基于联邦学习和相似度密文计算的个性化项目推荐方法
1.本发明的技术领域是研究具有隐私保护的推荐机制,更具体地说,本发明是一种基于联邦学习基于相似度密文计算及联邦学习的高效个性化项目推荐方法,其中,项目包括电影、音乐、图书、商品。
背景技术:
2.随着大数据的兴起,信息过载使人们获得更多无用的信息。于是,推荐系统逐渐流行起来。推荐系统的目的是为用户提供个性化的在线产品或服务推荐,推荐系统已成为解决信息过载问题的重要途径,为教育、医疗和其他行业带来了机遇和挑战。
3.然而,推荐系统给人们带来便利的同时,当前的推荐系统存在许多潜在风险,其中隐私披露是首要问题之一。一般来说,推荐系统由两部分组成:推荐服务器和用户。为了得到一个更好的推荐模型,传统的推荐系统使用一个中央架构,通常会收集大量的反馈信息,比如用户偏好。但这些信息往往对用户敏感,并可能导致严重的隐私和安全风险:用户的原始数据可能会从某些程序的反馈信息中泄露出来。例如,推荐系统在一定条件下,只须取得用户观看电影的纪录,便可推断出一些隐私信息(例如年龄、收入、病历等)。此外,推荐系统亦可收集使用者的个人资料,并与第三者分享,以获取利润。一旦这些信息被滥用,后果不堪设想。因此,人们越来越关心他们的数据隐私,他们希望他们的私人信息不会被互联网应用程序知道。在现有的研究中,有很多方法来保护数据隐私,如匿名、差分隐私、同态加密和联邦学习。联合学习是一个流行的工具,以减少隐私风险。因此,联邦学习越来越受到重视。2021年,zhou等人在文献《a privacy-preserving distributed contextual federated online learning framework with big data support in social recommender systems》中提出了一种基于联邦学习的框架推荐方案。该方案定义了多个协同推荐代理,使用联邦学习框架保护用户的数据隐私,提高推荐项目的可靠性。然而,在该方案的系统模型中,云的设置是完全可信的,这在实际实践中很难实现,而且所有的记录都以明文形式存储在云中,因此仍然存在隐私泄露的风险。
4.在其他方面,为了获得更好的推荐结果,经常引入相似度的概念。一般来说,为了保证推荐项目的准确性,许多推荐系统需要计算两个参数。一个是用户需求与推荐项目属性的相似性,另一个是用户对推荐项目的评价。对于前者,较高的相似性意味着项目将更适合用户的需要。对于后者,这意味着项目将具有更高的推荐优先级。在收到推荐项目后,用户将评估推荐项目,即提交反馈分数。推荐系统会收集这些分数,并根据评估结果计算推荐代理人的可靠程度。显然,在目前的推荐系统下,保护用户的隐私至关重要。当用户提交需求或估计时,他们希望自己的信息受到保护。这是因为用户的需求和评价通常与信息的隐私有关。为了解决这些问题,提出了一些可行的解决方案。2021年,zhang等人在文献《a privacy-preserving optimization of neighborhood-based recommendation for medical-aided diagnosis and treatment》中提出在推荐过程中使用bgn密码体制保护用户隐私,利用同态性质计算密文域中两个用户之间的相似度。然而,该方案使用了双线性对
的计算,给用户带来了沉重的计算负担。
技术实现要素:
5.本发明的目的是为了解决现有技术中的上述缺陷,提供一种基于相似度密文计算及联邦学习的个性化项目推荐方法。本发明首先设计了一个基于正交矩阵的相似度密文计算算法,在此基础上,设计了一种基于相似度密文计算及联邦学习的高效个性化项目推荐方法,实现了高效的具有保护数据隐私的个性化推荐项目功能,其中项目包括电影、音乐、图书、商品。
6.本发明的目的可以通过采取如下技术方案达到:
7.一种基于联邦学习和相似度密文计算的个性化推荐项目方法,所述项目包括电影、音乐、图书、商品,所述项目推荐方法包括以下步骤:
8.s1、系统初始化:可信中心ta为推荐代理ageni,用户u
i,j
