人像风格化方法、装置、设备及介质与流程
本技术涉人工智能,尤其涉及一种人像风格化方法、装置、设备及介质。
背景技术:
1、卡通化人像生成模型g′是人像(卡通)风格化整个方案流程中非常重要的模块,直接决定最终卡通化人像的逼真度和风格化效果。以往的技术方案是先构建通用的生成真人图像的人像生成模型,然后在通用人像生成模型g的基础上进行知识迁移得到卡通化人像生成模型g′,因此,g和g′往往具有相同的网络结构。发明人发现,以往的技术方案中,g和g′都是使用卷积神经网络(cnn)进行建模,然而,卷积神经网络(cnn)具有感受视野受限的问题,而且端到端直接生成高分辨率(1024*1024)的整张人脸图像,这对人像生成模型g的模型容量和网络结构要求很高,而且对于训练过程的调参要求苛刻,所以,实际得到的通用人像生成模型g所生成的真人图像细节不够,卡通化人像生成模型g′所生成的卡通人像逼真度和风格化效果都有所欠缺。
技术实现思路
1、针对上述技术问题,本技术的目的在于提供一种人像风格化方法、装置、设备及介质,旨在解决cnn感受视野受限和直接生成整张高分辨率图像任务导致生成的卡通人像逼真度和风格化效果有所欠缺的技术问题。
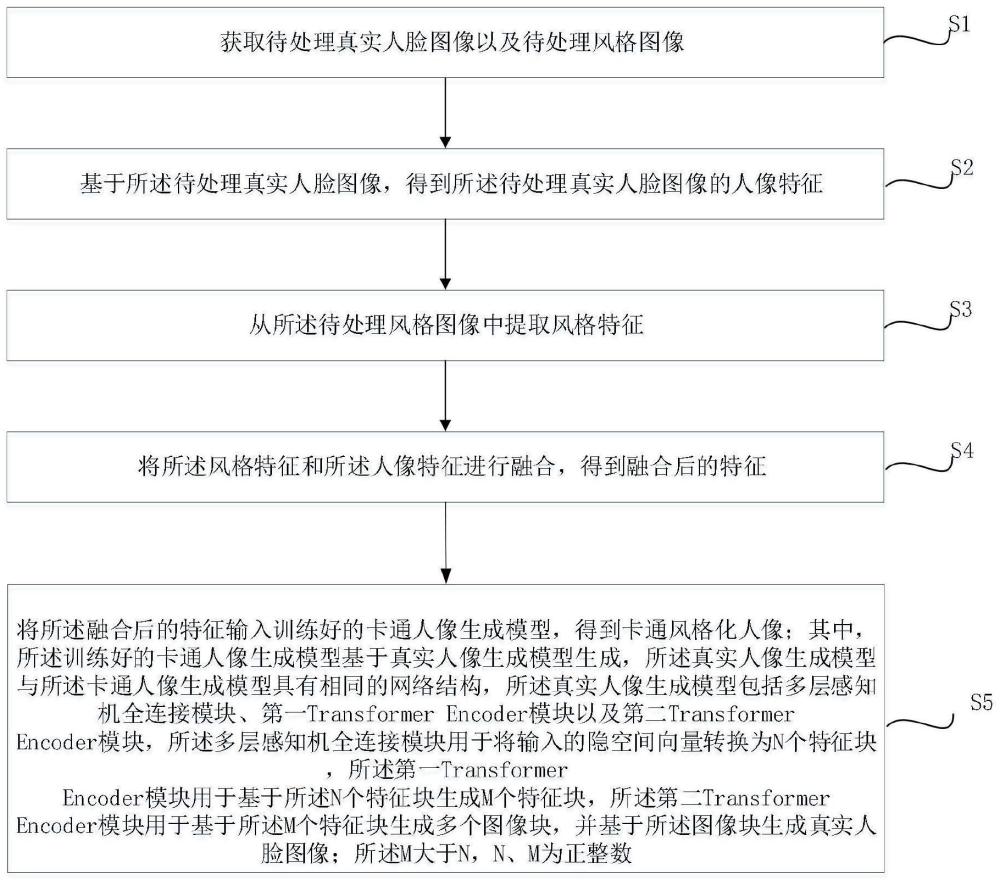
2、本技术实施例提供一种人像风格化方法,包括:
3、获取待处理真实人脸图像以及待处理风格图像;
4、基于所述待处理真实人脸图像,得到所述待处理真实人脸图像的人像特征;
5、从所述待处理风格图像中提取风格特征;
6、将所述风格特征和所述人像特征进行融合,得到融合后的特征;
7、将所述融合后的特征输入训练好的卡通人像生成模型,得到卡通风格化人像;其中,所述训练好的卡通人像生成模型基于真实人像生成模型生成,所述真实人像生成模型与所述卡通人像生成模型具有相同的网络结构,所述真实人像生成模型包括多层感知机全连接模块、第一transformer encoder模块以及第二transformer encoder模块,所述多层感知机全连接模块用于将输入的隐空间向量转换为n个特征块,所述第一transformerencoder模块用于基于所述n个特征块生成m个特征块,所述第二transformer encoder模块用于基于所述m个特征块生成多个图像块,并基于所述图像块生成真实人脸图像;所述m大于n,n、m为正整数。
8、进一步的,所述基于所述待处理真实人脸图像,得到所述待处理真实人脸图像的人像特征;包括:
9、对所述待处理真实人脸图像进行分割,得到人像分割图;
10、从所述人像分割图中提取局部纹理特征;
11、从所述待处理真实人脸图像中提取全局特征;
12、将所述局部纹理特征和所述全局特征进行线性融合,得到结构特征;其中,所述结构特征为所述人像特征。
13、进一步的,基于真实人像生成模型生成训练好的卡通人像生成模型,包括:
14、获取p张卡通人脸图像;p为正整数;
15、将所述真实人像生成模型参数迁移到卡通人像生成网络中,作为所述卡通人像生成网络的初始化参数,形成待训练卡通人像生成模型;
16、基于所述真实人像生成模型以及人脸特征提取模型,确定每张卡通人脸图像对应的第一隐空间向量;
17、提取每个所述第一隐空间向量输入所述待训练真实人像生成模型后每层网络的特征,得到每个所述第一隐空间向量对应的特征;
18、从高斯分布随机噪声中随机采样得到m个第二隐空间向量;
