基于Emo-ResNet的面部表情识别方法、装置、设备和介质
基于emo-resnet的面部表情识别方法、装置、设备和介质
技术领域
1.本发明涉及表情识别技术领域,具体涉及一种基于emo-resnet的面部表情识别方法、装置、设备和介质。
背景技术:
2.目前的面部表情识别多数是基于深度学习的。然而,许多面部表情识别的系统都是基于实验室环境的数据集,也就是受测者的表情都是故意变现的,表达较为明显,并不是自然表现,而人们大多数情况下的面部表情比较多都是自然表情。
3.卷积神经网络在特征提取方面存在一定优势,而目前基于深度学习的面部表情识别多数方法都为卷积神经网络。卷积神经网络使用卷积操作对人脸图像进行特征提取,从而在浅层学习到颜色、边缘等低层次特征,在中间层则会学习到纹理特征这类比较复杂的特征,而高层就会学习到带有区别性的关键特征。然而,普通的卷积神经网络只能学习到局部特征,还不能对图像的整理空间域特征进行学习,缺乏图像的上下文信息。而且若卷积神经网络的层数过高,会引起梯度消失或者梯度爆炸等问题,所以普通的卷积神经网络不能很好地抑制影响人脸表情识别的因素。
技术实现要素:
4.本发明的目的是为了解决现有技术中的上述缺陷,提供一种基于emo-resnet的面部表情识别方法、装置、设备和介质。
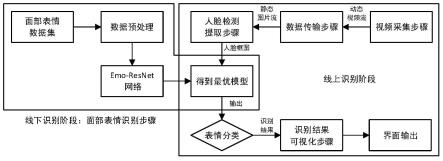
5.本发明的第一个目的在于提供一种基于emo-resnet的面部表情识别方法,所述面部表情识别方法包括:
6.s1、视频采集步骤,获取待识别者的实时动态视频流;
7.s2、数据传输步骤,将实时动态视频流进行帧间隔提取操作,并保存为静态图片流,获取包含待识别者面部在内的图像;
8.s3、人脸检测提取步骤,从包含待识别者面部在内的图像中识别出人脸并进行人脸矫正和人脸对齐,然后裁剪得到每位待识别者的人脸图片;
9.s4、面部表情识别步骤,将每位待识别者的人脸图片输入到经过训练的emo-resnet网络中,得到每位待识别者的各类面部表情类别的概率,将最大概率对应的面部表情作为待识别者的面部表情识别结果,其中,所述emo-resnet网络的主体框架为改进的resnet50,并在第四层卷积块的第一个瓶颈层将多头自注意力机制mhsa(multi-head self-attention)替换对应的卷积层和归一化网络层,同时将深度注意力中心损失(deep attentive center loss)作为损失函数;
10.s5、识别结果可视化步骤,将判定识别的面部表情类别以及该面部表情在实时动态视频中的时间在显示装置中输出,将识别结果可视化。
11.进一步地,所述视频采集步骤中获取的包括待识别者的动态视频流,是线上实时的录屏,或者是线下摄像头实时传输的视频,供实时掌握对方的实时情绪;又或者是事先已
经录制好的视频。该技术方案落地应用于日常生活,故应用的素材需要是日常自然的视频,使发明更有真实性与适用性。
12.进一步地,所述数据传输步骤中,将实时动态视频流进行帧提取操作,根据事先指定短时间间隔将动态视频流进行间隔提取后保存为待识别者的静态图片流。帧提取操作,将一段连贯的视频流按同一时间间隔分成若干张图片,该时间间隔一般为0.1s-0.5s之间,时间间隔过短容易造成输入图片数量过多而系统卡顿,时间间隔过长则容易造成一些面部重要细节的疏漏。该操作为接下来的人脸检测提取步骤以及识别网络提供更合适的输入,有利于本发明的识别效率。
13.进一步地,所述人脸检测提取步骤中,检测静态图片流中每帧包括的人脸,对静态图片使用多任务卷积神经网络(mtcnn,multi-task convolutional neural network)提取人脸区域,同时提取多个对应人脸的感兴趣区域,所述感兴趣区域包括眼部区域、眉毛区域、嘴部区域以及面部轮廓区域,基于双眼区域确认人脸的中心点所在位置,并基于中心点对整张人脸进行人脸矫正,然后使人脸图片相对平面直角坐标系对齐,实现人脸对齐,最后裁剪得到每位待识别者经过人脸矫正与人脸对齐的人脸图片。上面步骤的多任务卷积神经网络采用级联的思想,一步步筛选出符合标准的人脸区域,将一个大的网络拆解成三个小型网络,比单个网络多出两个个置信度损失函数、人脸位置偏移量损失函数和五官偏移量损失函数,增加了两倍的损失函数量,使得整体参数量减少,运算更快。并且多任务卷积神经网络中使用小的卷积核代替大的卷积核,使其感受野相同,也是使参数量更少,运算更快,从而更利于人脸区域关键点与感兴趣区域的提取,也利于加快数据集的预处理过程。
14.其中,多任务卷积神经网络出自文献“zhang k,zhang z,li z,et al.joint face detection and alignment using multitask cascaded convolutional networks[j].ieee signal processing letters,2016,23(10):1499-1503.”,属于现有技术。
