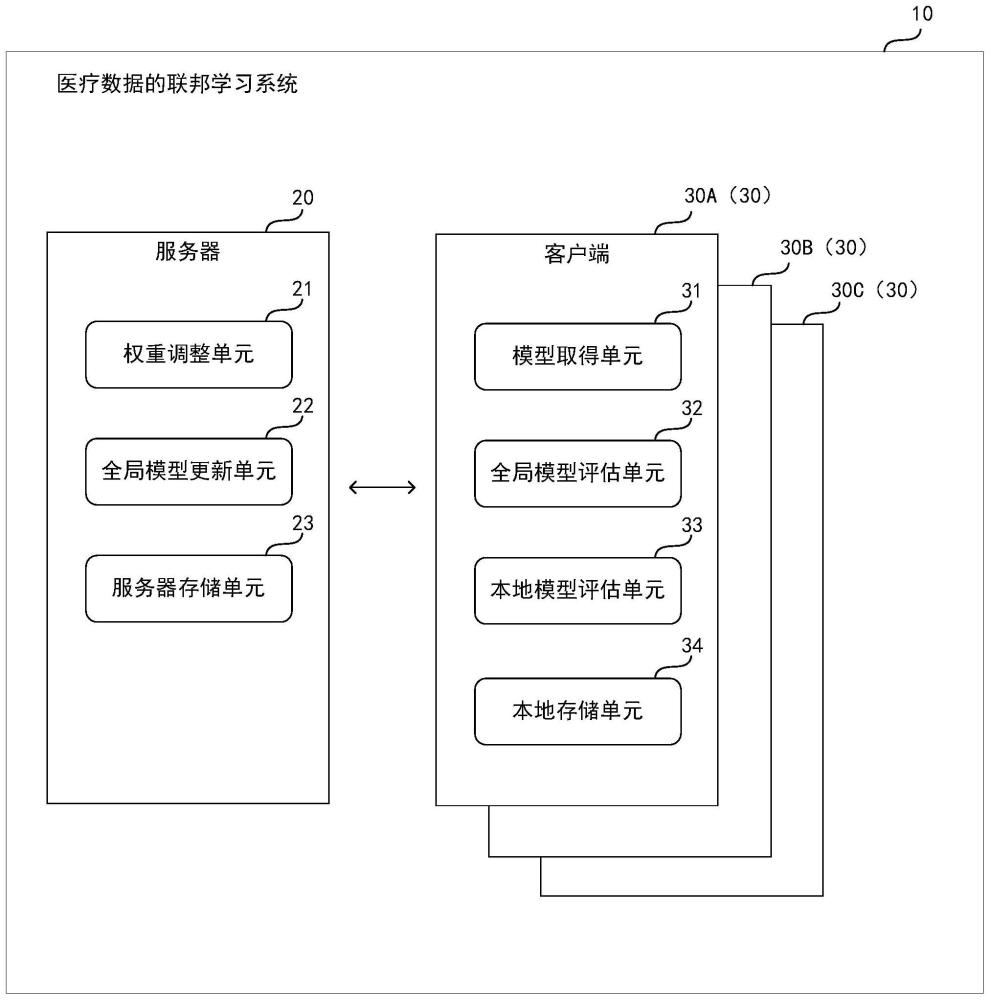
2、本发明的医疗数据的联邦学习系统(10),包括服务器(20)和多个客户端(30),所述服务器存储有多个全局模型,各所述客户端存储有一个以上的本地模型,其特征在于,所述客户端具有:模型取得单元(31),从所述服务器取得对象全局模型,所述对象全局模型是所述多个全局模型中的成为联邦学习的对象的全局模型;全局模型评估单元(32),使用所述对象全局模型以及该客户端的本地训练数据进行训练,使用本地评估数据对训练后的对象全局模型进行评估而得到全局模型评估结果,将所述全局模型评估结果发送至所述服务器;以及本地模型评估单元(33),使用所述本地评估数据对存储于所述客户端的对象本地模型进行评估而得到本地模型评估结果,将所述本地模型评估结果发送至所述服务器,所述对象本地模型是所述一个以上的本地模型中的与所述对象全局模型相同种类的本地模型;所述服务器具有:权重调整单元(21),根据从各所述客户端接收的所述全局模型评估结果和所述本地模型评估结果,调整各所述客户端的权重。
3、在所述医疗数据的联邦学习系统中,所述权重调整单元在从所述客户端接收的所述全局模型评估结果比所述本地模型评估结果差的情况下,增加该客户端的权重,所述权重调整单元在从所述客户端接收的所述全局模型评估结果不比所述本地模型评估结果差的情况下,将该客户端的权重维持不变。
4、在所述医疗数据的联邦学习系统中,所述权重调整单元每m轮次进行所述全局模型评估结果与所述本地模型评估结果的比较,比较的范围是当前轮次的全局模型评估结果和本地模型评估结果,或者比较的范围是当前轮次之前连续n轮的全局模型评估结果和本地模型评估结果,其中m≥2,n≥2,m≥n。
5、在所述医疗数据的联邦学习系统中,所述全局模型评估结果包括训练轮数、auc值、acc值、dice值中的一个以上。
6、在所述医疗数据的联邦学习系统中,所述模型取得单元(31)使用从所述服务器取得的全局模型以及该客户端的本地训练数据进行多次训练,将经过多次训练后的所述全局模型作为本地模型。
7、在所述医疗数据的联邦学习系统中,所述服务器还具有:全局模型更新单元(22),使用各所述客户端的调整后的权重以及从各所述客户端接收的所述对象全局模型的训练结果,更新所述对象全局模型的参数。
8、在所述医疗数据的联邦学习系统中,所述本地模型评估单元(33)向所述服务器发送所述客户端的本地标注信息,所述服务器还具有:数据质量评价单元(29),根据所述本地标注信息与所述服务器所具有的基准标注信息之间的匹配程度,决定是否允许所述本地标注信息所对应的所述客户端加入所述联邦学习。