和云服务器生成并分发密钥,其中,假设一共有n个推荐代理,每个推荐代理都有m个用户和n个项目,第i个推荐代理表示为ageni,推荐代理ageni的第j个用户表示为u
i,j
,并且满足1≤i≤n,1≤j≤m;推荐代理ageni的第i
′
个项目表示为i
i,i
′
,并且满足1≤i≤n,1≤i
′
≤n;可信中心ta首先运行密钥生成算法somc.keygen(p),其中p为矩阵维度,得到实现加密功能的第一密钥ka,第二密钥k
s,1
,k
s,2
,...,k
s,n
,第三密钥k1,k2,...,kn,第四密钥l和第五密钥j1,j2,...,jn;随后可信中心ta将ka,ki,k
s,i
发送给对应的推荐代理ageni;将k
s,1
,k
s,2
,...,k
s,n
和l发送给云服务器;将密钥ji发送给对应的用户u
i,1
,u
i,2
,...,u
i,m
;可信中心ta给推荐代理agen1,agen2,...,agenn生成身份标识id1,id2,...,idn;给每一个项目i
i,i
′
生成对应的身份标识iid
i,i
′
;可信中心ta将推荐代理agen1,agen2,...,agenn的可靠度分值res1,res2,...,resn初始化为0,以及res1,res2,...,resn的更新次数count1,count2,...,countn初始化为0;
9.s2、数据加密:每一个项目i
i,i
′
的属性信息用p维向量表示,其中b
ii
′
,1
,b
ii
′
,2
,...,b
ii
′
,p
表示项目i
i,i
′
的第1,2,...,p个属性值,符号
“”
表示转置运算;每一个推荐代理ageni运行加密算法输出加密结果上传保存在云服务器中;
10.s3、项目推荐:每一个用户u
i,j
的需求信息用p维向量表示,其中a
ij,1
,a
ij,2
,...,a
ij,p
表示用户u
i,j
需求的第1,2,...,p个属性值,用户u
i,j
运行加密算法输出加密结果之后用户u
i,j
往输出结果中加入噪声得到随后,用户u
i,j
将加密加噪的需求向量发给推荐代理ageni,通过推荐代理ageni和云服务器交互,执行项目推荐算法wi,得到被推荐的项目i
opt
和对应的身份标识iid
opt
发送给用户u
i,j
,其中是用户u
i,j
的加密加噪需求向量,是推荐代理ageni的项目属性密文数据集,wi是推荐代理ageni的推荐权值矩阵,{resi,i=1,2,...,n}是每一个推荐代理的可靠度分值数据集,l是云服务器私钥,是实现选择推荐代理的第一、第二门限值;
11.s4、更新可靠度分值:每一个用户u
i,j
收到推荐结果之后,生成评分矩阵r
i,j
,用户u
i,j
往评分矩阵r
i,j
中加入噪声得到并生成评分标识向量并运行加密算法得到加密加噪评分矩阵r
′
i,j
,计算其中符号“·”表示乘法运算;随后,用户u
i,j
将发给推荐代理ageni;通过推荐代理ageni和云服务器交互,执行更新可靠度分值算法更新推荐代理ageni的可靠度分值,其中是推荐代理ageni收到的所有加密反馈,fi是给推荐代理ageni发过反馈的用户集合,resi是推荐代理ageni的可靠度分值,counti是推荐代理ageni的可靠度分值resi的更新次数。
12.进一步地,所述步骤s1中密钥算法somc.keygen(p)中,输入矩阵维度p,可信中心ta随机生成n+2个p
×
p正交矩阵,记为ka,l,k
s,1
,k
s,2
,...,k
s,n
,然后根据以下公式生成k1,k2,...,kn和j1,j2,...,jn:ki=ka·ks,i
,i=1,2,...,n;ji=ki·
l,i=1,2,...,n。用正交矩阵作为密钥,可以在一次运算中同时处理多个明文,同时,正交矩阵具有以下特性:假设矩阵p为正交矩阵,则满足其中,e表示为单位矩阵,符号
“”
表示转置运算,符号
“‑
1”表示矩阵求逆运算,即正交矩阵的逆矩阵即为正交矩阵的转置。
13.进一步地,所述步骤s2中加密算法somc.enc(sk,m)中,输入私钥sk,明文m,其中私钥sk为ki或ji;明文m是p
×
