宫颈细胞萎缩级别智能诊断方法
1.本发明设计宫颈细胞萎缩级别智能诊断方法
背景技术:
2.宫颈阴道部鳞状上皮分为表层、中层以及基底层细胞,卵巢雌激素影响着细胞的生长与成熟,雌性激素水平的降低会导致萎缩性阴道炎和骨质疏松等症状,需要及时治疗,目前对鳞状细胞萎缩诊断不够明确,萎缩程度的诊断研究报道也较少。目前萎缩程度诊断完全依赖于医生“手动操作、肉眼观察”的人工阅片,这种方式存在两大痛点:(1)病理医生对tct图像有形成分的检测准确率较低,存在误诊和漏诊的情况;(2)病理诊断的工作量大,对医生的专业知识储备有一定的要求,且从业病理医生的人较少,无法大范围推广检查。因此,采用人工智能技术辅助医生做病原微生物检测具有重要意义。如今,随着人工智能的发展,智能诊断系统被广泛应用于宫颈细胞学检验。系统通过人工智能和图像处理等手段自动分析宫颈细胞病理涂片的有形成分,从而对细胞常见成分进行筛选,帮助病理医生节省90%以上的阅片时间,提高诊断效率。医学显微图像的自动化识别也成了热门的研究方向,但目前主要是人体细胞癌变的研究,而对于宫颈萎缩程度判别方面却鲜少有人研究。针对以上问题,提出宫颈细胞萎缩级别智能诊断方法,该方法提出了根据目标检测模型和分割模型结果计算出多种评价指标,将指标输入随机森林分类模型完成宫颈萎缩程度判别。
3.宫颈萎缩程度判别的关键在于表层细胞、中层细胞和基底层细胞的检测和细胞的细胞核分割。由于宫颈全景切片图像的尺寸过大,通常全景切片图像包含上亿数量级的像素。所以采用图像裁剪的方式,获得适当尺寸的图像。先用目标检测模型检测出表层细胞、中层细胞、基底层细胞,然后使用实例分割网络模型对检测出的每一层细胞的细胞核进行分割,最后计算每一层的细胞数量比、平均核质比和细胞拥挤度指标,将指标输入随机森林分类模型进行萎缩程度分级;经过充分的实验验证得知,在宫颈细胞萎缩程度判别上取得了很好的效果。
技术实现要素:
4.本发明的目的是为了解决给宫颈细胞萎缩程度判别制定系统化、智能化的诊断流程,而提出的一种宫颈细胞萎缩级别智能诊断方法。
5.上述发明目的主要是通过以下技术方案实现的:
6.1、扫描仪扫描样本,获得全景切片图像,然后用图像裁剪的方式,将病人样本裁剪成适当尺寸的图像,作为目标检测网络训练数据;
7.宫颈细胞萎缩程度判别方法的关键在于图像特征的提取,由于全景切片图像的尺寸过大,通常全景切片图像包含上亿数量级的像素。所以采用图像裁剪的方式,将病人样本分割成适当尺寸的图像。
8.2、采用目标检测网络进行目标检测,检测出每一张图表层细胞、中层细胞和基底层细胞;
9.s21、对步骤s1中的数据进行圆形框标注;
10.s22、目标检测网络采用改进后的circlenet圆形目标检测网络,在网络中生成热图的高斯核生成方法进行改进,高斯核半径的计算公式如下所示,其中,o为圆形标注框与预测框的重叠区域,r为圆形目标框的半径,r1为预测框包含圆形标注框时的高斯核半径,r2为原标注框包含预测框时的高斯核半径,r3为预测框与原标注框相交时的高斯核半径,gr为最后选择的高斯核半径:
11.(πr2)(π(r+r1)2)=o
ꢀꢀꢀ
(1)
12.(π(r-r2)2)(πr2)=o
ꢀꢀꢀ
(2)
[0013][0014]gr
=min(r1,r2,r3)
ꢀꢀꢀ
(4)
[0015]
s23、在circlenet特征提取的基础模块中引入金字塔卷积,金字塔卷积利用尺寸大小不小的卷积核对图像特征图进行卷积操作,采用不同尺寸的卷积核,一般的,小尺寸的卷积核感受野较小得到小目标和局部细节信息,较大的卷积核感受野较大,可以获得大目标的全局语义信息,最后将四种尺寸获得的特征图进行融合得到金字塔卷积后的特征图;