[0015]
人脸检测提取步骤的过程如下:
[0016]
s31、对静态图片流使用opencv自带的人脸检测模型检测每帧包括的人脸;其中,opencv自带的人脸检测模型出自“khan m,chakraborty s,astya r,et al.face detection and recognition using opencv[c]//2019international conference on computing,communication,and intelligent systems(icccis).ieee,2019:116-119.”[0017]
s32、对检测后的图片使用多任务卷积神经网络提取人脸区域,同时提取多个对应人脸的感兴趣区域;
[0018]
s33、基于双眼区域确认人脸的中心点所在位置,并基于中心点对整张人脸进行人脸矫正与人脸对齐,其中双眼区域的左眼中心位置设为(x
left_i
,y
left_i
),右眼中心位置设为(x
right_i
,y
right_i
),使用式(1)计算样本的倾斜度θ,式(1)为:
[0019][0020]
s34、将左眼中心位置(x
left_i
,y
left_i
)与右眼中心位置(x
right_i
,y
right_i
)的中心点作为中心对图片进行仿射变换,得到对应的正脸图像,仿射变换的公式如式(2)为:
[0021][0022]
其中,为输入的样本,经过放射变换成为偏移量为a为与倾斜度θ有关的仿射矩阵,具体如下:
[0023][0024]
s35、裁剪得到每位待识别者经过人脸矫正与人脸对齐的人脸图片。
[0025]
进一步地,所述emo-resnet网络具体如下:
[0026]
emo-resnet网络的输入为每位待识别者经过人脸矫正与人脸对齐的人脸图片,emo-resnet网络从输入到输出依次为顺序连接的卷积层conv 1、第一模块、第二模块、第三模块、第四模块、池化层avgpool、全连接层fc以及softmax模块,其中卷积层conv 1设置卷积核大小为3,步长为1,填充宽度为1;第一模块、第二模块、第三模块、第四模块的基础单元均为瓶颈层,每个瓶颈层有两条分支,其中第一分支依次为顺序连接的卷积层conv 01、归一化网络层bn01、激活函数relu、卷积层conv 02、归一化网络层bn02、激活函数relu、卷积层conv 03、归一化网络层bn03,第二分支依次为顺序连接的卷积层conv 04、归一化网络层bn04,将第一分支与第二分支的输出进行相加并经过激活函数relu得到瓶颈层的输出结果,第一模块、第二模块、第三模块、第四模块中瓶颈层数分别为3、4、6、3,其中对第四模块中的第一个瓶颈层用多头自注意力机制mhsa替换卷积层conv 04、归一化网络层bn04,而第一模块、第二模块、第三模块、第四模块中除第一个瓶颈层外,其他瓶颈层的第二分支均无卷积层conv 04与归一化网络层bn04。emo-resnet网络的主体框架是基于resnet50所作的改进,即基于残差网络。残差网络是卷积神经网络中的一种,具有容易优化的特点,本发明增加一定的网络深度以及嵌入注意力机制会在一定程度上提高准确率,而所构成的部分瓶颈层中第二分支均无卷积层与归一化网络层的特点会缓解增加网络深度所带来的网络退化(如梯度消失、梯度退化等)的问题。残差网络通过瓶颈层的恒等映射,将当前输出传入下一层结构,并且通过直连(shortcut)连接不会产生额外的参数,不会增加计算复杂度。同时网络中使用的归一化网络层能有效防止模型过拟合、梯度消失等问题。残差网络的全连接层对学到的“特征表述”起到“分类器”的作用。
[0027]
所述多头自注意力机制mhsa中的每一个注意力汇聚都被称作为一个头,而头(head)的数量设定为4,二维特征图的宽(width)与高(height)都设定为14,多头自注意力机制mhsa的计算公式表示如下:
[0028]
mhsa(q,k,v)=concat(head1,head2,...,headn)w0,
[0029]
其中attention计算公式为其中n为头的数量,q指查询向量矩阵,k指“被查”向量矩阵,q、k都是用来计算注意力的权重矩阵,v为用来将注意力加权求和得到最终结果的权重矩阵,dk为矩阵k维度大小,令通过权值进行线性变换,最终通过可学习的权重矩阵w0将多个由attention得到的头部headn拼接在一起,得到最终由q,k,v计算的多头自注意力结果mhsa(q,k,v),用于对图像进行提取特征,contact(head1,head2,...,headn)表示将head1,head2,...,headn进行拼接,所以concat(head1,head2,...,headn)w0表示将head1,head2,...,headn拼接后再与一个可学习的权重矩阵wo做线性变换,得到最终的注意力输出。使用多头自注意力机制不仅提高了计算效率,还能够给予注意力层的输出包含有不同子空间中的编码表示信息,从而增强模型的表达能力。