p矩阵或p维向量,计算其中,符号
“”
表示转置运算,输出密文c
sk
。在加密方法中,具有加法同态加密的性质,同时解密只需求出密钥矩阵的逆矩阵即可,正交矩阵的特性使得在拥有密钥的情况下,解密更加便捷,但若不知道密钥矩阵的情况下,求出逆矩阵又是十分困难的,保证了数据的安全。
14.进一步地,所述步骤s3中往加密算法的输出结果加入噪声得到其中
[0015][0015][0016]a′
ij,1
,a
′
ij,2
,...,a
′
ij,p
表示a
ij,1
,a
ij,2
,...,a
ij,p
加密的结果,用户u
i,j
在a
′
ij,1
,a
′
ij,2
,...,a
′
ij,p
中选取个元素组成集合sub,其中,p表示向量的维度;符号表示向上取整运算;随后,用户u
i,j
计算加入噪声后结果:
[0017][0018]
其中,a
″
ij,1
,a
″
ij,2
,...,a
″
ij,p
表示a
′
ij,1
,a
′
ij,2
,...,a
′
ij,p
加入噪声之后的结果,lap(
·
)表示为拉普拉斯函数,b表示为拉普拉斯参数。在本步骤中,在加密结果中加入噪声,更进一步地保护隐私,在不加噪声的情况下,假设敌手(推荐代理或云服务器)拥有了加密的矩阵密钥,因为用户选择加噪元素的随机性以及拉普拉斯函数的特性,使得敌手也没有办法获得敏感信息同时不会影响后期相似度的计算。
[0019]
进一步地,所述步骤s3中项目推荐算法
[0020][0021]
实现过程如下:
[0022]
s31、当推荐代理ageni收到了用户u
i,j
的加密需求后,根据以下公式计算加密推荐权值矩阵结果w
′i:w
′i=somc.enc(ki,wi),其中,ki为推荐代理ageni的私钥,wi为对角矩阵,记为wi=diag(w
i,1
,w
i,2
,...,w
i,p
),其中w
i,1
,w
i,2
,...,w
i,p
为权值参数且表示推荐项目属性向量中对应属性的影响因子,随后,推荐代理ageni将发送给云服务器并请求协作推荐;在本步骤中,推荐代理ageni将自己的推荐权值矩阵进行加密,是为了防止云服务器得到推荐权值矩阵中详细的参数信息,达到只让云服务器使用但不让云服务器知道详情的目的;
[0023]
s32、云服务器收到推荐代理ageni发送的后,判断推荐代理ageni的可靠度分值是否满足门限值r,即:resi>r,如果满足,云服务器则会发起联邦协作推荐并执行步骤s33,如果不满足,云服务器则只使用推荐代理ageni的推荐权值矩阵独自推荐,令w
′
rec
=w
′i,其中w
′
rec
为计算推荐结果的推荐权值矩阵密文形式,执行步骤s34;在本步骤中,云服务器需要判断推荐代理ageni是否有资格来进行独自推荐,如果可靠度分值超过了门限值r则说明推荐代理以往的推荐都得到了用户较高的评价,因此说明推荐代理能够有资格进行独自推荐,即只使用推荐代理ageni的推荐权值矩阵;反之云服务器则判断认为推荐代理ageni没有独自推荐的资格,需要其他的推荐代理的一起联邦推荐才能生成更让用户满意的推荐项目使推荐项目更具可信度使用户更满意;
[0024]
s33、云服务器首先将所有的可靠度分值{resi,i=1,2,...,n)进行降序排序,选择可靠度分值前j个的推荐代理组成集合aci,并且满足门限条件:其中res
(max-z)
表示排序之后的第z个可靠度分值,resq表示为推荐代理agenq的可靠度分值;云服务器选取达到要求的推荐代理:可靠度分值总和占比达到了全部推荐代理的可靠度分值的一定门限值比例则认为联邦推荐产生的推荐结果才具有可信度,随后,云服务器为每个被选中的推荐代理agenk∈aci计算伪随机身份标识pidk:pidk=h(idk||rk),其中idk为推荐代理agenk的身份标识,rk为随机数,定义h:{0,1}
*
→
{0,1}
λ
为将任意长度的字符串映射为长度λ为的字符串的哈希函数,其中{0,1}
*
表示任意长度的字符串,{0,1}
λ
