一种地形自适应水深模型分区加权融合方法
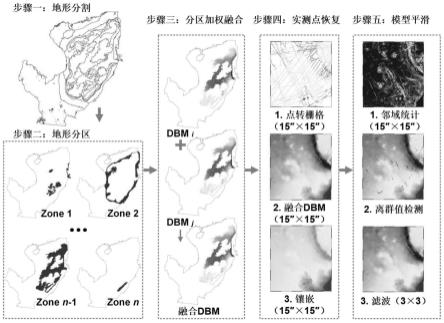
1.本发明涉及一种基于地形特征的自适应水深模型分区加权融合方法,该方法通过多源水深数据和模型预处理(包括海图矢量化、数学基础统一、数据清洗等步骤)、数字水深模型(dbm)质量验证与对比、多尺度地形分割与分区、最优空间域加权融合、实测点恢复和自适应邻域统计滤波的步骤,得到一个更高质量的无缝南海水深数据集,为大规模海底地形数据集的及时重建和更新提供了有价值的参考。
背景技术:
2.世界海洋覆盖约3.62亿平方公里,占地球表面面积的71%(ronov 1994; eakins and sharman 2010)。许多研究依赖于数字水深模型(dbm)数据,例如板块构造和海洋盆地的演化(sandwell and smith 1997)、精确的海洋环流建模 (gula et al.2014)、海洋地质灾害评估(chiocci et al.2011)依据海啸等自然灾害预测波(sepulveda et al.2019)等。海洋基础设施的发展也需要高分辨率dbm数据(ellis et al.2017)。dbm数据也有助于海上搜救工作,马航mh370 航班坠毁区域高分辨率测深数据的缺乏,极大地阻碍了搜救工作(picard et al. 2018)。dbm数据对于航行安全和大陆架界限确定也至关重要的(jakobsson et al. 2003)。此外,通过dbm数据获取的坡度、坡向等特征对底栖生物的分布影响很大(wilson et al.2007)。因此,许多国家和国际组织已经意识到建立全球dbm 的重要性(jakobsson et al.2017)。
3.目前,全球仅6.2%的海底地形存在船载声呐测绘数据(mayer et al.2018),全球网格化的dbm数据融合工作仍然极具挑战性(hell et al.2011)。通过对船舶测深、海洋重力等数据的不断细化和改进,已经形成了多个版本的公开全球dbm数据集,包括gebco(jakobsson et al.2017)、srtm(becker et al.2009)、全球海底地形(简称topo)(smith and sandwell 1997)、etopo(amante andeakins 2009)以及dtu(andersen et al.2008)等。现有dbm生成技术多集中在利用精度较高的dbm进行补充或插值,例如反距离加权法(schaffer et al. 2016)、克里金法(merwade 2009)、样条插值法(hell et al.2011)、双线性插值法(ramillien and cazenave 1997)以及自然邻域插值法(glenn et al.2016) 等,插值结果会出现噪声、数据空洞和分辨率不足等问题(yue et al.2015)。常用的模型融合方法分为频率域融合、空间域融合和稀疏表达融合三类。如在频率域融合srtm和aster gdem数据,以填充模型空洞,可提高融合结果的整体精度(karkee et al.2008);基于稀疏表达的融合框架可有效减少局部几何异常(papasaika et al.2011);空间域融合通常直接在数值层面上进行 (costantini et al.2006),该方法简单易行,且较为可靠(gruber et al. 2016;petrasova et al.2017)。然而,该方法的关键在于如何量化不同数据集在每个地表位置的输入权重(schindler et al.2011)。
4.现有的研究倾向于用新获得的测深数据来补充区域dbm,很少有研究利用多个数据集及时重建和更新大规模海底地形。随着15弧秒分辨率dbms的最新发布,现在有必要对这些新产品的质量进行比较和验证。此外,dbm数据集的精度会因地形条件的不同而有所差
异(yang et al.2018),可在实测测深数据的约束下进行分割和融合。本发明提出了一种基于地形特征的自适应水深模型分区加权融合框架,用于南海及其邻近地区水下地形的及时重建和更新。通过融合多源测深数据和dbm数据集,生成一个高质量无缝南海数字水深模型数据集。
技术实现要素:
5.本发明要解决的技术问题是:船测水深数据的不足,使得大规模海底地形重建和更新困难。通过融合处理,将多源测深数据用于增强全局dbm数据集,利用多个数据集及时重建和更新大规模海底地形,以克服船测水深数据的不足。
6.为了解决以上技术问题,本发明提供的一种地形自适应水深模型分区加权融合方法,包括以下步骤:
7.步骤1、数据预处理——对纸质海图进行矢量化,将矢量水深数据统一坐标系和分辨率,对船测声纳数据进行清洗,获得具有相同空间基准的有效实测水深数据和数字水深模型数据集;
