一种基于对比学习的BERT模型去偏方法及系统
一种基于对比学习的bert模型去偏方法及系统
技术领域
1.本发明涉及计算机的深度学习技术领域,更具体的,涉及一种基于对比学习的bert模型去偏方法及系统。
背景技术:
2.得益于机器学习的快速发展,人工智能领域愈发成熟,在追求模型极致的效率的同时,模型的公平性经常被忽略,这会导致严重的后果。美国的compas风险评估工具被设计用来根据被告的犯罪记录,犯罪类型等信息来预判其构成累犯的风险,以协助法官做出保释的决定。
3.自然语言处理领域中也会存在偏见,先前的去偏方法包括构建无偏数据集,词向量去偏等。然而近年来诸如bert等预训练语言模型的出现,在nlp,多模态学习,基础语言学习中的多项任务上取得了更好的性能,因此它们在各种现实世界应用中的使用激增。但最近的研究表明,预训练语言模型中也存在各种偏见,如情感分析中的性别不公平,模型认为男性更容易愤怒,女性更容易嫉妒。而先前的去偏方法在预训练语言模型中并不适用:以bert为例,拥有几亿参数量的bert的预训练需要使用大量的文本在大量的机器上花费大量的时间,重新构建如此大规模的无偏数据集是不现实的,重新训练对硬件和时间的要求也很高,并且每当出现新的偏见,很难又重新训练新的模型;词向量去偏在glove和word2vec上取得了很好的效果,但预训练语言模型bert强大的原因之一在于模型能学习到句子的上下文表征,由多个词组成的句子表现出很大的多样性,这种变化由许多因素导致,如话题,背景,个人等因素之间的差异;再者,词向量去偏受限于词表的长度,定义的偏见是有限的,而句子是无限的,偏见是无限的,因此很难将传统的词向量去偏方法扩展到句子。
4.针对这一问题,现有一种面向网络话题的热度评价方法,包括:将网络话题的属性与规则中的属性进行对比;其中,所述规则是经过训练得到的,且用于指示网络话题的属性与热度值的对应关系;以及根据对比的结果得到该网络话题的热度值。本发明定义了数值评价体系,方便了用户理解话题的热度程度,有利于话题之间的热度比较;以及,采用粗糙集相关理论最优化训练集中的不一致性,学习出热度值与属性之间的关系,提供了高热度评价的效果
5.现有的去偏方法有效率低,准确性低,因此如何发明一种效率高,准确性高的去偏方法,是本技术领域亟需解决的问题。
技术实现要素:
6.本发明为了解决现有技术效率低,准确性低的问题,提供了一种基于对比学习的bert模型去偏方法,其具有能够了解数据高阶特征的特点。
7.为实现上述本发明目的,采用的技术方案如下:
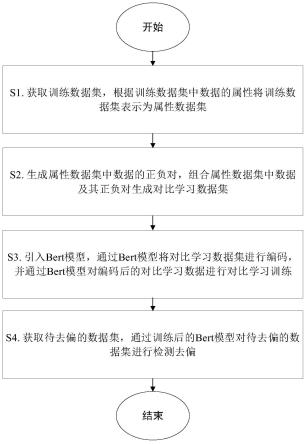
8.一种基于对比学习的bert模型去偏方法,包括以下步骤:
9.s1.获取训练数据集,根据训练数据集中数据的属性将训练数据集表示为属性数
据集;
10.s2.生成属性数据集中数据的正负对,组合属性数据集中数据及其正负对生成对比学习数据集;
11.s3.引入bert模型,通过bert模型将对比学习数据集进行编码,并通过bert模型对编码后的对比学习数据进行对比学习训练;
12.s4.获取待去偏的数据集,通过训练后的bert模型对待去偏的数据集进行检测去偏。
13.优选的,所述的步骤s1中,获取训练数据集,根据训练数据集中数据的属性将训练数据集表示为属性数据集,具体步骤为;
14.s101.获取数据集,将数据集分为训练数据集、验证集、测试集;
15.s102.分析训练数据集中具有多个属性的数据的属性,整理训练数据集中具有多个属性的数据的n个属性;
16.s103.根据整理出的属性,将训练数据集中具有多个属性的数据表示为属性数据xi={v1,v2,
…
,vn},并将属性数据组成属性数据集;其中,xi表示第i个属性数据,v1,v2,vn分别表示该数据的第1个,第2个,第n个属性的状态数。
17.进一步的,所述的步骤s2中,生成属性数据集中数据的正负对,组合属性数据集中数据及其正负对生成对比学习数据集,具体步骤为:
18.s201.分析属性数据集,确定一个或多个重要属性;
19.s202.将与属性数据集中的数据xi的重要属性语义相反的属性数据集中的数据作为数据xi的负例x
i-;
20.s203.将与属性数据集中的数据xi的重要属性相近的属性数据集中的数据作为数据xi的正例x
i+
;
21.s204.组合xi、x
i-、x
i+
,得到数据组si:
[0022][0023]
s205.将数据组si组合,生成对比学习数据集。
[0024]
更进一步的,所述的步骤s3中,通过bert模型将对比学习数据集进行编码具体为:通过bert编码器将对比学习数据集中的数据xi编码为hi,编码为编码为编码为
[0025][0026]
更进一步的,所述的步骤s3中,对比学习训练中,编码后的学习数据目标的损失函数为:
[0027][0028]
其中,τ为对比损失中的温度系数,用来控制模型对负样本的区分度,n为批次大小。
[0029]
更进一步的,所述的步骤s3中,通过bert模型对编码后的对比学习数据进行对比学习训练,具体为:bert模型采用并联的工作模式,对每一个属性对应的编码后的对比学习数据进行对比学习训练:
[0030]
bert=bert(v1,v2,
…
,vn)
[0031]
对应每一个属性vi,训练中采用损失函数l
vi
,总损失函数为:
[0032]
l
all
=α1l
v1
+α2l
v2
+
…
+αnl
vn
[0033]
其中,α1、α2、
…
、αn为每个各个属性对应的损失权重。
[0034]
更进一步的,所述的步骤s4中,获取待去偏的数据集,通过训练后的bert模型对待去偏的数据集进行检测去偏,具体步骤为:
[0035]
s401.获取待去偏的数据集(y1、y2、
…
、yn2),n2为待去偏的数据集中数据的数量;
[0036]
s402.通过训练后的bert模型对待去偏的数据集进行编码:
[0037]
bert(y1,y2…yn2
)=(h11,h12…
h1
n2
);
[0038]
s403.设置一个二类分类器将编码后的待去偏的数据集进行二分类:
[0039]
classifier(h11,h12…
h1
n2
)=(score1,score2);
[0040]
s404.使用softmax激活函数并取最大概率作预测标签:
[0041]
logits=max(softmax(score1,score2));
[0042]
s405.根据预测标签,使用训练后的bert模型进行检测对待去偏数据集中的偏见的训练;
[0043]
s406.根据检测到的偏见结果,对待去偏数据集进行去偏。
[0044]
更进一步的,步骤s3后,还通过验证集检测了训练后的bert模型的性能指标;bert模型的性能指标包括准确度,加权f1,宏f1和roc曲线下面积的auc值。
[0045]
更进一步的,检测了训练后的bert模型的性能指标后,还通过测试集评估了训练后的bert模型的公平性;bert模型的公平性指标通过计算测试集中数据的每个属性的真阳率/真阴率之间的平等差异和假阳率/假阴率之间的平等差异,并汇总各个属性的比率与总体比率的差值得到。
[0046]
一种基于对比学习的bert模型去偏系统,包括数据获取模块、属性划分模块、数据组合模块、bert模型、训练模块;
[0047]
所述的数据获取模块用于获取训练数据集;
[0048]
所述的属性划分模块用于根据训练数据集中数据的属性将训练数据集表示为属性数据集;
[0049]
所述的数据组合模块用于生成属性数据集中数据的正负对,组合属性数据集中数据及其正负对生成对比学习数据集;
[0050]
所述的bert模型用于将对比学习数据集进行编码和对编码后的对比学习数据进行对比学习训练;
[0051]
所述的数据获取模块还用于获取待去偏的数据集;
[0052]
所述的bert模型还用于对待去偏的数据集进行检测去偏。
[0053]
本发明的有益效果如下:
[0054]
本发明通过根据训练数据集中数据的属性将训练数据集表示为属性数据集,并生成属性数据集中数据的正负对,组合属性数据集中数据及其正负对生成对比学习数据集,
了解了数据的高阶特征;本发明还引入bert模型,通过bert模型将对比学习数据集进行编码,并通过bert模型对编码后的对比学习数据进行对比学习训练,提高了偏见粗检测的效率和准确率;由此本发明解决了现有技术效率低,准确性低的问题。
附图说明
[0055]
图1是本发明一种基于对比学习的bert模型去偏方法的流程示意图。
[0056]
图2是本发明一种基于对比学习的bert模型的对比学习框架图。
具体实施方式
[0057]
下面结合附图和具体实施方式对本发明做详细描述。
[0058]
实施例1
[0059]
如图1所示,一种基于对比学习的bert模型去偏方法,包括以下步骤:
[0060]
s1.获取训练数据集,根据训练数据集中数据的属性将训练数据集表示为属性数据集;
[0061]
s2.生成属性数据集中数据的正负对,组合属性数据集中数据及其正负对生成对比学习数据集;
[0062]
s3.引入bert模型,通过bert模型将对比学习数据集进行编码,并通过bert模型对编码后的对比学习数据进行对比学习训练;
[0063]
s4.获取待去偏的数据集,通过训练后的bert模型对待去偏的数据集进行检测去偏。
[0064]
实施例2
[0065]
更具体的,在一个具体实施例中,所述的步骤s1中,获取训练数据集,根据训练数据集中数据的属性将训练数据集表示为属性数据集,具体步骤为;
[0066]
s101.获取数据集,将数据集分为训练数据集、验证集、测试集;
[0067]
s102.分析训练数据集中具有多个属性的数据的属性,整理训练数据集中具有多个属性的数据的n个属性;
[0068]
s103.根据整理出的属性,将训练数据集中具有多个属性的数据表示为属性数据xi={v1,v2,
…
,vn},并将属性数据组成属性数据集;其中,xi表示第i个属性数据,v1,v2,vn分别表示该数据的第1个,第2个,第n个属性的状态数。
[0069]
本实施例中,数据集包括84542条数据,其中算作偏见的仇恨言论数据为31121条,非仇恨言论数据为53421条;将数据集按7:1.5:1.5划分训练集,验证集,测试集。
[0070]
本实施例只对训练集中属性明确的句子进行划分:
[0071]
根据性别划分:女性18650条,男性13000条;
[0072]
根据年龄划分:大于年龄阈值的13445条,小于年龄阈值的16616条。
[0073]
本实施例中,属性数据表示为;
[0074]
xi={性别,年龄,城市,种族,仇恨标签};
[0075]
若一条仇恨言论标签为h的推文x1的作者是男性,年龄为a,居住地为c,种族为e,那么这条推文的标签为:
[0076]
x1={0,a,c,e,h}
[0077]
在一个具体实施例中,所述的步骤s2中,生成属性数据集中数据的正负对,组合属性数据集中数据及其正负对生成对比学习数据集,具体步骤为:
[0078]
s201.分析属性数据集,确定一个或多个重要属性;
[0079]
s202.将与属性数据集中的数据xi的重要属性语义相反的属性数据集中的数据作为数据xi的负例x
i-;
[0080]
s203.将与属性数据集中的数据xi的重要属性相近的属性数据集中的数据作为数据xi的正例x
i+
;
[0081]
s204.组合xi、x
i-、x
i+
,得到数据组si:
[0082][0083]
s205.将数据组si组合,生成对比学习数据集。
[0084]
本实施例中,现以性别为变量,那么这条推文与相同性别的作者发表的推文是语义相近的,与不同性别的作者发表的推文是语义相反的,但其他属性也会对性别这个变量造成一定的影响,控制性别这个变量的同时也要控制其他属性变量,因此,本实施例考虑了大量情况,生成大量的正负例与原文本组成句子对s来进行实验,尽管有正负例两个句子,但实际上正负例标签的差别只是性别变量,其他变量应该是相同的。