表示长度为λ的字符串;云服务器要用伪随机身份标识pidk来收集各个被选推荐代理的加密推荐矩阵,以便查验有没有个别推荐代理没有按要求提交,同时,如果中途被恶意用户截获信息,只有伪随机身份标识pidk并不能和推荐代理对应,随后,云服务器将pidk发给对应的推荐代理agenk∈aci,并且发送推荐请求。推荐代理agenk∈aci收到之后,计算加密推荐权值矩阵结果:w
′k=somc.enc(kk,wk),其中,wk表示推荐代理agenk的推荐权值矩阵,kk为推荐代理agenk的私钥;随后,推荐代理agenk∈aci发送pidk,w
′k给云服务器;云服务器在收集齐所有的pidk,w
′k(agenk∈aci)之后,代理重加密每一个推荐代理agenk∈aci的加密推荐矩阵w
′k(agenk∈aci)得到结果w
′
aggr,k
(agenk∈aci):
[0025][0026]
其中k
s,i
为云服务器和ageni共享密钥,k
s,k
为云服务器和agenk共享密钥,kk为推荐代理agenk的私钥,ka为所有推荐代理的共享密钥,代理重加密的主要目的是为了能够使加密的密文进行归一化,方便之后进行聚合,因为之前密钥的设置,推荐代理的密钥则分为推荐代理之间共享密钥与推荐代理和云服务器共享密钥的乘积,即ki=ka·ks,i
,i=1,2,...,n;同时,用户的密钥为推荐代理的密钥和云服务器的密钥乘积,即ji=ki·
l,i=1,2,...,n,所以云服务器拥有密钥k
s,1
,k
s,2
,...,k
s,n
,只需要知道k1,k2,...,kn中的任意某一个,通过公式ki=ka·ks,i
,i=1,2,...,n即能实现密钥的转换,随后,云服务器计算聚合权值矩阵w
′
fed
:
[0027][0028]
其中,resk表示为推荐代理agenk的可靠度分值,实则是进行加权求和,被选中的推荐代理中哪一个推荐代理的可靠度分值越高,占比就越高,因为可靠度分值越高说明其之前的推荐结果得到用户更高的反馈评价,令得到:其中w
′
fed
表示为w
fed
的加密结果,最后令w
′
rec
=w
′
fed
,其中w
′
rec
为计算推荐结果的推荐权值矩阵密文形式;
[0029]
s34、云服务器找到推荐代理ageni的项目属性密文数据集后,计算:
[0030][0031]
其中为用户u
i,j
加密的需求向量,w
′
rec
为计算推荐结果的推荐权值矩阵密文形式,符号
“”
表示转置运算;随后云服务器运行算法得到相似度集合其中定义“|
·
|
2”为向量模长的平方运算,
“‑”
为向量相减运算,随后,云服务器选取相似度最小的物品最后输出推荐项目及其身份标识号:i
opt
,iid
opt
,云服务器将i
opt
,iid
opt
发给推荐代理ageni,推荐代理ageni转发给用户u
i,j
。在本步骤中,相似度为用户需求和项目的相似程度,用户需求向量和项目的属性矩阵进行每一项相减,随后求平方和,数值越小,说明两者越接近,说明两者匹配程度越高,
[0032]
进一步地,所述步骤s34中密文计算算法somc.eval(l,ck,cj),输入私钥l,密文ck和cj,其中密文ck=somc.enc(ki,mk),cj=somc.enc(ji,mj),
[0033]
和为p维向量,其中m
k,1
,m
k,2
,...,m
k,p
为向量mk中p个元素且都为实数,m
j,1
,m
j,2
,...,m
j,p
为向量mj中p个元素且都为实数,计算mk和mj的相似度sim
k,j
:
[0034][0035]
输出相似度sim
k,j
。在步骤中,因为在计算过程中,都是密文的形式下进行,所以不会暴露用户的敏感信息或者推荐代理的参数信息,保护了用户和推荐代理的数据隐私。
[0036]
进一步地,所述步骤s4中往评分矩阵r
i,j
中加入噪声得到中,其中r
i,j
为对角矩阵,记为其中r
i,1
,r
i,2
,...,r
i,p
为关于推荐项目的第1,2,...,p维度的评分分值,用户u
i,j
在中选取个元素组成集合rsub
i,j
,其中,p表示向量的维度;符号表示向上取整运算;随后,用户u
i,j
计算加入噪声后结果:
[0037]
其中r
′
j,1
,r
′
j,2