8.步骤2、dbm模型质量验证与对比——模型质量对比评价,对7个dbm 模型进行掩膜处理,得到水下部分;dbm模型质量对比从定量和定性两个方面进行:
9.a)、利用处理后的实测水深数据,对整体质量进行定量比较,精度采用三个定量指标:mae、sd和rmse;
10.b)、沿航线剖面的质量进行定量比较,精度采用三个定量指标:mae、sd 和rmse;
11.c)、在南沙群岛和西沙群岛等局部地区,通过设置等高距一致的等高线,定性对比各模型对水下地形在细节上的表现;
12.步骤3、多尺度地形分割与分区——顾及不同地形单元对模型融合的不同贡献,对目标区域进行分割与分区,具体如下:
13.a)、地形分割
14.利用多尺度分割方法对待融合区域进行地形分割,当分割单元的内部同质性和外部异质性都达到最大,即为最佳分割结果;
15.b)、地形分区
16.基于水深和地形特征参数进行地形分区,通过计算水深、地形坡度、地形粗糙度和表面切割深度,建立自适应地形分类规则词典,指导地形分区;
17.步骤4、最优空间域加权融合——根据加权融合方法,计算各个地形子融合 dbm结果,以测点为参考,对原始水深输入数据两两地进行线性加权平均,公式如下:
18.z(x,y)=wi×
zi(x,y)+wj×
zj(x,y)
19.其中,zi(x,y)、zj(x,y)代表输入的第i个dbm模型dbmi的水深值和第j 个dbm模型dbmj的水深值,wi、wj分别代表各自的权重,i、j∈{1,2,3,4,5,6, 7}并且i≠j;
20.采用遍历寻优定权的方法确定权重,以dbm模型水深值与实测值之间的均方根误差rmse最小为约束,遍历权重赋值进行寻优,得到7个dbms的最优融合结果及对应权重;具体方法如下:
21.取待融合的dbmi权重为w,dbmj权重为1-w,w取值为[0,1],设计计算步长为0.01;通过加权系数由0到1的遍历计算,从而得到遍历过程中的融合最优解与权重系数;
[0022]
步骤5、实测点恢复——利用实测点恢复的方法,形成质量更好的融合模型;
[0023]
步骤6、模型平滑——利用自适应邻域统计滤波方法,进行融合模型的平滑。
[0024]
本发明的有效效益如下:
[0025]
(1)本发明提出的一种自适应分区域空间加权融合框架,可通过多个水深模型快速重建和更新大规模海底地形。通过填补空白和消除异常值对模型进行整合和补充,可以提高模型的可靠性。该融合框架可以扩展到其他地区。
[0026]
(2)本发明融合得15弧秒分辨率的无缝南海水深模型,通过同其他全球水深模型对比验证,准确性提升1-40%不等。融合后的模型对地形细节的表达更加细致和真实。
[0027]
(3)本发明验证与对比了南海范围内应用最广泛的7个全球水深模型的性能。证明了srtm15_plus和gebco_2019两类数据集整体精度最高、最稳健,提高了全球水深模型的适用范围和潜力。
附图说明
[0028]
下面结合附图对本发明作进一步的说明。
[0029]
图1为本发明实施例的范围示意图。
[0030]
图2为本发明实施例的总体流程图。
[0031]
图3为本发明数据清洗方法示意图。
[0032]
图4为本发明多尺度地形分割与分区流程图。
[0033]
图5为本发明空间域加权融合示意图。
[0034]
图6为本发明遍历寻优定权方法流程图。
[0035]
图7为本发明实测点恢复和模型平滑流程图。
[0036]
图8为本发明实施例水深模型融合结果。
[0037]
图9为本发明实施例水深模型融合结果对比验证。
具体实施方式
[0038]
下面根据附图详细阐述本发明,使本发明的技术路线和操作步骤更加清晰。
[0039]
本技术方案的实施例在中国南海及周边海域进行(图1),对多源水深数据和模型进行自适应分区域空间加权融合,重建和更新大规模海底地形。南海是一个半开放海域,被中国、越南、马来西亚、印度尼西亚和菲律宾包围,其海底地形极为复杂,边缘为大陆架,中心为深海盆地,海山、环礁、岛屿星罗棋布。本实施例以该实验区为例说明一种自适应分区域空间加权融合方法,技术流程如图2所示,具体包括以下步骤:
[0040]
步骤1、数据预处理——对纸质海图进行矢量化,将矢量水深数据统一坐标系和分辨率,对船测声纳数据进行清洗,获得具有相同空间基准的有效实测水深数据和数字水深模型数据集。具体如下:
[0041]
a)、海图矢量化。
[0042]
首先,对纸质海图先进行数字化扫描。然后,对扫描的海图图像文件进行几何校正,创建点矢量文件,标注水深点的地理位置。最后,读取海图图像中包含水深点的区域,识别其中中的水深点数字,并进行目视检查,最终实现纸质海图的矢量化。在此过程中,保证海图水深点具有统一的地理参考,并保存为为xyz ascii data格式文件。
[0043]