9、在所述医疗数据的联邦学习系统中,所述本地标注信息以及所述基准标注信息包括灰度特征、纹理特征、几何特征中的一个以上。
10、在所述医疗数据的联邦学习系统中,所述模型取得单元(31)将从所述服务器取得的全局模型作为本地模型,所述权重调整单元(21)根据规定轮次以后从各所述客户端接收的所述全局模型评估结果和所述本地模型评估结果,调整各所述客户端的权重。
11、本发明的在医疗数据的联邦学习系统中使用的医疗数据的联邦学习方法,该联邦学习系统包括服务器和多个客户端,所述服务器存储有多个全局模型,各所述客户端存储有一个以上的本地模型,其特征在于,所述联邦学习方法包括:模型取得步骤(s11),从所述服务器取得对象全局模型,所述对象全局模型是所述多个全局模型中的成为联邦学习的对象的全局模型;全局模型评估步骤(s12),使用所述对象全局模型以及该客户端的本地训练数据进行训练,使用本地评估数据对训练后的对象全局模型进行评估而得到全局模型评估结果,将所述全局模型评估结果发送至所述服务器;本地模型评估步骤(s13),使用所述本地评估数据对存储于所述客户端的对象本地模型进行评估而得到本地模型评估结果,将所述本地模型评估结果发送至所述服务器,所述对象本地模型是所述一个以上的本地模型中的与所述对象全局模型相同种类的本地模型;权重调整步骤(s14),根据从各所述客户端接收的所述全局模型评估结果和所述本地模型评估结果,调整各所述客户端的权重。
12、本发明的计算机可读存储介质,其上存储有计算机程序,其特征在于,该计算机程序被处理器执行时实现所述医疗数据的联邦学习方法的步骤。
13、本发明的计算机程序产品,包括计算机程序,其特征在于,该计算机程序被处理器执行时实现所述医疗数据的联邦学习方法的步骤。
14、发明效果
15、根据上述构成的医疗数据的联邦学习系统、方法、存储介质及程序产品,通过综合考虑本地模型对各客户端的本地数据的性能表现(performance)以及全局模型对各客户端的本地数据的性能表现,即使服务器侧的基准数据集和客户端侧的本地数据集之间差异较大的情况下,也能够正确地评估并调整联邦学习中的各客户端的权重,从而能够更准确地提高全局模型的泛化能力。
16、此外,根据各客户端的本地标注信息与服务器的基准标注信息之间的匹配程度能够判断本地训练数据的质量以及标注质量的好坏,进而能够剔除本地训练数据的质量差或标注质量差的客户端参加联邦学习。因此,减少了本地训练数据的质量差或标注质量差的客户端对联邦学习的不良影响,提高了质量好的数据在联邦学习中的利用率。
- 还没有人留言评论。精彩留言会获得点赞!