,...,r
′
j,p
表示为加噪处理后的结果,随后计算评分标识向量
[0038][0039]
其中,r
0,1
,r
0,2
,...,r
0,p
表示评分标识向量中的p个元素且取值为1或0;
[0040]
最后得到真实评分向量其中
[0041][0042]r″
j,1
,r
″
j,2
,...,r
″
j,p
表示真实评分向量中的p个元素且都为实数。在步骤中,云服务器只被允许知道用户评分的总和,但是不能具体每一项的分值,推荐代理则不被允许知道用户评分的总和以及具体每一项的分值,所以本发明设计了一个标识向量,标记在评分矩阵中,哪一个元素是噪声,哪一个元素是真正的评分,评分矩阵为对角矩阵,在和标识向量相乘后,只有真实的评分会保留下来,但是标识向量在发送之前被用户u
i,j
乘上了自己私钥ji,需要推荐代理ageni利用自己私钥ki进行半解密,之后,云服务器才能利用密钥l解开,所以推荐代理ageni无法得到标识向量解密结果。
[0043]
进一步地,所述步骤s4中更新可靠度分值算法的实现过程如下:
[0044]
s41、推荐代理ageni收集用户u
i,j
∈fi的加密反馈数据集后,为每一个用户u
i,j
∈fi计算随后发送处理后的加密反馈数据集给云服务器;本步骤中,推荐代理ageni需要先利用自己的私钥ki对标识向量进行半解密,再发给云服务器;
[0045]
s42、云服务器对进行解密得到解密过程如下:
[0046][0047]
本步骤中,因为上一步骤中推荐代理ageni对标识向量进行了半解密,于是云服务器可以通过自己的私钥l将标识向量解密得到明文结果;
[0048]
s43、云服务器计算并更新推荐代理ageni的可靠度分值resi以及可靠度分值resi更新次数counti,具体过程如下:
[0049][0050][0051]
count
i(new)
=counti+1
[0052]
其中,为用户u
i,j
给出反馈评分总分,为真实评分向量,r
i,1
,r
i,2
,...,r
i,p
为关于推荐项目的第1,2,...,p维度的评分分值,rsub
i,j
表示为用户u
i,j
在中选取个元素组成的集合,res
i(new)
为更新后的推荐代理ageni的可靠度分值,|fi|为给推荐代理ageni发过反馈的用户总数。在本步骤中,云服务器因为评分矩阵为密文形式,所以不能知道具体每一项的分值,但是因为知道标识向量的明文,同时密钥是正交矩阵,通过相乘后向量内积运算,在不知道具体每一项的分值的情况下,即可得到每一项真实评分是总和。
[0053]
本发明相对于现有技术具有如下的优点及效果:
[0054]
(1)本发明设计了一个基于正交矩阵的密文相似度计算算法,不仅可以减少计算开销,还可以保证用户的隐私安全。基于该算法,本发明设计了一种基于联邦学习和相似度密文计算的个性化项目推荐方法,能够安全地从多个推荐代理中聚集推荐权重矩阵,计算出密文下的用户需求与项目属性之间的相似度,从而在保证用户和推荐代理双方隐私的同时提高推荐的准确性。此外,根据可靠性分数选择性能较好的代理参与联邦推荐,进一步提高推荐的准确性。
[0055]
(2)本发明在已定义的威胁模型下,即云服务器和推荐代理都是诚实但好奇:假设推荐代理和云服务器将遵循协议运行,但可能对用户的敏感信息感到好奇,并且推荐代理和云服务器不允许合谋;证明了该方法能够满足用户和推荐代理的隐私要求。此外,通过实验表明,与现有方案相比,该方案具有最佳的准确度和效率。
附图说明
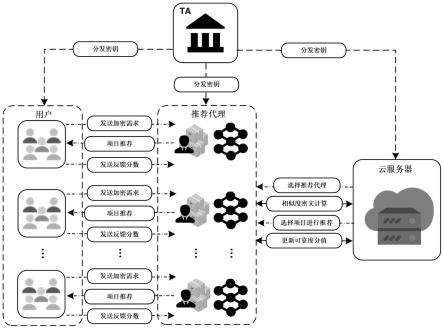
[0056]
图1是本发明实施例公开的一种基于联邦学习和相似度密文计算的个性化项目推荐方法的系统设计图;
[0057]
图2是本发明实施例公开的一种基于联邦学习和相似度密文计算的个性化项目推荐方法的流程示意图。
具体实施方式
[0058]
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0059]
实施例1
[0060]