[0030]
进一步地,所述emo-resnet网络的损失函数为深度注意力中心损失,该深度注意
力中心损失出自“farzaneh a h,qi x.facial expression recognition in the wild via deep attentive center loss[c]//proceedings of the ieee/cvf winter conference on applications of computer vision.2021:2402-2411.”深度自注意力中心损失可以自适应地选择重要特征元素的集合进行增强识别。深度自注意力中心损失集成注意力机制,以卷积神经网络中生成的空间特征图为背景,预测与特征重要性相关的注意力权重。预测权重适应中心损失的稀疏公式,对嵌入空间中相关信息以选择性地实现类内聚敛(intra-class compactness)和类间分离(inter-class separation)。所述面部表情类别包括生气、厌恶、恐惧、开心、伤心、惊讶以及中性。
[0031]
进一步地,所述emo-resnet网络的训练过程如下:
[0032]
使用数据集fer2013进行人脸检测步骤提取操作。深度学习需要足够的训练数据来确保对给定识别任务的通用性。然而,大多数公开可用的面部表情识别数据库并没有足够数量的图像用于训练。因此,数据增强是深度学习研究的重要步骤。本发明对实现人脸矫正与人脸对齐后的人脸图像的中心和四角随机裁剪输入样本,然后水平翻转、旋转,这样可以得到一个比原始训练数据大十倍的数据集,将数据增强后的人脸图片与原数据集合并整合成新的训练集。多种操作的组合可以产生更多训练样本,使网络对人脸偏差和旋转更有鲁棒性,以进一步扩展数据的大小和多样性,缓解训练过拟合。
[0033]
接着,对新的训练集在emo-resnet网络中进行迭代训练,直到损失函数收敛为止,得到训练好的识别网络模型。其中,训练过程中的迭代函数为深度注意力中心损失函数,调度器采用余弦调度器(cosine),优化器为随机梯度下降优化器sgd,设置基础学习率为0.01,批量(batch_size)设置为32,设置每30组小样本损失函数不再提升则降低学习率,训练的最大迭代次数为300次,评估指标为准确率(accuracy)。对网络经过不断微调,并结合对比准确率,最终得到最佳训练网络模型。
[0034]
进一步地,所述步骤s5的识别结果可视化步骤对面部表情识别步骤所判定的结果与数据传输步骤传输来的图片流对应在视频流的时间进行结合,在前端界面输出,使得识别结果可视化,让待识别者的情态得到及时的反馈。
[0035]
本发明的第二个目的在于提供一种基于emo-resnet的面部表情识别装置,所述面部表情识别装置包括:
[0036]
视频采集模块,获取待识别者的实时动态视频流;
[0037]
数据传输模块,将实时动态视频流进行帧间隔提取操作,并保存为静态图片流,获取包含待识别者面部在内的图像;
[0038]
人脸检测提取模块,从包含待识别者面部在内的图像中识别出待识别者的人脸并进行人脸矫正和人脸对齐,然后裁剪得到每位待识别者的人脸图片;
[0039]
面部表情识别模块,将每位待识别者的人脸图片输入到经过训练的emo-resnet网络中,得到每位待识别者的各类面部表情类别的概率,将最大概率对应的面部表情作为待识别者的面部表情识别结果,其中,所述面部表情类别包括生气、厌恶、恐惧、开心、伤心、惊讶以及中性,所述emo-resnet网络的主体框架为改进的resnet50,并在第四层卷积块的第一个瓶颈层将多头自注意力机制mhsa替换对应的卷积层和归一化网络层,同时将深度注意力中心损失作为损失函数;
[0040]
识别结果可视化模块,将判定识别的面部表情类别以及该面部表情在实时动态视
频中的时间在显示装置中输出,将识别结果可视化。
[0041]
本发明的第三个目的在于提供一种计算机设备,包括处理器以及用于存储处理器可执行程序的存储器,所述处理器执行存储器存储的程序时,实现基于emo-resnet的面部表情识别方法。
[0042]
本发明的第四个目的在于提供一种存储介质,存储有程序,所述程序被处理器执行时,实现基于emo-resnet的面部表情识别方法。
[0043]
