人脸驱动方法、装置及终端与流程
本技术实施例涉及计算机视觉,尤其涉及一种人脸驱动方法、装置及终端。
背景技术:
1、人脸驱动技术通过视频或照片在计算机设备上建立训练对象的三维模型,并通过另一对象的表情驱动三维模型,使三维模型既具有训练对象的特征,又可以呈现另一对象的表情。目前,常将该技术应用于影视娱乐领域,例如,通过捕捉演员的脸部表情,将其与计算机设备上的三维模型的表情相匹配,最终呈现具有演员脸部表情的三维模型,以得到较为真实的、具有训练对象特征的画面。
2、由于该技术是用另一对象的表情驱动三维模型,而三维模型是以训练对象的部分数据为基础训练得到,因此,驱动三维模型的表情中可能存在训练三维模型的数据中没有的表情。该表情在训练数据中的缺失,很容易导致最终得到的三维模型在脸部表情上的细节缺失,从而使三维模型缺少真实感。
技术实现思路
1、鉴于上述问题,本技术实施例提供了一种人脸驱动方法、装置及终端,可以提升三维模型在脸部表情上的细节的丰富度,从而提高三维模型的真实感。
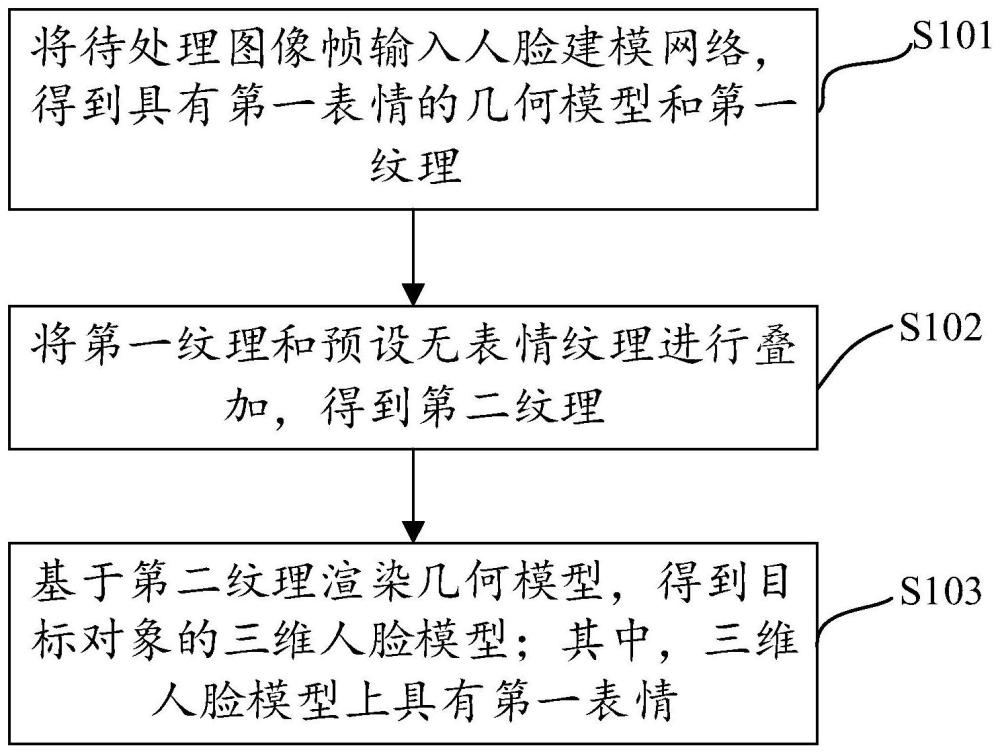
2、第一方面,本技术实施例提供了一种人脸驱动方法,包括:
3、将待处理图像帧输入人脸驱动网络,得到具有第一表情的几何模型和第一纹理;其中,人脸驱动网络是基于目标对象的训练数据集预先训练得到;
4、将第一纹理和预设无表情纹理进行叠加,得到第二纹理;
5、基于第二纹理渲染几何模型,得到目标对象的三维人脸模型;其中,三维人脸模型上具有第一表情。
6、在一种可选的实现方式中,人脸驱动网络包括表情子网络、模型子网络、纹理子网络、第一多层感知器mlp子网络和第二mlp子网络;
7、将待处理图像帧输入人脸驱动网络,得到具有第一表情的几何模型和第一纹理,包括:
8、将待处理图像帧输入表情子网络,得到第一表情隐向量;
9、将第一表情隐向量输入第一mlp子网络,得到第二表情隐向量;并将第一表情隐向量输入第二mlp子网络,得到第三表情隐向量;
10、将第二表情隐向量输入模型子网络,得到具有第一表情的几何模型;
11、将第三表情隐向量输入纹理子网络,得到第一纹理。
12、在一种可选的实现方式中,将待处理图像帧输入人脸驱动网络之前,方法还包括:
13、获取目标对象的训练数据集;训练数据集中包括多组训练数据,每组训练数据至少包括第一待训练图像、待训练模型以及对应的待训练纹理;
14、根据第一待训练图像对初始的表情子网络进行训练,得到训练好的表情子网络,根据待训练模型对初始的模型子网络进行训练,得到训练好的模型子网络,以及,根据待训练纹理对初始的纹理子网络进行训练,得到训练好的纹理子网络;
15、根据训练数据集分别对初始的第一mlp子网络和初始的第二mlp子网络进行训练,得到训练好的第一mlp子网络和第二mlp子网络;