[0016]
s24、circlenet目标检测模型会检测出每张图像上的各层细胞数量和病人样本中各层细胞的数量。
[0017]
3、如权利要求1所述的宫颈细胞萎缩级别智能诊断方法,其特征在于,步骤s3中所述的根据检测出的细胞统计三层细胞的各自的数量和拥挤度,方法如下:
[0018]
s31、对每一层细胞的数量比计算如下,其中n
total
为病人样本检测出来的所有细胞,n
surface
为病人样本检测出来的所有表层细胞,n
middle
为病人样本检测出来的所有中层细胞,n
basal
为病人样本检测出来的所有基底层细胞:
[0019]ntotal
=n
surface
+n
middle
+n
basal
ꢀꢀꢀ
(5)
[0020]rsurface
=n
surface
/n
total
ꢀꢀꢀ
(6)
[0021]rmiddle
=n
middle
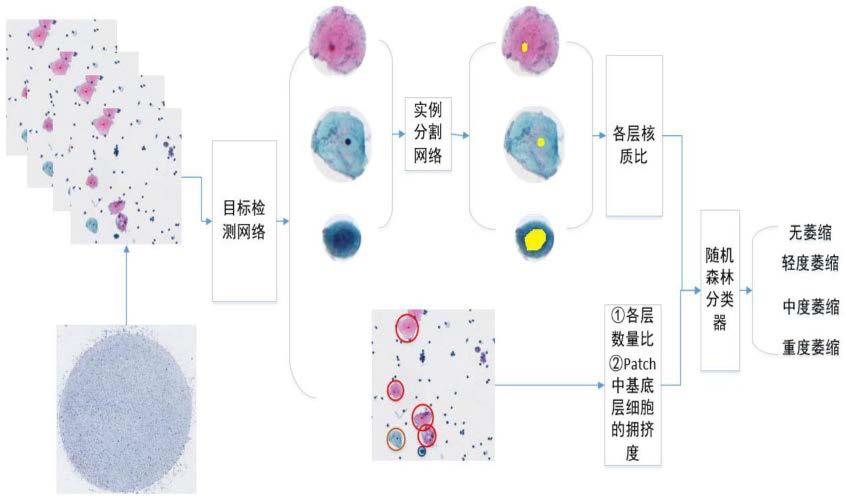
/n
total
ꢀꢀꢀ
(7)
[0022]rbasal
=n
basal
/n
total
ꢀꢀꢀ
(8)
[0023]
s32、每层细胞的拥挤度是采用每层细胞的面积之和占图片总面积的比例,计算如下,其中cr
surface
为病人样本表层细胞的拥挤度,cr
middle
为病人样本中层细胞的拥挤度,cr
basal
为病人样本基底层细胞的拥挤度,pa
itotal
为病人样本中第i张patch的面积,h为patch的高,w为patch的宽,pa为细胞的面积,r为细胞的半径,pa
ijsurface
为病人样本中第i张patch检测出来的第j个表层细胞的面积,pa
ijmiddle
为病人样本中第i张patch检测出来的第j个中层细胞的面积,pa
ijbasal
为病人样本中第i张patch检测出来的第j个基底层细胞的面积,m为第i张patch检测出来对应细胞层的所有细胞数量,n为病人样本分割成patch的总数:
[0024]
pa
itotal
=h*w
ꢀꢀꢀ
(9)
[0025]
pa=πr2ꢀꢀꢀ
(10)
[0026]
[0027][0028][0029]
4、如权利要求1所述的宫颈细胞萎缩级别智能诊断方法,其特征在于,步骤s4中所述的均匀选取目标检测出来的细胞小图,做细胞分割模型的训练数据,利用实例分割网络进行细胞核分割,得出每个细胞的细胞核轮廓,方法如下:
[0030]
s41、考虑到不同染色风格,不同制片方式都会对分割效果有影响,所以分别从不同域中挑选表层细胞、中层细胞、基底层细胞,每一层细胞各挑选出同样数量的单个细胞;
[0031]
s42、采用阈值分割先对数据进行粗分割,然后再人工确认分割标注,更正错误标注以及查漏补缺,得到实例分割模型的训练数据集;
[0032]
s43、由于制片或者患者雌激素低导致细胞密集堆叠等原因,会出现circlenet检测出来的单个细胞中可能存在多个细胞核的原因,所以采用实例分割分割出单个细胞核,并选取细胞核轮廓面积较大的作为该细胞的细胞核。
[0033]
5、如权利要求1所述的宫颈细胞萎缩级别智能诊断方法,其特征在于,步骤s5中所述的根据细胞核轮廓计算每一个细胞的核质比,统计表层细胞、中层细胞和基底层细胞各自的平均核质比,方法如下:
[0034]
