一种基于网络文本的社交用户抑郁倾向识别方法
1.本发明涉及一种基于网络文本的社交用户抑郁倾向识别方法,属于机器学习技术领域。
背景技术:
2.刘定平等在基于社交网络信息的用户抑郁症倾向识别这篇文章中利用文本内容、发博时间等社交信息作为特征,提出了一种基于社交网络信息的用户抑郁识别模型。2021年燕山大学刘海鸥等人根据一定时间内用户博文中的抑郁占比计算抑郁指数,提出了一种基于tcnn-gru的在线健康社区抑郁症用户画像模型。
3.然而上述方法中都只基于一个限定的时间段进行特征提取和计算,忽略了纵向时间跨度这个重要特征对结果的影响,从而导致错误识别曾有抑郁倾向或只是短暂发泄负面情绪的正常用户的现象,在一定程度上影响了抑郁用户识别结果的精度。
技术实现要素:
4.本发明的目的是提供一种基于网络文本的社交用户抑郁倾向识别方法,能够通过社交用户的文本信息和发博时间、内容占比等非文本信息,较为全面地计算用户的抑郁预测分数,提高社交网络用户的抑郁倾向识别准确性。
5.本发明的技术方案如下:
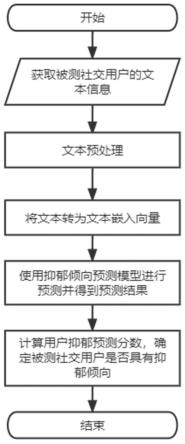
6.一种基于网络文本的社交用户抑郁倾向识别方法,包括以下步骤:
7.步骤1:获取被测社交用户的文本信息,进行文本预处理;
8.步骤2:将获得的文本转为文本嵌入向量;
9.步骤3:基于得到的文本嵌入向量,使用抑郁倾向预测模型进行预测并得到预测结果;
10.步骤4:基于预测结果,计算用户抑郁预测分数,确定被测社交用户是否具有抑郁倾向。
11.进一步地,步骤1中被测社交用户的文本信息包括一定时间内用户在其账户下发布的所有微博文本和一定时间内用户在其他用户微博下发布的所有评论文本。文本预处理即对原始文本进行清洗处理,清洗与结果无影响的字符。
12.进一步地,步骤2中将文本转为文本嵌入向量使用了bert(bidirectional encoder representations from transformers)模型,将文本转化为若干个词向量的组合。
13.进一步地,步骤3中抑郁倾向预测模型为利用双向长短时记忆网络bi-lstm模型对文本嵌入向量样本(包含抑郁倾向文本嵌入向量样本和无抑郁倾向文本嵌入向量样本)训练而得。得到的预测结果为二分类结果,即1表示有抑郁倾向,0表示无抑郁倾向。
14.步骤4中基于预测结果,计算用户抑郁预测分数,确定被测社交用户是否具有抑郁倾向的具体步骤包括以下:
15.步骤41:统计一定时间内被测用户在个人账户下发布的所有微博文本中具有抑郁倾向的微博文本占比;
16.步骤42:统计一定时间内被测用户在其他用户微博下发布的所有评论文本中具有抑郁倾向的评论文本占比;
17.步骤43:通过对步骤41和42中的两部分占比及各个时间段分配权重,将两部分占比逐个时间段累计加权求和,计算用户抑郁分数;
18.步骤44:将用户抑郁预测分数与预先设定的阈值k进行比较,如果大于等于阈值k,则确定被测用户具有抑郁倾向,如果小于阈值k,则确定用户不具有抑郁倾向。
19.本发明的有益效果在于:
20.本发明通过bert模型转换文本信息为词向量表示,并使用bi-lstm模型进行建模,更好地基于文本信息上下文相关性挖掘文本特征,提高文本抑郁预测的准确性;基于时间跨度和文本预测结果计算抑郁预测分数,通过纵向分隔时间为多个时间段并分别分配权重,合理考虑到纵向时间跨度对判别用户当前状态的影响,更好地提高了抑郁用户识别结果的精度。
附图说明
21.图1为本发明实施例的方法流程图;
22.图2为本发明实施例中单条文本预测流程;
23.图3为本发明实施例中时间段划分示意图。
24.具体实施方法
25.下面结合具体实施例,进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本技术所附权利要求所限定的范围。
26.如图1所示,一种基于网络文本的社交用户抑郁倾向识别方法,包括如下步骤:
27.步骤1:获取被测社交用户的文本信息,进行文本预处理。
28.本步骤中,选取新浪微博为社交媒体,选定被测用户,获取用户在个人账户下发布的所有微博文本和该用户在其他用户微博下发布的所有评论文本作为文本信息。
29.收集到文本信息后,对收集的文本信息进行文本预处理,即对文本进行清洗操作。清洗时,主要清洗掉两类与不影响结果的因素:一是非中文常见文本,如英文字母、希腊字母、标点符号类字符等;二是微博文本中形如“@走饭”的@用户昵称,使得文本信息更精简,信息密度更高。
30.步骤2:将获得的文本转为文本嵌入向量。