16、将训练好的表情子网络、模型子网络、纹理子网络、第一mlp子网络和第二mlp子网络确定为人脸驱动网络;
17、根据获取到的第二待训练图像和对应的标签信息对人脸驱动网络进行优化,得到优化后的人脸驱动网络;
18、其中,标签信息用于标识第二待训练图像的类型。
19、在一种可选的实现方式中,第一待训练图像包括第一图像帧、第二图像帧和第三图像帧;其中,第一图像帧具有第一表情信息和第一角度信息,第二图像帧的第二表情信息与第一表情信息不同,第三图像帧的第二角度信息与第一角度信息不同;
20、根据第一待训练图像对初始的表情子网络进行训练,得到训练好的表情子网络,包括:
21、将第一图像帧输入初始的表情子网络,得到第四表情隐向量和第一视角隐向量;
22、将第二图像帧输入初始的表情子网络,得到第二视角隐向量;
23、将第三图像帧输入初始的表情子网络,得到第五表情隐向量;
24、基于表情损失函数更新初始的表情子网络的参数,得到训练好的表情子网络;表情损失函数是基于第四表情隐向量和第五表情隐向量的差值,以及第一视角隐向量和第二视角隐向量的差值构建的。
25、在一种可选的实现方式中,待训练模型包括:第一模型,第二模型和第三模型;其中,第一模型具有第三表情信息和第三角度信息,第二模型的第四表情信息与第三表情信息不同,第三模型的第四角度信息与第三角度信息不同;
26、根据待训练模型对初始的模型子网络进行训练,得到训练好的模型子网络,包括:
27、将第一模型、第二模型、第三模型分别输入初始的模型子网络,得到对应的第四模型、第五模型和第六模型;
28、基于模型损失函数更新初始的模型子网络的参数,得到训练好的模型子网络;模型损失函数是基于第四模型与第一模型的差值、第五模型与第二模型的差值、和第六模型与第三模型的差值构建的。
29、在一种可选的实现方式中,待训练纹理包括第一多层纹理的皱纹图,根据待训练纹理对初始的纹理子网络进行训练,得到训练好的纹理子网络,包括:
30、将第一多层纹理的皱纹图输入初始的纹理子网络,得到第二多层纹理的皱纹图;
31、基于纹理损失函数更新初始的纹理子网络的参数,得到训练好的纹理子网络;纹理损失函数是基于第一多层纹理的皱纹图和第二多层纹理的皱纹图的差值构建的。
32、在一种可选的实现方式中,根据训练数据集分别对初始的第一mlp子网络和初始的第二mlp子网络进行训练,得到训练好的第一mlp子网络和第二mlp子网络,包括:
33、将第一待训练图像输入表情子网络,得到第一训练表情隐向量;
34、将待训练模型输入模型子网络,得到第二训练表情隐向量;
35、将第一训练表情隐向量输入初始的第一mlp子网络,得到第三训练表情隐向量;
36、基于第一mlp损失函数更新初始的第一mlp子网络的参数,得到训练好的第一mlp子网络;第一mlp损失函数是基于第三训练表情隐向量与第二训练表情隐向量的差值构建的;