s51、经过circlenet检测出来的圆形预测框已经跟细胞的轮廓贴近,所以将预测框的面积当作细胞的面积,实例分割出来的细胞核轮廓经过可计算出轮廓的面积,即细胞核的面积;
[0035]
s52、细胞的核质比是由细胞核的面积/细胞的面积,计算公式如下,其中,nisurface为第i个表层细胞的细胞核面积,cisurface为第i个表层细胞的细胞面积,nimiddle为第i个中层细胞的细胞核面积,cimiddle为第i个中层细胞的细胞面积,nibasal为第i个基底层细胞的细胞核面积,cibasal为第i个基底层细胞的细胞面积:
[0036][0037][0038][0039]
6、如权利要求1所述的宫颈细胞萎缩级别智能诊断方法,其特征在于,步骤s6中所述的s2-s5中计算的指标特征输入随机森林模型,获得指标特征值的预测结果,最终给样片判定萎缩程度,原理如下:
[0040]
s61、随机森林就是通过集成学习的思想将多棵树集成的一种算法,它的基本单元是决策树,每一棵树是从整个训练样本集当中选取固定数量的样本集,然后选取固定数量的特征集,从而构建随机森林中的每一棵决策树,每棵决策树都是一个分类器,那么对于一个输入样本,n棵树会有n个分类结果,而随机森林集成了所有的分类投票结果,将投票次数最多的类别指定为最终的输出;
[0041]
s62、选取不同萎缩程度的样本,分别计算上述的指标,采用有放回的抽样方式选择样本,构成中间数据集,然后在这个中间数据集的所有特征中随机选择多个特征,作为最终的数据集,从而构建多个数据集,每一轮采样中,样本x能被抽取到的概率是1/m,因此,经过m轮的抽样后,样本x还没有被抽取到的概率为:
[0042][0043]
s63、为每个数据集建立完全分裂的决策树,利用cart为每个数据集建立一个完全分裂、没有经过剪枝的决策树,最终得到多棵cart决策树;
[0044]
s64、在决策树cart算法中用gini指数来衡量数据的不纯度或者不确定性,同时用gini指数来决定类别变量的最优二分值切分问题,通过gini指数来确定某个特征的最优切分点,也即只需要确保切分后某点的gini指数值最小,这就是决策树cart算法中类别变量切分的关键所在,在分类问题中,假设有k个类,样本点属于第k类的概率为pk,则概率分布的gini指数的定义为:
[0045][0046]
如果样本集合d根据某个指标a被分割为d1,d2两个部分,那么在指标a的条件下,集合d的gini指数的定义为:
[0047]
gini(d,a)=d1/dgini(d1)+d2/dgini(d2)
ꢀꢀꢀ
(19)
[0048]
s65、预测新数据,根据得到的每一个决策树的结果来计算新数据的预测值,随机森林集成了所有的分类投票结果,将投票次数最多的类别指定为最终的输出,即为预测的萎缩程度级别。
[0049]
7、如权力要求1所述的宫颈细胞萎缩级别智能诊断方法,其特征在于,步骤s7中所述的将细胞萎缩诊断方法应用在智能病理诊断系统中,步骤如下:根据步骤s6中得到的细胞萎缩程度判别,对宫颈液基细胞全景切片图像的整体细胞萎缩程度进行定级;细胞萎缩程度为0表示“无萎缩”,细胞萎缩程度为1表示“轻度萎缩”,细胞萎缩程度为2表示“中度萎缩”,细胞萎缩程度为3表示“重度萎缩”;在智能诊断系统中,对于萎缩程度较高的片应给予高度重视。
[0050]
发明效果
[0051]