b)、数学基础统一。
[0044]
具体包括坐标基准统一和分辨率统一。使用feature manipulationengine(fme)软件,将矢量水深数据的数据基准转换到wgs-84坐标系下,同时将数据转换成esri arcgis shape files。将7个水深模型数据统一为geotiffformat格式,并对所有数据进行坐标系及投影转换,将其投影并配准到到统一的地理参考系统中。
[0045]
将7个水深模型数据的空间分辨率统一为15"。船测水深点的原始空间分辨率过高,所以还需要对原始船测水深点进行格网化,保证每个水深栅格(15"
×ꢀ
15")仅对应一个高程值,若一个栅格范围存在多点,则栅格值用多个点的平均值表示。
[0046]
c)、数据清洗。
[0047]
数据清洗方法如图3所示。首先,根据船测数据属性筛选出60年代以后的船测声纳数据。然后,根据iho s-44第五版有关规定对测深数据中的无水深值和无效值进行剔除。最后,依据pauta criterion(3σ准则)对船测数据进行异常值检验和剔除。具体方法是通过对所有有效航次进行数据检验,包括两个方面,第一是航行方向(航线剖面)的异常值检验,第二是根据数据统计的异常值检验。
[0048]
步骤2、dbm模型质量验证与对比——模型质量对比评价,对7个dbm模型进行掩膜处理,得到水下部分。dbm模型质量对比从定量和定性两个方面进行:
[0049]
a)、利用处理后的实测水深数据,对整体质量进行定量比较,精度采用三个定量指标:mae、sd和rmse。
[0050]
b)、沿航线剖面的质量进行定量比较,精度采用三个定量指标:mae、sd 和rmse。
[0051]
c)、在南沙群岛和西沙群岛等局部地区,通过设置等高距一致的等高线,定性对比各模型对水下地形在细节上的表现。
[0052]
精度采用的三个定量指标(mae、sd和rmse),公式如下:
[0053][0054][0055][0056]
其中,e为对应dbm值与参考水深做差得到的误差,n为参与检验的水深点个数,为误差的均值。mae能反映没有异常值情况下的精度鲁棒性;sd用来衡量一组数自身的离散程度;rmse能更准确地反映存在异常值情况下的误差分布。
[0057]
步骤3、多尺度地形分割与分区——顾及不同地形单元对模型融合的不同贡献,对目标区域进行分割与分区。多尺度地形分割与分区流程如图4所示,具体如下:
[0058]
a)、地形分割。
[0059]
利用多尺度分割方法(costa et al.2017)对待融合区域进行地形分割。从像素层开始将图像对象逐层集成到较大的图像对象中,产生不同分割尺度的分割结果。利用局部方差(lv)检测的最优分割尺度,当lv的变化率(roc)达到峰值时,认为相应的分割规模最
优,此时分割单元的内部同质性和外部异质性都达到最大。
[0060]
b)、地形分区。
[0061]
基于水深和地形特征参数进行地形分区。本方法通过计算4个地形特征参数(水深、地形坡度、地形粗糙度和表面切割深度),建立自适应地形分类词典,地形特征参数计算公式如下:
[0062]
其中,sc为海底单元的曲面表面积,sh为sc在水平表面上的投影面积。
[0063][0064]
其中,表示邻域内的平均水深,z
max
代表邻域内的最大水深。
[0065][0066]
其中,表示南北方向(x轴)高程变化率,表示东西方向(y轴)高程变化率。
[0067]
多尺度分割在ecognition developer 9.1软件的尺度参数估计工具中实现,选择形状设为0.1,紧致度设为0.5,不断优化分割尺度,最终确定分割尺度为 2500,得到分割结果与水深分布基本吻合。利用计算的多个地形特征参数,建立地形分类规则字典,将目标区域划分为7个地形分区。
[0068]
步骤4、最优空间域加权融合——根据加权融合方法,计算各个地形子融合 dbm结果。空间域加权融合原理如5所示。以测点为参考,对原始水深输入数据两两地进行线性加权平均,公式如下:
[0069]
z(x,y)=wi×
zi(x,y)+wj×
zj(x,y)
[0070]
其中,zi(x,y)、zj(x,y)代表输入的第i个dbm模型dbmi的水深值和第j 个dbm模型dbmj的水深值,wi、wj分别代表各自的权重,i、j∈{1,2,3,4,5,6,7}并且i≠j。
[0071]
采用遍历寻优定权的方法确定权重,以dbm模型水深值与实测值之间的均方根误差rmse最小为约束,遍历权重赋值进行寻优,得到7个dbms的最优融合结果及对应权重。简要流程如图6所示,该步骤通过编程实现,具体方法如下:
[0072]