31.具体实施时,采用了bert预训练模型,将获得的文本信息进行词嵌入向量表示,转为文本嵌入向量。bert模型将文本以词为粒度,将每个词表示为一个768维的向量,具体地来讲,可以将用户的某一篇微博文本转为若干个768维的词向量。相比于word2vec得到的静态的词向量嵌入,通过bert训练得到的嵌入向量考虑到上下文语境,能提取到更深层次的文本特征。
32.具体地,如图2所示,输入经处理后的文本信息“我失眠半年了”,分别得到了“我”“失眠”“半年”“了”所对应的768维词向量。
33.步骤3:基于得到的文本嵌入向量,使用抑郁倾向预测模型进行预测并得到预测结果。
34.抑郁倾向预测模型为利用双向长短时记忆网络bi-lstm模型对文本嵌入向量样本训练而得,上述文本嵌入向量样本包括含抑郁倾向文本嵌入向量样本和无抑郁倾向文本嵌入向量样本。lstm模型是循环神经网络的变体,解决了传统循环网络梯度消失或爆炸的问题,在较长的时序输入中表现较好。具体实施时,向抑郁倾向预测模型中输入文本嵌入向量,模型根据输入的先后顺序进行双向循环,不仅能利用到过去的信息,还能捕捉到后续的信息。最后经过softmax层,输出预测结果。所述预测结果为二分类结果,即1表示有抑郁倾向,0表示无抑郁倾向。
35.具体实施时,如图2所示,分别将词向量e
我e失眠e半年e了
按照时间顺序依次输入到抑郁预测模型中,通过bi-lstm层,全连接层和softmax层后,输出预测结果0或1。
36.步骤4:基于预测结果,计算用户抑郁预测分数,确定被测社交用户是否具有抑郁倾向。
37.抑郁倾向预测模型可以对单条文本数据进行预测,但很难判定发表该条微博或评论的用户一定具有抑郁倾向。如发表“考试真的让人心灰意冷”微博或评论的用户有可能只是短时间受到情绪创伤,发表了冲动文字,并非真的具有抑郁倾向。因此针对单个用户,提出了基于历史微博或评论来计算其抑郁预测分数,实现社交用户抑郁倾向的精准判别。具体步骤包括如下:
38.步骤41:统计一定时间跨度内被测用户在个人账户下发布的所有微博文本中具有抑郁倾向的微博文本占比q,计算公式如下所示:
[0039][0040]
其中,m
self
为一定时间跨度内被测用户在个人账户下发布的所有微博数,m
d_self
为同一时间跨度内被测用户个人账户下发布的所有微博文本中,文本预测结果为有抑郁的微博数。
[0041]
步骤42:统计一定时间跨度内被测用户在其他用户微博下发布的所有评论文本中具有抑郁倾向的评论文本占比k,计算公式如下所示:
[0042][0043]
其中,m
other
为一定时间跨度内被测用户在其他用户微博下发布的所有评论数,m
d_other
为同一时间跨度内被测用户在其他用户微博下发布的所有评论中,文本预测结果为有抑郁的评论数。
[0044]
步骤43:通过分配恰当的权重值,将步骤41和42中的两部分占比逐个时间段累计加权求和,计算用户抑郁预测分数score。
[0045]
用户文本的发布时间也会在一定程度上影响用户的抑郁预测分数,如近期发布的微博或评论会比一年前发布的微博或评论,更能反映用户近期的状态。因此引入了按照时间段累加的方法。
[0046]
在具体实施中,如图3所示,可以将时间段以一年、半年或三个月进行划分,如以半年为单位进行划分,从2022年6月开始,往前找半年为一个跨度,即统计2022年1月至6月这
个跨度内占比,令其为q1,k1,再向前半年,以此类推下一个时间跨度为2021年7月至12月,直至向前找到用户发布的最早的微博或评论结束。
[0047]
在各个时间段的权重分配上,时间段的总数会随着用户最早一条文本的发布时间而变化,如果手动设置各个时间段的权重较为复杂。具体实施时,通过等比数列分配时间段权重,设置下一个时间段的权重为上一个时间段的c倍,其中1>c>0。
[0048]
用户抑郁预测分数score的计算公式如下所示:
[0049][0050]
其中,n为包含用户发布的最早微博或评论最少总时间段数,qi和ki分别为第n个时间段跨度中的占比,α、β、γ分别为qi,ki和时间段的权重,α+β=1,c为常数。在具体实施时,权重值可由经验值或者实验结果来设定,本发明实例中对此不进行限定。例如,可以设置α=0.5,β=0.5,γ=1。
[0051]
步骤44:将用户抑郁预测分数与预先设定的阈值k进行比较,如果大于等于阈值k,则确定被测用户有抑郁倾向,如果小于阈值k,则确定用户不具有抑郁倾向。
[0052]
具体实施中,最佳阈值k可由经验值或者实验结果来设定。例如被测用户的抑郁预测分数为0.82,阈值k为0.4,0.82大于0.4,即确定被测用户有抑郁倾向。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1