宫颈细胞中的特征信息对医生和自动化诊断系统的诊断具有很重要的参考价值,在传统的诊断方式中,完全依赖于医生“手动操作、肉眼观察”的人工阅片,这种方式导致病理医生对tct图像有形成分的检测准确率较低,存在误诊和漏诊的情况;除此之外,病理诊断的工作量大,对医生的专业知识储备有一定的要求,且从业病理医生的人较少,无法大范围推广检查。因此,采用人工智能技术辅助医生做病原微生物检测具有重要意义。本算法先用目标检测检测出表层细胞、中层细胞、基底层细胞,然后使用实力分割模型对检测出的每一层细胞的细胞核进行分割,最后计算每一层的细胞数量比、核质比和细胞拥挤度指标,将指标输入随机森林分类模型进行萎缩程度分级。为自动化诊断系统提供有力的支持,减少了因病理医生因专业知识不同带来的误诊,有效地提高了系统诊断的效率和准确率。
附图说明
[0052]
图1本文方法的实现流程图
[0053]
图2circlenet目标检测流程图;
[0054]
图3随机森林分类流程图;
[0055]
具体实施方法
[0056]
具体实施方式一:
[0057]
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0058]
如图1所示本文方法的流程图:
[0059]
所述模型训练包含步骤:
[0060]
s1、扫描仪扫描样本,获得全景切片图像,然后用图像裁剪的方式,获得适当尺寸的图像,作为目标检测训练数据;
[0061]
s2、利用目标检测网络进行细胞检测,检测出每一张图像的表层细胞、中层细胞和基底层细胞;
[0062]
s3、根据检测出的细胞统计三种层次细胞的数量占比和三种层次细胞的拥挤度;
[0063]
s4、均匀选取目标检测出来的细胞小图,做细胞分割模型的训练数据,利用实例分割网络进行细胞核分割,得出每个细胞的细胞核轮廓;
[0064]
s5、根据细胞核轮廓计算出每一个细胞的核质比,统计表层细胞、中层细胞和基底层细胞各自的平均核质比;
[0065]
s6、将s2-s5中计算的指标特征输入随机森林模型,获得指标特征值的预测结果,最终给样片判定萎缩程度;
[0066]
s7、将细胞萎缩诊断方法应用在智能病理诊断系统中。
[0067]
下面对本发明实施例进行详细的说明:
[0068]
本发明实施,应用本发明方法实现具体实现如下。
[0069]
如图1所示宫颈细胞萎缩级别智能诊断包含步骤:
[0070]
1、扫描仪扫描样本,获得全景切片图像,然后用图像裁剪的方式,获得1500张1024*1024尺寸的图像,作为circlenet训练数据;
[0071]
宫颈细胞萎缩程度判别方法的关键在于图像特征的提取,由于全景切片图像的尺寸过大,通常全景切片图像包含上亿数量级的像素。所以采用图像裁剪的方式,获得1024*1024尺寸的图像。
[0072]
2、利用目标检测网络进行细胞检测,检测出每一张图像的表层细胞、中层细胞和基底层细胞;
[0073]
s21、对步骤s1中的数据进行圆形框标注;
[0074]
s22、目标检测网络采用改进后的circlenet圆形目标检测网络,在网络中生成热图的高斯核生成方法进行改进,高斯核半径的计算公式如下所示,其中,o为圆形标注框与预测框的重叠区域,r为圆形目标框的半径,r1为预测框包含圆形标注框时的高斯核半径,r2为原标注框包含预测框时的高斯核半径,r3为预测框与原标注框相交时的高斯核半径,gr为
最后选择的高斯核半径:
[0075]
(πr2)/(π(r+r1)2)=o
ꢀꢀꢀ
(1)
[0076]
(π(r-r2)2)/(πr2)=o
ꢀꢀꢀ
(2)
[0077][0078]gr
=min(r1,r2,r3)
ꢀꢀꢀ
(4)
[0079]