本发明相对于现有技术具有如下的优点及效果:
[0044]
(1)本发明训练时采用的数据集为自然环境下的面部表情数据集fer2013,通过该数据集训练出来的识别效果可以比目前许多基于实验室环境的面部表情数据集更适用于真实场景的面部表情识别;
[0045]
(2)本发明利用残差网络容易优化,且增加一定的网络深度或者对应嵌入注意力机制会一定程度上提高准确率,其所构成的残差块中跳跃连接的特点会缓解增加网络深度所带来的网络退化(如梯度消失、梯度退化等)的问题,其全连接层对学到的“特征表述”起到“分类器”的作用等的优点。克服普通的卷积神经网络只能学习到局部特征,还不能对图像的整理空间域特征进行学习,缺乏图像的上下文信息,而且若卷积神经网络的层数过高,会引起梯度消失或者梯度爆炸等的问题;
[0046]
(3)本发明融合残差网络以及多头自注意力机制、深度注意力中心损失[1]的优点,实现比单纯的残差网络更高准确率地对人脸面部表情进行分类识别;
[0047]
(4)本发明能够在应用场景上进一步扩展,可应用在各种场景中识别对方的面部表情,而且不局限于对图片输入进行识别,还可以对视频输入进行实时的识别并作出反馈,在应用中有更强的地适用性。
附图说明
[0048]
此处所说明的附图用来提供对本发明的进一步理解,构成本技术的一部分,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
[0049]
图1是本发明中公开的一种基于emo-resnet的面部表情识别方法的流程图;
[0050]
图2是本发明中emo-resnet网络识别模型的结构示意图;
[0051]
图3是本发明中瓶颈层的结构示意图;
[0052]
图4是本发明实施例提供的方法在fer2013数据集的测试集上表情分类混淆矩阵结构图;
[0053]
图5是本发明实施例提供的方法在raf-db数据集的测试集上表情分类混淆矩阵结构图;
[0054]
图6是本发明实施例4中超声图像处理装置的结构框图;
[0055]
图7是本发明实施例5中计算机设备的结构框图。
具体实施方式
[0056]
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员
在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0057]
实施例1
[0058]
目前许多面部表情识别的系统都是基于实验室环境的数据集,也就是受测者的表情都是故意变现的,表达较为明显,并不是自然表现,而大多数环境下人民的表情尤其是微表情比较多都是自然表情;同时,普通的卷积神经网络只能学习到局部特征,还不能对图像的整理空间域特征进行学习,缺乏图像的上下文信息,而且若卷积神经网络的层数过高,会引起梯度消失或者梯度爆炸等问题,所以普通的卷积神经网络不能很好地抑制影响人脸表情识别的因素;另外,单纯的残差网络虽然对图像特征的提取比普通的卷积神经网络要好,但是可以在原有的基础上通过嵌入注意力机制、修改损失函数,结合多方优点来实现更准确率地对人脸面部表情进行分类识别。
[0059]
本实施例提供一种基于emo-resnet的面部表情识别方法,包括如下步骤:
[0060]
s1、视频采集步骤,获取的包括待识别者的动态视频流,是线上实时的录屏,或者是线下摄像头实时传输的视频,供我们掌握对方的实时情绪;又或者是事先已经录制好的视频;
[0061]
s2、数据传输步骤,将实时动态视频流进行帧提取操作,根据事先处指定短时间间隔将动态视频流进行间隔提取后保存为待待识别者的静态图片流;
[0062]
s3、人脸检测提取步骤,对待识别者面部在内的图像进行检测每帧包括的人脸,使用多任务卷积神经网络(mtcnn,multi-task convolutional neural network)(zhang k,zhang z,li z,et al.joint face detection and alignment using multitask cascaded convolutional networks[j].ieee signal processing letters,2016,23(10):1499-1503.)对图片提取人脸区域,同时提取多个对应人脸的感兴趣区域,所述感兴趣区域包括眼部区域、眉毛区域、嘴部区域以及面部轮廓区域,基于双眼区域确认人脸的中心点所在位置,并基于中心点对整张人脸进行人脸矫正,然后使人脸图片相对平面直角坐标系对齐,实现人脸对齐,最后裁剪得到每位待识别者经过人脸矫正与人脸对齐的人脸图片,过程如下:
[0063]