随着大数据的流行,信息过载使人们获得更多无用的信息。于是,推荐系统逐渐流行起来。为用户提供个性化的项目推荐是推荐系统的主要目的,其中项目包括电影,图书等,目前,推荐系统已成为解决信息过载问题的重要途径,但是,推荐系统为教育、医疗和其他行业带来了机遇的同时也带来了一系列的挑战。其中隐私泄露是首要问题之一。一般来说,推荐系统由两部分组成:推荐服务器和用户。为了得到一个更好的推荐模型,传统的推荐系统使用一个中央架构,通常会收集大量的反馈信息,比如用户偏好。但这些信息往往对用户敏感,并可能导致严重的隐私和安全风险:用户的原始数据可能会从某些程序的反馈信息中泄露出来。例如,推荐系统在一定条件下,只须取得用户观看电影的纪录,便可推断出一些隐私信息(例如年龄、收入、病历等)。此外,推荐系统亦可收集使用者的个人资料,并与第三者分享,以获取利润。一旦这些信息被滥用,后果不堪设想。因此,人们越来越关心他们的数据隐私,他们希望他们的私人信息不会被互联网应用程序知道。
[0061]
本实施例针对以上问题,主要研究了一种基于联邦学习和相似度密文计算的高效个性化项目推荐技术,其中,项目包括电影、音乐、图书、商品,首先设计了一个基于正交矩阵的密文相似度计算算法,不仅可以减少计算开销,还可以保证用户的隐私安全。基于该算法,本发明设计了一种基于联邦学习和相似度密文计算的个性化项目推荐方法,能够安全
地从多个推荐代理中聚集推荐权重矩阵,计算出密文下的用户需求与项目属性之间的相似度,从而在保证用户和推荐代理双方隐私的同时提高推荐的准确性。此外,根据可靠性分数选择性能较好的代理参与联邦推荐,进一步提高推荐的准确性。
[0062]
下面结合图1对本实施例公开的一种基于联邦学习和相似度密文计算的个性化项目推荐方法,以电影推荐场景作为具体实施实例,进行详细说明:
[0063]
s1、系统初始化:可信中心ta为电影推荐代理ageni,用户u
i,j
和云服务器生成并分发密钥,其中,假设一共有n个电影推荐代理,每个电影推荐代理都有m个用户和n个电影,第i个电影推荐代理表示为ageni,电影推荐代理ageni的第j个用户表示为u
i,j
,并且满足1≤i≤n,1≤j≤m;电影推荐代理ageni的第i
′
个电影表示为i
i,i
′
,并且满足1≤i≤n,1≤i
′
≤n;可信中心ta首先运行密钥生成算法somc.keygen(p),其中p为矩阵维度,得到实现加密功能的第一密钥ka,第二密钥k
s,1
,k
s,2
,...,k
s,n
,第三密钥k1,k2,...,kn,第四密钥l和第五密钥j1,j2,...,jm;随后可信中心ta将ka,ki,k
s,i
发送给对应的电影推荐代理ageni,其中i=1,2,...,n;将k
s,1
,k
s,2
,...,k
s,n
和l发送给云服务器;将ji发送给用户u
i,1
,u
i,2
,...,u
i,m
;可信中心ta给电影推荐代理agen1,agen2,...,agenn生成身份标识id1,id2,...,idn;每一个电影i
i,i
′
生成对应的身份标识iid
i,i
′
,其中i=1,2,...,n,i
′
=1,2,...,n;可信中心ta将电影推荐代理agen1,agen2,...,agenn的可靠度分值res1,res2,...,resn初始化为0,以及res1,res2,...,resn的更新次数count1,count2,...,countn初始化为0;
[0064]
s2、数据加密:每一个电影i
i,i
′
的属性信息用p维向量表示,其中b
ii
′
,1
,b
ii
′
,2
,...,b
ii
′
,p
表示电影i
i,i
′
的第1,2,...,p个属性值,符号
“”
表示转置运算;每一个电影推荐代理ageni运行加密算法输出加密结果上传保存在云服务器中;
[0065]
s3、电影推荐:每一个用户u
i,j
的需求信息用p维向量表示,其中a
ij,1
,a
ij,2
,...,a
ij,p
表示用户u
i,j
需求的第1,2,...,p个属性值,用户u
i,j
运行加密算法输出加密结果之后用户u
i,j
往输出结果中加入噪声得到随后,用户u
i,j