s23、在circlenet特征提取的基础模块中引入金字塔卷积,金字塔卷积利用尺寸大小不小的卷积核对图像特征图进行卷积操作,采用的卷积核大小为1*1,3*3,5*5,7*7四种尺寸,一般的,小尺寸的卷积核感受野较小得到小目标和局部细节信息,较大的卷积核感受野较大,可以获得大目标的全局语义信息,最后将四种尺寸获得的特征图进行融合得到金字塔卷积后的特征图;
[0080]
s24、circlenet目标检测模型会检测出每张图像上的各层细胞数量和病人样本中各层细胞的数量。
[0081]
3、根据检测出的细胞统计三层细胞的各自的数量和拥挤度;
[0082]
s31、对每一层细胞的数量比计算如下,其中n
total
为病人样本检测出来的所有细胞,n
surface
为病人样本检测出来的所有表层细胞,n
middle
为病人样本检测出来的所有中层细胞,n
basal
为病人样本检测出来的所有基底层细胞:
[0083]ntotal
=n
surface
+n
middle
+n
basal
ꢀꢀꢀ
(5)
[0084]rsurface
=n
surface
/n
total
ꢀꢀꢀ
(6)
[0085]rmiddle
=n
middle
/n
total
ꢀꢀꢀ
(7)
[0086]rbasal
=n
basal
/n
total
ꢀꢀꢀ
(8)
[0087]
s32、每层细胞的拥挤度是采用每层细胞的面积之和占图片总面积的比例,计算如下,其中cr
surface
为病人样本表层细胞的拥挤度,cr
middle
为病人样本中层细胞的拥挤度,cr
basal
为病人样本基底层细胞的拥挤度,pa
itotal
为病人样本中第i张patch的面积,h为patch的高,w为patch的宽,pa为细胞的面积,r为细胞的半径,pa
ijsurface
为病人样本中第i张patch检测出来的第j个表层细胞的面积,pa
ijmiddle
为病人样本中第i张patch检测出来的第j个中层细胞的面积,pa
ijbasal
为病人样本中第i张patch检测出来的第j个基底层细胞的面积,m为第i张patch检测出来对应细胞层的所有细胞数量,n为病人样本分割成patch的总数:
[0088]
pa
itotal
=h*w
ꢀꢀꢀ
(9)
[0089]
pa=πr2ꢀꢀꢀ
(10)
[0090][0091][0092][0093]
4、均匀选取目标检测出来的细胞小图,做细胞分割模型的训练数据,利用实例分割网络进行细胞核分割,得出每个细胞的细胞核轮廓;
[0094]
s41、考虑到不同染色风格,不同制片方式都会对分割效果有影响,所以分别从不同域中挑选表层细胞、中层细胞、基底层细胞,每一层细胞各挑选出1000张能明显看出细胞核的单个细胞,一共3000张图片。
[0095]
s42、实力分割模型采用maskrcnn网络,先采用阈值分割先对数据进行粗分割,然后再人工确认分割标注,更正错误标注以及查漏补缺,得到maskrcnn的训练数据集。
[0096]
s43、由于制片或者患者雌激素低导致细胞密集堆叠等原因,会出现circlenet检测出来的单个细胞中可能存在多个细胞核的原因,所以采用实例分割maskrcnn分割出单个细胞核,并选取细胞核轮廓面积较大的作为该细胞的细胞核。
[0097]
5、根据细胞核轮廓计算每一个细胞的核质比,统计表层细胞、中层细胞和基底层细胞各自的平均核质比;
[0098]
s51、经过circlenet检测出来的圆形预测框已经跟细胞的轮廓贴近,所以将预测框的面积当作细胞的面积,maskrcnn分割出来的细胞核轮廓经过opencv库可计算出轮廓的面积,及细胞核的面积。