取待融合的dbmi权重为w,dbmj权重为1-w,w取值为[0,1],设计计算步长为0.01;通过加权系数由0到1的遍历计算,从而得到遍历过程中的融合最优解与权重系数。以区域2为例,rmse指标与w之间关系如图6所示,横坐标为gebco_2019权重w,纵坐标单位为m。由图可见,在最优权重w=0.23之前, rmse随着权重的增加而降低,这表明gebco_2019对于融合dbm存在正的贡献。在最优权重w=0.23之后,rmse随着权重的增加而增加,即srtm15_plus 为0.77时rmse最小=73.22m。
[0073]
通过上述方法,以dbm与实测值之间的rmse最小为约束,遍历权重赋值进行寻优,可得到7个dbms的最优融合结果及对应权重。具体如下:
[0074]
7个dbm模型在不同地形子区域对应的权重具体如下:
[0075]
子区域1:srtm15_plus(权重=0.85)、gebco_2019(权重=0.15)。
[0076]
子区域2:srtm15_plus(权重=0.77)、gebco_2019(权重=0.23)。
[0077]
子区域3:srtm15_plus(权重=0.50)、srtm30_plus(权重=0.50)。
[0078]
子区域4:srtm15_plus(权重=0.73)、gebco_2014(权重=0.27)。
[0079]
子区域5:srtm15_plus(权重=0.91)、dtu10(权重=0.09)。
[0080]
子区域6:srtm15_plus(权重=0.78)、gebco_2014(权重=0.22)。
[0081]
子区域7:srtm15_plus(权重=0.80)、topo v19.1(权重=0.20)。
[0082]
步骤5、实测点恢复。利用实测点恢复的方法,形成质量更好的融合模型,简要流程如图7(a)-7(d)所示,具体如下:将实测点转化为规则格网(15
″×
15
″
分辨率),同时移去融合模型的对应栅格,二者镶嵌以实现融合模型的实测值恢复。
[0083]
步骤6、模型平滑。在上一步的基础上,引入自适应邻域统计滤波方法,进行融合模型的平滑,简要流程如图7(e)-7(h)所示,具体如下:首先提取每个像素围绕中心像素的3
×
3邻域补丁,计算邻域像素与中心像素之间的差值,将差值大于3倍标准差的中心像素判断为异常值。然后,利用邻域像素的均值替代异常值,同时实现nodata区域的空洞填充,从而达到高程异常值滤波的目的。最后,通过低通滤波(3
×
3),进行模型平滑。最终的融合结果如图8所示。
[0084]
验证实施例:
[0085]
下面为验证本发明方法可靠性,继续以该实例进行说明。
[0086]
为验证本方法的可靠性,引入实测数据,与原始dbm模型相比,融合得到的南海水深模型总体精度有所提高,rmse为99.60m,mae为44.03m,sd为 99m,r2为0.98,其误差主要集中在(-100-100m)范围,约占90%。与 gebco_2019、gebco_2014、srtm30_plus相比,rmse精度分别提高13%, 40%和15%。与srtm15_plus(rmse=100.74)的精度最为接近,提高了0.1%,证明了srtm15_plus的精度最可靠,其次是gebco_2019。
[0087]
利用交叉验证,基于统计的检查点法,比较局部融合前后的dbm质量。实验位置选择在南沙群岛及其附近海域,该区域均存在大量珊瑚礁,水深跨度大,地形复杂。融合前与融合后的模型分别与实测数据(2900个海图水深点)作精度比较,结果如图9所示,其中等深线为实测点(船测水深点和海图水深点) 由克里金插值得到,(b)-(i)分别代表融合dbm、gebco_2019、gebco_2014、 srtm15_plus v2、srtm30_plus v11、topo v19.1、etopo1和dtu10。8 个dbm与等深线图基本一致。南沙海域的融合模型与srtm15_plus v2, gebco_2019最接近,出露水面的岛礁的大小和位置基本一致,地形细节更为丰富。srtm15_plus,gebco_2019比各自之前的版本在浅水区的结果更可靠。 topo v19.1在水深变化处存在大量噪声。etopo1在深水区效果与 srtm30_plus接近,而出露水面的范围过大。dtu10在深水区的反演水深普遍更浅,但细节却是最严重。
[0088]
原始的dbm模型依赖于重力卫星和测高卫星提供的高精度的重力异常和垂直重力梯度信息,本发明提出的水深模型融合方法一定程度上克服了测深数据的不足。当新的测深数据被引入,该融合框架用于提高dbm的可靠性。
[0089]
除上述实施例外,本发明还可以有其他实施方式。凡采用等同替换或等效变换形成的技术方案,均落在本发明要求的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1