将加密加噪的需求向量发给电影推荐代理ageni,通过电影推荐代理ageni和云服务器交互,执行电影推荐算法wi,得到被推荐的电影i
opt
和对应的身份标识iid
opt
发送给用户u
i,j
;
[0066]
s4、更新可靠度分值:每一个用户u
i,j
收到推荐结果之后,生成评分矩阵r
i,j
,用户u
i,j
往评分矩阵r
i,j
中加入噪声得到并生成评分标识向量并运行加密算法得到加噪加密评分矩阵r
′
i,j
,计算随后,用户u
i,j
将发给电影推荐代理ageni;通过电影推荐代理ageni和云服务器交互,执行更新可靠
度分值算法更新电影推荐代理ageni的可靠度分值。
[0067]
实施例2
[0068]
下面结合图1对本实施例公开的一种基于联邦学习和相似度密文计算的个性化项目推荐方法,以音乐、图书、商品推荐场景作为具体实施实例,进行详细说明:
[0069]
s1、系统初始化:可信中心ta为音乐/图书/商品推荐代理ageni,用户u
i,j
和云服务器生成并分发密钥,其中,假设一共有n个音乐/图书/商品推荐代理,每个音乐/图书/商品推荐代理都有m个用户和n个音乐/图书/商品,第i个音乐/图书/商品推荐代理表示为ageni,音乐/图书/商品推荐代理ageni的第j个用户表示为u
i,j
,并且满足1≤i≤n,1≤j≤m;音乐/图书/商品推荐代理ageni的第i
′
个音乐/图书/商品表示为i
i,i
′
,并且满足1≤i≤n,1≤i
′
≤n;可信中心ta首先运行密钥生成算法somc.keygen(p),其中p为矩阵维度,得到实现加密功能的第一密钥ka,第二密钥k
s,1
,k
s,2
,...,k
s,n
,第三密钥k1,k2,...,kn,第四密钥l和第五密钥j1,j2,...,jm;随后可信中心ta将ka,ki,k
s,i
发送给对应的音乐/图书/商品推荐代理ageni,其中i=1,2,...,n;将k
s,1
,k
s,2
,...,k
s,n
和l发送给云服务器;将ji发送给用户u
i,1
,u
i,2
,...,u
i,m
;可信中心ta给音乐/图书/商品推荐代理agen1,agen2,...,agenn生成身份标识id1,id2,...,idn;每一个音乐/图书/商品i
i,i
′
生成对应的身份标识iid
i,i
′
,其中i=1,2,...,n,i
′
=1,2,...,n;可信中心ta将音乐/图书/商品推荐代理agen1,agen2,...,agenn的可靠度分值res1,res2,...,resn初始化为0,以及res1,res2,...,resn的更新次数count1,count2,...,countn初始化为0;
[0070]
s2、数据加密:每一个音乐/图书/商品i
i,i
′
的属性信息用p维向量表示,其中b
ii
′
,1
,b
ii
′
,2
,...,b
ii
′
,p
表示音乐/图书/商品i
i,i
′
的第1,2,...,p个属性值,符号
“”
表示转置运算;每一个音乐/图书/商品推荐代理ageni运行加密算法输出加密结果上传保存在云服务器中;
[0071]
s3、音乐/图书/商品推荐:每一个用户u
i,j
的需求信息用p维向量表示,其中a
ij,1
,a
ij,2
,...,a
ij,p
表示用户u
i,j
需求的第1,2,...,p个属性值,用户u
i,j
运行加密算法输出加密结果之后用户u
i,j
往输出结果中加入噪声得到随后,用户u
i,j
将加密加噪的需求向量发给音乐/图书/商品推荐代理ageni,通过音乐/图书/商品推荐代理ageni和云服务器交互,执行音乐/图书/商品推荐算法
[0072][0072]
得到被推荐的音乐/图书/商品i
opt
和对应的身份标识iid
opt
发送给用户u
i,j
;
[0073]
s4、更新可靠度分值:每一个用户u
i,j
收到推荐结果之后,生成评分矩阵r
i,j
,用户u
i,j
往评分矩阵r
i,j
中加入噪声得到并生成评分标识向量并运行加密算法得到加噪加密评分矩阵r
′
i,j
,计算随后,用户u
i,j
将