s31、利用opencv(khan m,chakraborty s,astya r,et al.face detection and recognition using opencv[c]//2019international conference on computing,communication,and intelligent systems(icccis).ieee,2019:116-119.)自带的人脸检测模型检测静态图片流中每帧包括的人脸;s32、使用多任务卷积神经网络提取人脸区域,同时提取多个对应人脸的感兴趣区域;
[0064]
s33、基于双眼区域确认人脸的中心点所在位置,并基于中心点对整张人脸进行人脸矫正与人脸对齐,其中双眼区域的左眼中心位置设为(x
left_i
,y
left_i
),右眼中心位置设为(x
right_i
,y
right_i
),使用式(1)计算样本的倾斜度θ,式(1)为:
[0065]
s34、将左眼中心位置(x
left_i
,y
left_i
)与右眼中心位置(x
right_i
,y
right_i
)的中心点作为中心对图片进行仿射变换,得到对应的正脸图像,仿射变换的公式如式(2)为:
[0066]
其中,为输入的样本,经过放射变换成为偏移量为a为与倾斜度θ有关的仿射
矩阵,具体如下:
[0067]
s35、裁剪得到每位待识别者经过人脸矫正与人脸对齐的人脸图片。
[0068]
s4、面部表情识别步骤,将每张待识别者的人脸图片输入到经过训练的emo-resnet网络中,得到每个待识别者的每类面部表情类别的概率,将最大概率对应的面部表情作为待识别者的面部表情识别结果,其中,所述emo-resnet网络的主体框架为改进的resnet50,并在第四层卷积块将多头自注意力机制多头自注意力机制mhsa(multi-head self-attention)替换对应的卷积层,同时将深度注意力中心损失(deep attentive center loss)(出自farzaneh a h,qi x.facial expression recognition in the wild via deep attentive center loss[c]//proceedings of the ieee/cvf winter conference on applications of computer vision.2021:2402-2411.)作为损失函数;面部表情类别包括生气、厌恶、恐惧、开心、伤心、惊讶以及中性。
[0069]
其中,emo-resnet网络具体如下:
[0070]
emo-resnet网络的输入为每位待识别者经过人脸矫正与人脸对齐的人脸图片,emo-resnet网络从输入到输出依次为顺序连接的卷积层conv1、第一模块、第二模块、第三模块、第四模块、池化层avgpool、全连接层fc以及softmax模块,其中卷积层conv 1设置卷积核大小为3,步长为1,填充宽度为1;第一模块、第二模块、第三模块、第四模块的基础单元均为瓶颈层,每个瓶颈层有两条分支,其中第一分支依次为顺序连接的卷积层conv 01、归一化网络层bn01、激活函数relu、卷积层conv02、归一化网络层bn02、激活函数relu、卷积层conv 03、归一化网络层bn03,第二分支依次为顺序连接的卷积层conv 04、归一化网络层bn04,将第一分支与第二分支的输出进行相加并经过激活函数relu得到瓶颈层的输出结果,第一模块、第二模块、第三模块、第四模块中瓶颈层数分别为3、4、6、3,其中对第四模块中的第一个瓶颈层用多头自注意力机制mhsa替换卷积层conv 04、归一化网络层bn04,而第一模块、第二模块、第三模块、第四模块中除第一个瓶颈层外,其他瓶颈层的第二分支均无卷积层conv 04与归一化网络层bn04;
[0071]
本实施例中,多头自注意力机制mhsa中的每一个注意力汇聚都被称作为一个头,而头(head)的数量设定为4,二维特征图的宽(width)与高(height)都设定为14,多头自注意力机制mhsa的计算公式表示如下:
[0072]
mhsa(q,k,v)=concat(head1,head2,...,headn)w0,
[0073]
其中attention计算公式为其中n为头的数量,q指查询向量矩阵,k指“被查”向量矩阵,q、k都是用来计算注意力的权重矩阵,v为用来将注意力加权求和得到最终结果的权重矩阵,dk为矩阵k维度大小,令通过权值进行线性变换,最终通过可学习的权重矩阵w0将多个由attention得到的头部headn拼接在一起,得到最终由q,k,v计算的多头自注意力结果mhsa(q,k,v),用于对图像进行提取特征,contact(head1,head2,...,headn)表示将head1,head2,...,headn进行拼接,所以concat(head1,head2,...,headn)w0表示将head1,head2,...,headn拼接后再与一个可学习的权重矩阵wo做线性变换,得到最终的attention输出。