19、提取每个所述第二隐空间向量输入所述待训练卡通人像生成模型后每层网络的特征,得到每个所述第二隐空间向量对应的特征;
20、将每一所述第二隐空间向量输入所述待训练卡通人像生成模型,得到每一所述第二隐空间向量对应的卡通化人脸图像;
21、通过判别器对每一所述卡通化人脸图像进行评价打分,得到每一所述卡通化人脸图像对应的分数;
22、基于每个所述第一隐空间向量对应的特征、每个所述第二隐空间向量对应的特征以及每一所述卡通化人脸图像对应的分数,采用预设的损失函数计算损失;
23、以所述损失最小化为目标迭代训练所述卡通人像生成模型,得到所述训练好的卡通人像生成模型。
24、进一步的,所述基于所述真实人像生成模型以及人脸特征提取模型,确定每张卡通人脸图像对应的第一隐空间向量,包括:
25、根据公式确定每张卡通人脸图像对应的第一隐空间向量;其中,g表示真实人像生成模型,z表示第二隐空间向量,f表示人脸特征提取模型,表示第i张卡通人脸图像,λ1为预设的参数。
26、进一步的,所述的人像风格化方法,其特征在于,所述基于每个所述第一隐空间向量对应的特征、每个所述第二隐空间向量对应的特征以及每一所述卡通化人脸图像对应的分数,采用预设的损失函数计算损失,包括:
27、根据损失函数计算损失;其中,m为一次迭代训练需要的卡通人脸图像数量,为第i张卡通人脸图像对应的第一隐空间向量,zi为第i个第二隐空间向量,l为网络层数,为第一隐空间向量输入真实人像生成模型中,第j层网络的特征;为第二隐空间向量输入卡通化人像生成模型中,第j层网络的特征,λ2为预设的参数,为第i个卡通化人脸图像对应的分数。
28、第二方面,本技术实施例提供一种人像风格化装置,包括:
29、获取模块,用于获取待处理真实人脸图像以及待处理风格图像;
30、人像特征提取模块,用于基于所述待处理真实人脸图像,得到所述待处理真实人脸图像的人像特征;
31、风格特征提取模块,用于从所述待处理风格图像中提取风格特征;
32、融合模块,用于将所述风格特征和所述人像特征进行融合,得到融合后的特征;
33、输入模块,用于将所述融合后的特征输入训练好的卡通人像生成模型,得到卡通风格化人像;其中,所述训练好的卡通人像生成模型基于真实人像生成模型生成,所述真实人像生成模型与所述卡通人像生成模型具有相同的网络结构,所述真实人像生成模型包括多层感知机全连接模块、第一transformer encoder模块以及第二transformer encoder模块,所述多层感知机全连接模块用于将输入的隐空间向量转换为n个特征块,所述第一transformer encoder模块用于基于所述n个特征块生成m个特征块,所述第二transformerencoder模块用于基于所述m个特征块生成多个图像块,并基于所述图像块生成真实人脸图像;所述m大于n,n、m为正整数。
34、进一步的,所述人像特征提取模块,包括:
35、分割单元,用于对所述待处理真实人脸图像进行分割,得到人像分割图;
36、局部纹理特征提取单元,用于从所述人像分割图中提取局部纹理特征;
37、全局特征提取单元,用于从所述待处理真实人脸图像中提取全局特征;
38、融合单元,用于将所述局部纹理特征和所述全局特征进行线性融合,得到结构特征;其中,所述结构特征为所述人像特征。
39、进一步的,所述的人像风格化装置,还包括:卡通人像生成模型训练模块,所述卡通人像生成模型训练模块包括:
40、获取单元,用于获取p张卡通人脸图像;p为正整数;