[0085]
本实施例中,对于数据x1={0,a,c,e,h},其组成的数据组可为:
[0086][0087]
本实施例中,对于数据x1={0,a,c,e,h},其组成的数据组还可为:
[0088][0089]
s1只改变性别变量,其他属性与原文本相同,但是这种方法的挑选条件比较严格,生成的句子对比较少;s2除了改变性别变量,让年龄变量和原文本一致,其他变量不控制。
[0090]
针对其他变量,类似于s1和s2的生成方式同样高效。
[0091]
在一个具体实施例中,所述的步骤s3中,通过bert模型将对比学习数据集进行编码具体为:通过bert编码器将对比学习数据集中的数据xi编码为hi,编码为编码为
[0092][0093]
在一个具体实施例中,所述的步骤s3中,对比学习训练中,编码后的学习数据目标的损失函数为:
[0094]
[0095]
其中,τ为对比损失中的温度系数,用来控制模型对负样本的区分度,n为批次大小。
[0096]
如图2所示,在一个具体实施例中,所述的步骤s3中,通过bert模型对编码后的对比学习数据进行对比学习训练,具体为:bert模型采用并联的工作模式,对每一个属性对应的编码后的对比学习数据进行对比学习训练:
[0097]
bert=bert(v1,v2,
…
,vn)
[0098]
对应每一个属性vi,训练中采用损失函数l
vi
,总损失函数为:
[0099]
l
all
=α1l
v1
+α2l
v2
+
…
+αnl
vn
[0100]
其中,α1、α2、
…
、αn为每个各个属性对应的损失权重。
[0101]
本实施例中,并联的工作模式为:
[0102]
bert=bert(a
性别
,a
年龄
,a
国家
,a
种族
)
[0103]
本实施例中,总损失函数为:
[0104]
l
all
=α1l
性别
+α2l
年龄
+α3l
国家
+α4l
种族
[0105]
其中,通过实验,年龄属性对整个语义空间的影响较大,因此其对应的权重α2相对来说会更大。
[0106]
本实施例中,对比学习训练阶段在4张nvidia-a100上进行训练,每张卡的批次大小为128,一共训练10个epoch,最大句子长度设置为32,模型学习率为5e-5。
[0107]
在一个具体实施例中,所述的步骤s4中,获取待去偏的数据集,通过训练后的bert模型对待去偏的数据集进行检测去偏,具体步骤为:
[0108]
s401.获取待去偏的数据集(y1、y2、
…
、yn2),n2为待去偏的数据集中数据的数量;
[0109]
s402.通过训练后的bert模型对待去偏的数据集进行编码:
[0110]
bert(y1,y2…yn2
)=(h11,h12…
h1
n2
);
[0111]
s403.设置一个二类分类器将编码后的待去偏的数据集进行二分类:
[0112]
classifier(h11,h12…
h1
n2
)=(score1,score2);
[0113]
s404.使用softmax激活函数并取最大概率作预测标签:
[0114]
logits=max(softmax(score1,score2));
[0115]
s405.根据预测标签,使用训练后的bert模型进行检测对待去偏数据集中的偏见的训练;
[0116]
s406.根据检测到的偏见结果,对待去偏数据集进行去偏。
[0117]
本实施例中,仇恨言论检测训练阶段只需在1张nvidia-a100上进行训练,训练批次大小为64,一共训练4个epoch,使用adamw优化器,模型学习率为5e-6,dropout为0.1。
[0118]
在一个具体实施例中,步骤s3后,还通过验证集检测了训练后的bert模型的性能指标;bert模型的性能指标包括准确度,加权f1,宏f1和roc曲线下面积的auc值。
[0119]