[0074]
emo-resnet网络的训练过程如下:
[0075]
s41、对数据集fer2013进行人脸检测步骤提取操作;
[0076]
s42、对实现人脸矫正与人脸对齐后的人脸图像进行翻转、旋转、切割等的数据增强,将数据增强后的人脸图片与原数据集合并整合成新的训练集。
[0077]
s43、对新的训练集在emo-resnet网络中进行迭代训练,直到损失函数收敛为止,得到训练好的识别网络模型。其中,训练过程中的迭代函数为深度注意力中心损失函数,调度器采用余弦调度器(cosine),优化器为随机梯度下降优化器sgd,设置基础学习率为0.01,批量(batch_size)设置为32,设置每30组小样本损失函数不再提升则降低学习率,训练的最大迭代次数为300次,评估指标为准确率(accuracy)。
[0078]
s44、对网络经过不断微调,并结合对比准确率,最终得到最佳训练网络模型。
[0079]
s5、识别结果可视化步骤,对面部表情识别模块所判定的结果(七分类:生气、厌恶、恐惧、开心、伤心、惊讶或者中性)与数据处理模块传输来的图片流对应在视频流的时间进行结合,在前端界面模块输出,使得识别结果可视化,让待识别者的情态得到及时的反馈。
[0080]
实施例2
[0081]
本实施例中实验环境基于pytorch1.7cuda10.2进行,使用nvidia corporation gp104gl[tesla p4]内存为8g的gpu(graphic processing unit),实验的开发语言为python。
[0082]
实验的超参数设置,批量设置batch_size为32,即每次训练向网络中输入32张图片;学习率设为0.01,调度器采用cosine,优化器为随机梯度下降优化器sgd,设置每30组小样本损失函数不再提升则降低学习率,迭代次数设置为300,实施上述面部表情识别方法,使用fer2013公共数据集评估本发明面部表情识别方法的性能。
[0083]
本实施例通过在fer2013公共数据集上的准确率,进行消融实验——在保持相应参数相同的情况下,提出的模型与原始的resnet50、改进的resnet50、改进的resnet50+mhsa、改进的resnet50+dacl、改进的resnet50+mhsa+softmax loss、改进的resnet50+mhsa+center loss进行对比;同时,进行对比实验——在保持相应参数相同的情况下,提出的模型比常见的面部表情识别算法googlenet、vgg+svm、resnet+cbam、dnn、cnn+svm、inception、densenet进行对比。
[0084]
具体地,本发明方法在fer2013数据集上通过本专利提出的模型得到的平均结果和原始的resnet50、改进的resnet50、改进的resnet50+mhsa、改进的resnet50+dacl、改进的resnet50+mhsa+softmax loss、改进的resnet50+mhsa+center loss的准确率进行消融实验对比,结果如表1所示:
[0085]
表1.fer2013数据集上消融实验结果对比表
[0086]
方法准确率accresnet5072.10%改进的resnet5072.58%改进的resnet50+mhsa72.88%改进的resnet50+dacl72.96%改进的resnet50+mhsa+softmax loss72.93%
改进的resnet50+mhsa+center loss73.29%emo-resnet(本发明方法)73.64%
[0087]
由表1可知,本发明构建的面部表情识别方法比原始的resnet50、改进的resnet50、改进的resnet50+mhsa、改进的resnet50+dacl、改进的resnet50+mhsa+softmax loss、改进的resnet50+mhsa+center loss的准确率都要高。
[0088]
具体地,本发明方法在fer2013数据集上通过本专利提出的模型得到的平均结果和常见的面部表情识别算法googlenet、vgg+svm、resnet+cbam、dnn、cnn+svm、inception、densenet进行对比实验,结果如表2所示:
[0089]
表2.fer2013数据集上对比实验结果对比表
[0090][0091][0092]
由表2可知,本发明构建的面部表情识别方法比常见的面部表情识别算法googlenet、vgg+svm、resnet+cbam、dnn、cnn+svm、inception、densenet的准确率都要高。