发给音乐/图书/商品推荐代理ageni;通过音乐/图书/商品推荐代理ageni和云服务器交互,执行更新可靠度分值算法更新音乐/图书/商品推荐代理ageni的可靠度分值。
[0074]
在效率方面,将提出的基于联邦学习和相似度密文计算的个性化项目推荐方法与文献[1,2]对比,具体来说,对比包括加密时间和推荐时间,结果如表1,2所示,其中推荐次数表示用户提交需求向量到获得推荐结果的过程循环的次数。其中,文献[1]的作者、文献名称和出处具体为m.zhang,y.chen,j.lin,a privacy-preserving optimization of neighbourhood-based recommendation for medical-aided diagnosis and treatment,ieee internet of things journal.。文献[2]的作者、文献名称和出处具体为peng,d.he,j.chen,n.kumar,m.k.khan,eprt:an efficient privacy preserving medical service recommendation and trust discovery scheme for ehealth system,acm transactions on internet technology(toit)21(3)(2021)1-24。
[0075]
表1.本发明与相关方案的加密时间对比表(单位:秒)
[0076]
推荐次数100200300400500600本发明0.09780.17090.27510.34030.4260.5086文献[1]0.111790.222590.336750.448710.562510.67988文献[2]0.9663411.9501372.9120033.8889134.8572025.840947
[0077]
表2.本发明与相关方案的推荐时间对比表(单位:秒)
[0078]
推荐次数100200300400500600本发明0.26410.50130.75131.01321.2471.51文献[1]12.13.25.56.26.8文献[2]1.03452.04173.05554.08715.21026.1359
[0079]
从表1,2可知,随着推荐次数的增加,本发明,文献[1]和文献[2]所需要的加密时间和推荐时间都是增加的趋势,但是本发明始终都保持最少的加密时间和推荐时间,这是因为在文献[1]中的加密方法中,一次加密操作只能处理1比特的信息,在文献[2]中的加密方法中,一次加密操作只能处理一个整数信息,但是本发明的加密方法中,一次加密操作可以同时处理多个整数信息。由此可知,本发明的计算开销是低于文献[1,2],有效地提升了推荐效率。
[0080]
在推荐准确率方面,将提出的基于联邦学习和相似度密文计算的个性化项目推荐方法与文献[1,2]对比,使用电影推荐评分movielens-100k数据集验证,改数据集的基本统计情况如表3所示。其中,用户数为943,电影项目数为1682,评分记录数为1000,每个用户至少评分20部电影。用户和电影从1号开始连续编号。数据是随机排序的。
[0081]
表3.movielens-100k数据集的基本统计表
[0082]
数据集用户项目(电影)评分记录movielens-100k943168210000
[0083]
将本发明和文献[1,2]进行对比,使用准确率进行性能的评估,比较结果如表4所示:
[0084]
表4.本发明与相关方案的推荐推荐准确度对比表
[0085]
推荐次数70008000900010000本发明65.51%67.94%71.24%75.19%文献[1]58.51%57.57%57.98%59.69%文献[2]59.60%60.53%61.33%62.64%
[0086]
从表4可以看出,本发明的一种基于联邦学习和相似度密文计算的个性化项目推荐方法随着推荐次数的增加始终比文献[1,2]准确率更高,具有更好的预测性能。
[0087]
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1