[0099]
s52、为了让计算出来的每一层核质比更有代表性,先对每一层细胞计算出来的核质比进行排序,然后取中间3/5的平均值作为每一层的核质比,细胞的核质比是由细胞核的面积/细胞的面积,计算公式如下,其中,n
isurface
为第i个表层细胞的细胞核面积,c
isurface
为第i个表层细胞的细胞面积,n
imiddle
为第i个中层细胞的细胞核面积,c
imiddle
为第i个中层细胞的细胞面积,n
ibasal
为第i个基底层细胞的细胞核面积,c
ibasal
为第i个基底层细胞的细胞面积:
[0100][0101][0102][0103]
6、将s2-s5中计算的指标特征输入随机森林分类模型,获得指标特征值的预测结果,最终给样片判定萎缩程度;
[0104]
s61、随机森林就是通过集成学习的思想将多棵树集成的一种算法,它的基本单元是决策树,每一棵树是从整个训练样本集当中选取固定数量的样本集,然后选取固定数量的特征集,从而构建随机森林中的每一棵决策树,每棵决策树都是一个分类器(假设现在针对的是分类问题),那么对于一个输入样本,n棵树会有n个分类结果,而随机森林集成了所有的分类投票结果,将投票次数最多的类别指定为最终的输;
[0105]
s62、选取150个不同萎缩程度的样本,分别计算上述的9个指标,采用有放回的抽样方式选择150个样本,构成中间数据集,然后在这个中间数据集的所有特征中随机选择3个特征,作为最终的数据集,从而构建多个数据集,每一轮采样中,样本x能被抽取到的概率是1/m,因此,经过m轮的抽样后,样本x还没有被抽取到的概率为:
[0106][0107]
s63、为每个数据集建立完全分裂的决策树,利用cart为每个数据集建立一个完全
分裂、没有经过剪枝的决策树,最终得到多棵cart决策树;
[0108]
s64、在决策树cart算法中用gini指数来衡量数据的不纯度或者不确定性,同时用gini指数来决定类别变量的最优二分值切分问题,通过gini指数来确定某个特征的最优切分点,即只需要确保切分后某点的gini指数值最小,这就是决策树cart算法中类别变量切分的关键所在,在分类问题中,假设有k个类,样本点属于第k类的概率为pk,则概率分布的gini指数的定义为:
[0109][0110]
如果样本集合d根据某个指标a被分割为d1,d2两个部分,那么在指标a的条件下,集合d的gini指数的定义为:
[0111]
gini(d,a)=d1/dgini(d1)+d2/dgini(d2)
ꢀꢀꢀ
(19)
[0112]
s65、预测新数据,根据得到的每一个决策树的结果来计算新数据的预测值,随机森林集成了所有的分类投票结果,将投票次数最多的类别指定为最终的输出,即为预测的萎缩程度级别。
[0113]
7、将细胞萎缩诊断方法应用在智能病理诊断系统中;
[0114]
根据步骤s6中得到的细胞萎缩程度判别,对宫颈液基细胞全景切片图像的整体细胞萎缩程度进行定级;细胞萎缩程度为0表示“无萎缩”,细胞萎缩程度为1表示“轻度萎缩”,细胞萎缩程度为2表示“中度萎缩”,细胞萎缩程度为3表示“重度萎缩”;在智能诊断系统中,对于萎缩程度较高的片应给予高度重视。
[0115]
本发明还可有其它多种实施例,在不背离本发明精神及其实质的情况下,本领域技术人员当可根据本发明做出各种相应的改变和变形,但这些相应的改变和变形都应属于本发明范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1