[0093]
本发明方法生成的混淆矩阵如图5所示,对于高兴、惊讶、厌恶和自然这四种表情的识别准确率比较高,尤其是对高兴的表情识别准确度基本都有90%以上。
[0094]
本实施例构建了一种基于emo-resnet的待识别者面部表情识别方法,结合残差网络以及mhsa、dacl的优点,实现较高准确率实时地对人脸面部表情进行分类识别,并通过消融实验和对比实验证明本实施例提出的算法更适用于面部表情识别,也为待识别者面部表情识别系统的构造提供方法。
[0095]
实施例3
[0096]
本实施例实验环境基于pytorch1.7cuda10.2进行,使用nvidia corporation gp104gl[tesla p4]内存为8g的gpu(graphic processing unit),实验的开发语言为python。
[0097]
实验的超参数设置与实施例1相似,实施上述面部表情识别方法,使用raf-db公共数据集评估本发明面部表情识别方法的性能。
[0098]
本发明通过在raf-db公共数据集上的准确率,进行消融实验——在保持相应参数相同的情况下,提出的模型与原始的resnet50、改进的resnet50、改进的resnet50+mhsa、改进的resnet50+dacl、改进的resnet50+mhsa+softmax loss、改进的resnet50+mhsa+center loss进行对比;同时,进行对比实验——在保持相应参数相同的情况下,提出的模型比常见的面部表情识别算法googlenet、vgg+svm、resnet+cbam、dnn、cnn+svm、inception、densenet进行对比。
[0099]
具体地,本发明方法在raf-db数据集上通过本实施例提出的模型得到的平均结果和原始的resnet50、改进的resnet50、改进的resnet50+mhsa、改进的resnet50+dacl、改进
的resnet50+mhsa+softmax loss、改进的resnet50+mhsa+center loss的准确率进行消融实验对比,结果如表1所示:
[0100]
表3.raf-db数据集上消融实验结果对比表
[0101]
方法准确率accresnet5085.78%改进的resnet5086.18%改进的resnet50+mhsa86.54%改进的resnet50+dacl87.18%改进的resnet50+mhsa+softmax loss86.54%改进的resnet50+mhsa+center loss87.06%emo-resnet(本发明方法)88.34%
[0102]
由表3可知,本发明构建的面部表情识别方法比原始的resnet50、改进的resnet50、改进的resnet50+mhsa、改进的resnet50+dacl、改进的resnet50+mhsa+softmax loss、改进的resnet50+mhsa+center loss的准确率都要高。
[0103]
具体地,本发明方法在raf-db数据集上通过本实施例提出的模型得到的平均结果和常见的面部表情识别算法googlenet、vgg+svm、resnet+cbam、dnn、cnn+svm、inception、densenet进行对比实验,结果如表4所示:
[0104]
表4.raf-db数据集上对比实验结果对比表
[0105][0106][0107]
由表4可知,本发明构建的面部表情识别方法比常见的面部表情识别算法googlenet、vgg+svm、resnet+cbam、dnn、cnn+svm、inception、densenet的准确率都要高。
[0108]
本发明方法生成的混淆矩阵如图5所示,对于高兴、惊讶、厌恶和自然这四种表情的识别准确率比较高,尤其是对高兴的表情识别准确度基本都有90%以上。
[0109]
上述实施例构建了一种基于emo-resnet的待识别者面部表情识别方法,结合残差网络以及mhsa、dacl的优点,实现较高准确率实时地对人脸面部表情进行分类识别,并通过消融实验和对比实验证明本专利提出的算法更适用于面部表情识别,也为待识别者面部表情识别系统的构造提供方法。
[0110]
实施例4
[0111]
如图6所示,本实施例提供了一种基于emo-resnet的面部表情识别装置,该面部表情识别装置包括视频采集模块601、数据传输模块602、人脸检测提取模块603、面部表情识别模块604和识别结果可视化模块605,各个模块的具体功能如下:
[0112]
视频采集模块601,获取待识别者的实时动态视频流;
[0113]
数据传输模块602,将实时动态视频流进行帧间隔提取操作,并保存为静态图片流,获取包含待识别者面部在内的图像;