在一个具体实施例中,检测了训练后的bert模型的性能指标后,还通过测试集评估了训练后的bert模型的公平性;bert模型的公平性指标通过计算测试集中数据的每个属性的真阳率/真阴率之间的平等差异和假阳率/假阴率之间的平等差异,并汇总各个属性的比率与总体比率的差值得到。
[0120]
本实施例中,如表1所示,对比单纯使用bert模型以及运用两种不同模版的对比学
习bert的仇恨检测的性能,可以看出bert模型在这个任务上的性能是很好的,并且用了对比学习后,bert的性能并没有明显下降:
[0121] accuracyf1-mf1-waucbert0.81150.75420.80800.8337模版s1对比学习0.801020.75140.79300.8302模版s2对比学习0.81020.75340.79900.8312
[0122]
表1
[0123]
本实施例中,表2显示了单纯bert模型的公平性评估,表3显示了运用s1数据组的bert模型的公平性评估,表4显示了运用s2数据组的bert模型的公平性评估;计算统计每个属性的真阳率/真阴率之间的平等差异(ed)和假阳率/假阴率之间的平等差异(ed),ed越高说明偏见越大越不公平,反之偏见越小越公平;对比bert的结果,两种对比学习的方法在四个属性上都有减少偏差的效果:
[0124] fnedfpedsun-ed性别0.014(
±
0%)0.035(
±
0%)0.049(
±
0%)年龄0.058(
±
0%)0.096(
±
0%)0.154(
±
0%)国家0.030(
±
0%)0.014(
±
0%)0.044(
±
0%)种族0.005(
±
0%)0.013(
±
0%)0.018(
±
0%)
[0125]
表2
[0126] fnedfpedsun-ed性别0.010(-28%)0.030(-14%)0.040(-18%)年龄0.051(-12%)0.086(-10%)0.137(-11%)国家0.024(-19%)0.015(+6%)0.041(-6%)种族0.005(
±
0%)0.009(-30%)0.0014(-22%)
[0127]
表3
[0128] fnedfpedsun-ed性别0.015(+6%)0.027(-22%)0.042(-14%)年龄0.045(-22%)0.095(-1%)0.140(-8%)国家0.025(-16%)0.011(-21%)0.036(-18%)种族0.003(-40%)0.009(-30%)0.012(-33%)
[0129]
表4
[0130]
由此,本发明通过根据训练数据集中数据的属性将训练数据集表示为属性数据集,并生成属性数据集中数据的正负对,组合属性数据集中数据及其正负对生成对比学习数据集,了解了数据的高阶特征;本发明还引入bert模型,通过bert模型将对比学习数据集进行编码,并通过bert模型对编码后的对比学习数据进行对比学习训练,提高了偏见粗检测的效率和准确率;由此本发明解决了现有技术效率低,准确性低的问题。
[0131]
实施例3
[0132]
一种基于对比学习的bert模型去偏系统,包括数据获取模块、属性划分模块、数据组合模块、bert模型、训练模块;
[0133]
所述的数据获取模块用于获取训练数据集;
[0134]
所述的属性划分模块用于根据训练数据集中数据的属性将训练数据集表示为属性数据集;
[0135]
所述的数据组合模块用于生成属性数据集中数据的正负对,组合属性数据集中数据及其正负对生成对比学习数据集;
[0136]
所述的bert模型用于将对比学习数据集进行编码和对编码后的对比学习数据进行对比学习训练;
[0137]
所述的数据获取模块还用于获取待去偏的数据集;
[0138]
所述的bert模型还用于对待去偏的数据集进行检测去偏。
[0139]
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1