41、初始化单元,用于将所述真实人像生成模型参数迁移到卡通人像生成网络中,作为所述卡通人像生成网络的初始化参数,形成待训练卡通人像生成模型;
42、第一确定单元,用于基于所述真实人像生成模型以及人脸特征提取模型,确定每张卡通人脸图像对应的第一隐空间向量;
43、第一提取单元,用于提取每个所述第一隐空间向量输入所述待训练真实人像生成模型后每层网络的特征,得到每个所述第一隐空间向量对应的特征;
44、采样单元,用于从高斯分布随机噪声中随机采样得到m个第二隐空间向量;
45、第二提取单元,用于提取每个所述第二隐空间向量输入所述待训练卡通人像生成模型后每层网络的特征,得到每个所述第二隐空间向量对应的特征;
46、输入单元,用于将每一所述第二隐空间向量输入所述待训练卡通人像生成模型,得到每一所述第二隐空间向量对应的卡通化人脸图像;
47、打分单元,用于通过判别器对每一所述卡通化人脸图像进行评价打分,得到每一所述卡通化人脸图像对应的分数;
48、损失计算单元,用于基于每个所述第一隐空间向量对应的特征、每个所述第二隐空间向量对应的特征以及每一所述卡通化人脸图像对应的分数,采用预设的损失函数计算损失;
49、迭代训练单元,用于以所述损失最小化为目标迭代训练所述卡通人像生成模型,得到所述训练好的卡通人像生成模型。
50、第三方面,本技术实施例提供一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现上述任一项所述方法的步骤。
51、第四方面,本技术实施例提供一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现上述任一项所述的方法的步骤。
52、本技术实施例提供一种人像风格化方法,包括:获取待处理真实人脸图像以及待处理风格图像;基于所述待处理真实人脸图像,得到所述待处理真实人脸图像的人像特征;从所述待处理风格图像中提取风格特征;将所述风格特征和所述人像特征进行融合,得到融合后的特征;将所述融合后的特征输入训练好的卡通人像生成模型,得到卡通风格化人像;其中,所述训练好的卡通人像生成模型基于真实人像生成模型生成,所述真实人像生成模型与所述卡通人像生成模型具有相同的网络结构,所述真实人像生成模型包括多层感知机全连接模块、第一transformer encoder模块以及第二transformer encoder模块,所述多层感知机全连接模块用于将输入的隐空间向量转换为n个特征块,所述第一transformerencoder模块用于基于所述n个特征块生成m个特征块,所述第二transformer encoder模块用于基于所述m个特征块生成多个图像块,并基于所述图像块生成真实人脸图像;所述m大于n,n、m为正整数。由于transformer encoder模块本身包括自注意力机制模块,因此,增大了滤波器的感受视野,从而保留更多信息,帮助生成更多人脸细节;通过两个transformerencoder模块,分阶段生成低清晰度到高清晰度人脸分块图像,有助于模型更容易学习到生成高清人脸图像的能力,且分成小块的人脸图像由于分辨率更低也有更容易学习,避免了直接生成整张高清晰度(分辨率)导致人像生成模型难以训练、训练得到的人像生成模型生成的真实人脸图像细节不够好的问题,从而提高了卡通风格化人像的逼真度以及风格化效果。此外,通过解耦人像特征和结构特征,能够更加精准的控制风格化图像的生成。
- 还没有人留言评论。精彩留言会获得点赞!