37、将待训练纹理输入纹理子网络,得到第四训练表情隐向量;
38、将第一训练表情隐向量输入初始的第二mlp子网络得到第五训练表情隐向量;
39、基于第二mlp损失函数更新初始的第二mlp子网络的参数,得到训练好的第二mlp子网络;第二mlp损失函数是基于第五训练表情隐向量与第四训练表情隐向量的差值构建的;
40、其中,第一待训练图像、待训练模型和待训练纹理具有的角度信息和表情信息均相同。
41、在一种可选的实现方式中,根据获取到的第二待训练图像和对应的标签信息对人脸驱动网络进行优化,得到优化后的人脸驱动网络,包括:
42、将第二待训练图像输入人脸驱动网络,得到人脸驱动图像;
43、基于建模损失函数更新人脸驱动网络的参数,得到优化后的人脸驱动网络;其中,建模损失函数是基于人脸驱动图像和第二待训练图像的差值构建的。
44、第二方面,本技术实施例提供了一种人脸驱动装置,包括:
45、图像处理模块,用于将待处理图像帧输入人脸驱动网络,得到具有第一表情的几何模型和第一纹理;其中,人脸驱动网络是基于目标对象的训练数据集预先训练得到的;
46、纹理处理模块,用于将第一纹理和预设无表情纹理进行叠加,得到第二纹理;
47、模型渲染模块,用于基于第二纹理渲染几何模型,得到目标对象的三维人脸模型;其中,三维人脸模型上具有第一表情。
48、第三方面,本技术实施例提供了一种终端,包括:存储器和处理器;存储器存储有能够被处理器执行的计算机程序或指令;处理器执行计算机程序或指令以实现上述第一方面中任一项的人脸驱动方法。
49、第四方面,本技术实施例提供了计算机存储介质,存储介质中存储有能够被处理器执行的计算机程序或指令,计算机程序或指令被执行时实现上述第一方面中任一项的人脸驱动方法。
50、第五方面,本技术实施例提供了一种计算机程序产品,当计算机程序产品在终端设备上运行时,使得终端设备执行上述第一方面中任一项所述的人脸驱动方法。
51、本技术实施例提供的人脸驱动方法、装置及终端,通过驱动对象的待处理图像帧,将驱动对象携带的第一表情输入至目标对象的人脸驱动网络,从而驱动人脸驱动网络输出带有第一表情的属于目标对象的第一纹理和几何模型,通过将目标对象的携带第一表情的纹理特征的第一纹理与纹理细节丰富的预设无表情纹理进行叠加,得到具有第一表情的丰富细节的目标对象的第二纹理,将第二纹理渲染至几何模型,得到目标对象的具有第一表情的三维人脸模型,并保证该三维人脸模型的纹理细节丰富,具有较强的真实感。
52、上述说明仅是本技术实施例技术方案的概述,为了能够更清楚了解本技术实施例的技术手段,而可依照说明书的内容予以实施,并且为了让本技术实施例的上述和其它目的、特征和优点能够更明显易懂,以下特举本技术的具体实施方式。
- 还没有人留言评论。精彩留言会获得点赞!