[0114]
人脸检测提取模块603,从包含待识别者面部在内的图像中识别出待识别者的人脸并进行人脸矫正和人脸对齐,然后裁剪得到每位待识别者的人脸图片;
[0115]
面部表情识别模块604,将每位待识别者的人脸图片输入到经过训练的emo-resnet网络中,得到每位待识别者的各类面部表情类别的概率,将最大概率对应的面部表情作为待识别者的面部表情识别结果,其中,所述面部表情类别包括生气、厌恶、恐惧、开心、伤心、惊讶以及中性,所述emo-resnet网络的主体框架为改进的resnet50,并在第四层卷积块的第一个瓶颈层将多头自注意力机制mhsa替换对应的卷积层和归一化网络层,同时将深度注意力中心损失作为损失函数;
[0116]
识别结果可视化模块605,将判定识别的面部表情类别以及该面部表情在实时动态视频中的时间在显示装置中输出,将识别结果可视化。
[0117]
本实施例中各个模块的具体实现可以参见上述实施例1,在此不再一一赘述;需要说明的是,本实施例提供的装置仅以上述各功能模块的划分进行举例说明,在实际应用中,可以根据需要而将上述功能分配由不同的功能模块完成,即将内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能。
[0118]
实施例5
[0119]
本实施例提供了一种计算机设备,该计算机设备可以为计算机,如图7所示,其通过系统总线701连接的处理器702、存储器、输入装置703、显示器704和网络接口705,该处理器用于提供计算和控制能力,该存储器包括非易失性存储介质706和内存储器707,该非易失性存储介质706存储有操作系统、计算机程序和数据库,该内存储器707为非易失性存储介质中的操作系统和计算机程序的运行提供环境,处理器702执行存储器存储的计算机程序时,实现上述实施例1提出的一种基于emo-resnet的面部表情识别方法,过程如下:
[0120]
s1、视频采集步骤,获取待识别者的实时动态视频流;
[0121]
s2、数据传输步骤,将实时动态视频流进行帧间隔提取操作,并保存为静态图片流,获取包含待识别者面部在内的图像;
[0122]
s3、人脸检测提取步骤,从包含待识别者面部在内的图像中识别出待识别者的人脸并进行人脸矫正和人脸对齐,然后裁剪得到每位待识别者的人脸图片;
[0123]
s4、面部表情识别步骤,将每位待识别者的人脸图片输入到经过训练的emo-resnet网络中,得到每位待识别者的各类面部表情类别的概率,将最大概率对应的面部表情作为待识别者的面部表情识别结果,其中,所述面部表情类别包括生气、厌恶、恐惧、开心、伤心、惊讶以及中性,所述emo-resnet网络的主体框架为改进的resnet50,并在第四层卷积块的第一个瓶颈层将多头自注意力机制mhsa替换对应的卷积层和归一化网络层,同时将深度注意力中心损失作为损失函数;
[0124]
s5、识别结果可视化步骤,将判定识别的面部表情类别以及该面部表情在实时动态视频中的时间在显示装置中输出,将识别结果可视化。
[0125]
实施例6
[0126]
本实施例提供了一种存储介质,该存储介质为计算机可读存储介质,其存储有计算机程序,所述计算机程序被处理器执行时,实现上述实施例1的一种基于emo-resnet的面
部表情识别方法,过程如下:
[0127]
s1、视频采集步骤,获取待识别者的实时动态视频流;
[0128]
s2、数据传输步骤,将实时动态视频流进行帧间隔提取操作,并保存为静态图片流,获取包含待识别者面部在内的图像;
[0129]
s3、人脸检测提取步骤,从包含待识别者面部在内的图像中识别出待识别者的人脸并进行人脸矫正和人脸对齐,然后裁剪得到每位待识别者的人脸图片;
[0130]
s4、面部表情识别步骤,将每位待识别者的人脸图片输入到经过训练的emo-resnet网络中,得到每位待识别者的各类面部表情类别的概率,将最大概率对应的面部表情作为待识别者的面部表情识别结果,其中,所述面部表情类别包括生气、厌恶、恐惧、开心、伤心、惊讶以及中性,所述emo-resnet网络的主体框架为改进的resnet50,并在第四层卷积块的第一个瓶颈层将多头自注意力机制mhsa替换对应的卷积层和归一化网络层,同时将深度注意力中心损失作为损失函数;
[0131]
s5、识别结果可视化步骤,将判定识别的面部表情类别以及该面部表情在实时动态视频中的时间在显示装置中输出,将识别结果可视化。
[0132]
本实施例中所述的存储介质可以是磁盘、光盘、计算机存储器、随机存取存储器(ram,randomaccessmemory)、u盘、移动硬盘等介质。
[0133]
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1